Rozważ następujące zapytanie AdventureWorks, które zwraca identyfikatory transakcji tabeli historii dla produktu o identyfikatorze 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Optymalizator zapytań szybko znajduje wydajny plan wykonania z dokładnie poprawnym oszacowaniem liczności (liczba wierszy), jak pokazano w SQL Sentry Plan Explorer:

Teraz powiedzmy, że chcemy znaleźć identyfikatory transakcji historii dla produktu AdventureWorks o nazwie „Metal Plate 2”. Istnieje wiele sposobów wyrażenia tego zapytania w T-SQL. Jedna naturalna formuła to:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Plan wykonania jest następujący:
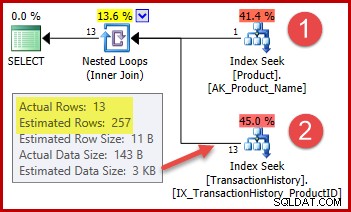
Strategia to:
- Odszukaj identyfikator produktu w tabeli Produkt z podanej nazwy
- Zlokalizuj wiersze dla tego identyfikatora produktu w tabeli Historia
Szacowana liczba wierszy w kroku 1 jest dokładnie prawidłowa, ponieważ używany indeks jest zadeklarowany jako unikalny i zawiera klucz tylko w nazwie produktu. Test równości na „Metal Plate 2” gwarantuje zatem zwrócenie dokładnie jednego wiersza (lub zero wierszy, jeśli określimy nazwę produktu, która nie istnieje).
Podświetlone oszacowanie 257 wierszy dla kroku drugiego jest mniej dokładne:w rzeczywistości napotkano tylko 13 wierszy. Ta rozbieżność powstaje, ponieważ optymalizator nie wie, który konkretny identyfikator produktu jest powiązany z produktem o nazwie „Metal Plate 2”. Traktuje wartość jako nieznaną, generując oszacowanie kardynalności na podstawie informacji o średniej gęstości. Obliczenie wykorzystuje elementy z obiektu statystyk pokazanego poniżej:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
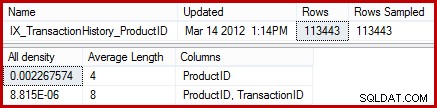
Statystyki pokazują, że tabela zawiera 113443 wierszy z 441 unikalnymi identyfikatorami produktów (1 / 0,002267574 =441). Zakładając, że rozkład wierszy w identyfikatorach produktów jest jednolity, oszacowanie kardynalności oczekuje, że identyfikator produktu będzie zgodny (113443 / 441) =średnio 257,24 wierszy. Jak się okazuje, rozkład nie jest szczególnie równomierny; jest tylko 13 rzędów dla produktu „Metal Plate 2”.
Na bok
Być może myślisz, że oszacowanie 257 wierszy powinno być dokładniejsze. Na przykład, biorąc pod uwagę, że identyfikatory i nazwy produktów są ograniczone jako unikatowe, SQL Server może automatycznie przechowywać informacje o tej relacji jeden-do-jednego. Będzie wtedy wiedział, że „Metal Plate 2” jest powiązany z produktem o identyfikatorze 479 i wykorzysta te informacje do wygenerowania dokładniejszego oszacowania za pomocą histogramu ProductID:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
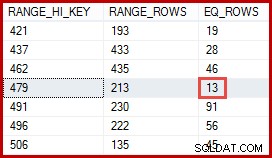
Oszacowanie 13 wierszy wyprowadzonych w ten sposób byłoby dokładnie poprawne. Niemniej jednak oszacowanie 257 wierszy nie było nieuzasadnione, biorąc pod uwagę dostępne informacje statystyczne i normalne założenia upraszczające (takie jak rozkład jednorodny) stosowane obecnie przez oszacowanie kardynalności. Dokładne szacunki są zawsze dobre, ale „rozsądne” szacunki są również całkowicie akceptowalne.
