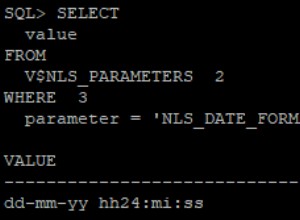
Wszyscy popełniamy błędy i wszyscy możemy uczyć się na błędach innych ludzi. W tym poście przyjrzymy się licznym zasobom online, aby uniknąć złego projektu bazy danych, który może prowadzić do wielu problemów i kosztować zarówno czas, jak i pieniądze. A w nadchodzącym artykule powiemy Ci, gdzie znaleźć wskazówki i najlepsze praktyki.
Błędy i błędy w projektowaniu bazy danych, których należy unikać
Istnieje wiele zasobów online, które pomagają projektantom baz danych uniknąć typowych błędów i pomyłek. Oczywiście ten artykuł nie jest wyczerpującą listą wszystkich dostępnych artykułów. Zamiast tego sprawdziliśmy i skomentowaliśmy wiele różnych źródeł, abyś mógł znaleźć to, które najbardziej Ci odpowiada.
Nasza rekomendacja
Jeśli wśród tych zasobów jest tylko jeden artykuł, który zamierzasz przeczytać, powinien to być „Jak uzyskać strasznie niepoprawny projekt bazy danych” od Roberta Sheldona
Zacznijmy od bloga DATAVERSITY, który zawiera szeroki zestaw całkiem dobrych zasobów:
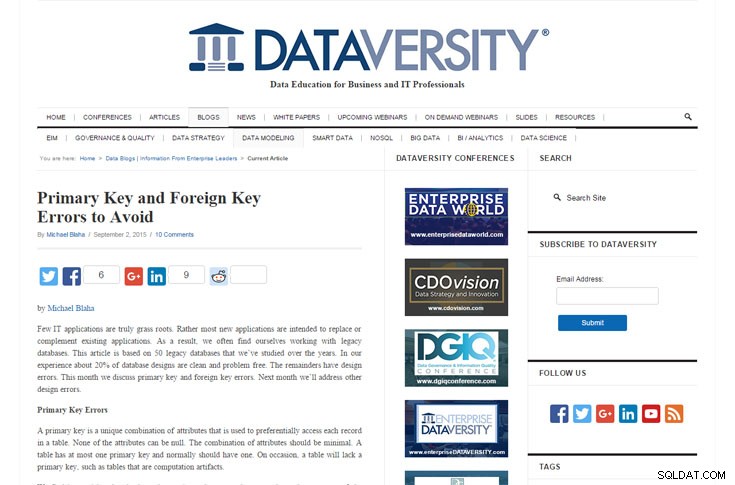
Błędy klucza podstawowego i obcego, których należy unikać
Michael Blaha | Blog DATAVERSITY | 2 września 2015
Więcej błędów projektowania bazy danych – zamieszanie z relacjami wiele-do-wielu
Michael Blaha | Blog DATAVERSITY | 30 września 2015
Różne błędy projektowania bazy danych
Michael Blaha | Blog DATAVERSITY | 26 października 2015
Michael Blaha napisał ładny zestaw trzech artykułów. Każdy artykuł dotyczy różnych pułapek modelowania baz danych i projektowania fizycznego; tematy obejmują klucze, relacje i ogólne błędy. Ponadto trwają dyskusje z Michaelem dotyczące niektórych punktów. Jeśli szukasz pułapek związanych z kluczami i relacjami, będzie to dobre miejsce na rozpoczęcie.
Blaha stwierdza, że „około 20% baz danych narusza zasady klucza podstawowego”. Wow! Oznacza to, że około 20% programistów baz danych nie tworzyło prawidłowo kluczy podstawowych. Jeśli ta statystyka jest prawdziwa, to naprawdę pokazuje znaczenie narzędzi do modelowania danych, które silnie „zachęcają” lub nawet wymagają od modelarzy zdefiniowania kluczy podstawowych.
Pan Blaha podziela również heurystykę, że „około 50% baz danych” ma problemy z kluczem obcym (zgodnie z jego doświadczeniem ze starszymi bazami danych, które badał). Przypomina nam, aby unikać nieformalnych powiązań między tabelami poprzez osadzenie wartości z jednej tabeli w drugiej, zamiast używania klucza obcego.
