Tło
Jedną z pierwszych rzeczy, na które patrzę podczas rozwiązywania problemów z wydajnością, są statystyki oczekiwania za pośrednictwem DMV sys.dm_os_wait_stats. Aby zobaczyć, na co czeka SQL Server, używam zapytania z bieżącego zestawu zapytań diagnostycznych SQL Server Glenna Berry'ego. W zależności od wyników zaczynam zagłębiać się w określone obszary w SQL Server.
Na przykład, jeśli widzę wysokie oczekiwania CXPACKET, sprawdzam liczbę rdzeni na serwerze, liczbę węzłów NUMA oraz wartości maksymalnego stopnia równoległości i progu kosztu równoległości. To są podstawowe informacje, których używam do zrozumienia konfiguracji. Zanim nawet rozważę wprowadzenie jakichkolwiek zmian, zbieram więcej dane ilościowe, ponieważ system z czekami CXPACKET niekoniecznie musi mieć niepoprawne ustawienie maksymalnego stopnia równoległości.
Podobnie system, który ma wysokie oczekiwania na typy oczekiwania związane z operacjami we/wy, takie jak PAGEIOLATCH_XX, WRITELOG i IO_COMPLETION, niekoniecznie ma gorszy podsystem pamięci masowej. Kiedy widzę typy oczekiwania związane z we/wy jako najwyższe oczekiwania, od razu chcę dowiedzieć się więcej o podstawowym magazynie. Czy jest to pamięć masowa podłączana bezpośrednio, czy sieć SAN? Jaki jest poziom RAID, ile dysków znajduje się w tablicy i jaka jest prędkość dysków? Chcę również wiedzieć, czy inne pliki lub bazy danych współdzielą pamięć. I chociaż ważne jest, aby zrozumieć konfigurację, logicznym następnym krokiem jest przyjrzenie się wirtualnym statystykom plików za pośrednictwem DMV sys.dm_io_virtual_file_stats.
Wprowadzony w SQL Server 2005, ten DMV zastępuje funkcję fn_virtualfilestats, którą prawdopodobnie znają i kochają ci z Was, którzy korzystali z SQL Server 2000 i wcześniejszych wersji. DMV zawiera skumulowane informacje we/wy dla każdego pliku bazy danych, ale dane są resetowane po ponownym uruchomieniu instancji, gdy baza danych jest zamknięta, przełączona w tryb offline, odłączona i ponownie dołączona itp. Bardzo ważne jest, aby zrozumieć, że dane statystyk wirtualnych plików nie są reprezentatywne dla bieżących wydajność – jest to migawka będąca agregacją danych I/O od ostatniego wyczyszczenia przez jedno z wyżej wymienionych zdarzeń. Mimo że dane nie pochodzą z określonego punktu w czasie, nadal mogą być przydatne. Jeśli najwyższy czas oczekiwania na instancję jest związany z we/wy, ale średni czas oczekiwania jest mniejszy niż 10 ms, przechowywanie prawdopodobnie nie stanowi problemu – ale skorelowanie wyników z tym, co widzisz w sys.dm_io_virtual_stats, nadal warto potwierdzić niski opóźnienia. Co więcej, nawet jeśli widzisz duże opóźnienia w sys.dm_io_virtual_stats, nadal nie udowodniłeś, że przechowywanie jest problemem.
Konfiguracja
Aby spojrzeć na statystyki wirtualnych plików, ustawiłem dwie kopie bazy danych AdventureWorks2012, którą można pobrać z Codeplex. W przypadku pierwszej kopii, zwanej dalej EX_AdventureWorks2012, uruchomiłem skrypt Jonathana Kehayiasa, aby rozszerzyć tabele Sales.SalesOrderHeader i Sales.SalesOrderDetail do odpowiednio 1,2 miliona i 4,9 miliona wierszy. W przypadku drugiej bazy danych, BIG_AdventureWorks2012, użyłem skryptu z mojego poprzedniego wpisu dotyczącego partycjonowania, aby utworzyć kopię tabeli Sales.SalesOrderHeader z 123 milionami wierszy. Obie bazy danych były przechowywane na zewnętrznym dysku USB (Seagate Slim 500 GB), z tempdb na moim dysku lokalnym (SSD).
