Jednym z wielu ulepszeń planów wykonania w SQL Server 2012 było dodanie rezerwacji wątków i informacji o użyciu dla planów wykonania równoległego. Ten post pokazuje dokładnie, co oznaczają te liczby, i zapewnia dodatkowy wgląd w zrozumienie wykonywania równoległego.
Rozważ następujące zapytanie uruchomione w powiększonej wersji bazy danych AdventureWorks:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Optymalizator zapytań wybiera równoległy plan wykonania:
Eksplorator planu pokazuje szczegóły użycia wątków równoległych w podpowiedziach węzła głównego. Aby zobaczyć te same informacje w SSMS, kliknij węzeł główny planu, otwórz okno Właściwości i rozwiń ThreadStat węzeł. Używając maszyny z ośmioma procesorami logicznymi dostępnymi dla SQL Server, informacje o wykorzystaniu wątków z typowego przebiegu tego zapytania są pokazane poniżej, Eksplorator planów po lewej, widok SSMS po prawej:
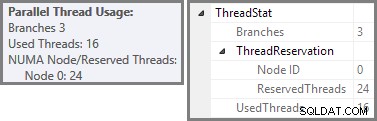
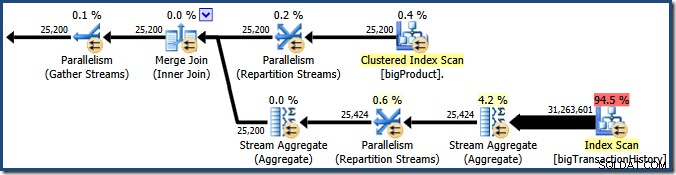
Zrzut ekranu pokazuje, że silnik wykonawczy zarezerwował 24 wątki dla tego zapytania i zakończył korzystanie z 16 z nich. Pokazuje również, że plan zapytań ma trzy gałęzie , chociaż nie mówi dokładnie, czym jest gałąź. Jeśli przeczytałeś mój artykuł Simple Talk na temat równoległego wykonywania zapytań, będziesz wiedział, że gałęzie są sekcjami równoległego planu zapytań ograniczone operatorami wymiany. Poniższy diagram przedstawia granice i numeruje gałęzie (kliknij, aby powiększyć):

Oddział drugi (pomarańczowy)
Przyjrzyjmy się najpierw gałęzi drugiej bardziej szczegółowo:
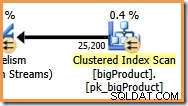
Przy stopniu równoległości (DOP) wynoszącym osiem, istnieje osiem wątków działających w tej gałęzi planu zapytań. Ważne jest, aby zrozumieć, że to jest cały plan wykonania jeśli chodzi o te osiem wątków – nie mają wiedzy o szerszym planie.
W planie wykonania szeregowego pojedynczy wątek odczytuje dane ze źródła danych, przetwarza wiersze za pomocą wielu operatorów planu i zwraca wyniki do miejsca docelowego (może to być na przykład okno wyników zapytania SSMS lub tabela bazy danych).
W oddziale równoległego planu wykonania sytuacja jest bardzo podobna:każdy wątek odczytuje dane ze źródła, przetwarza wiersze za pomocą wielu operatorów planu i zwraca wyniki do miejsca docelowego. Różnice polegają na tym, że miejscem docelowym jest operator wymiany (równoległości), a źródłem danych może być również wymiana.
W pomarańczowej gałęzi źródłem danych jest Clustered Index Scan, a miejscem docelowym jest prawa strona wymiany strumieni podziału. Prawa strona giełdy nazywana jest stroną producenta , ponieważ łączy się z gałęzią, która dodaje dane do giełdy.
Osiem wątków w pomarańczowym odgałęzieniu współpracuje, aby przeskanować tabelę i dodać wiersze do giełdy. Giełda składa wiersze w pakiety o rozmiarze strony. Gdy pakiet jest pełny, jest przepychany przez centralę na drugą stronę. Jeśli wymiana ma inny pusty pakiet dostępny do wypełnienia, proces jest kontynuowany, dopóki wszystkie wiersze źródła danych nie zostaną przetworzone (lub w wymianie zabraknie pustych pakietów).