Wielokrotnie widziałem ten problem. Przyznaję, że nieformalne powiązanie może być wymagane przez funkcjonalność, która ma być zaimplementowana, ale częściej dzieje się to z powodu zwykłego lenistwa. Na przykład możemy chcieć pokazać identyfikator użytkownika kogoś, kto coś zmodyfikował, więc przechowujemy identyfikator użytkownika bezpośrednio w tabeli. Ale co, jeśli ten użytkownik zmieni swój identyfikator użytkownika? Wtedy ten nieformalny link jest uszkodzony. Jest to często spowodowane złym projektem i modelowaniem.
Projektowanie bazy danych:5 najważniejszych błędów, których należy unikać
przez Henrique Netzka | Blog DATAVERSITY | 2 listopada 2015
Byłem trochę rozczarowany tym artykułem, ponieważ zawierał kilka dość specyficznych pozycji (protokół przechowywania w CLOB) i kilka bardzo ogólnych (pomyśl o lokalizacji). Ogólnie rzecz biorąc, artykuł jest w porządku, ale czy to naprawdę 5 najważniejszych błędów, których należy unikać? Moim zdaniem istnieje kilka innych typowych błędów, które powinny znaleźć się na liście.
Jednak pozytywnie, jest to jeden z nielicznych artykułów, w których w jakikolwiek znaczący sposób wspomina się o globalizacji i lokalizacji. Pracuję w bardzo wielojęzycznym środowisku i widziałem kilka okropnych wdrożeń lokalizacji, więc ucieszyłem się, że wspomniałem o tym problemie. Kolumny językowe i kolumny stref czasowych mogą wydawać się oczywiste, ale bardzo rzadko pojawiają się w modelach baz danych.
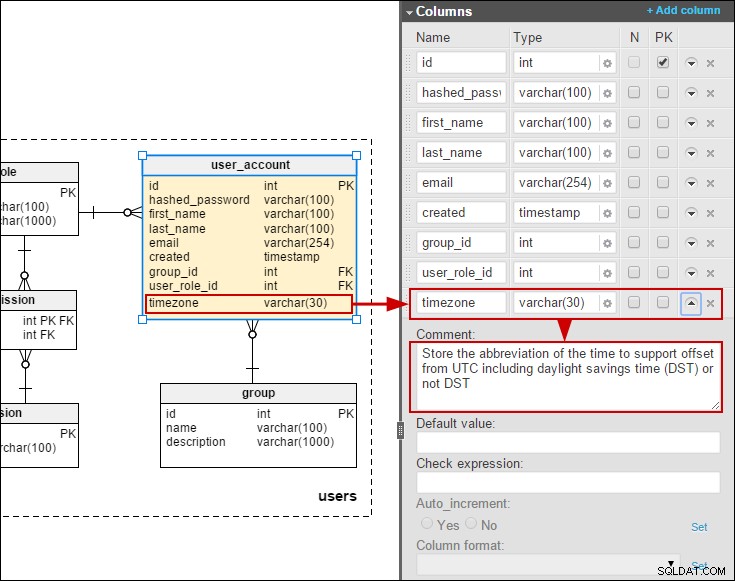
Biorąc to pod uwagę, pomyślałem, że byłoby interesujące stworzyć model zawierający tłumaczenia, które mogą być zmieniane przez użytkowników końcowych (w przeciwieństwie do korzystania z pakietów zasobów). Jakiś czas temu pisałem o modelu do internetowej bazy ankiet. Tutaj zamodelowałem uproszczone tłumaczenie pytań i odpowiedzi:
Zakładając, że musimy umożliwić użytkownikom końcowym utrzymanie tłumaczeń, preferowaną metodą byłoby dodanie tabel tłumaczeń dla pytań i odpowiedzi:
Dodałem również strefę czasową do user_account tabelę, dzięki której możemy przechowywać daty/godziny w czasie lokalnym użytkowników:
7 typowych błędów projektowania bazy danych
Grzegorz Kaczor | Blog Vertabelo | 17 lipca 2015
Zrobię tu małą autopromocję. Staramy się regularnie publikować tutaj interesujące i angażujące artykuły.
W tym konkretnym artykule wskazano kilka ważnych obszarów, takich jak nazewnictwo, indeksowanie, kwestie dotyczące objętości i ścieżki audytu. Artykuł porusza nawet kwestie związane z konkretnymi systemami DBM, takimi jak ograniczenia Oracle dotyczące nazw tabel. Naprawdę lubię ładne, jasne przykłady, nawet jeśli ilustrują, w jaki sposób projektanci popełniają błędy i błędy.