Przed testowaniem utworzyłem cztery niestandardowe procedury składowane w każdej bazie danych (Create_Custom_SPs.zip), które służyłyby jako moje „normalne” obciążenie. Mój proces testowania przebiegał następująco dla każdej bazy danych:
- Uruchom ponownie instancję.
- Przechwyć statystyki wirtualnych plików.
- Uruchom „normalne” obciążenie przez dwie minuty (procedury wywoływane wielokrotnie za pomocą skryptu PowerShell).
- Przechwyć statystyki wirtualnych plików.
- Przebuduj wszystkie indeksy dla odpowiednich tabel SalesOrder.
- Przechwyć statystyki wirtualnych plików.
Dane
Aby przechwycić wirtualne statystyki plików, utworzyłem tabelę do przechowywania informacji historycznych, a następnie wykorzystałem odmianę zapytania Jimmy'ego Maya z jego skryptu DMV All-Stars do wykonania migawki:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Uruchomiłem ponownie instancję, a następnie natychmiast przechwyciłem statystyki plików. Kiedy przefiltrowałem dane wyjściowe, aby wyświetlić tylko pliki bazy danych EX_AdventureWorks2012 i tempdb, przechwycono tylko dane tempdb, ponieważ nie zażądano żadnych danych z bazy danych EX_AdventureWorks2012:

Wyjście z początkowego przechwycenia sys.dm_os_virtual_file_stats
Następnie uruchomiłem „normalne” obciążenie przez dwie minuty (liczba wykonań każdej procedury składowanej nieznacznie się różniła), a po ponownym zakończeniu przechwyconych statystyk plików:

Wyjście z sys.dm_os_virtual_file_stats po normalnym obciążeniu
Widzimy opóźnienie 57 ms dla pliku danych EX_AdventureWorks2012. Nie jest to idealne, ale z biegiem czasu, przy moim normalnym obciążeniu pracą, prawdopodobnie to by się wyrównało. Opóźnienie tempdb jest minimalne, czego można się spodziewać, ponieważ obciążenie, które uruchomiłem, nie generuje dużej aktywności tempdb. Następnie przebudowałem wszystkie indeksy dla tabel Sales.SalesOrderHeaderEnlarged i Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Przebudowa zajęła mniej niż minutę i zauważono wzrost opóźnienia odczytu dla pliku danych EX_AdventureWorks2012 oraz skok opóźnienia zapisu dla danych EX_AdventureWorks2012 i pliki dziennika:

Wyjście z sys.dm_os_virtual_file_stats po przebudowie indeksu
Zgodnie z tą migawką statystyk plików opóźnienie jest straszne; ponad 600ms na zapisy! Gdybym zobaczył tę wartość dla systemu produkcyjnego, łatwo byłoby od razu podejrzewać problemy z magazynowaniem. Jednak warto również zauważyć, że AvgBPerWrite również wzrósł, a większe zapisy bloków trwają dłużej. Oczekuje się wzrostu wartości AvgBPerWrite dla zadania odbudowy indeksu.