Łączenie dwóch zapytań
Załóżmy, że chcemy teraz zobaczyć wszystkie identyfikatory historii transakcji, w których identyfikator produktu to 421 LUB nazwa produktu to „Metal Plate 2”. Naturalnym sposobem połączenia dwóch poprzednich zapytań jest:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Plan wykonania jest teraz nieco bardziej złożony, ale nadal zawiera rozpoznawalne elementy planów pojedynczego predykatu:
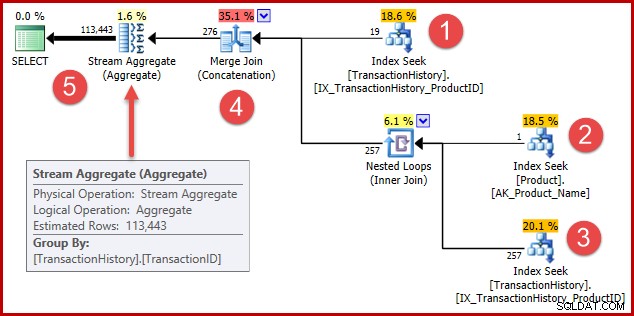
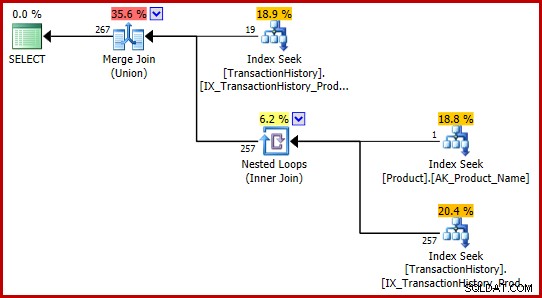
Strategia to:
- Znajdź rekordy historii dla produktu 421
- Sprawdź identyfikator produktu o nazwie „Metal Plate 2”
- Znajdź rekordy historii dla identyfikatora produktu znalezionego w kroku 2
- Połącz wiersze z kroków 1 i 3
- Usuń wszelkie duplikaty (ponieważ produkt 421 może mieć również nazwę „Metal Plate 2”)
Kroki od 1 do 3 są dokładnie takie same jak poprzednio. Te same szacunki są tworzone z tych samych powodów. Krok 4 jest nowy, ale bardzo prosty:łączy oczekiwanych 19 wierszy z oczekiwanymi 257 wierszami, co daje szacunkową liczbę 276 wierszy.
Krok 5 jest interesujący. Agregacja strumienia usuwająca duplikaty ma szacunkową wartość wejściową 276 wierszy i szacunkową wartość wyjściową 113443 wierszy. Agregat, który wyprowadza więcej wierszy niż otrzymuje, wydaje się niemożliwy, prawda?
* Jeśli korzystasz z modelu szacowania kardynalności sprzed 2014 r., zobaczysz szacunkową liczbę 102099 wierszy.
Błąd szacowania kardynalności
Niemożliwe oszacowanie Stream Aggregate w naszym przykładzie jest spowodowane błędem w oszacowaniu kardynalności. Jest to interesujący przykład, więc omówimy go szczegółowo.
Usunięcie podzapytania
Może Cię zaskoczyć informacja, że optymalizator zapytań SQL Server nie działa bezpośrednio z podzapytaniami. Są one usuwane z logicznego drzewa zapytań na wczesnym etapie procesu kompilacji i zastępowane równoważną konstrukcją, z którą optymalizator jest skonfigurowany do pracy i uzasadnienia. Optymalizator ma kilka reguł, które usuwają podzapytania. Można je wymienić według nazwy za pomocą następującego zapytania (odnośny DMV jest minimalnie udokumentowany, ale nie jest obsługiwany):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Wyniki (na SQL Server 2014):
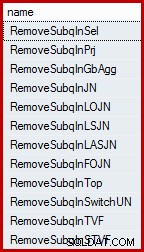
Połączone zapytanie testowe ma dwa predykaty ("wybory" w kategoriach relacyjnych) w tabeli historii, połączone przez OR . Jeden z tych predykatów zawiera podzapytanie. Całe poddrzewo (zarówno predykaty, jak i podzapytanie) jest przekształcane przez pierwszą regułę na liście („usuń podzapytanie z zaznaczenia”) w częściowe sprzężenie nad sumą poszczególnych predykatów. Chociaż nie jest możliwe przedstawienie wyniku tej wewnętrznej transformacji dokładnie przy użyciu składni T-SQL, jest to prawie takie samo:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); To trochę niefortunne, że moje aproksymacja T-SQL wewnętrznego drzewa po usunięciu podzapytania zawiera podzapytanie, ale w języku procesora zapytań tak nie jest (jest to sprzężenie semi). Jeśli wolisz zobaczyć surowy formularz wewnętrzny zamiast mojej próby stworzenia odpowiednika T-SQL, zapewniam, że będzie on dostępny za chwilę.
