Pierwszy post na tej stronie, w lipcu 2012 roku, mówił o najlepszych metodach obliczania sum biegowych. Od tego czasu wielokrotnie pytano mnie, jak podszedłbym do problemu, gdyby sumy bieżące były bardziej złożone – w szczególności, gdybym musiał obliczyć sumy bieżące dla wielu podmiotów – powiedzmy, zamówienia każdego klienta.
W oryginalnym przykładzie wykorzystano fikcyjny przypadek miasta wystawiającego mandaty za przekroczenie prędkości; bieżąca suma była po prostu sumowaniem i prowadzeniem bieżącej liczby mandatów za przekroczenie prędkości w ciągu dnia (niezależnie od tego, komu bilet został wystawiony i za ile był). Bardziej złożonym (ale praktycznym) przykładem może być sumowanie dziennej łącznej wartości mandatów za przekroczenie prędkości, pogrupowanych według prawa jazdy. Wyobraźmy sobie następującą tabelę:
CREATE TABLE dbo.SpeedingTickets( IncidentID INT IDENTITY(1,1) PRIMARY KEY, Numer licencji INT NOT NULL, IncidentDate DATA NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL); UTWÓRZ UNIKALNY INDEKS x NA dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Możesz zapytać, DECIMAL(7,2) , naprawdę? Jak szybko ci ludzie idą? Cóż, na przykład w Kanadzie nie jest aż tak trudno uzyskać mandat w wysokości 10 000 USD za przekroczenie prędkości.
Teraz wypełnijmy tabelę przykładowymi danymi. Nie będę tutaj omawiał wszystkich szczegółów, ale powinno to dać około 6000 wierszy reprezentujących wielu kierowców i wiele kwot biletów w ciągu miesiąca:
;WITH TicketAmounts(ID,Value) AS ( -- 10 dowolnych kwot biletów SELECT i,p FROM ( VALUES(1,32,75),(2,75),(3109),(4,175),(5295), ( 1000) 7000000 + liczba, n =NEWID() FROM [master].dbo.spt_values WHERE number BETWEEN 1 AND 999999 ORDER BY n),JanuaryDates([day]) AS ( -- codziennie w styczniu 2014 SELECT TOP (31) DATEADD(DZIEŃ, liczba, '20140101') FROM [master].dbo.spt_values WHERE [typ] =N'P' ORDER BY numer),Tickets(NumerLicencji,[dzień],s) AS( -- dopasowanie *jakaś* licencje do dni, w których otrzymali bilety SELECT DISTINCT l.NumerLicencji, d.[dzień], s =RTRIM(l.NumerLicencji) FROM NumeryLicencji AS l CROSS JOIN StyczeńDaty AS d WHERE SUMA KONTROLNA(NEWID()) % 100 =l.NumerLicencji % 100 AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%') OR (RTRIM(l.LicenseNumber+1) LIKE ' %' + PRAWO( CONVERT(CHAR(8), d.[dzień], 112),1) + '%'))INSERT dbo.SpeedingTickets(NumerLicencji,DataIncydentu,KwotaBiletu)SELECT t.NumerLicencji, t.[dzień], ta.Wartość FROM Tickety AS t INNER JOIN Kwoty Biletów AS ta ON ta.ID =CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1)) ORDER BY t.[day], t .Numer licencji;
To może wydawać się trochę zbyt skomplikowane, ale jednym z największych wyzwań, jakie często napotykam podczas pisania tych postów na blogu, jest skonstruowanie odpowiedniej ilości realistycznych „losowych” / arbitralnych danych. Jeśli masz lepszą metodę na arbitralne gromadzenie danych, za wszelką cenę nie używaj moich mamrotań jako przykładu – są one marginalne w stosunku do tego postu.
Podejścia
Istnieje wiele sposobów rozwiązania tego problemu w T-SQL. Oto siedem podejść wraz z powiązanymi planami. Pominąłem techniki, takie jak kursory (ponieważ będą niezaprzeczalnie wolniejsze) i rekurencyjne CTE oparte na dacie (ponieważ zależą od ciągłych dni).
