SQL Server 2005 dodał możliwość uwzględniania kolumn bez klucza w indeksie nieklastrowym. W SQL Server 2000 i wcześniejszych, dla indeksu nieklastrowego, wszystkie kolumny zdefiniowane dla indeksu były kolumnami kluczowymi, co oznaczało, że były częścią każdego poziomu indeksu, od korzenia do poziomu liścia. Gdy kolumna jest zdefiniowana jako kolumna dołączona, jest tylko częścią poziomu liścia. Books Online odnotowuje następujące zalety dołączonych kolumn:
- Mogą to być typy danych niedozwolone jako kolumny klucza indeksu.
- Nie są one brane pod uwagę przez aparat bazy danych podczas obliczania liczby kolumn klucza indeksu lub rozmiaru klucza indeksu.
Na przykład kolumna varchar(max) nie może być częścią klucza indeksu, ale może być uwzględnioną kolumną. Co więcej, ta kolumna varchar(max) nie wlicza się do limitu 900 bajtów (lub 16 kolumn) nałożonego na klucz indeksu.
W dokumentacji odnotowuje się również następujące korzyści w zakresie wydajności:
Indeks z kolumnami bez klucza może znacznie poprawić wydajność zapytania, gdy wszystkie kolumny w zapytaniu są uwzględnione w indeksie jako kolumny klucza lub kolumny bez klucza. Wzrost wydajności jest osiągany, ponieważ optymalizator zapytań może zlokalizować wszystkie wartości kolumn w indeksie; brak dostępu do danych tabeli lub indeksu klastrowego, co powoduje mniejszą liczbę operacji we/wy dysku.Możemy wywnioskować, że niezależnie od tego, czy kolumny indeksu są kolumnami kluczowymi, czy niekluczowymi, uzyskujemy poprawę wydajności w porównaniu do sytuacji, gdy wszystkie kolumny nie są częścią indeksu. Ale czy istnieje różnica w wydajności między tymi dwiema odmianami?
Konfiguracja
Zainstalowałem kopię bazy danych AdventuresWork2012 i zweryfikowałem indeksy tabeli Sales.SalesOrderHeader przy użyciu wersji sp_helpindex firmy Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Indeksy domyślne dla Sales.SalesOrderHeader
Zaczniemy od prostego zapytania do testowania, które pobiera dane z wielu kolumn:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Jeśli wykonamy to w bazie danych AdventureWorks2012 przy użyciu Eksploratora planów SQL Sentry i sprawdzimy plan oraz dane wyjściowe tabeli we/wy, zobaczymy, że otrzymujemy klastrowane skanowanie indeksu z 689 odczytami logicznymi:
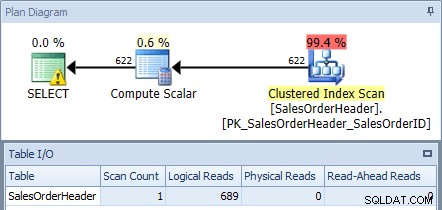
Plan wykonania z oryginalnego zapytania
(W Management Studio można zobaczyć metryki we/wy za pomocą SET STATISTICS IO ON; .)
SELECT ma ikonę ostrzeżenia, ponieważ optymalizator zaleca indeks dla tego zapytania:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
Najpierw utworzymy indeks zalecany przez optymalizator (o nazwie NCI1_included), a także odmianę ze wszystkimi kolumnami jako kolumnami kluczowymi (o nazwie NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Jeśli ponownie uruchomimy oryginalne zapytanie, raz wskazując je za pomocą NCI1, a raz wskazując je za pomocą NCI1_included, widzimy plan podobny do oryginalnego, ale tym razem istnieje wyszukiwanie indeksu każdego indeksu nieklastrowanego, z równoważnymi wartościami dla tabeli I/ O i podobne koszty (oba około 0,006):
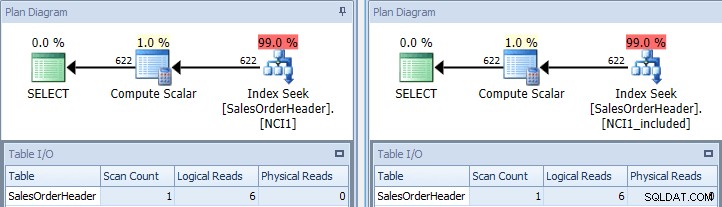
Pierwotne zapytanie z wyszukiwaniem indeksu – klucz po lewej, wstaw na właściwy
(Liczba skanowania nadal wynosi 1, ponieważ wyszukiwanie indeksu jest w rzeczywistości ukrytym skanowaniem zakresu).
