Od czasu do czasu możesz zauważyć, że jedno lub więcej złączeń w planie wykonania jest oznaczonych znacznikiem StarJoinInfo Struktura. Oficjalny schemat showplanu zawiera następujące informacje o tym elemencie planu (kliknij, aby powiększyć):
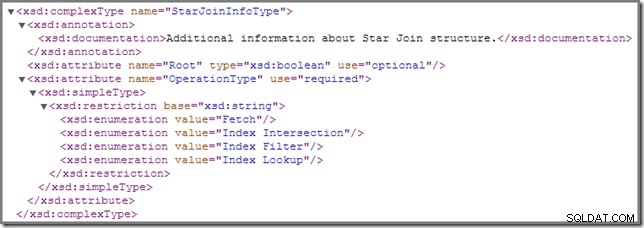
Pokazana tam dokumentacja wbudowana („dodatkowe informacje o strukturze Star Join ") nie jest aż tak pouczający, chociaż inne szczegóły są dość intrygujące – przyjrzymy się im szczegółowo.
Jeśli sprawdzisz swoją ulubioną wyszukiwarkę, aby uzyskać więcej informacji, używając terminów takich jak „Optymalizacja łączenia gwiazd SQL Server”, prawdopodobnie zobaczysz wyniki opisujące zoptymalizowane filtry bitmapowe. Jest to oddzielna funkcja tylko dla przedsiębiorstw wprowadzona w SQL Server 2008 i niezwiązana z StarJoinInfo w ogóle.
Optymalizacja dla selektywnych zapytań dotyczących gwiazdek
Obecność StarJoinInfo wskazuje, że SQL Server zastosował jedną z zestawu optymalizacji ukierunkowanych na selektywne zapytania oparte na schemacie gwiazdy. Te optymalizacje są dostępne w SQL Server 2005 we wszystkich edycjach (nie tylko Enterprise). Pamiętaj, że selektywne tutaj odnosi się do liczby wierszy pobranych z tabeli faktów. Kombinacja predykatów wymiarowych w zapytaniu może nadal być selektywna, nawet jeśli poszczególne predykaty kwalifikują dużą liczbę wierszy.
Zwykłe przecięcie indeksu
Optymalizator zapytań może rozważyć połączenie wielu indeksów nieklastrowanych, gdy odpowiedni pojedynczy indeks nie istnieje, jak pokazuje następujące zapytanie AdventureWorks:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Optymalizator określa, że połączenie dwóch nieklastrowanych indeksów (jeden na SalesPersonID a drugi na CustomerID ) jest najtańszym sposobem spełnienia tego zapytania (brak indeksu w obu kolumnach):
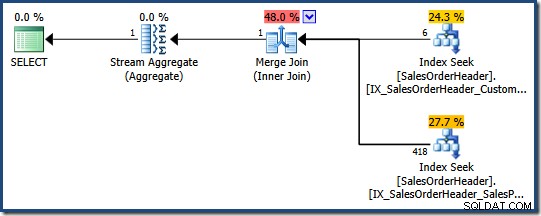
Każde wyszukiwanie indeksu zwraca klucz indeksu klastrowego dla wierszy, które przekazują predykat. Łączenie pasuje do zwróconych kluczy, aby zapewnić, że tylko wiersze pasują do obydwóch predykaty są przekazywane.
Gdyby tabela była stertą, każde wyszukiwanie zwróciłoby identyfikatory wierszy sterty (RID) zamiast kluczy indeksu klastrowego, ale ogólna strategia jest taka sama:znajdź identyfikatory wierszy dla każdego predykatu, a następnie dopasuj je.