Oczywiście nie można wymienić wszystkich błędów projektowych, a te wymienione mogą nie być twoje najczęstsze błędy. Kiedy piszemy o typowych błędach, czerpiemy z tych, które popełniliśmy lub znaleźliśmy w pracy innych. Kompletna lista błędów, uszeregowana pod względem częstotliwości, byłaby niemożliwa do skompilowania przez pojedynczą osobę. Niemniej jednak myślę, że ten artykuł zawiera kilka przydatnych informacji na temat potencjalnych pułapek. Ogólnie rzecz biorąc, jest to dobry, solidny zasób.
Podczas gdy pan Kaczor porusza kilka interesujących punktów w swoim artykule, jego komentarze dotyczące „nie brania pod uwagę możliwego natężenia ruchu” są dość interesujące. Szczególnie istotne jest zalecenie oddzielenia często wykorzystywanych danych od danych historycznych. Jest to rozwiązanie, którego często używamy w naszych aplikacjach do przesyłania wiadomości; musimy mieć przeszukiwalną historię wszystkich wiadomości, ale wiadomości, do których najprawdopodobniej uzyskamy dostęp, to te, które zostały opublikowane w ciągu ostatnich kilku dni. Tak więc dzielenie „aktywnych” lub najnowszych danych, które są często używane (znacznie mniejsza ilość danych) od długoterminowych danych historycznych (duża masa danych) jest ogólnie bardzo dobrą techniką.
Częste błędy w projektowaniu bazy danych
Troy Blake | Starszy blog DBA | 11 lipca 2015
Artykuł Troya Blake'a jest kolejnym dobrym źródłem informacji, chociaż mogłem zmienić jego nazwę na „Powszechne błędy projektowania serwera SQL”.
Na przykład mamy komentarz:„procedury składowane są twoim najlepszym przyjacielem, jeśli chodzi o efektywne wykorzystanie SQL Server”. To dobrze, ale czy jest to powszechny błąd ogólny, czy jest bardziej specyficzny dla SQL Server? Musiałbym zdecydować się na to, aby było to trochę specyficzne dla SQL Server, ponieważ korzystanie z procedur składowanych ma wady, takie jak kończenie się procedurami składowanymi specyficznymi dla dostawcy, a tym samym uzależnienie od dostawcy. Dlatego nie jestem fanem umieszczania na tej liście „Nie używaj procedur zapisanych”.
Jednak z drugiej strony myślę, że autor zidentyfikował kilka bardzo powszechnych błędów, takich jak słabe planowanie, tandetny projekt systemu, ograniczona dokumentacja, słabe standardy nazewnictwa i brak testów.
Sklasyfikowałbym to więc jako bardzo przydatne źródło informacji dla praktyków SQL Server i przydatne dla innych.
Siedem błędów modelowania danych
Kurt Cagle | LinkedIn | 12 czerwca 2015
Naprawdę podobało mi się czytanie listy błędów modelowania bazy danych pana Cagle'a. Pochodzą one z punktu widzenia architekta baz danych; wyraźnie identyfikuje błędy modelowania wyższego poziomu, których należy unikać. Dzięki temu większemu widokowi obrazu możesz przerwać potencjalny bałagan w modelowaniu.
Niektóre z typów wymienionych w artykule można znaleźć gdzie indziej, ale kilka z nich jest wyjątkowych:zbyt wczesne abstrahowanie lub mieszanie modeli koncepcyjnych, logicznych i fizycznych. Nie są one często wymieniane przez innych autorów, prawdopodobnie dlatego, że koncentrują się na procesie modelowania danych, a nie na większym widoku systemu.
W szczególności przykład „Zbyt abstrakcyjne zbyt wczesne” opisuje interesujący proces myślowy polegający na tworzeniu przykładowych „historii” i testowaniu, które relacje są ważne w tej dziedzinie. Skupia to myślenie na relacjach między modelowanymi obiektami. Powoduje to pytania typu jakie są ważne relacje w tej domenie ?