Teraz baza danych AdventureWorks2012 nie jest reprezentatywna dla produkcyjnej bazy danych pod względem rozmiaru, a jeśli spojrzymy na liczbę stron w każdym indeksie, zobaczymy, że są one dokładnie takie same:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
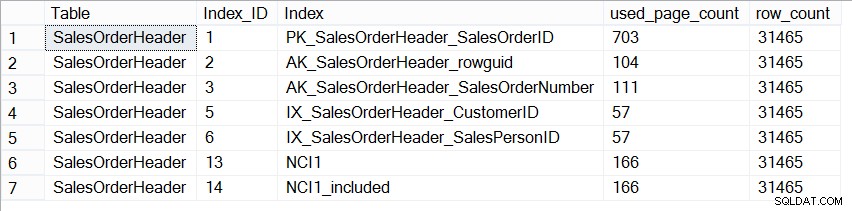
Rozmiar indeksów w Sales.SalesOrderHeader
Jeśli patrzymy na wydajność, idealnym (i przyjemniejszym) jest testowanie z większym zestawem danych.
Test 2
Mam kopię bazy danych AdventureWorks2012, która ma tabelę SalesOrderHeader z ponad 200 milionami wierszy (skrypt TUTAJ), więc utwórzmy te same indeksy nieklastrowane w tej bazie danych i ponownie uruchom zapytania:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
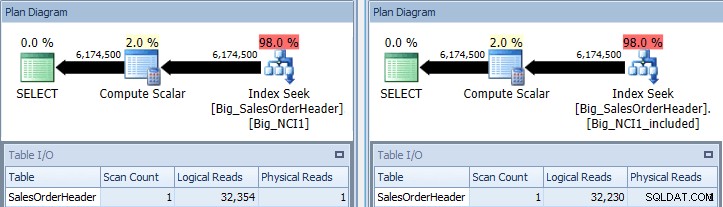
Oryginalne zapytanie z wyszukiwaniem indeksu względem Big_NCI1 (l) i Big_NCI1_Included ( r)
Teraz otrzymujemy trochę danych. Zapytanie zwraca ponad 6 milionów wierszy, a wyszukanie każdego indeksu wymaga nieco ponad 32 000 odczytów, a szacowany koszt jest taki sam dla obu zapytań (31.233). Nie ma jeszcze różnic w wydajności, a jeśli sprawdzimy rozmiar indeksów, zobaczymy, że indeks z dołączonymi kolumnami ma o 5578 stron mniej:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Rozmiar indeksów w Sales.Big_SalesOrderHeader
Jeśli zagłębimy się w to dalej i sprawdzimy dm_dm_index_physical_stats, zobaczymy, że różnica istnieje na pośrednich poziomach indeksu:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
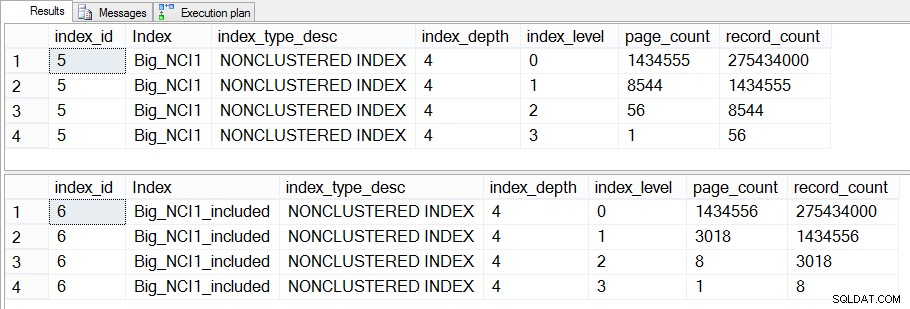
Rozmiar indeksów (w zależności od poziomu) w Sales.Big_SalesOrderHeader
Różnica między pośrednimi poziomami obu indeksów wynosi 43 MB, co może nie jest znaczące, ale prawdopodobnie nadal skłaniałbym się do tworzenia indeksu z dołączonymi kolumnami, aby zaoszczędzić miejsce – zarówno na dysku, jak iw pamięci. Z perspektywy zapytań nadal nie widzimy dużych zmian w wydajności między indeksem ze wszystkimi kolumnami w kluczu a indeksem z dołączonymi kolumnami.
