Grupowanie danych daty i godziny wiąże się z organizowaniem danych w grupy reprezentujące stałe przedziały czasu do celów analitycznych. Często danymi wejściowymi są dane szeregów czasowych przechowywane w tabeli, w której wiersze reprezentują pomiary wykonane w regularnych odstępach czasu. Na przykład pomiary mogą być odczytami temperatury i wilgotności dokonywanymi co 5 minut, a dane chcesz pogrupować za pomocą przedziałów godzinowych i agregacji obliczeniowych, takich jak średnia na godzinę. Mimo że dane szeregów czasowych są powszechnym źródłem analizy opartej na kubełkach, koncepcja ta jest równie istotna dla wszelkich danych, które obejmują atrybuty daty i godziny oraz powiązane miary. Na przykład możesz chcieć uporządkować dane sprzedaży w przedziałach roku obrachunkowego i obliczyć agregacje, takie jak łączna wartość sprzedaży na rok obrachunkowy. W tym artykule omówię dwie metody tworzenia zbiorczych danych o dacie i godzinie. Jednym z nich jest użycie funkcji o nazwie DATE_BUCKET, która w momencie pisania jest dostępna tylko w Azure SQL Edge. Innym jest użycie niestandardowych obliczeń, które emulują funkcję DATE_BUCKET, której można używać w dowolnej wersji, edycji i odmianie SQL Server i Azure SQL Database.
W moich przykładach użyję przykładowej bazy danych TSQLV5. Skrypt, który tworzy i wypełnia TSQLV5, oraz jego diagram ER znajdziesz tutaj.
DATE_BUCKET
Jak wspomniano, funkcja DATE_BUCKET jest obecnie dostępna tylko w Azure SQL Edge. SQL Server Management Studio obsługuje już technologię IntelliSense, jak pokazano na rysunku 1:
 Rysunek 1:Obsługa funkcji Intellience dla DATE_BUCKET w SSMS
Rysunek 1:Obsługa funkcji Intellience dla DATE_BUCKET w SSMS
Składnia funkcji jest następująca:
DATE_BUCKET (Wejście pochodzenie reprezentuje punkt kontrolny na strzałce czasu. Może to być dowolny z obsługiwanych typów danych daty i godziny. Jeśli nie określono, wartością domyślną jest 1900, 1 stycznia, północ. Możesz wtedy wyobrazić sobie oś czasu podzieloną na dyskretne interwały, zaczynając od punktu początkowego, gdzie długość każdego interwału jest oparta na danych wejściowych szerokość zasobnika i część daty . Pierwsza to ilość, a druga to jednostka. Na przykład, aby uporządkować oś czasu w jednostkach dwumiesięcznych, należy określić 2 jako szerokość zasobnika wejście i miesiąc jako część daty wejście.
Wejście sygnatura czasowa to arbitralny punkt w czasie, który należy powiązać z pojemnikiem zawierającym. Jego typ danych musi być zgodny z typem danych wejściowych początek . Wejście sygnatura czasowa to wartość daty i godziny powiązana z przechwytywanymi miarami.
Wyjście funkcji jest wtedy punktem początkowym wiadra zawierającego. Typ danych wyjściowych to typ danych wejściowych sygnatura czasowa .
Jeśli nie było to już oczywiste, zwykle użyjesz funkcji DATE_BUCKET jako elementu zbioru grupującego w klauzuli GROUP BY zapytania i naturalnie zwrócisz ją również na liście SELECT, wraz z zagregowanymi miarami.
Nadal jesteś trochę zdezorientowany funkcją, jej danymi wejściowymi i wyjściowymi? Może pomocny byłby konkretny przykład z wizualnym przedstawieniem logiki funkcji. Zacznę od przykładu, który używa zmiennych wejściowych, a w dalszej części artykułu zademonstruję bardziej typowy sposób, w jaki można ich użyć jako części zapytania względem tabeli wejściowej.
Rozważ następujący przykład:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Wizualny obraz logiki funkcji można znaleźć na rysunku 2.