Możemy zobaczyć liczbę wierszy przetworzonych w każdym wątku za pomocą widoku drzewa planów w Eksploratorze planów:
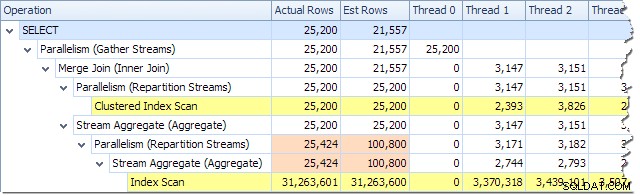
Eksplorator planów ułatwia sprawdzenie, jak wiersze są rozłożone w wątkach dla wszystkich fizyczne operacje w planie. W SSMS możesz zobaczyć rozkład wierszy dla jednego operatora planu. Aby to zrobić, kliknij ikonę operatora, otwórz okno Właściwości, a następnie rozwiń węzeł Rzeczywista liczba wierszy. Poniższa grafika przedstawia informacje SSMS dla węzła Strumienie repartycji na granicy między pomarańczowymi i fioletowymi gałęziami:
Oddział trzeci (zielony)
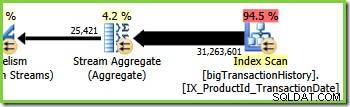
Gałąź trzecia jest podobna do gałęzi drugiej, ale zawiera dodatkowy operator Stream Aggregate. Zielona gałąź ma również osiem wątków, co daje w sumie szesnaście widocznych do tej pory. Osiem zielonych wątków odczytuje dane z nieklastrowego skanowania indeksu, dokonuje pewnego rodzaju agregacji i przekazuje wyniki do strony producenta innej wymiany strumieni repartycji.
Etykietka narzędzia Eksplorator planu dla Stream Aggregate pokazuje, że grupuje się według identyfikatora produktu i oblicza wyrażenie oznaczone jako partialagg1005 :
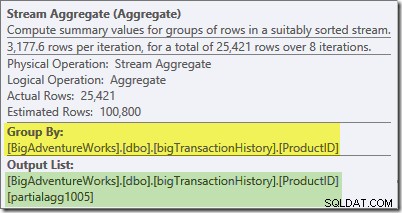
Karta Wyrażenia pokazuje, że wyrażenie jest wynikiem zliczenia wierszy w każdej grupie:

Stream Aggregate oblicza częściowy (znany również jako agregat „lokalny”). Kwalifikator częściowy (lub lokalny) oznacza po prostu, że każdy wątek oblicza agregację w widzianych wierszach. Wiersze ze skanowania indeksu są rozdzielane między wątki przy użyciu schematu opartego na zapotrzebowaniu:nie ma ustalonego rozkładu wierszy z wyprzedzeniem; wątki otrzymują szereg wierszy ze skanowania, gdy o nie proszą. Które wiersze kończą się na których wątkach są zasadniczo losowe, ponieważ zależy to od problemów z czasem i innych czynników.
Każdy wątek widzi różne wiersze ze skanu, ale wiersze z tym samym identyfikatorem produktu może być widoczny dla więcej niż jednego wątku. Suma jest „częściowa”, ponieważ sumy częściowe dla określonej grupy identyfikatorów produktów mogą pojawiać się w więcej niż jednym wątku; jest „lokalny”, ponieważ każdy wątek oblicza swój wynik tylko na podstawie wierszy, które otrzymuje. Załóżmy na przykład, że w tabeli jest 1000 wierszy dla identyfikatora produktu nr 1. Jeden wątek może zobaczyć 432 z tych wierszy, podczas gdy inny może zobaczyć 568. Oba wątki będą miały częściowe liczba wierszy dla produktu ID #1 (432 w jednym wątku, 568 w drugim).
Agregacja częściowa to optymalizacja wydajności, ponieważ zmniejsza liczbę wierszy wcześniej, niż byłoby to możliwe w innym przypadku. W zielonej gałęzi wczesna agregacja skutkuje łączeniem mniejszej liczby wierszy w pakiety i przekazywaniem ich przez giełdę Repartition Stream.
Oddział 1 (fioletowy)

Fioletowa gałąź ma jeszcze osiem nitek, co daje jak dotąd dwadzieścia cztery. Każdy wątek w tej gałęzi odczytuje wiersze z dwóch giełd Repartition Streams i zapisuje wiersze do wymiany Gather Streams. Ta gałąź może wydawać się skomplikowana i nieznana, ale to po prostu odczytywanie wierszy ze źródła danych i wysyłanie wyników do miejsca docelowego, jak każdy inny plan zapytań.