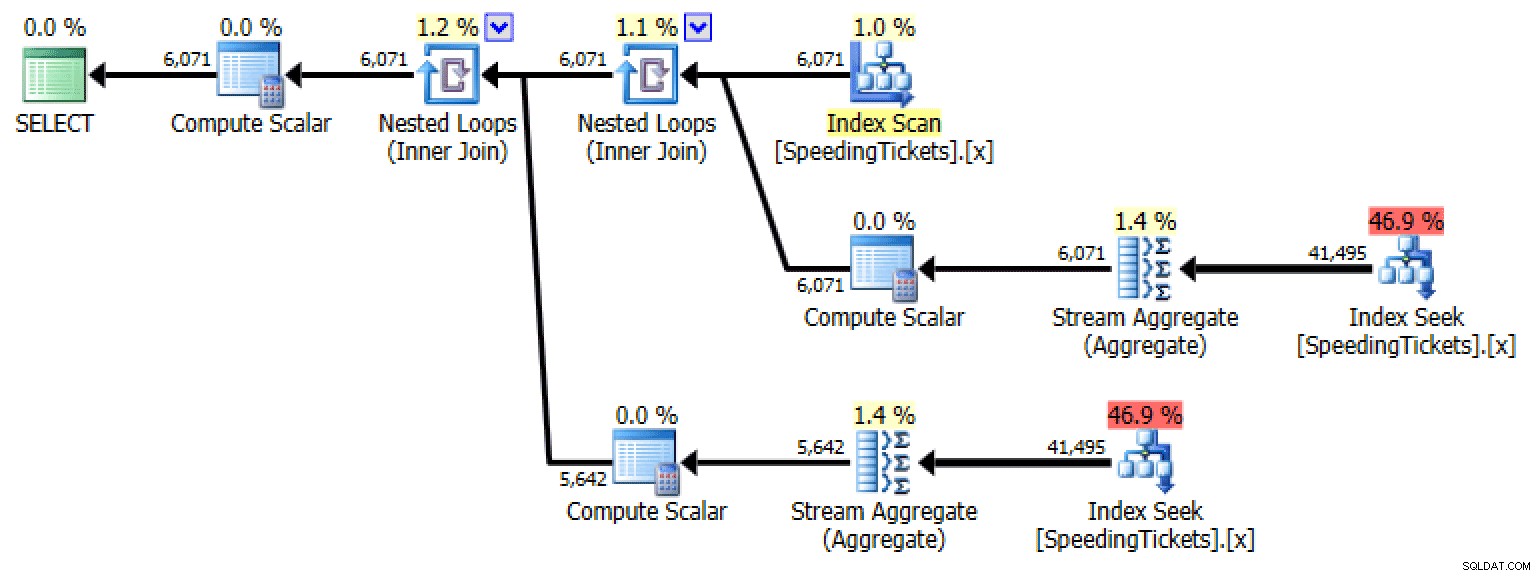
Podzapytanie nr 1
SELECT Numer Licencji, Data Incydentu, Kwota Biletu, Razem Uruchomione =Kwota Biletu + COALESCE ( ( SELECT SUM (Kwota Biletu) FROM dbo. SpeedingTickets AS s WHERE s. Numer licencji =o. Numer licencji AND s. Data Incydentu
Plan dla podzapytania nr 1Podzapytanie nr 2
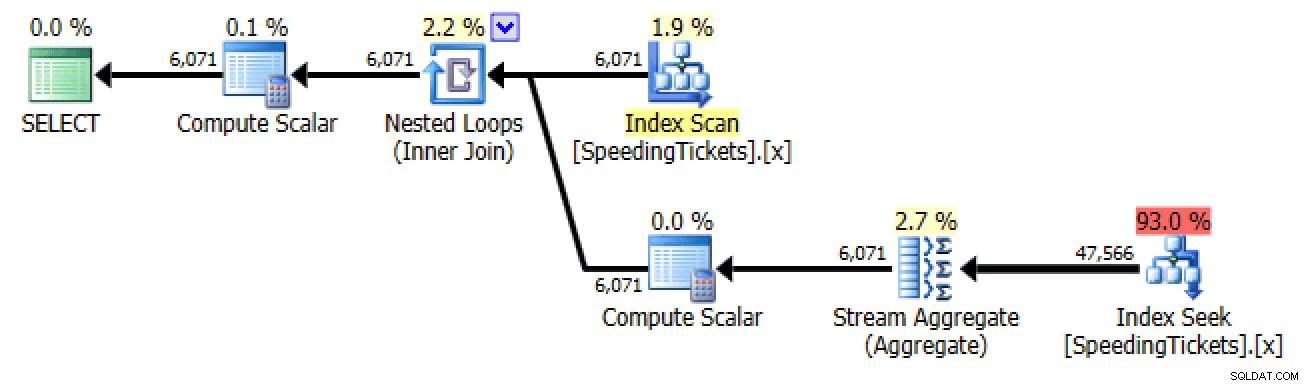
SELECT NumerLicencji, DataIncydentu, KwotaBiletu, Suma Bieżącego =( SELECT SUM(KwotaBiletu) FROM dbo.SpeedingTickets WHERE NumerLicencji =t.NumerLicencji AND DataIncydentu <=t.DataIncydentu )FROM dbo.SpeedingTickets AS tORDER BY Numer licencji;
Plan dla podzapytania nr 2Samozłączenie
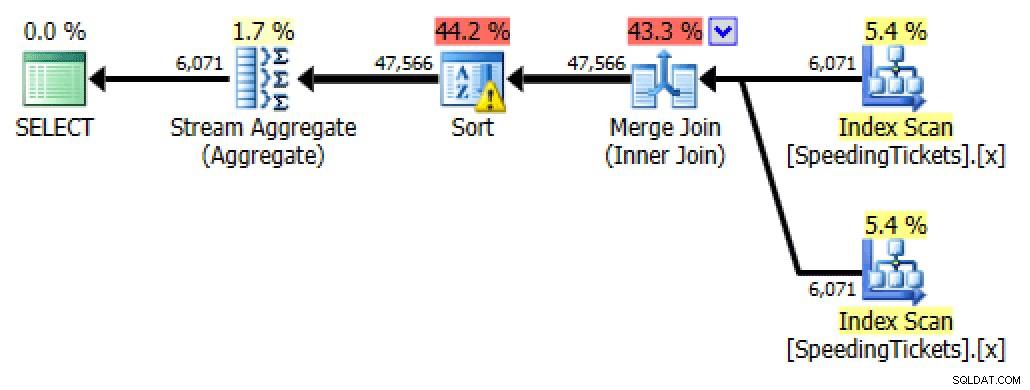
SELECT t1.Numer licencji, t1.IncydentDate, t1.Kwota biletu, RunningTotal =SUM(t2.Kwota biletu)FROM dbo.SpeedingTickets AS t1INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNicate.NumberId2. t2.IncidentDateGROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmountORDER BY t1.LicenseNumber, t1.IncidentDate;
Plan samodzielnego dołączaniaZewnętrzne zastosowanie