Opierając się na tym zrozumieniu, tworzymy model wokół relacji, a nie zaczynamy od poszczególnych elementów domeny i budujemy na nich relacje. Chociaż wielu z nas może stosować takie podejście, wśród tych zasobów żaden inny autor nie skomentował tego. Ten opis i przykłady są dla mnie dość interesujące.
Jak źle projektować bazę danych
Robert Sheldon | Prosta rozmowa | 6 marca 2015
Jeśli wśród tych zasobów jest tylko jeden artykuł, który zamierzasz przeczytać, powinien to być ten autorstwa Roberta Sheldona
To, co naprawdę podoba mi się w tym artykule, to to, że dla każdego z wymienionych błędów znajdują się wskazówki, jak zrobić to dobrze. Większość z nich skupia się na unikaniu niepowodzenia, a nie na naprawieniu go, ale nadal uważam, że są one bardzo przydatne. Jest tu bardzo mało teorii; w większości proste odpowiedzi na temat unikania błędów podczas modelowania danych. Istnieje kilka konkretnych punktów dotyczących SQL Server, ale głównie SQL Server służy do dostarczania przykładów unikania błędów lub sposobów wyjścia z awarii.
Zakres artykułu jest również dość szeroki:obejmuje zaniedbywanie planowania, nie zawracanie sobie głowy dokumentacją, używanie kiepskich konwencji nazewnictwa, problemy z normalizacją (za dużo lub za mało), nieudane klucze i ograniczenia, nieprawidłowe indeksowanie i wykonywanie niewystarczające testy.
Szczególnie spodobały mi się praktyczne porady dotyczące integralności danych – kiedy stosować ograniczenia sprawdzające, a kiedy definiować klucze obce. Ponadto pan Sheldon opisuje również sytuację, w której zespoły odraczają zastosowanie aplikacji w celu wymuszenia integralności. Ma rację, gdy stwierdza, że do bazy danych można uzyskać dostęp na wiele sposobów i za pomocą wielu aplikacji. Stwierdza, że „dane powinny być chronione tam, gdzie się znajdują:w bazie danych”. Jest to tak prawdziwe, że można to powtórzyć zespołom programistycznym i menedżerom, aby wyjaśnić znaczenie wdrażania kontroli integralności w modelu danych.
To jest mój rodzaj artykułu i można powiedzieć, że inni się zgadzają na podstawie licznych komentarzy, które go popierają. Tak więc najwyższe oceny tutaj; jest to bardzo cenny zasób.
Dziesięć typowych błędów w projektowaniu baz danych
Louis Davidson | Prosta rozmowa | 26 lutego 2007
Ten artykuł wydał mi się całkiem dobry, ponieważ zawierał wiele typowych błędów projektowych. Były znaczące analogie, przykłady, modele, a nawet klasyczne cytaty z Williama Szekspira i J.R.R. Tolkiena.
Kilka błędów zostało wyjaśnionych bardziej szczegółowo niż inne, z długimi przykładami i fragmentami SQL, które okazały się nieco niewygodne. Ale to kwestia gustu.
Ponownie mamy kilka tematów dotyczących SQL Server. Na przykład niekorzystanie z procedur przechowywanych w celu uzyskania dostępu do danych jest dobre dla SQL, ale SP nie zawsze jest dobrym pomysłem, gdy celem jest obsługa wielu DBMS. Ponadto ostrzegamy przed próbami kodowania ogólnych obiektów T-SQL. Ponieważ rzadko pracuję z SQL Server lub Sybase, ta wskazówka nie była dla mnie odpowiednia.
Lista jest dość podobna do listy Roberta Sheldona, ale jeśli pracujesz głównie na SQL Server, znajdziesz kilka dodatkowych bryłek informacji.
Pięć prostych błędów projektowania bazy danych, których należy unikać
Autor:Anith Sen Larson | Prosta rozmowa | 16 października 2009
Ten artykuł zawiera kilka znaczących przykładów dla każdego z prostych błędów projektowych, które obejmuje. Z drugiej strony skupia się raczej na podobnych typach błędów:typowych tabelach przeglądowych, tabelach jednostka-atrybut-wartość i dzieleniu atrybutów.
Obserwacje są w porządku, a artykuł zawiera nawet odniesienia, które są rzadkością. Mimo to chciałbym zobaczyć bardziej ogólne błędy projektowania bazy danych. Błędy te wydawały się dość specyficzne, ale, jak już napisałem, błędy, o których piszemy, to na ogół te, z którymi mamy osobiste doświadczenia.