Test 3
Na potrzeby tego testu zmieńmy zapytanie i dodajmy filtr dla [SubTotal] >= 100 do klauzuli WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
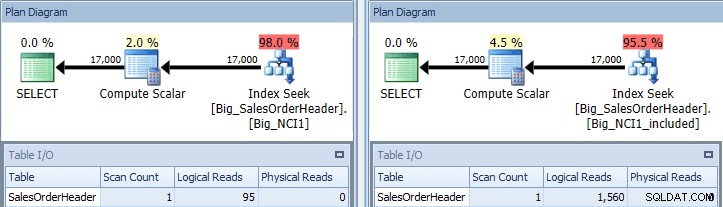
Plan wykonania zapytania z predykatem SubTotal dla obu indeksów
Teraz widzimy różnicę we/wy (95 odczytów w porównaniu z 1560), koszt (0,848 w porównaniu z 1,55) oraz subtelną, ale wartą uwagi różnicę w planie zapytań. Podczas używania indeksu ze wszystkimi kolumnami w kluczu, predykatem wyszukiwania jest CustomerID i SubTotal:
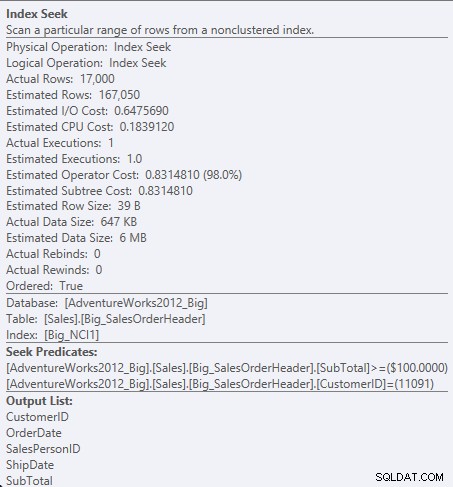
Wyszukiwanie predykatu względem NCI1
Ponieważ SubTotal jest drugą kolumną w kluczu indeksu, dane są uporządkowane, a SubTotal istnieje na pośrednich poziomach indeksu. Mechanizm może wyszukiwać bezpośrednio do pierwszego rekordu z identyfikatorem klienta 11091 i sumą częściową większą lub równą 100, a następnie czytać indeks, aż nie będzie już więcej rekordów dla identyfikatora klienta 11091.
W przypadku indeksu z dołączonymi kolumnami suma częściowa istnieje tylko na poziomie liścia indeksu, więc CustomerID jest predykatem wyszukiwania, a suma pośrednia jest predykatem rezydualnym (wymienionym jako predykat na zrzucie ekranu):
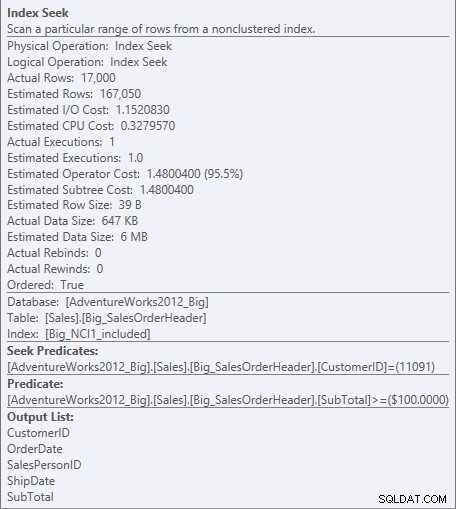
Wyszukuj predykat i predykat rezydualny względem NCI1_included
Wyszukiwarka może wyszukiwać bezpośrednio do pierwszego rekordu, w którym IDKlienta wynosi 11091, ale potem musi przejrzeć każdy rekord dla CustomerID 11091, aby sprawdzić, czy suma częściowa wynosi 100 lub więcej, ponieważ dane są uporządkowane według CustomerID i SalesOrderID (klucz klastrowania).