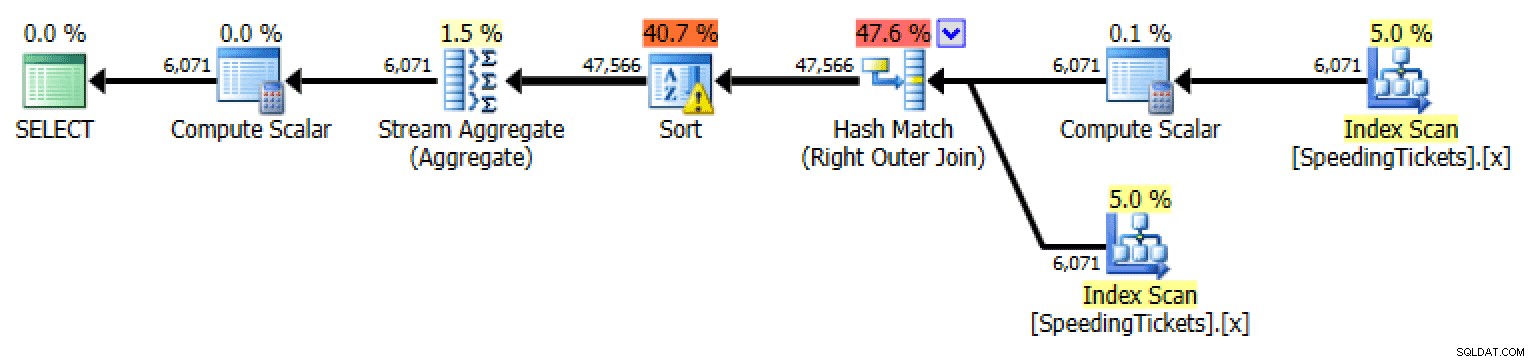
SELECT t1.Numer licencji, t1.IncydentDate, t1.Kwota biletu, RunningTotal =SUM(t2.Kwota biletu)FROM dbo.SpeedingTickets AS t1OUTER APPLY( SELECT TicketAmount FROM dbo.SpeedingTickets WHERE Numer licencji1.Numer t1. IncidentDate) AS t2GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmountORDER BY t1.LicenseNumber, t1.IncidentDate;
Plan dla zastosowania zewnętrznegoSUM OVER() przy użyciu RANGE (tylko 2012+)
SELECT NumerLicencji, DataIncydentu, KwotaBiletu, Suma_Rzecz. =SUM(Kwota Biletu) OVER (PARTYCJA BY Numer licencji ORDER BY IncidentDate ZAKRES BEZ OGRANICZEŃ PRECEDING ) FROM dbo.SpeedingTickets ORDER BY Numer licencji, IncidentDate;
Zaplanuj SUM OVER() przy użyciu RANGESUM OVER() przy użyciu ROWS (tylko 2012+)
SELECT NumerLicencji, DataIncydentu, KwotaBiletu, Suma_Rzecz. =SUM(KwotaBiletu) OVER (PARTYCJA BY Numer licencji ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING ) FROM dbo.SpeedingTickets ORDER BY Numer licencji, IncidentDate;