Jedną z rzeczy, która mi się podobała, była konkretna zasada dotycząca decydowania, kiedy użyć ograniczenia sprawdzającego, a kiedy oddzielnej tabeli z ograniczeniem klucza obcego. Kilku autorów przedstawia podobne zalecenia, ale Larson dzieli je na „konieczność”, „rozważenie” i „mocne argumenty” – przyznając, że „projektowanie jest mieszanką sztuki i nauki, a zatem wiąże się z kompromisami”. Uważam to za bardzo prawdziwe.
Dziesięć najczęstszych błędów w projektowaniu fizycznej bazy danych
Craig Mullins | Dane i technologia dzisiaj | 5 sierpnia 2013
Jak sama nazwa wskazuje, „Dziesięć najczęstszych błędów w projektowaniu fizycznej bazy danych” jest nieco bardziej zorientowane na projektowanie fizyczne niż na projektowanie logiczne i koncepcyjne. Żaden z błędów, o których wspomina autor Craig Mullins, nie wyróżnia się ani nie jest wyjątkowy, dlatego polecam tę informację osobom zajmującym się fizyczną stroną DBA.
Ponadto opisy są nieco krótkie, więc czasami trudno jest zrozumieć, dlaczego konkretny błąd będzie sprawiał problemy. Nie ma nic złego w krótkich opisach, ale nie dają one wiele do myślenia. I nie przedstawiono żadnych przykładów.
Podniesiono jedną interesującą kwestię dotyczącą braku udostępniania danych. Ten punkt jest czasami wspominany w innych artykułach, ale nie jako błąd projektowy. Jednak widzę ten problem dość często, gdy bazy danych są „odtwarzane” w oparciu o bardzo podobne wymagania, ale przez nowy zespół lub dla nowego produktu
.Często zdarza się, że zespół produktowy uświadamia sobie później, że wolałby wykorzystać dane, które były już obecne w „ojcu” ich aktualnej bazy danych. W rzeczywistości jednak powinni byli raczej wzmocnić rodzica niż tworzyć nowe potomstwo. Aplikacje mają na celu udostępnianie danych; dobry projekt może pozwolić na częstsze ponowne wykorzystanie bazy danych.
Czy popełniasz 5 błędów w projektowaniu bazy danych?
Thomas Larock | Blog Thomasa Larocka | 2 stycznia 2012
Możesz znaleźć kilka interesujących punktów, gdy odpowiesz na pytanie Thomasa Larocka:Czy popełniasz te 5 błędów w projektowaniu baz danych?
Ten artykuł jest nieco mocno obciążony kluczami (klucze obce, klucze zastępcze i klucze wygenerowane). Jednak ma jeden ważny punkt:nie należy zakładać, że funkcje DBMS są takie same we wszystkich systemach. Myślę, że to bardzo dobry punkt. Jest to również taki, którego nie można znaleźć w większości innych artykułów, być może dlatego, że wielu autorów koncentruje się i pracuje głównie z pojedynczym DBMS.
Projektowanie bazy danych:7 rzeczy, których nie chcesz robić
Thomas Larock | Blog Thomasa Larocka | 16 stycznia 2013
Pan Larock przetworzył kilka swoich „5 błędów w projektowaniu bazy danych”, pisząc „7 rzeczy, których nie chcesz robić”, ale są tutaj inne dobre strony.
Co ciekawe, niektórych punktów, które wysuwa pan Larock, nie można znaleźć w wielu innych źródłach. Dostajesz kilka dość unikalnych obserwacji, takich jak „nie mając żadnych oczekiwań dotyczących wydajności”. To poważny błąd, który z mojego doświadczenia wynika, że zdarza się dość często. Nawet przy tworzeniu kodu aplikacji często już po stworzeniu modelu danych, bazy danych i samej aplikacji ludzie zaczynają myśleć o wymaganiach niefunkcjonalnych (kiedy muszą powstać testy niefunkcjonalne) i zaczynają definiować oczekiwania wydajnościowe .
I odwrotnie, jest kilka punktów, których nie umieściłbym na mojej własnej liście Top Ten, takich jak „na wszelki wypadek”. Rozumiem, o co chodzi, ale nie znajduje się on tak wysoko na mojej liście podczas tworzenia modelu danych. Nie ma specyfiki dla konkretnego systemu DBM, więc jest to bonus.