Ręczne przecięcie indeksu połączenia gwiazdy
Ten sam pomysł można rozszerzyć na zapytania, które wybierają wiersze z tabeli faktów za pomocą predykatów zastosowanych do tabel wymiarów. Aby zobaczyć, jak to działa, rozważ następujące zapytanie (przy użyciu przykładowej bazy danych Contoso BI), aby znaleźć łączną kwotę sprzedaży dla odtwarzaczy MP3 sprzedawanych w sklepach Contoso z dokładnie 50 pracownikami:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Dla porównania z późniejszymi wysiłkami, to (bardzo selektywne) zapytanie tworzy plan zapytania podobny do następującego (kliknij, aby rozwinąć):
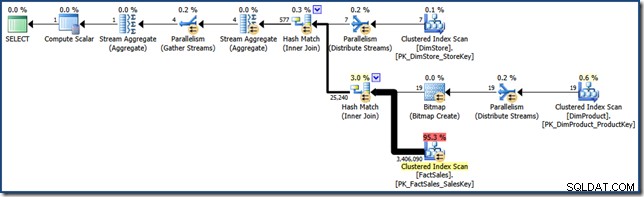
Ten plan wykonania ma szacunkowy koszt nieco ponad 15,6 jednostek . Posiada równoległe wykonanie z pełnym skanowaniem tabeli faktów (choć z zastosowanym filtrem bitmapowym).
Tabele faktów w tej przykładowej bazie danych nie zawierają domyślnie indeksów nieklastrowanych w kluczach obcych tabeli faktów, więc musimy dodać kilka:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Mając te indeksy, możemy zacząć widzieć, jak przecięcie indeksów może być wykorzystane do poprawy wydajności. Pierwszym krokiem jest znalezienie identyfikatorów wierszy tabeli faktów dla każdego oddzielnego predykatu. Poniższe zapytania stosują predykat jednowymiarowy, a następnie łączą się z powrotem z tabelą faktów, aby znaleźć identyfikatory wierszy (klastrowe klucze indeksowe tabeli faktów):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Plany zapytań zawierają skan tabeli małych wymiarów, a następnie wyszukiwania przy użyciu indeksu nieklastrowanego tabeli faktów w celu znalezienia identyfikatorów wierszy (pamiętaj, że indeksy nieklastrowane zawsze zawierają klucz klastrowania tabeli podstawowej lub identyfikator RID sterty):
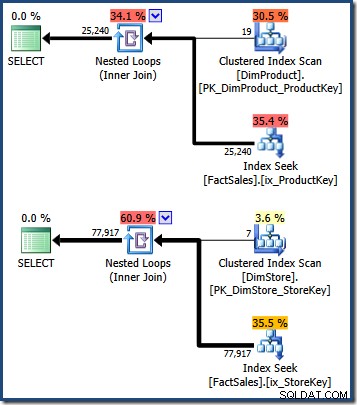
Przecięcie tych dwóch zestawów kluczy indeksu klastrowego tabeli faktów identyfikuje wiersze, które powinny zostać zwrócone przez oryginalne zapytanie. Gdy mamy już te identyfikatory wierszy, wystarczy wyszukać kwotę sprzedaży w każdym wierszu tabeli faktów i obliczyć sumę.
Ręczne zapytanie o przecięcie indeksu
Umieszczenie tego wszystkiego razem w zapytaniu daje następujące wyniki:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK wskazówka jest po to, aby zapewnić, że otrzymamy odnośniki punktów do tabeli faktów. Bez tego optymalizator postanawia przeskanować tabelę faktów, czego właśnie chcemy uniknąć. MAXDOP 1 wskazówka pomaga tylko utrzymać ostateczny plan w dość rozsądnym rozmiarze do celów wyświetlania (kliknij, aby zobaczyć go w pełnym rozmiarze):
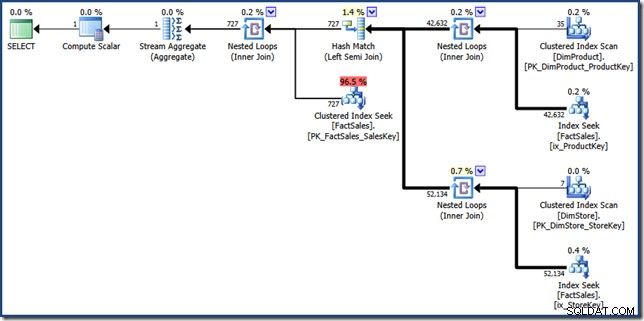
Części składowe ręcznego planu przecięcia indeksu są dość łatwe do zidentyfikowania. Dwa nieklastrowane wyszukiwania indeksów tabeli faktów po prawej stronie generują dwa zestawy identyfikatorów wierszy tabeli faktów. Łączenie mieszające znajduje przecięcie tych dwóch zestawów. Wyszukiwanie indeksu klastrowego w tabeli faktów znajduje kwoty sprzedaży dla tych identyfikatorów wierszy. Na koniec Stream Aggregate oblicza całkowitą kwotę.