Prawa strona planu pokazuje dane odczytywane z drugiej strony dwóch wymian strumieni podziału widocznych w pomarańczowej i zielonej gałęzi. Ta (lewa) strona giełdy jest znana jako konsument z boku, ponieważ dołączone tu wątki czytają (zużywają) wiersze. Osiem fioletowych wątków gałęzi to konsumenci danych na dwóch wymianach strumieni repartycji.
Lewa strona fioletowej gałęzi pokazuje wiersze zapisywane do producenta stronie wymiany Gather Streams. te same osiem wątków (czyli konsumenci na giełdach Repartition Streams) wykonują producenta rolę tutaj.
Każdy wątek w fioletowej gałęzi uruchamia każdy operator w gałęzi, tak jak pojedynczy wątek wykonuje każdą operację w planie wykonania szeregowego. Główna różnica polega na tym, że jednocześnie działa osiem wątków, z których każdy pracuje w innym rzędzie w dowolnym momencie, używając różnych instancji operatorów planu zapytań.
Stream Aggregate w tej gałęzi jest globalny agregat. Łączy częściowe (lokalne) agregaty obliczone w zielonej gałęzi (przypomnij sobie przykład liczby 432 w jednym wątku i 568 w drugim), aby uzyskać łączną sumę dla każdego identyfikatora produktu. Etykietka narzędzia Eksplorator planu pokazuje globalne wyrażenie wynikowe, oznaczone Expr1004:
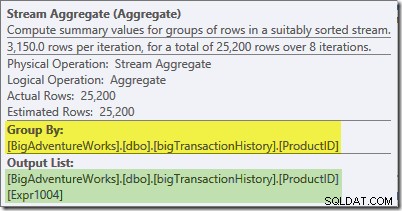
Prawidłowy wynik globalny na identyfikator produktu jest obliczany przez zsumowanie częściowych agregatów, jak pokazano na karcie Wyrażenia:
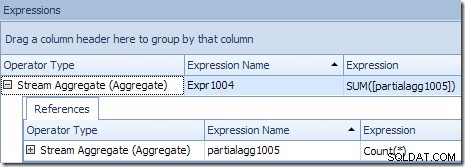
Kontynuując nasz (wyobrażony) przykład, poprawny wynik 1000 wierszy dla produktu o identyfikatorze nr 1 uzyskuje się przez zsumowanie dwóch sum częściowych 432 i 568.
Każdy z ośmiu fioletowych wątków gałęzi odczytuje dane z dwóch giełd Gather Streams po stronie konsumenta, oblicza globalne agregacje, wykonuje sprzężenie scalające na identyfikatorze produktu i dodaje wiersze do wymiany Gather Streams po lewej stronie fioletowej gałęzi. Podstawowy proces nie różni się zbytnio od zwykłego planu seryjnego; różnice polegają na tym, skąd wiersze są odczytywane, dokąd są wysyłane i jak wiersze są rozdzielane między wątki…
Rozkład rzędów wymiany
Czytelnik alertów będzie się w tym momencie zastanawiał nad kilkoma szczegółami. W jaki sposób fioletowy oddział może obliczyć prawidłowe wyniki według identyfikatora produktu ale zielona gałąź nie mogła (wyniki dla tego samego identyfikatora produktu były rozłożone na wiele wątków)? Ponadto, jeśli istnieje osiem oddzielnych złączeń scalających (po jednym na wątek), w jaki sposób SQL Server gwarantuje, że wiersze, które zostaną połączone, kończą się w tym samym wystąpieniu przyłączenia?
Na oba te pytania można odpowiedzieć, patrząc na sposób, w jaki dwa strumienie podziału wymieniają wiersze tras od strony producenta (w gałęzi zielonej i pomarańczowej) do strony konsumenta (w gałęzi fioletowej). Najpierw przyjrzymy się wymianie strumieni repartycji graniczącej z pomarańczowymi i fioletowymi gałęziami:
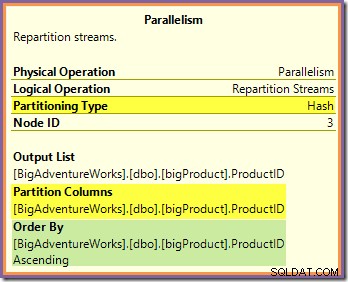
Ta wymiana kieruje przychodzące wiersze (z pomarańczowej gałęzi) przy użyciu funkcji skrótu zastosowanej do kolumny identyfikatora produktu. W efekcie wszystkie wiersze dla konkretnego identyfikatora produktu są gwarantowane być skierowana do tego samego fioletowo-rozgałęzionego wątku. Nici pomarańczowe i fioletowe nic nie wiedzą o tym trasowaniu; wszystko to jest obsługiwane wewnętrznie przez giełdę.