Podsumowując, wiele z tych punktów można ująć w punkcie:„niezrozumienie wymagań”, który tak naprawdę znajduje się na mojej liście 10 najczęstszych błędów.
Jak uniknąć 8 typowych błędów w tworzeniu baz danych
Base36 | 6 grudnia 2012
Byłem bardzo zainteresowany przeczytaniem tego artykułu. Byłem jednak trochę rozczarowany. Nie ma zbyt wielu dyskusji na temat unikania, a punkt artykułu naprawdę wydaje się brzmieć „są to powszechne błędy bazy danych” i „dlaczego są to błędy”; opisy sposobów uniknięcia błędu są mniej widoczne.
Ponadto niektóre z 8 najważniejszych błędów artykułu są faktycznie kwestionowane. Przykładem jest niewłaściwe użycie klucza podstawowego. Base36 mówi nam, że muszą być generowane przez system, a nie na podstawie danych aplikacji w wierszu. Chociaż do pewnego stopnia się z tym zgadzam, nie jestem przekonany, że wszystkie PK powinny zawsze być generowane; to trochę zbyt kategoryczne.
Z drugiej strony błąd „twardych usunięć” jest interesujący i nieczęsto wspominany gdzie indziej. Nietrwałe usuwanie powoduje inne problemy, ale prawdą jest, że samo oznaczenie wiersza jako nieaktywnego ma swoje zalety, gdy próbujesz dowiedzieć się, dokąd trafiły te dane, które były w systemie wczoraj. Przeszukiwanie dzienników transakcji nie jest moim pomysłem na przyjemny sposób na spędzenie dnia.
Siedem grzechów głównych projektowania baz danych
Jason Tiret | Dziennik systemów korporacyjnych | 16 lutego 2010
Miałem dużą nadzieję, kiedy zacząłem czytać artykuł Jasona Tireta „Siedem grzechów głównych projektowania baz danych”. Ucieszyłem się więc, że nie tylko powtarza błędy, które można znaleźć w wielu innych artykułach. Wręcz przeciwnie, oferował „grzech”, którego nie znalazłem na innych listach:próba wykonania całego projektu bazy danych „z góry” i nieaktualizowanie modelu po uruchomieniu bazy danych, gdy w bazie są wprowadzane zmiany. (Lub, jak to ujął Jason, „Nie traktować modelu danych jak żywego, oddychającego organizmu”).
Wielokrotnie widziałem ten błąd. Większość ludzi uświadamia sobie swój błąd dopiero wtedy, gdy muszą dokonać aktualizacji modelu, który nie pasuje już do rzeczywistej bazy danych. Oczywiście rezultatem jest bezużyteczny model. Jak stwierdzono w artykule, „zmiany muszą znaleźć drogę z powrotem do modelu”.
Z drugiej strony większość elementów listy Jasona jest dość dobrze znana. Opisy są dobre, ale nie ma zbyt wielu przykładów. Przydałoby się więcej przykładów i szczegółów.
Najczęstsze błędy w projektowaniu baz danych
Brian Prince | eWeek.com | 19 marca 2008

Artykuł „Najczęstsze błędy projektowania bazy danych” to w rzeczywistości seria slajdów z prezentacji. Jest kilka ciekawych przemyśleń, ale niektóre z unikalnych przedmiotów są być może nieco ezoteryczne. Mam na myśli punkty takie jak „Poznaj RAID” i zaangażowanie interesariuszy.
Ogólnie rzecz biorąc, nie umieściłbym tego na twojej liście lektur, chyba że skupisz się na ogólnych kwestiach (planowanie, nazewnictwo, normalizacja, indeksy) i szczegółach fizycznych.
10 typowych błędów projektowych
autor:davidm | Blogi dotyczące SQL Server – SQLTeam.com | 12 września 2005
Niektóre punkty w „Dziesięciu typowych błędów projektowych” są interesujące i stosunkowo nowe. Jednak niektóre z tych błędów są dość kontrowersyjne, takie jak „używanie wartości NULL” i denormalizacja.
Zgadzam się, że tworzenie wszystkich kolumn jako dopuszczających wartość null jest błędem, ale zdefiniowanie kolumny jako dopuszczającej wartość null może być wymagane dla określonej funkcji biznesowej. Czy zatem można to uznać za błąd ogólny? Myślę, że nie.