Ten plan kwerend wykonuje stosunkowo niewiele wyszukiwań w indeksach nieklastrowanych i klastrowanych tabeli faktów. Jeśli zapytanie jest wystarczająco selektywne, może to być tańsza strategia wykonania niż całkowite skanowanie tabeli faktów. Przykładowa baza danych Contoso BI jest stosunkowo niewielka i zawiera tylko 3,4 miliona wierszy w tabeli faktów sprzedaży. W przypadku większych tabel faktów różnica między pełnym skanowaniem a kilkoma setkami wyszukiwań może być bardzo znacząca. Niestety, ręczne przepisywanie wprowadza kilka poważnych błędów kardynalności, co skutkuje planem o szacowanym koszcie 46,5 jednostki .
Automatyczne przecięcie indeksu łączenia gwiazd z wyszukiwaniami
Na szczęście nie musimy decydować, czy pisane przez nas zapytanie jest wystarczająco selektywne, aby uzasadnić to ręczne przepisanie. Optymalizacje łączenia w gwiazdę dla zapytań selektywnych oznaczają, że optymalizator zapytań może za nas zbadać tę opcję, używając bardziej przyjaznej dla użytkownika oryginalnej składni zapytań:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Optymalizator tworzy następujący plan wykonania z szacowanym kosztem 1,64 jednostki (kliknij, aby powiększyć):
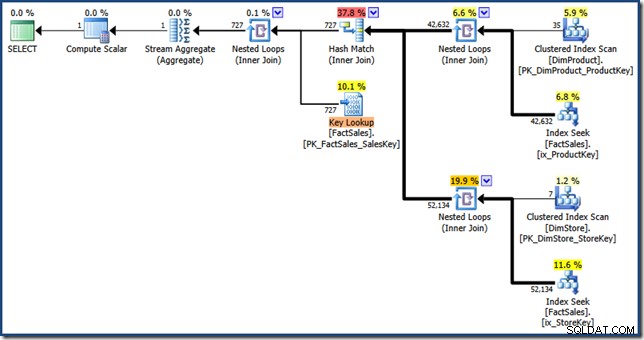
Różnice między tym planem a wersją ręczną są następujące:przecięcie indeksu jest sprzężeniem wewnętrznym zamiast sprzężeniem częściowym; a wyszukiwanie indeksu klastrowego jest wyświetlane jako wyszukiwanie klucza zamiast wyszukiwania indeksu klastrowanego. Ryzykując pracę nad tym punktem, jeśli tabela faktów byłaby stertą, wyszukiwanie klucza byłoby wyszukiwaniem RID.
Właściwości StarJoinInfo
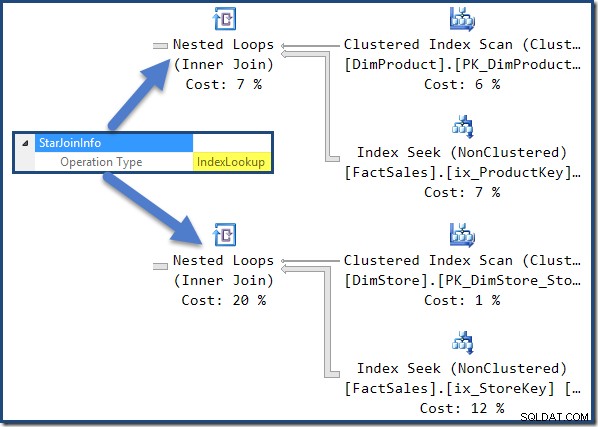
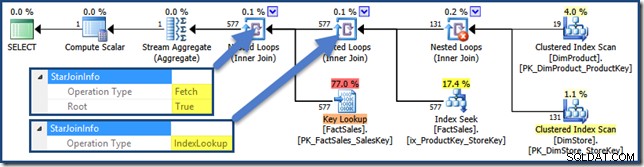
Wszystkie połączenia w tym planie mają StarJoinInfo Struktura. Aby to zobaczyć, kliknij iterator łączenia i spójrz w okno Właściwości SSMS. Kliknij strzałkę po lewej stronie StarJoinInfo element do rozwinięcia węzła.