Wszystkie wątki pomarańczowe wiedzą, że zwracają wiersze do iteratora nadrzędnego, który o nie poprosił (strona producenta giełdy). Podobnie wszystkie fioletowe wątki „wiedzą”, że odczytują wiersze ze źródła danych. Wymiana określa, do którego pakietu trafi przychodzący wiersz z pomarańczową nitką i może to być dowolny z ośmiu pakietów kandydujących. Podobnie giełda określa, z którego pakietu odczytać wiersz, aby spełnić żądanie odczytu z fioletowego wątku.
Uważaj, aby nie uzyskać mentalnego obrazu konkretnej pomarańczowej (producenta) nici połączonej bezpośrednio z konkretną fioletową (konsumencką) nitką. Nie tak działa ten plan zapytań. Pomarańczowy producent może w końcu wysyłają wiersze do wszystkich fioletowych konsumentów – trasowanie zależy całkowicie od wartości kolumny identyfikatora produktu w każdym przetwarzanym wierszu.
Należy również pamiętać, że pakiet wierszy na giełdzie jest przesyłany tylko wtedy, gdy jest pełny (lub gdy po stronie producenta skończą się dane). Wyobraź sobie wymianę wypełniającą pakiety wiersz po wierszu, gdzie wiersze dla konkretnego pakietu mogą pochodzić z dowolnego wątku po stronie producenta (pomarańczowego). Gdy pakiet jest pełny, jest przekazywany do strony konsumenta, gdzie konkretny wątek konsumenta (fioletowy) może zacząć z niego czytać.
Wymiana strumieni podziału graniczących z zielonymi i fioletowymi gałęziami działa w bardzo podobny sposób:
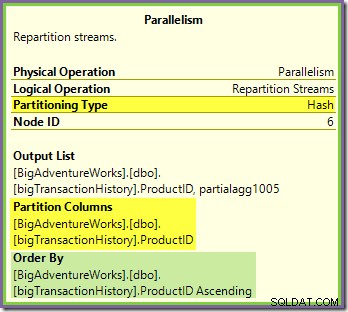
Wiersze są kierowane do pakietów w tej wymianie przy użyciu tej samej funkcji skrótu w tej samej kolumnie partycjonowania jak w przypadku wymiany pomarańczowo-fioletowej widzianej wcześniej. Oznacza to, że oba Repartition Streams wymienia wiersze tras z tym samym identyfikatorem produktu w tym samym fioletowym wątku.
To wyjaśnia, w jaki sposób Stream Aggregate w fioletowej gałęzi może obliczać globalne agregaty — jeśli jeden wiersz z określonym identyfikatorem produktu jest widoczny w określonym wątku fioletowej gałęzi, ten wątek ma gwarancję, że zobaczy wszystkie wiersze dla tego identyfikatora produktu (i nie inny wątek będzie).
Kolumna partycjonowania wspólnej wymiany jest również kluczem łączenia dla łączenia przez scalanie, więc wszystkie wiersze, które mogą się połączyć, mają gwarancję, że zostaną przetworzone przez ten sam (fioletowy) wątek.
Ostatnią rzeczą, na którą należy zwrócić uwagę, jest to, że obie giełdy zachowują zamówienia (tzw. „scalanie”) wymiany, jak pokazano w atrybucie Sortuj według w podpowiedziach. Spełnia to wymaganie łączenia scalającego dotyczące sortowania wierszy wejściowych według kluczy łączenia. Pamiętaj, że giełdy nigdy nie sortują wierszy same, można je po prostu skonfigurować tak, aby zachować istniejące zamówienie.