Inną kwestią, z którą mam problem, jest denormalizacja. Nie zawsze jest to błąd projektowy. Na przykład denormalizacja może być wymagana ze względu na wydajność.
W tym artykule również w dużej mierze brakuje szczegółów i przykładów. Rozmowy między DBA a programistą lub menedżerem są zabawne, ale wolałbym bardziej konkretne przykłady i szczegółowe uzasadnienia tych typowych błędów.
OTLT i EAV:dwa duże błędy projektowe, które popełniają wszyscy początkujący
Tony Andrews | Tony Andrews o Oracle i bazach danych | 21 października 2004
Artykuł pana Andrewsa przypomina nam o błędach „One True Lookup Table” (OTLT) i Entity-Attribute-Value (EAV), o których wspomniano w innych artykułach. Miłym punktem tej prezentacji jest to, że skupia się na tych dwóch błędach, więc opisy i przykłady są precyzyjne. Ponadto podano możliwe wyjaśnienie, dlaczego niektórzy projektanci wdrażają OTLT i EAV.
Aby przypomnieć, tabela OTLT zwykle wygląda mniej więcej tak, z wpisami z wielu domen wrzuconymi do tej samej tabeli:
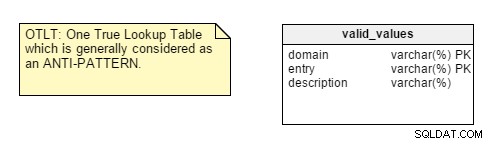
Jak zwykle toczy się dyskusja na temat tego, czy OTLT jest wykonalnym rozwiązaniem i dobrym wzorcem projektowym. Muszę powiedzieć, że jestem po stronie grupy anty-OTLT; tabele te wprowadzają liczne problemy. Możemy użyć analogii do używania pojedynczego enumeratora do reprezentowania wszystkich możliwych wartości wszystkich możliwych stałych. Jak dotąd nigdy tego nie widziałem.
Częste błędy bazy danych
John Paul Ashenfelter | Dr Dobb's | 01 stycznia 2002
Artykuł pana Ashenfeltera wymienia aż 15 typowych błędów baz danych. Jest nawet kilka błędów, o których nie wspomina się często w innych artykułach. Niestety opisy są stosunkowo krótkie i nie ma przykładów. Zaletą tego artykułu jest to, że lista obejmuje wiele podstaw i może być używana jako „lista kontrolna” błędów, których należy unikać. Chociaż mogę nie sklasyfikować ich jako najważniejszych błędów bazy danych, z pewnością należą one do najczęstszych.
Pozytywnie, jest to jeden z nielicznych artykułów, w których wspomniano o potrzebie obsługi internacjonalizacji formatów danych, takich jak data, waluta i adres. Przydałby się tutaj przykład. Może to być tak proste, jak „upewnij się, że State jest kolumną dopuszczającą wartość null; w wielu krajach nie ma stanu powiązanego z adresem”.
Wcześniej w tym artykule wspomniałem o innych problemach i niektórych podejściach do przygotowania się do globalizacji bazy danych, takich jak strefy czasowe i tłumaczenia (lokalizacja). Niepokojący jest fakt, że żaden inny artykuł nie wspomina o problemie formatów waluty i daty. Czy nasze bazy danych są przygotowane do globalnego użytkowania naszych aplikacji?
Honorowe wzmianki
Oczywiście istnieją inne artykuły opisujące typowe błędy i błędy w projektowaniu baz danych, ale chcieliśmy przedstawić szeroki przegląd różnych zasobów. Dodatkowe informacje można znaleźć w artykułach takich jak:
10 typowych błędów w projektowaniu baz danych | Blog klasowy MIS | 29 stycznia 2012
10 typowych błędów w projektowaniu baz danych | IDG.se | 24 czerwca 2010
Zasoby internetowe:od czego zacząć? Gdzie iść?
Jak wcześniej wspomniano, ta lista zdecydowanie nie jest wyczerpującą analizą każdego artykułu online opisującego błędy i błędy w projektowaniu baz danych. Zidentyfikowaliśmy raczej kilka źródeł, które są szczególnie przydatne lub skupiają się na konkretnym aspekcie, który może okazać się przydatny.
Zachęcamy do polecania dodatkowych artykułów.