Wskazówka dotycząca nieudokumentowanej kwerendy zawarta w powyższym języku T-SQL ma zapobiec późniejszej transformacji tym z was, którzy chcą zobaczyć przekształconą logikę w formie planu wykonania. Poniższe adnotacje pokazują pozycje dwóch predykatów po przekształceniu:
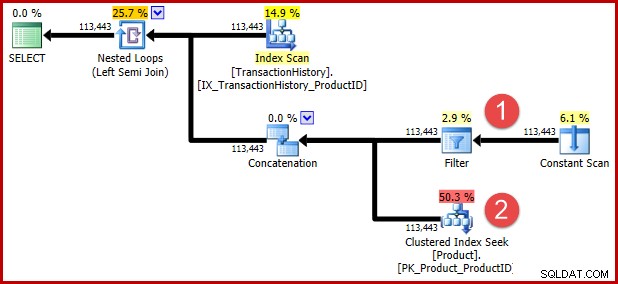
Intuicja stojąca za transformacją jest taka, że wiersz historii kwalifikuje się, jeśli którykolwiek z predykatów jest spełniony. Bez względu na to, jak pomocne jest moje przybliżone przedstawienie T-SQL i planu wykonania, mam nadzieję, że jest przynajmniej dość jasne, że przepisanie wyraża te same wymagania, co oryginalne zapytanie.
Powinienem podkreślić, że optymalizator nie generuje dosłownie alternatywnej składni T-SQL ani nie tworzy kompletnych planów wykonania na etapach pośrednich. Powyższe reprezentacje T-SQL i planu wykonania mają na celu wyłącznie pomoc w zrozumieniu. Jeśli interesują Cię surowe szczegóły, obiecana wewnętrzna reprezentacja przekształconego drzewa zapytań (nieco zredagowana dla jasności/przestrzeń):
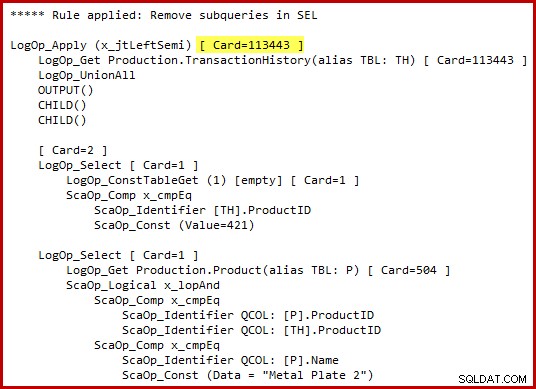
Zwróć uwagę na podświetloną szacunkową kardynalność Zastosuj półzłącze. Jest to 113443 wierszy przy użyciu estymatora kardynalności 2014 (102099 wierszy przy użyciu starego CE). Należy pamiętać, że tabela historii AdventureWorks zawiera łącznie 113443 wierszy, co oznacza 100% selektywność (90% dla starego CE).