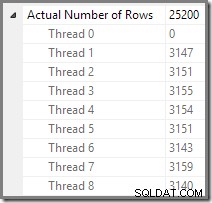
Wątek zero
Ostatnia część planu wykonania leży na lewo od giełdy Gather Streams. Zawsze działa na jednym wątku – tym samym, który służył do uruchomienia całego zwykłego planu szeregowego. Ten wątek jest zawsze oznaczony jako „Wątek 0” w planach wykonania i czasami jest nazywany wątkiem „koordynatora” (oznaczenie, które nie wydaje mi się szczególnie pomocne).
Zero wątku odczytuje wiersze z konsumenta (lewej) strony wymiany Gather Streams i zwraca je do klienta. W tym przykładzie nie ma iteratorów zerowych wątków poza wymianą, ale gdyby były, wszystkie działałyby w tym samym pojedynczym wątku. Zwróć uwagę, że Gather Streams jest również giełdą łączącą (ma atrybut Order By):

Bardziej złożone plany równoległe mogą obejmować strefy wykonywania szeregowego inne niż strefa po lewej stronie końcowej wymiany strumieni Gather Stream. Te strefy szeregowe nie są uruchamiane w wątku zerowym, ale jest to szczegół do zbadania innym razem.
Ponowne przeglądanie wątków zarezerwowanych i używanych
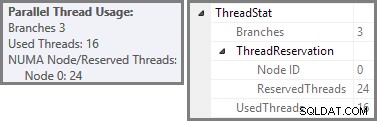
Widzieliśmy, że ten równoległy plan zawiera trzy gałęzie. To wyjaśnia, dlaczego SQL Server zarezerwowany 24 wątki (trzy gałęzie w DOP 8). Pytanie brzmi, dlaczego tylko 16 wątków zostało zgłoszonych jako „używane” na powyższym zrzucie ekranu.
Odpowiedź składa się z dwóch części. Pierwsza część nie dotyczy tego planu, ale i tak ważne jest, aby o tym wiedzieć. Liczba zgłoszonych oddziałów to maksymalna liczba, która może być wykonywana równocześnie .
Jak być może wiesz, niektórzy operatorzy planu „blokują się” – co oznacza, że muszą wykorzystać wszystkie swoje wiersze wejściowe, zanim będą mogli wygenerować pierwszy wiersz wyjściowy. Najwyraźniejszym przykładem operatora blokującego (znanego również jako operator stop-and-go) jest Sort. Funkcja sortowania nie może zwrócić pierwszego wiersza w posortowanej kolejności, zanim zobaczy każdy wiersz wejściowy, ponieważ ostatni wiersz wejściowy może zostać posortowany jako pierwszy.
Operatory z wieloma danymi wejściowymi (na przykład złączenia i złączki) mogą blokować się względem jednego wejścia, ale nie blokować („potokowo”) względem drugiego. Przykładem tego jest sprzężenie haszujące — dane wejściowe kompilacji są blokowane, ale dane wejściowe sondy są przesyłane potokowo. Wejście kompilacji jest blokowane, ponieważ tworzy tablicę mieszającą, na której testowane są wiersze sond.
Obecność operatorów blokujących oznacza, że jedna lub więcej równoległych gałęzi może mieć pewność, że zostanie ukończone, zanim inni będą mogli zacząć. W takim przypadku SQL Server może użyć ponownie wątki używane do przetwarzania ukończonej gałęzi dla późniejszej gałęzi w sekwencji. SQL Server jest bardzo konserwatywny w kwestii rezerwacji wątków, więc tylko gałęzie, które są gwarantowane aby zakończyć, zanim rozpocznie się kolejny, skorzystaj z tej optymalizacji rezerwacji wątków. Nasz plan zapytań nie zawiera żadnych operatorów blokujących, więc raportowana liczba oddziałów to tylko łączna liczba oddziałów.
Drugą częścią odpowiedzi jest to, że wątki mogą być nadal używane, jeśli wydarzą się zakończyć przed uruchomieniem wątku w innej gałęzi. W tym przypadku pełna liczba wątków jest nadal zarezerwowana, ale rzeczywiste użycie może być mniejsze. Liczba wątków, które faktycznie wykorzystuje plan równoległy, zależy między innymi od problemów z czasem i może różnić się między wykonaniami.