Zrozum, że patrząc na te dane, nie otrzymujesz pełnego obrazu. Lepszym sposobem na sprawdzenie opóźnień przy użyciu wirtualnych statystyk plików jest zrobienie migawek, a następnie obliczenie opóźnień dla minionego okresu. Na przykład poniższy skrypt używa dwóch migawek (bieżącego i poprzedniego), a następnie oblicza liczbę odczytów i zapisów w tym okresie, różnicę wartości io_stall_read_ms i io_stall_write_ms, a następnie dzieli deltę io_stall_read_ms przez liczbę odczytów i deltę io_stall_write_ms liczba zapisów. Za pomocą tej metody obliczamy czas, przez jaki SQL Server czekał na I/O na odczyty lub zapisy, a następnie dzielimy go przez liczbę odczytów lub zapisów, aby określić opóźnienie.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Kiedy wykonujemy to, aby obliczyć opóźnienie podczas odbudowy indeksu, otrzymujemy następujące informacje:

Opóźnienie obliczone na podstawie sys.dm_io_virtual_file_stats podczas przebudowy indeksu dla EX_AdventureWorks2012
Teraz widzimy, że rzeczywiste opóźnienie w tym czasie było wysokie – czego byśmy się spodziewali. A gdybyśmy wrócili do normalnego obciążenia i uruchomili go przez kilka godzin, średnie wartości obliczone na podstawie wirtualnych statystyk plików zmniejszyłyby się z czasem. W rzeczywistości, jeśli spojrzymy na dane PerfMon, które zostały przechwycone podczas testu (a następnie przetworzone przez PAL), zobaczymy znaczące skoki wartości średniej. Dysk s/odczyt i śr. Dysk s/zapis, co jest skorelowane z czasem, w którym uruchomiono odbudowę indeksu. Ale w innych przypadkach wartości opóźnienia są znacznie poniżej akceptowalnych wartości:
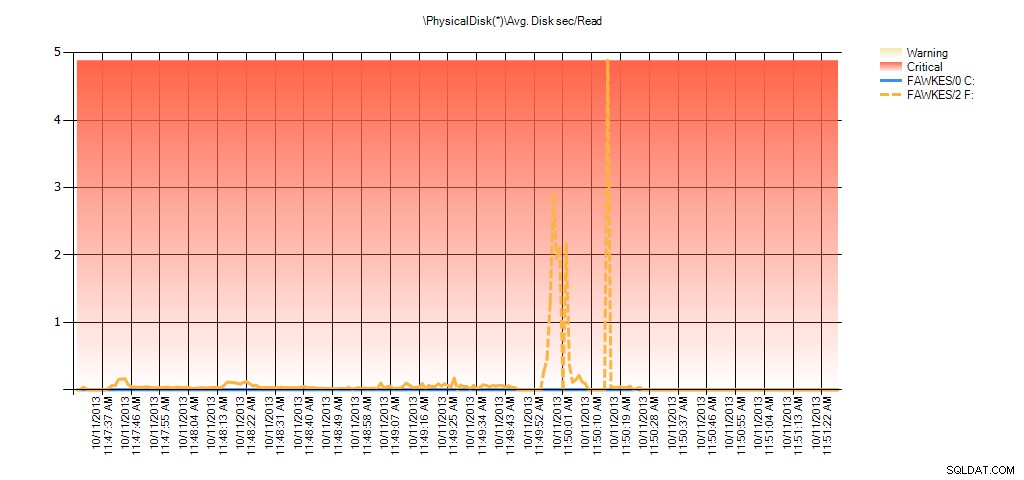
Podsumowanie średniego czasu/odczytu dysku z PAL dla EX_AdventureWorks2012 podczas testów
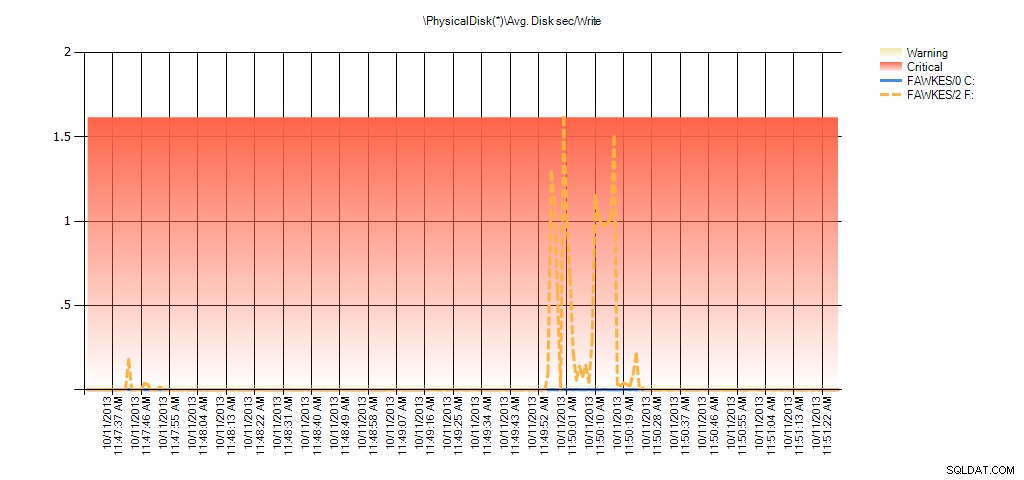
Podsumowanie średniej wartości dysku/zapisu z PAL dla EX_AdventureWorks2012 podczas testów