Widzieliśmy wcześniej, że zastosowanie jednego z tych predykatów powoduje tylko niewielką liczbę dopasowań:19 wierszy dla produktu ID 421 i 13 wierszy (szacunkowo 257) dla „Metal Plate 2”. Szacowanie, że alternatywa (OR) z dwóch predykatów zwróci wszystkie wiersze w tabeli podstawowej wydaje się całkowicie szalone.
Szczegóły błędu
Szczegóły obliczeń selektywności dla sprzężenia częściowego są widoczne tylko w SQL Server 2014, gdy używany jest nowy estymator liczności z (nieudokumentowaną) flagą śledzenia 2363. Prawdopodobnie można zobaczyć coś podobnego w przypadku zdarzeń rozszerzonych, ale dane wyjściowe flagi śledzenia są wygodniejsze do wykorzystania tutaj. Odpowiednia sekcja danych wyjściowych jest pokazana poniżej:
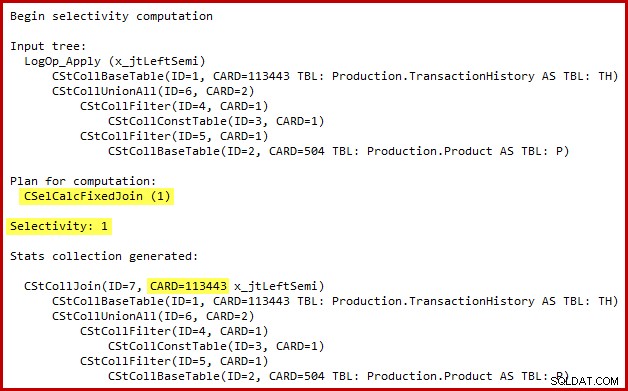
Estymator kardynalności wykorzystuje kalkulator Fixed Join ze 100% selektywnością. W konsekwencji szacowana liczność wyjściowa sprzężenia semi jest taka sama jak jego dane wejściowe, co oznacza, że wszystkie 113443 wiersze z tabeli historii powinny się zakwalifikować.
Dokładna natura tego błędu polega na tym, że obliczenia selektywności sprzężenia semi pomijają wszystkie predykaty umieszczone poza sumą w drzewie wejściowym. Na poniższej ilustracji brak predykatów na samym sprzężeniu semi oznacza, że każdy wiersz zostanie zakwalifikowany; ignoruje efekt predykatów poniżej konkatenacji (unij wszystko).
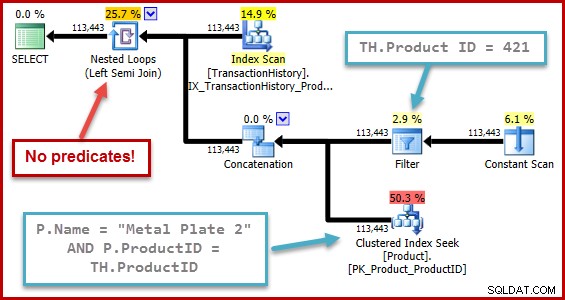
To zachowanie jest tym bardziej zaskakujące, gdy weźmie się pod uwagę, że obliczenia selektywności działają na reprezentacji drzewa, którą wygenerował sam optymalizator (kształt drzewa i położenie predykatów jest wynikiem usunięcia podzapytania).
Podobny problem występuje z estymatorem liczności sprzed 2014 r., ale ostateczne oszacowanie jest ustalone na 90% szacowanego wejścia semi-join (z powodów zabawnych związanych z odwróconym stałym oszacowaniem predykatu 10%, który jest zbyt dużym odwróceniem, aby uzyskać do).