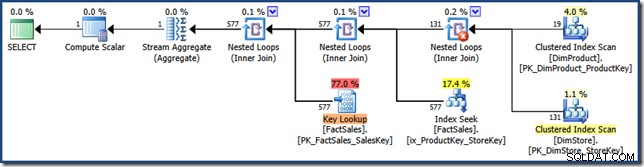
Nieklastrowane złączenia tabeli faktów po prawej stronie planu to wyszukiwania indeksu utworzone przez optymalizator:
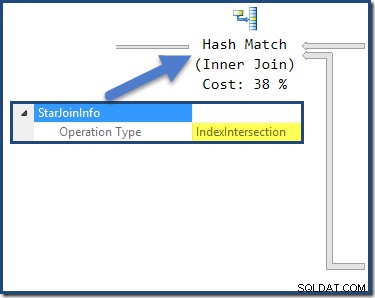
Połączenie haszujące ma StarJoinInfo struktura pokazująca, że wykonuje przecięcie indeksu (ponownie, wyprodukowane przez optymalizator):
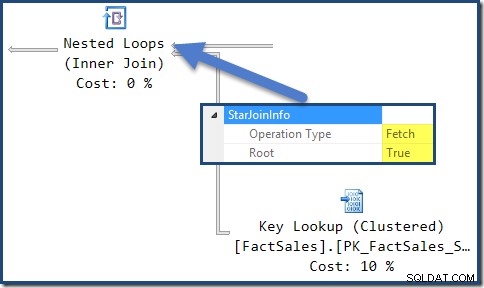
StarJoinInfo dla skrajnie lewej złączenia zagnieżdżonych pętli pokazuje, że zostało wygenerowane w celu pobrania wierszy tabeli faktów według identyfikatora wiersza. Znajduje się on u podstawy poddrzewa łączenia gwiazd generowanego przez optymalizator:
Produkty kartezjańskie i wielokolumnowe wyszukiwanie indeksu
Plany przecięcia indeksów uważane za część optymalizacji łączenia w gwiazdę są przydatne w przypadku zapytań selektywnych do tabel faktów, w których jednokolumnowe indeksy nieklastrowane istnieją na kluczach obcych tabeli faktów (powszechna praktyka projektowa).
Czasami sensowne jest również tworzenie indeksów wielokolumnowych na kluczach obcych tabeli faktów, dla często zadawanych kombinacji. Wbudowane selektywne optymalizacje kwerendy gwiaździstej zawierają również przepisanie dla tego scenariusza. Aby zobaczyć, jak to działa, dodaj następujący wielokolumnowy indeks do tabeli faktów:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Skompiluj ponownie zapytanie testowe:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Plan zapytania nie zawiera już przecięcia indeksów (kliknij, aby powiększyć):
Wybraną tutaj strategią jest zastosowanie każdego predykatu do tabel wymiarów, pobranie iloczynu kartezjańskiego wyników i użycie go do wyszukania obu kluczy indeksu wielokolumnowego. Plan kwerendy przeprowadza następnie wyszukiwanie kluczy w tabeli faktów, używając identyfikatorów wierszy dokładnie tak, jak widzieliśmy wcześniej.
Plan zapytań jest szczególnie interesujący, ponieważ łączy trzy funkcje, które są często uważane za złe rzeczy (pełne skanowanie, produkty kartezjańskie i wyszukiwanie kluczy) w ramach optymalizacji wydajności . Jest to prawidłowa strategia, gdy iloczyn tych dwóch wymiarów ma być bardzo mały.