Zaplanuj SUM OVER() przy użyciu ROWSIteracja oparta na zestawach
Z uznaniem dla Hugo Kornelisa (@Hugo_Kornelis) za rozdział 4 w SQL Server MVP Deep Dives Volume #1, to podejście łączy podejście oparte na zbiorach i podejście oparte na kursorze.
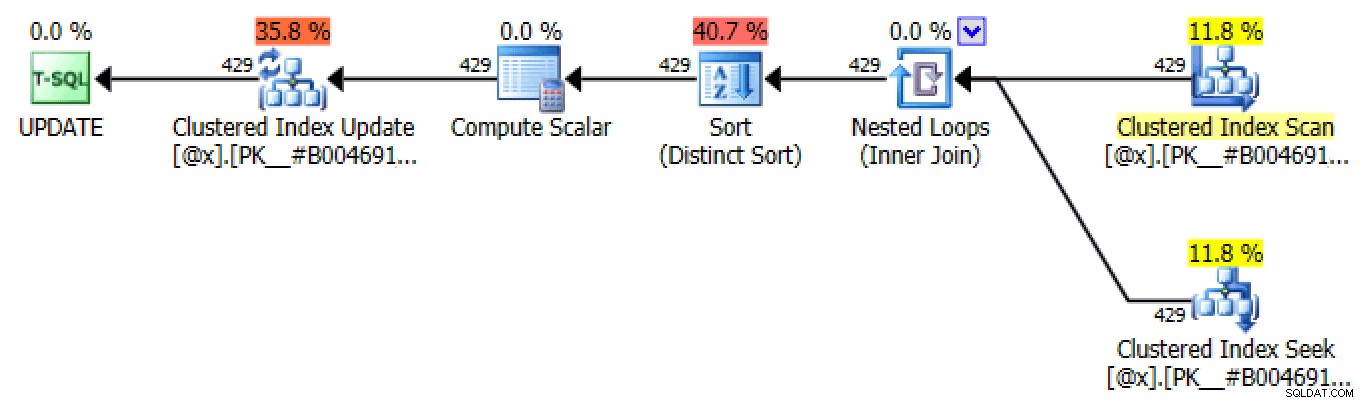
DECLARE @x TABLE( Numer licencji INT NOT NULL, IncidentDate DATA NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL, RunningTotal DECIMAL(7,2) NOT NULL, rn INT NOT NULL, PRIMARY KEY(LicenseNumber, IncidentDate) ); INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)SELECT SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount, ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate) FROM dbo.SpeedingTickets; ZADEKLARUJ @rn INT =1, @rc INT =1; WHILE @rc> 0BEGIN SET @rn +=1; UPDATE [bieżący] SET RunningTotal =[ostatni].RunningTotal + [bieżący].TicketAmount FROM @x AS [bieżący] INNER JOIN @x AS [ostatni] ON [bieżący].Numer licencji =[ostatni].Numer licencji AND [ostatni]. rn =@rn - 1 GDZIE [bieżący].rn =@rn; SET @rc =@@ROWCOUNT;END SELECT Numer licencji, data