Przykłady
Jak wspomniano powyżej, ten błąd pojawia się, gdy estymacja jest wykonywana dla sprzężenia semi z powiązanymi predykatami umieszczonymi poza sumą wszystkich. To, czy ten wewnętrzny układ wystąpi podczas optymalizacji zapytania, zależy od oryginalnej składni T-SQL i dokładnej sekwencji wewnętrznych operacji optymalizacji. Poniższe przykłady pokazują niektóre przypadki, w których błąd występuje i nie występuje:
Przykład 1
Ten pierwszy przykład zawiera trywialną zmianę w zapytaniu testowym:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Szacowany plan wykonania to:
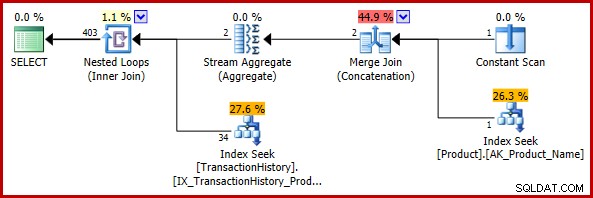
Ostateczne oszacowanie 403 wierszy jest niezgodne z szacunkami wejściowymi sprzężeń zagnieżdżonych pętli, ale nadal jest rozsądne (w sensie omówionym wcześniej). Jeśli napotkano błąd, ostateczne oszacowanie wyniosłoby 113443 wierszy (lub 102099 wierszy w przypadku modelu CE sprzed 2014 r.).
Przykład 2
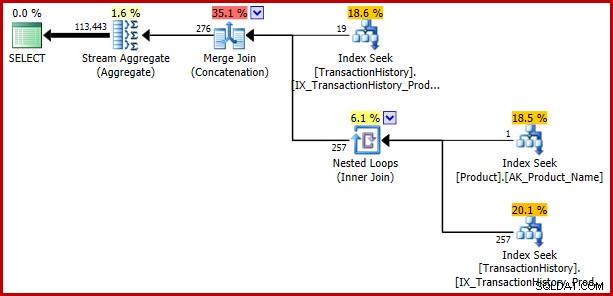
Jeśli miałbyś się spieszyć i przepisać wszystkie swoje ciągłe porównania jako trywialne podzapytania, aby uniknąć tego błędu, spójrz, co się stanie, jeśli dokonamy kolejnej trywialnej zmiany, tym razem zastępując test równości w drugim predykacie IN. Znaczenie zapytania pozostaje niezmienione:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Błąd powraca:
Przykład 3
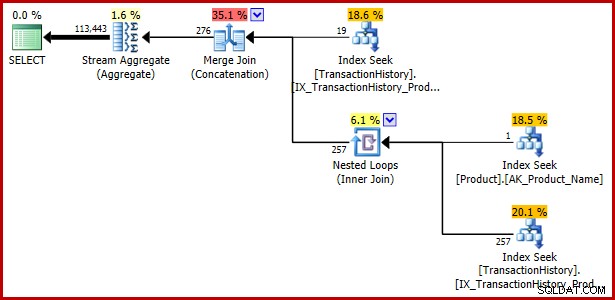
Chociaż ten artykuł do tej pory koncentrował się na predykacie rozłącznym zawierającym podzapytanie, poniższy przykład pokazuje, że ta sama specyfikacja zapytania wyrażona przy użyciu EXISTS i UNION ALL jest również podatna na ataki:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Plan wykonania:
Przykład 4
Oto jeszcze dwa sposoby wyrażenia tego samego logicznego zapytania w T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Żadne z zapytań nie napotyka błędu i oba generują ten sam plan wykonania:
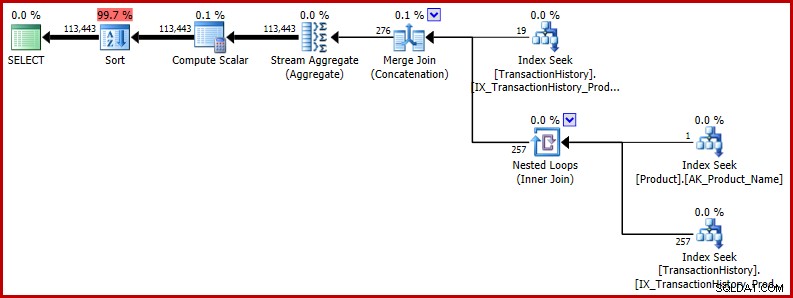
Te sformułowania T-SQL tworzą plan wykonania z całkowicie spójnymi (i rozsądnymi) szacunkami.