Test 4
Wypróbujemy jeszcze jedną odmianę naszego zapytania i tym razem dodamy ORDER BY:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
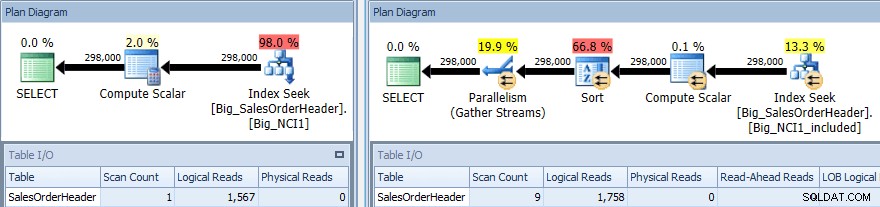
Plan wykonania zapytania z SORT względem obu indeksów
Ponownie mamy zmianę we/wy (choć bardzo niewielką), zmianę kosztu (1,5 vs 9,3) i znacznie większą zmianę kształtu planu; widzimy również większą liczbę skanów (1 vs 9). Zapytanie wymaga posortowania danych według sum częściowych; gdy suma częściowa jest częścią klucza indeksu, jest on sortowany, więc gdy pobierane są rekordy dla identyfikatora klienta 11091, są one już w żądanej kolejności.
Jeśli SubTotal istnieje jako uwzględniona kolumna, rekordy dla CustomerID 11091 muszą zostać posortowane, zanim będą mogły zostać zwrócone użytkownikowi, dlatego optymalizator wstawia w zapytanie operator sortowania. W rezultacie zapytanie korzystające z indeksu Big_NCI1_included również żąda (i otrzymuje) przyznanie pamięci w wysokości 29 312 KB, co jest godne uwagi (i można je znaleźć we właściwościach planu).
Podsumowanie
Pierwotnym pytaniem, na które chcieliśmy odpowiedzieć, było to, czy zobaczymy różnicę w wydajności, gdy zapytanie użyje indeksu ze wszystkimi kolumnami w kluczu, w porównaniu z indeksem z większością kolumn zawartych na poziomie liścia. W naszym pierwszym zestawie testów nie było różnicy, ale w naszym trzecim i czwartym teście była. To ostatecznie zależy od zapytania. Przyjrzeliśmy się tylko dwóm wariantom – jeden miał dodatkowy predykat, drugi ORDER BY – istnieje znacznie więcej.
Deweloperzy i administratorzy baz danych muszą zrozumieć, że uwzględnienie kolumn w indeksie ma wiele zalet, ale nie zawsze będą one działać tak samo, jak indeksy zawierające wszystkie kolumny w kluczu. Może być kuszące, aby przenieść kolumny, które nie są częścią predykatów i sprzężeń poza klucz, i po prostu je uwzględnić, aby zmniejszyć ogólny rozmiar indeksu. Jednak w niektórych przypadkach wymaga to więcej zasobów do wykonania zapytania i może obniżyć wydajność. Degradacja może być nieznaczna; to może nie być… nie będziesz wiedział, dopóki nie przetestujesz. Dlatego przy projektowaniu indeksu ważne jest, aby pomyśleć o kolumnach po wiodącej – i zrozumieć, czy muszą one być częścią klucza (np. dlatego, że utrzymanie uporządkowanych danych przyniesie korzyść), czy też mogą służyć swojemu celowi jako zawarte kolumny.
Jak zwykle w przypadku indeksowania w SQL Server, musisz przetestować swoje zapytania za pomocą indeksów, aby określić najlepszą strategię. Pozostaje sztuką i nauką – próba znalezienia minimalnej liczby indeksów, aby zaspokoić jak najwięcej zapytań.