W tym miesiącu we wtorek T-SQL poprowadzi Mike Donnelly (@SQLMD), który podsumowuje temat w następujący sposób:
Temat w tym miesiącu jest prosty, ale bardzo otwarty. Musisz nauczyć się czegoś nowego, a następnie napisać na blogu post wyjaśniający to.Cóż, od chwili, gdy Mike ogłosił temat, tak naprawdę nie zamierzałem uczyć się niczego nowego, a ponieważ zbliżał się weekend i wiedziałem, że poniedziałek zaatakuje mnie obowiązkiem ławy przysięgłych, pomyślałem, że będę musiał siedzieć w tym miesiąc przed.
Następnie Martin Smith nauczył mnie czegoś, czego albo nigdy nie wiedziałem, albo wiedziałem dawno temu, ale zapomniałem (czasami nie wiesz tego, czego nie wiesz, a czasami nie pamiętasz tego, czego nigdy nie wiedziałeś, a czego nie możesz Zapamiętaj). Pamiętam, że zmiana kolumny z NOT NULL na NULL powinien być operacją tylko na metadanych, przy czym zapisy na dowolnej stronie są odraczane do momentu zaktualizowania tej strony z innych powodów, ponieważ NULL bitmapa tak naprawdę nie musiałaby istnieć, dopóki co najmniej jeden wiersz nie może stać się NULL .
W tym samym poście @ypercube przypomniał mi również ten trafny cytat z Books Online (literówka i wszystko inne):
Zmiana kolumny z NOT NULL na NULL nie jest obsługiwana jako operacja w trybie online, gdy zmieniona kolumna odwołuje się do indeksów nieklastrowanych.„Operacja nie online” może być interpretowana jako „operacja nie tylko na metadanych” – co oznacza, że w rzeczywistości będzie to operacja rozmiaru danych (im większy indeks, tym dłużej to potrwa).
Postanowiłem to udowodnić za pomocą dość prostego (ale długotrwałego) eksperymentu z konkretną kolumną docelową, aby przekonwertować z NOT NULL na NULL . Utworzyłbym 3 tabele, wszystkie z klastrowanym kluczem podstawowym, ale każda z innym indeksem nieklastrowanym. Jedna miałaby kolumnę docelową jako kolumnę kluczową, druga jako INCLUDE kolumna, a trzecia w ogóle nie odwołuje się do kolumny docelowej.
Oto moje tabele i sposób ich wypełnienia:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Każda tabela miała 100 000 wierszy, indeksy klastrowe miały 310 stron, a indeksy nieklastrowe miały 272 strony (test1 i test2 ) lub 174 strony (test3 ). (Te wartości są łatwe do uzyskania z sys.dm_db_index_physical_stats .)
Następnie potrzebowałem prostego sposobu na przechwytywanie operacji, które były rejestrowane na poziomie strony – wybrałem sys.fn_dblog() , chociaż mogłem kopać głębiej i bezpośrednio przeglądać strony. Nie zawracałem sobie głowy przekazywaniem wartości LSN do funkcji, ponieważ nie uruchamiałem tego w środowisku produkcyjnym i nie dbałem zbytnio o wydajność, więc po testach po prostu zrzuciłem wyniki funkcji, wyłączając wszelkie dane, które został zarejestrowany przed ALTER TABLE operacje.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Teraz mogłem przeprowadzić moje testy, które były znacznie prostsze niż konfiguracja.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Teraz mogłem sprawdzić operacje, które zostały zarejestrowane w każdym przypadku:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Wyniki wydają się sugerować, że każda strona liścia indeksu nieklastrowanego jest dotykana w przypadkach, w których kolumna docelowa została w jakikolwiek sposób wymieniona w indeksie, ale takie operacje nie występują w przypadku, gdy kolumna docelowa nie jest wymieniona w żadnej indeks nieklastrowy:
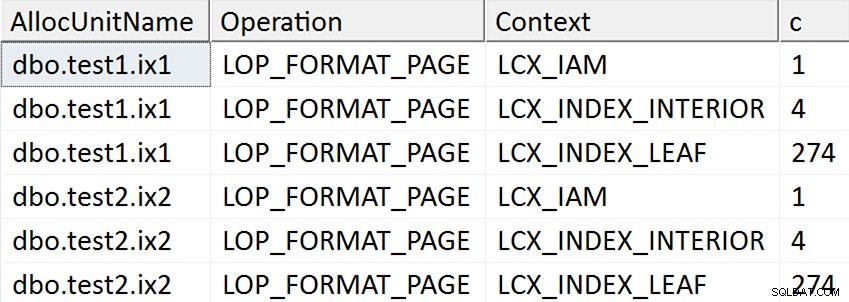
W rzeczywistości w pierwszych dwóch przypadkach przydzielane są nowe strony (możesz to sprawdzić za pomocą DBCC IND , jak zrobił to Spörri w swojej odpowiedzi), więc operacja może odbywać się online, ale to nie znaczy, że jest szybka (ponieważ nadal musi napisać kopię wszystkich tych danych i zrobić NULL zmiana bitmapy w ramach wypisywania każdej nowej strony i rejestrowania całej tej aktywności).
Myślę, że większość ludzi podejrzewałaby, że zmiana kolumny z NOT NULL na NULL byłyby tylko metadane we wszystkich scenariuszach, ale pokazałem tutaj, że nie jest to prawdą, jeśli do kolumny odwołuje się indeks nieklastrowany (i podobne rzeczy mają miejsce, niezależnie od tego, czy jest to klucz, czy INCLUDE kolumna). Być może tę operację można również zmusić do ONLINE w Azure SQL Database już dziś, czy będzie to możliwe w kolejnej głównej wersji? Niekoniecznie przyspieszy to rzeczywiste operacje fizyczne, ale zapobiegnie blokowaniu.
Nie testowałem tego scenariusza (a analiza, czy jest naprawdę online, i tak jest trudniejsza w Azure), ani nie testowałem go na stosie. Coś, do czego mogę wrócić w przyszłym poście. W międzyczasie uważaj na wszelkie założenia, które możesz poczynić w odniesieniu do operacji tylko na metadanych.