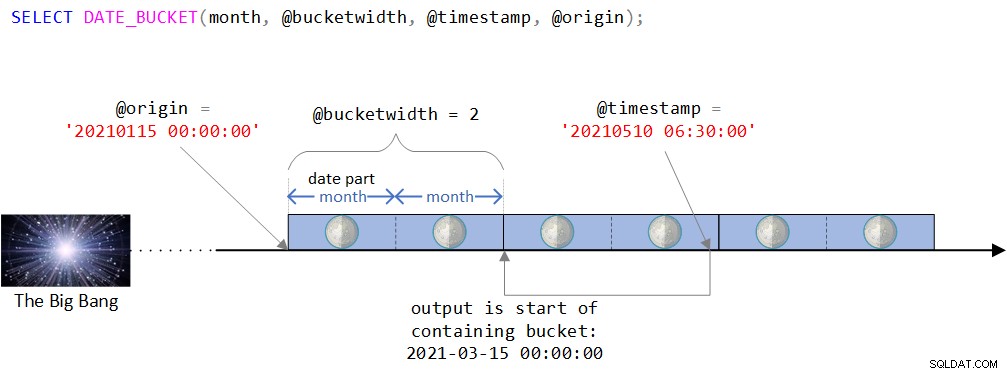 Rysunek 2:Wizualne przedstawienie logiki funkcji DATE_BUCKET
Rysunek 2:Wizualne przedstawienie logiki funkcji DATE_BUCKET
Jak widać na rysunku 2, punktem początkowym jest wartość DATETIME2 15 stycznia 2021 o północy. Jeśli ten punkt początkowy wydaje się nieco dziwny, miałbyś rację intuicyjnie wyczuwając, że normalnie użyłbyś bardziej naturalnego, jak początek pewnego roku lub początek pewnego dnia. W rzeczywistości często byłbyś zadowolony z wartości domyślnej, która, jak pamiętasz, to 1 stycznia 1900 o północy. Celowo chciałem użyć mniej trywialnego punktu początkowego, aby móc omówić pewne zawiłości, które mogą nie mieć znaczenia przy użyciu bardziej naturalnego punktu. Więcej na ten temat wkrótce.
Oś czasu jest następnie dzielona na dyskretne 2-miesięczne przedziały, zaczynając od punktu początkowego. Wprowadzony znacznik czasu to wartość DATETIME2 10 maja 2021, 6:30.
Zwróć uwagę, że wejściowy znacznik czasu jest częścią zasobnika, który rozpoczyna się 15 marca 2021 r. o północy. Rzeczywiście, funkcja zwraca tę wartość jako wartość wpisaną w DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Emulacja DATE_BUCKET
Jeśli nie korzystasz z usługi Azure SQL Edge, jeśli chcesz przenosić dane daty i godziny do segmentów, na razie musisz utworzyć własne niestandardowe rozwiązanie, aby emulować działanie funkcji DATE_BUCKET. Nie jest to zbyt skomplikowane, ale też nie jest zbyt proste. Radzenie sobie z danymi o dacie i godzinie często wiąże się z zawiłą logiką i pułapkami, na które należy uważać.
Zbuduję obliczenia w krokach i użyję tych samych danych wejściowych, których użyłem w przykładzie DATE_BUCKET, który pokazałem wcześniej:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Upewnij się, że dołączasz tę część przed każdym z przykładów kodu, które pokażę, jeśli rzeczywiście chcesz uruchomić kod.
W kroku 1 używasz funkcji DATEDIFF, aby obliczyć różnicę w części daty jednostki między pochodzeniem i sygnatura czasowa . Będę nazywał tę różnicę diff1 . Odbywa się to za pomocą następującego kodu:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
W przypadku naszych przykładowych danych wejściowych to wyrażenie zwraca 4.
Trudne jest to, że musisz obliczyć, ile całych jednostek części daty istnieje między pochodzeniem i sygnatura czasowa . W przypadku naszych przykładowych danych wejściowych są 3 całe miesiące między tymi dwoma, a nie 4. Powodem, dla którego funkcja DATEDIFF zgłasza 4 jest to, że podczas obliczania różnicy patrzy tylko na żądaną część danych wejściowych i wyższe części, ale nie niższe części . Tak więc, gdy pytasz o różnicę w miesiącach, funkcja zwraca uwagę tylko na części danych wejściowych związanych z rokiem i miesiącem, a nie o części poniżej miesiąca (dzień, godzina, minuta, sekunda itd.). Rzeczywiście, są 4 miesiące między styczniem 2021 a majem 2021, ale tylko 3 pełne miesiące między pełnymi danymi wejściowymi.