Możesz zobaczyć to samo zachowanie dla bazy danych BIG_AdventureWorks 2012. Oto informacje o opóźnieniach oparte na migawce statystyk pliku wirtualnego przed odbudową indeksu i po:

Opóźnienie obliczone na podstawie sys.dm_io_virtual_file_stats podczas przebudowy indeksu dla BIG_AdventureWorks2012
Dane z Monitora wydajności pokazują te same skoki podczas przebudowy:
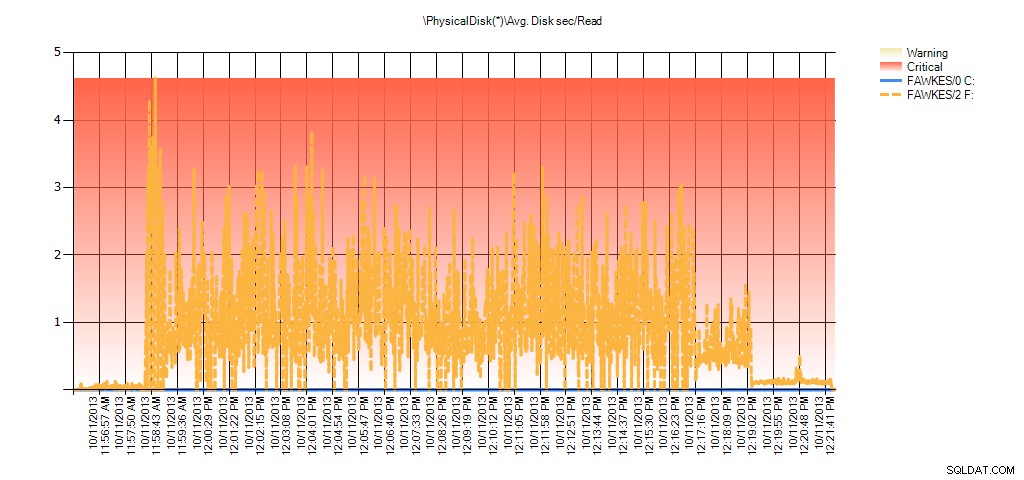
Podsumowanie średniego czasu/odczytu dysku z PAL dla BIG_AdventureWorks2012 podczas testów
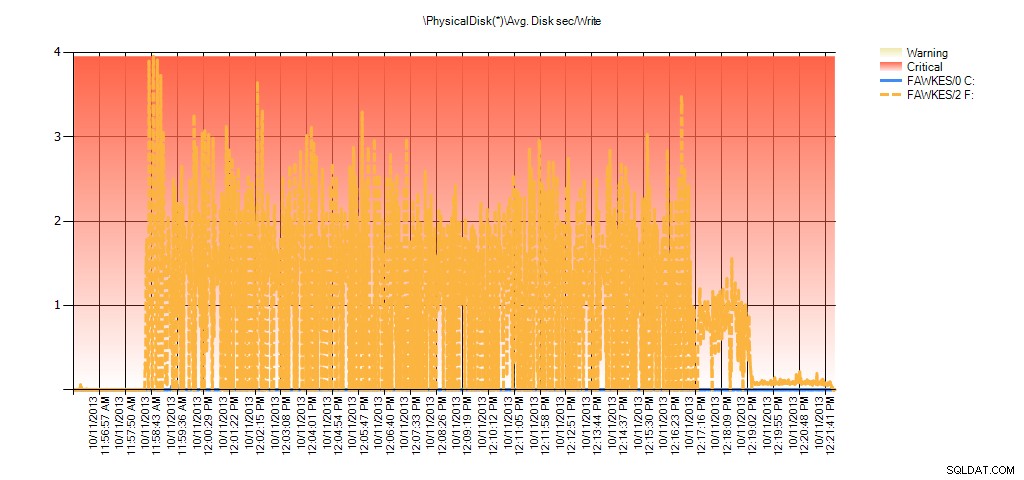
Podsumowanie średniego czasu/zapisu dysku z PAL dla BIG_AdventureWorks2012 podczas testów
Wniosek
Statystyki plików wirtualnych to doskonały punkt wyjścia, gdy chcesz poznać wydajność operacji we/wy dla instancji SQL Server. Jeśli widzisz oczekiwania związane z we/wy podczas przeglądania statystyk oczekiwania, logicznym następnym krokiem jest spojrzenie na sys.dm_io_virtual_file_stats. Pamiętaj jednak, że wyświetlane dane są zagregowane od ostatniego wyczyszczenia statystyk przez jedno z powiązanych zdarzeń (ponowne uruchomienie instancji, wyłączenie bazy danych itp.). Jeśli widzisz małe opóźnienia, oznacza to, że podsystem we/wy nadąża za obciążeniem wydajności. Jeśli jednak zauważysz duże opóźnienia, nie jest przesądzone, że przechowywanie jest problemem. Aby naprawdę wiedzieć, co się dzieje, możesz zacząć tworzyć migawki statystyk plików, jak pokazano tutaj, lub po prostu użyć Monitora wydajności, aby sprawdzić opóźnienia w czasie rzeczywistym. Bardzo łatwo jest utworzyć zestaw kolektorów danych w PerfMon, który przechwytuje liczniki dysku fizycznego Śr. s/odczyt dysku i śr. Disk Sec/Read dla wszystkich dysków, na których znajdują się pliki bazy danych. Zaplanuj regularne uruchamianie i zatrzymywanie modułu Data Collector oraz próbkowanie co n sekund (np. 15), a gdy już przechwycisz dane PerfMon przez odpowiedni czas, przeprowadź je przez PAL, aby zbadać opóźnienie w czasie.