Nie ma StarJoinInfo dla produktu kartezjańskiego, ale inne złącza mają informacje (kliknij, aby powiększyć):
Filtr indeksu
Wracając do schematu showplanu, jest jeszcze jeden StarJoinInfo operacja, którą musimy objąć:
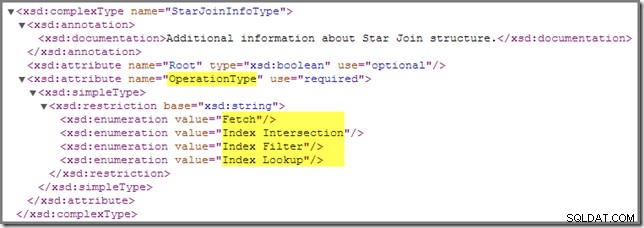
Index Filter wartość jest widoczna w przypadku złączeń, które są uważane za wystarczająco selektywne, aby warto było je wykonać przed pobraniem tabeli faktów. Połączenia, które nie są wystarczająco selektywne, zostaną wykonane po pobraniu i nie będą miały StarJoinInfo struktura.
Aby zobaczyć filtr indeksu przy użyciu naszego zapytania testowego, musimy dodać trzecią tabelę sprzężenia do miksu, usunąć nieklastrowane indeksy tabeli faktów utworzone do tej pory i dodać nową:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Plan zapytań jest teraz (kliknij, aby powiększyć):
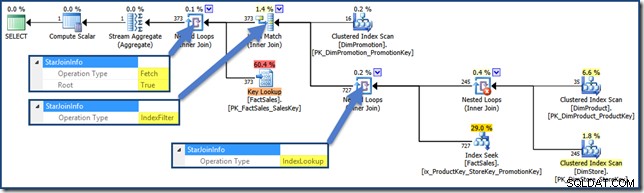
Plan zapytania przecięcia indeksu stosu
Dla kompletności, oto skrypt do tworzenia kopii stosu tabeli faktów z dwoma nieklastrowanymi indeksami potrzebnymi do umożliwienia przepisywania przez optymalizator przecięcia indeksów:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Plan wykonania dla tego zapytania ma te same funkcje co poprzednio, ale przecięcie indeksów jest wykonywane przy użyciu identyfikatorów RID zamiast kluczy indeksu klastrowego tabeli faktów, a końcowe pobieranie to wyszukiwanie identyfikatorów RID (kliknij, aby rozwinąć):
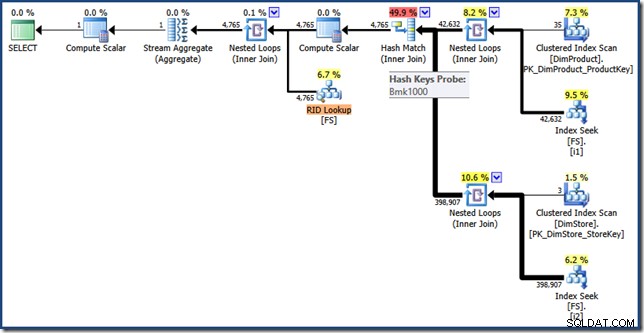
Ostateczne myśli
Pokazane tutaj przepisywania optymalizatora są skierowane na zapytania, które zwracają stosunkowo małą liczbę wierszy z dużego tabela faktów. Te zmiany są dostępne we wszystkich edycjach SQL Server od 2005 roku.
Chociaż ma to na celu przyspieszenie selektywnych zapytań schematów gwiazd (i płatków śniegu) w hurtowni danych, optymalizator może zastosować te techniki wszędzie tam, gdzie wykryje odpowiedni zestaw tabel i złączeń. Heurystyka używana do wykrywania zapytań dotyczących gwiazd jest dość szeroka, więc możesz napotkać kształty planu z StarJoinInfo struktury w niemal każdym typie bazy danych. Każda tabela o rozsądnym rozmiarze (powiedzmy 100 stron lub więcej) z odniesieniami do mniejszych (podobnych do wymiarów) tabel jest potencjalnym kandydatem do tych optymalizacji (zauważ, że jawne klucze obce nie wymagane).
Dla tych z Was, którzy lubią takie rzeczy, reguła optymalizatora odpowiedzialna za generowanie selektywnych wzorców łączenia gwiazd z logicznego łączenia n-tabel nazywa się StarJoinToIdxStrategy (przyłącz gwiazdką do strategii indeksowania).