Celem kroku 2 jest zatem obliczenie, ile całych jednostek części daty istnieje między pochodzeniem i sygnatura czasowa . Będę nazywał tę różnicę diff2 . Aby to osiągnąć, możesz dodać diff1 jednostki części daty do pochodzenia . Jeśli wynik jest większy niż sygnatura czasowa , odejmujesz 1 od różnic1 obliczyć diff2 , w przeciwnym razie odejmij 0 i dlatego użyj diff1 jako różnica2 . Można to zrobić za pomocą wyrażenia CASE, na przykład:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; To wyrażenie zwraca 3, czyli liczbę pełnych miesięcy między dwoma danymi wejściowymi.
Przypomnij sobie, że wcześniej wspomniałem, że w moim przykładzie celowo użyłem punktu początkowego, który nie jest naturalny, jak okrągły początek okresu, aby móc omówić pewne zawiłości, które wtedy mogą mieć znaczenie. Na przykład, jeśli używasz miesiąc jako część daty i dokładny początek jakiegoś miesiąca (1 z jakiegoś miesiąca o północy) jako początek, możesz bezpiecznie pominąć krok 2 i użyć diff1 jako różnica2 . To dlatego, że pochodzenie + różnica1 nigdy nie może być> sygnaturą czasową w takim przypadku. Jednak moim celem jest zapewnienie logicznie równoważnej alternatywy dla funkcji DATE_BUCKET, która działałaby poprawnie dla dowolnego punktu początkowego, wspólnego lub nie. W związku z tym dołączę logikę kroku 2 w moich przykładach, ale pamiętaj tylko, gdy identyfikujesz przypadki, w których ten krok nie jest istotny, możesz bezpiecznie usunąć część, w której odejmujesz wynik wyrażenia CASE.
W kroku 3 określasz, ile jednostek części daty istnieją całe zasobniki, które istnieją między początkiem i sygnatura czasowa . Będę nazywał tę wartość diff3 . Można to zrobić za pomocą następującego wzoru:
diff3 = diff2 / <bucket width> * <bucket width>
Sztuczka polega na tym, że używając operatora dzielenia / w T-SQL z operandami całkowitymi, otrzymujesz dzielenie całkowite. Na przykład 3/2 w T-SQL to 1, a nie 1,5. Wyrażenie diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; To wyrażenie zwraca 2, czyli liczbę miesięcy w pełnych 2-miesięcznych przedziałach, które istnieją między dwoma danymi wejściowymi.
W kroku 4, który jest ostatnim krokiem, dodajesz diff3 jednostki części daty do pochodzenia aby obliczyć początek zasobnika zawierającego. Oto kod, który pozwoli to osiągnąć:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ten kod generuje następujące dane wyjściowe:
--------------------------- 2021-03-15 00:00:00.0000000
Jak pamiętasz, jest to ten sam wynik, który generuje funkcja DATE_BUCKET dla tych samych danych wejściowych.
Proponuję wypróbować to wyrażenie z różnymi danymi wejściowymi i częściami. Pokażę tutaj kilka przykładów, ale możesz wypróbować własne.
Oto przykład, w którym pochodzenie nieznacznie wyprzedza sygnaturę czasową w miesiącu:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ten kod generuje następujące dane wyjściowe:
--------------------------- 2021-03-10 06:30:01.0000000
Zauważ, że początek zasobnika zawierającego jest w marcu.
Oto przykład, w którym pochodzenie jest w tym samym momencie w ciągu miesiąca, co sygnatura czasowa :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ten kod generuje następujące dane wyjściowe:
--------------------------- 2021-05-10 06:30:00.0000000
Zauważ, że tym razem początek zasobnika zawierającego ma miejsce w maju.
Oto przykład z 4-tygodniowymi przedziałami:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Zauważ, że kod używa tygodnia tym razem.
Ten kod generuje następujące dane wyjściowe:
--------------------------- 2021-02-12 00:00:00.0000000
Oto przykład z przedziałami 15-minutowymi:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Ten kod generuje następujące dane wyjściowe:
--------------------------- 2021-02-03 21:15:00.0000000
Zauważ, że ta część to minuta . W tym przykładzie chcesz użyć piętnastominutowych zasobników, zaczynając od dolnej części godziny, aby zadziałał punkt początkowy, który jest dolną częścią dowolnej godziny. W rzeczywistości, punkt początkowy, który ma jednostkę minutową 00, 15, 30 lub 45 z zerami w dolnych częściach, z dowolną datą i godziną będzie działał. A więc domyślne ustawienie używane przez funkcję DATE_BUCKET dla danych wejściowych origin pracowałbym. Oczywiście, używając wyrażenia niestandardowego, musisz jasno określić punkt początkowy. Tak więc, aby sympatyzować z funkcją DATE_BUCKET, możesz użyć daty bazowej o północy, tak jak to zrobiłem w powyższym przykładzie.