Nie wszystkie wątki równoległe zaczynają się wykonywać w tym samym czasie, ale znowu szczegóły będą musiały poczekać na inną okazję. Przyjrzyjmy się ponownie planowi zapytań, aby zobaczyć, jak wątki mogą być ponownie wykorzystane, pomimo braku operatorów blokujących:
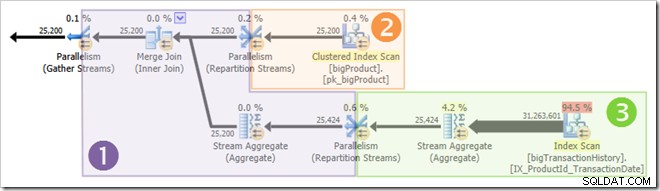
Oczywiste jest, że wątki w gałęzi pierwszej nie mogą zakończyć się przed uruchomieniem wątków w gałęziach dwóch lub trzech, więc nie ma tam szansy na ponowne użycie wątku. Trzecia gałąź też jest mało prawdopodobne do ukończenia przed uruchomieniem gałęzi pierwszej lub gałęzi drugiej, ponieważ ma tak dużo pracy do wykonania (prawie 32 miliony wierszy do zagregowania).
Druga gałąź to zupełnie inna sprawa. Stosunkowo mały rozmiar tabeli produktów oznacza, że istnieje spora szansa, że oddział może zakończyć swoją pracę przed rozpoczyna się trzecia gałąź. Jeśli odczytanie tabeli produktów nie powoduje żadnych fizycznych operacji we/wy, odczytanie 25 200 wierszy przez osiem wątków i przesłanie ich do wymiany strumieni podziału na pomarańczowo-fioletową granicę nie zajmie dużo czasu.
Dokładnie to wydarzyło się w testach używanych do zrzutów ekranu widocznych do tej pory w tym poście:osiem wątków pomarańczowych gałęzi zostało ukończonych wystarczająco szybko, aby można je było ponownie wykorzystać w zielonej gałęzi. W sumie wykorzystano szesnaście unikalnych wątków, więc to właśnie raportuje plan wykonania.
Jeśli zapytanie zostanie ponownie uruchomione z zimną pamięcią podręczną, opóźnienie wprowadzone przez fizyczne operacje we/wy jest wystarczające, aby zapewnić, że wątki z zielonymi gałęziami zostaną uruchomione przed zakończeniem jakichkolwiek wątków pomarańczowej gałęzi. Żadne wątki nie są ponownie wykorzystywane, więc plan wykonania informuje, że wszystkie 24 zarezerwowane wątki zostały faktycznie wykorzystane:
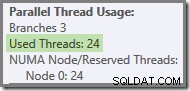
Mówiąc ogólniej, możliwa jest dowolna liczba „używanych wątków” między dwiema skrajnościami (16 i 24 dla tego planu zapytań):
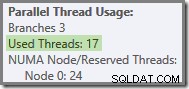
Na koniec zwróć uwagę, że wątek, który uruchamia seryjną część planu po lewej stronie końcowych strumieni Gather Stream, nie jest liczony w równoległych sumach wątków. Nie jest to dodatkowy wątek dodany w celu umożliwienia wykonywania równoległego.
Ostateczne myśli
Piękno modelu wymiany używanego przez SQL Server do implementacji wykonywania równoległego polega na tym, że cała złożoność buforowania i przenoszenia wierszy między wątkami jest ukryta w operatorach wymiany (równoległości). Reszta planu jest podzielona na zgrabne „gałęzie”, ograniczone wymianami. W ramach oddziału każdy operator zachowuje się tak samo, jak w planie szeregowym – w prawie wszystkich przypadkach operatorzy oddziałów nie mają wiedzy, że szerszy plan w ogóle korzysta z wykonywania równoległego.
Kluczem do zrozumienia wykonywania równoległego jest (mentalne) rozbicie planu równoległego na granicach wymiany i wyobrażenie każdej gałęzi jako oddzielnego DOP szeregowego plany, wszystkie wykonujące współbieżność w odrębnym podzbiorze wierszy. Pamiętaj w szczególności, że każdy taki plan szeregowy uruchamia wszystkie operatory w tej gałęzi – SQL Server nie uruchom każdy operator we własnym wątku!
Zrozumienie najbardziej szczegółowego zachowania wymaga trochę przemyślenia, w szczególności nad tym, jak wiersze są kierowane w ramach giełd i w jaki sposób silnik gwarantuje prawidłowe wyniki, ale większość rzeczy wartych poznania wymaga trochę przemyślenia, prawda?