incydentu, kwota biletu, suma uruchomienia FROM @x ORDER BY Numer licencji, data incydentu;Ze względu na swój charakter, to podejście generuje wiele identycznych planów w procesie aktualizacji zmiennej tabeli, z których wszystkie są podobne do planów samodzielnego łączenia i zewnętrznego zastosowania, ale mogą korzystać z wyszukiwania:
Jeden z wielu planów UPDATE utworzonych za pomocą iteracji opartej na zestawieJedyną różnicą między każdym planem w każdej iteracji jest liczba wierszy. W każdej kolejnej iteracji liczba wierszy, których to dotyczy, powinna pozostać taka sama lub maleć, ponieważ liczba wierszy, których dotyczy każda iteracja, reprezentuje liczbę kierowców posiadających bilety na tę liczbę dni (a dokładniej liczbę dni w ta "ranga").
Wyniki wydajności
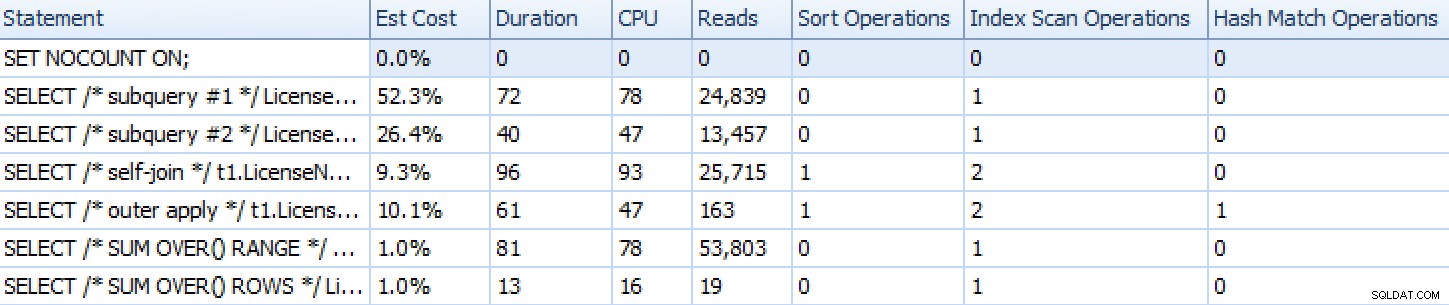
Oto jak ułożyły się podejścia, jak pokazuje SQL Sentry Plan Explorer, z wyjątkiem podejścia opartego na zbiorach, które, ponieważ składa się z wielu indywidualnych instrukcji, nie reprezentuje się dobrze w porównaniu z resztą.