Przykład 5
Być może zastanawiasz się, czy niedokładne oszacowanie jest ważne. W dotychczas przedstawionych przypadkach tak nie jest, przynajmniej nie bezpośrednio. Problemy pojawiają się, gdy błąd występuje w większym zapytaniu, a niepoprawne oszacowanie wpływa na decyzje optymalizatora w innym miejscu. Jako minimalnie rozszerzony przykład rozważ zwrócenie wyników naszego zapytania testowego w losowej kolejności:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Plan wykonania pokazuje, że nieprawidłowe oszacowanie wpływa na późniejsze operacje. Na przykład jest to podstawa przyznania pamięci zarezerwowanej dla sortowania:
Jeśli chcesz zobaczyć bardziej rzeczywisty przykład potencjalnego wpływu tego błędu, spójrz na to ostatnie pytanie od Richarda Mansella w witrynie Q &A SQLPerformance.com, answer.SQLPerformance.com.
Podsumowanie i przemyślenia końcowe
Ten błąd jest wywoływany, gdy optymalizator wykonuje oszacowanie kardynalności dla sprzężenia częściowego w określonych okolicznościach. Jest to trudny błąd do wykrycia i obejścia z wielu powodów:
- Nie ma wyraźnej składni T-SQL określającej sprzężenie semi, więc trudno z góry stwierdzić, czy dane zapytanie będzie podatne na ten błąd.
- Optymalizator może wprowadzić sprzężenie semi w wielu różnych okolicznościach, z których nie wszystkie są oczywistymi kandydatami do sprzężenia semi.
- Kłopotliwe semi-join jest często przekształcane w coś innego przez późniejszą aktywność optymalizatora, więc nie możemy nawet polegać na operacji semi-join w ostatecznym planie wykonania.
- Nie każdy dziwnie wyglądający oszacowanie kardynalności jest spowodowany tym błędem. Rzeczywiście, wiele przykładów tego typu jest oczekiwanym i nieszkodliwym efektem ubocznym normalnego działania optymalizatora.
- Błędne oszacowanie selektywności semi-join zawsze będzie wynosić 90% lub 100% danych wejściowych, ale zwykle nie będzie to odpowiadało liczności tabeli użytej w planie. Co więcej, liczność wejściowa półłączenia zastosowana w obliczeniach może nawet nie być widoczna w ostatecznym planie wykonania.
- Zazwyczaj istnieje wiele sposobów wyrażenia tego samego logicznego zapytania w T-SQL. Niektóre z nich wywołają błąd, a inne nie.
Te względy utrudniają udzielenie praktycznych porad, aby wykryć lub obejść ten błąd. Z pewnością warto sprawdzić plany wykonania pod kątem „oburzających” szacunków i zbadać zapytania o wydajności znacznie gorszej niż oczekiwano, ale oba te czynniki mogą mieć przyczyny niezwiązane z tym błędem. To powiedziawszy, warto w szczególności sprawdzać zapytania, które zawierają alternatywę predykatów i podzapytania. Jak pokazują przykłady w tym artykule, nie jest to jedyny sposób na napotkanie błędu, ale spodziewam się, że będzie to powszechny.
Jeśli masz szczęście, że korzystasz z programu SQL Server 2014 z włączonym nowym estymatorem liczności, możesz potwierdzić błąd, ręcznie sprawdzając dane wyjściowe flagi śledzenia 2363 pod kątem ustalonego 100% oszacowania selektywności dla sprzężenia częściowego, ale jest to mało wygodne. Oczywiście nie będziesz chciał używać nieudokumentowanych flag śledzenia w systemie produkcyjnym.
Raport o błędzie User Voice dotyczący tego problemu można znaleźć tutaj. Zagłosuj i skomentuj, jeśli chcesz, aby ten problem został zbadany (i ewentualnie naprawiony).