Nawiasem mówiąc, czy widzisz, dlaczego byłby to dobry przykład, w którym można całkowicie bezpiecznie pominąć krok 2 w rozwiązaniu? Jeśli rzeczywiście zdecydujesz się pominąć krok 2, otrzymasz następujący kod:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Oczywiście kod staje się znacznie prostszy, gdy krok 2 nie jest potrzebny.
Grupowanie i agregowanie danych według przedziałów daty i godziny
Istnieją przypadki, w których trzeba podzielić dane daty i godziny na segmenty, które nie wymagają zaawansowanych funkcji ani niewygodnych wyrażeń. Załóżmy na przykład, że chcesz wykonać zapytanie do widoku Sales.OrderValues w bazie danych TSQLV5, pogrupować dane co roku i obliczyć łączną liczbę zamówień i wartości rocznie. Oczywiście wystarczy użyć funkcji YEAR(data zamówienia) jako elementu zbioru grupującego, jak na przykład:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Ten kod generuje następujące dane wyjściowe:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Ale co, jeśli chcesz zebrać dane według roku obrotowego swojej organizacji? Niektóre organizacje używają roku obrachunkowego do celów księgowych, budżetowych i sprawozdawczości finansowej, które nie są wyrównane z rokiem kalendarzowym. Załóżmy na przykład, że rok obrachunkowy Twojej organizacji działa w kalendarzu obrachunkowym od października do września i jest oznaczony rokiem kalendarzowym, w którym kończy się rok obrachunkowy. Tak więc wydarzenie, które miało miejsce 3 października 2018 r., należy do roku podatkowego, który rozpoczął się 1 października 2018 r. i zakończył 30 września 2019 r., i jest oznaczone rokiem 2019.
Jest to dość łatwe do osiągnięcia za pomocą funkcji DATE_BUCKET, na przykład:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
A oto kod używający niestandardowego logicznego odpowiednika funkcji DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Ten kod generuje następujące dane wyjściowe:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Użyłem tutaj zmiennych dla szerokości wiadra i punktu początkowego, aby kod był bardziej uogólniony, ale możesz zastąpić je stałymi, jeśli zawsze używasz tych samych, a następnie odpowiednio uprościć obliczenia.
Jako niewielką zmianę powyższego załóżmy, że rok obrotowy trwa od 15 lipca jednego roku kalendarzowego do 14 lipca następnego roku kalendarzowego i jest oznaczony rokiem kalendarzowym, do którego należy początek roku obrotowego. Czyli zdarzenie, które miało miejsce 18 lipca 2018 r. należy do roku podatkowego 2018. Zdarzenie, które miało miejsce 14 lipca 2018 r. należy do roku podatkowego 2017. Używając funkcji DATE_BUCKET, osiągniesz to w następujący sposób:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Możesz zobaczyć zmiany w porównaniu z poprzednim przykładem w komentarzach.
A oto kod używający niestandardowego logicznego odpowiednika funkcji DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Ten kod generuje następujące dane wyjściowe:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Oczywiście istnieją alternatywne metody, których możesz użyć w określonych przypadkach. Weźmy przykład przed ostatnim, gdzie rok obrotowy trwa od października do września i jest oznaczony rokiem kalendarzowym, w którym kończy się rok obrotowy. W takim przypadku możesz użyć następującego, znacznie prostszego wyrażenia:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
A wtedy Twoje zapytanie wyglądałoby tak:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Jeśli jednak potrzebujesz uogólnionego rozwiązania, które działałoby w wielu innych przypadkach i które można by sparametryzować, naturalnie chciałbyś użyć bardziej ogólnej formy. Jeśli masz dostęp do funkcji DATE_BUCKET, to świetnie. Jeśli nie, możesz użyć niestandardowego odpowiednika logicznego.
Wniosek
Funkcja DATE_BUCKET jest całkiem przydatną funkcją, która umożliwia tworzenie zbiorczych danych o dacie i godzinie. Przydaje się do obsługi danych szeregów czasowych, ale także do tworzenia zbiorczych danych, które zawierają atrybuty daty i godziny. W tym artykule wyjaśniłem, jak działa funkcja DATE_BUCKET i podałem niestandardowy odpowiednik logiczny na wypadek, gdyby platforma, z której korzystasz, jej nie obsługuje.