Jeśli okaże się, że opóźnienie we/wy występuje podczas normalnego obciążenia pracą, a nie tylko podczas zadań konserwacyjnych, które sterują operacjami we/wy, nadal nie może wskazać przechowywania jako podstawowego problemu. Opóźnienie pamięci może mieć różne przyczyny, takie jak:
- SQL Server musi odczytać zbyt dużo danych w wyniku nieefektywnych planów zapytań lub brakujących indeksów
- Zbyt mało pamięci jest przydzielone do instancji i te same dane są wielokrotnie odczytywane z dysku, ponieważ nie mogą pozostać w pamięci
- Niejawne konwersje powodują skanowanie indeksów lub tabel
- Zapytania wykonują SELECT *, gdy nie wszystkie kolumny są wymagane
- Problemy z przekazywaniem rekordów w stosach powodują dodatkowe operacje we/wy
- Niska gęstość stron spowodowana fragmentacją indeksu, podziałami stron lub nieprawidłowymi ustawieniami współczynnika wypełnienia powoduje dodatkowe operacje we/wy
Bez względu na pierwotną przyczynę, najważniejsze, aby zrozumieć wydajność — szczególnie w odniesieniu do operacji we/wy — to fakt, że rzadko istnieje jeden punkt danych, którego można użyć do zidentyfikowania problemu. Znalezienie prawdziwego problemu wymaga wielu faktów, które połączone razem pomogą Ci odkryć problem.
Na koniec zwróć uwagę, że w niektórych przypadkach opóźnienie przechowywania może być całkowicie akceptowalne. Zanim zażądasz szybszego przechowywania lub zmian w kodzie, przejrzyj wzorce obciążenia i umowę dotyczącą poziomu usług (SLA) dla bazy danych. W przypadku hurtowni danych, która obsługuje raporty dla użytkowników, umowa SLA dla zapytań prawdopodobnie nie jest taka sama, jak w przypadku systemu OLTP o dużej objętości. W rozwiązaniu DW opóźnienia we/wy większe niż jedna sekunda mogą być całkowicie akceptowalne i oczekiwane. Zrozum oczekiwania firmy i jej użytkowników, a następnie określ, jakie działania podjąć, jeśli w ogóle. A jeśli wymagane są zmiany, zbierz dane ilościowe potrzebne do poparcia swojej argumentacji, a mianowicie statystyki oczekiwania, statystyki wirtualnych plików i opóźnienia z Monitora wydajności.