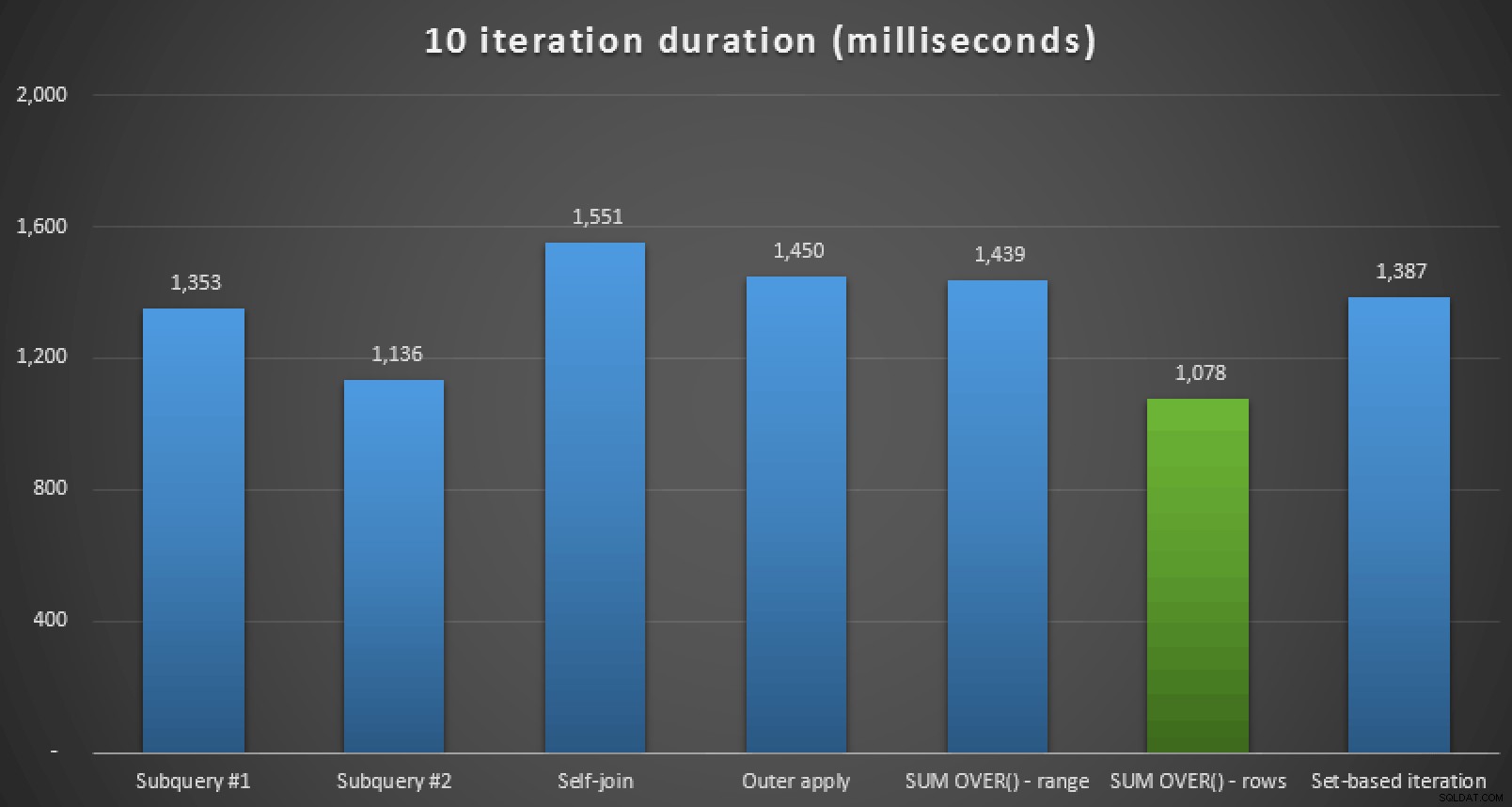
Wskaźniki czasu działania programu Plan Explorer dla sześciu z siedmiu podejśćOprócz przeglądania planów i porównywania metryk środowiska wykonawczego w Eksploratorze planów, mierzyłem również surowe środowisko wykonawcze w Management Studio. Oto wyniki 10-krotnego uruchomienia każdego zapytania, pamiętając, że obejmuje to również czas renderowania w SSMS:
Czas działania w milisekundach dla wszystkich siedmiu podejść (10 iteracji )Tak więc, jeśli korzystasz z SQL Server 2012 lub nowszego, najlepszym podejściem wydaje się być
SUM OVER()używającROWS UNBOUNDED PRECEDING. Jeśli nie korzystasz z SQL Server 2012, drugie podejście podzapytania wydaje się optymalne pod względem czasu wykonywania, pomimo dużej liczby odczytów w porównaniu z, powiedzmy,OUTER APPLYzapytanie. We wszystkich przypadkach, oczywiście, powinieneś przetestować te podejścia, dostosowane do twojego schematu, z własnym systemem. Twoje dane, indeksy i inne czynniki mogą prowadzić do tego, że inne rozwiązanie będzie najbardziej optymalne w Twoim środowisku.Inne zawiłości
Teraz unikalny indeks oznacza, że dowolna kombinacja Numer Licencji + Data Zdarzenia będzie zawierać jedną łączną sumę w przypadku, gdy określony kierowca otrzyma wiele biletów w danym dniu. Ta reguła biznesowa pomaga nieco uprościć naszą logikę, unikając potrzeby rozstrzygania remisów w celu uzyskania deterministycznych sum bieżących.
Jeśli masz przypadki, w których możesz mieć wiele wierszy dla dowolnej kombinacji Numer Licencji + Data Incydentu, możesz przerwać remis, używając innej kolumny, która pomaga uczynić tę kombinację unikalną (oczywiście tabela źródłowa nie będzie już miała ograniczenia unikatowego dla tych dwóch kolumn) . Pamiętaj, że jest to możliwe nawet w przypadkach, gdy
DATEkolumna to w rzeczywistościDATETIME– wiele osób zakłada, że wartości daty/czasu są unikalne, ale z pewnością nie zawsze jest to gwarantowane, niezależnie od szczegółowości.W moim przypadku mógłbym użyć
IDENTITYkolumna,IncidentID; oto jak dostosowałbym każde rozwiązanie (przyznając, że mogą istnieć lepsze sposoby; po prostu wyrzucając pomysły):/* --------- podzapytanie #1 --------- */ SELECT Numer licencji, Data zdarzenia, Kwota_biletu, Suma_ruchu =Kwota_biletu + COALESCE( ( SELECT SUM(Kwota_biletu) FROM dbo. SpeedingTickets AS s WHERE s.LicenseNumber =o.LicenseNumber AND (s.IncidentDate=t2.IncidentDate -- dodano ten wiersz:AND t1.IncidentID>=t2.IncidentIDGROUP BY t1.LicenseNumber .Kwota biletuZAMÓW PRZEZ t1.Numer licencji, t1.IncidentDate; /* --------- zewnętrzna aplikacja --------- */ SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FROM dbo.SpeedingTickets AS t1OUTER APPLY( SELECT TicketAmount FROM dbo.SpeedingTickets WHERE LicenseNumber =t1.LicenseNumber AND IncidentDate <=t1.IncidentDate -- dodano ten wiersz:AND IncidentID <=t1.IncidentID) AS t2GROUP BY t1.LicenseNumber.Incident1.Dt1. BY t1.LicenseNumber, t1.IncidentDate; /* --------- SUM() OVER przy użyciu RANGE --------- */ SELECT NumerLicencji, DataIncydentu, KwotaBiletu, Suma_Ruchu =SUM(KwotaBiletu) OVER ( PARTITION BY NumerLicencji ORDER BY DataIncydentu, IncidentID ZAKRES BEZ OGRANICZEŃ PRECEDING -- dodano tę kolumnę ^^^^^^^^^^^^ ) FROM dbo.SpeedingTickets ORDER BY LicenseNumber, IncidentDate; /* --------- SUM() OVER przy użyciu ROWS --------- */ SELECT NumerLicencji, DataIncydentu, KwotaBiletu, Suma_Ruchu =SUM(KwotaBiletu) OVER ( PARTITION BY NumerLicencji ORDER BY DataIncydentu, IncidentID ROWS UNBOUNDED PRECEDING -- dodano tę kolumnę ^^^^^^^^^^^^ ) FROM dbo.SpeedingTickets ORDER BY LicenseNumber, IncidentDate; /* --------- iteracja oparta na zestawie --------- */ DECLARE @x TABLE( -- dodał tę kolumnę i uczynił ją PK:IncidentID INT PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATA NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL, RunningTotal DECIMAL(7,2) NOT NULL, rn INT NOT NULL); -- dodano dodatkową kolumnę do INSERT/SELECT:INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount, ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate , IncidentID) -- i dodałem tę kolumnę rozstrzygającą ------------------------------^^^^^^^^ ^^^^ Z dbo.SpeedingTickets; -- reszta rozwiązania iteracyjnego opartego na zbiorach pozostała niezmieniona Inną komplikacją, na którą możesz się natknąć, jest to, że nie szukasz całego stołu, ale raczej podgrupy (powiedzmy, w tym przypadku, pierwszy tydzień stycznia). Musisz wprowadzić poprawki, dodając
WHEREklauzul i pamiętaj o tych predykatach, gdy masz skorelowane podzapytania.