Uwaga:ten post został pierwotnie opublikowany tylko w naszym e-booku, Techniki wysokiej wydajności dla SQL Server, tom 2. Możesz dowiedzieć się o naszych e-bookach tutaj.
Podsumowanie:Ten artykuł analizuje zaskakujące zachowanie wyzwalaczy INSTEAD OF i ujawnia poważny błąd szacowania kardynalności w SQL Server 2014.
Wyzwalacze i wersjonowanie wierszy
Tylko wyzwalacze DML AFTER używają wersjonowania wierszy (w SQL Server 2005 i nowsze), aby zapewnić wstawiony i usunięte pseudo-tabele wewnątrz procedury wyzwalacza. Ten punkt nie jest wyraźnie zaznaczony w większości oficjalnej dokumentacji. W większości miejsc dokumentacja po prostu mówi, że wersjonowanie wierszy jest używane do tworzenia wstawionych i usunięte tabele w wyzwalaczach bez kwalifikacji (przykłady poniżej):
Wykorzystanie zasobów wersjonowania wierszy
Zrozumienie poziomów izolacji opartych na wersjonowaniu wierszy
Kontrolowanie wykonywania wyzwalaczy podczas zbiorczego importu danych
Przypuszczalnie oryginalne wersje tych wpisów zostały napisane przed dodaniem do produktu wyzwalaczy INSTEAD OF i nigdy nie były aktualizowane. Albo to, albo jest to proste (ale powtarzające się) przeoczenie.
W każdym razie sposób, w jaki wersjonowanie wierszy działa z wyzwalaczami AFTER, jest dość intuicyjny. Te wyzwalacze uruchamiają się po modyfikacje, o których mowa, zostały wykonane, więc łatwo jest zobaczyć, w jaki sposób utrzymywanie wersji zmodyfikowanych wierszy umożliwia silnikowi bazy danych dostarczenie wstawionych i usunięte pseudo-tabele. usunięty pseudotabela jest tworzona z wersji wierszy, których dotyczy problem, przed wprowadzeniem modyfikacji; wstawiony pseudotabela jest tworzona z wersji wierszy, których dotyczy problem, w momencie rozpoczęcia procedury wyzwalania.
Zamiast wyzwalaczy
Wyzwalacze INSTEAD OF są inne, ponieważ ten typ wyzwalacza DML całkowicie zastępuje wyzwalane działanie. wstawiono i usunięte pseudotabele reprezentują teraz zmiany, które by miały zostało wykonane, czy instrukcja wyzwalająca została faktycznie wykonana. Dla tych wyzwalaczy nie można używać wersji wierszy, ponieważ z definicji nie nastąpiły żadne modyfikacje. Tak więc, jeśli nie używasz wersji wierszowych, jak robi to SQL Server?
Odpowiedź jest taka, że SQL Server modyfikuje plan wykonania dla wyzwalającej instrukcji DML, gdy istnieje wyzwalacz INSTEAD OF. Zamiast bezpośrednio modyfikować tabele, których dotyczy problem, plan wykonania zapisuje informacje o zmianach w ukrytej tabeli roboczej. Ta tabela robocza zawiera wszystkie dane potrzebne do wykonania oryginalnych zmian, typ modyfikacji do wykonania w każdym wierszu (usunięcie lub wstawienie), a także wszelkie informacje potrzebne w wyzwalaczu dla klauzuli OUTPUT.
Plan wykonania bez wyzwalacza
Aby zobaczyć to wszystko w akcji, najpierw przeprowadzimy prosty test bez wyzwalacza INSTEAD OF:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Plan wykonania usunięcia jest bardzo prosty:
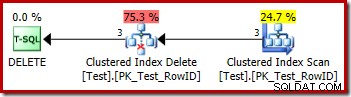
Każdy kwalifikujący się wiersz jest przekazywany bezpośrednio do operatora Clustered Index Delete, który go usuwa. Łatwe.
Plan wykonania z wyzwalaczem ZAMIAST
Teraz zmodyfikujmy test, aby zawierał wyzwalacz INSTEAD OF DELETE (który dla uproszczenia wykonuje tę samą akcję usuwania):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Plan wykonania polecenia DELETE jest teraz zupełnie inny:
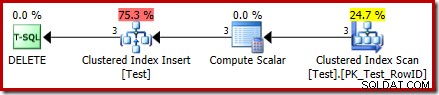
Operator Clustered Index Delete został zastąpiony przez Clustered Index Insert . Jest to wstawianie do ukrytej tabeli roboczej, której nazwa została zmieniona (w publicznej reprezentacji planu wykonania) na nazwę tabeli podstawowej, której dotyczy usunięcie. Zmiana nazwy następuje, gdy plan spektaklu XML jest generowany z wewnętrznej reprezentacji planu wykonania, więc nie ma udokumentowanego sposobu, aby zobaczyć ukryty stół roboczy.
W wyniku tej zmiany wydaje się, że plan wykonuje wstawienie do tabeli podstawowej, aby usunąć wiersze z niego. To mylące, ale przynajmniej ujawnia obecność wyzwalacza ZAMIAST. Zastąpienie operatora Insert przez Delete może być jeszcze bardziej mylące. Być może ideałem byłaby nowa ikona graficzna dla stołu roboczego ZAMIAST wyzwalacza? W każdym razie tak właśnie jest.
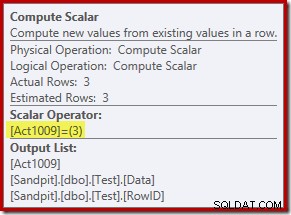
Nowy operator Compute Scalar definiuje typ akcji wykonywanej na każdym wierszu. Ten kod akcji jest liczbą całkowitą o następujących znaczeniach:
- 3 =USUŃ
- 4 =WSTAW
- 259 =USUŃ w planie MERGE
- 260 =WSTAW w planie MERGE
W przypadku tego zapytania akcja to stała 3, co oznacza, że każdy wiersz ma zostać usunięty :
Działania aktualizacji
Na marginesie, plan wykonania INSTEAD OF UPDATE zastępuje jeden operator Update przez dwa Zgrupowane wstawki indeksowe do tego samego ukrytego stołu roboczego – jeden dla wstawionych wiersze pseudotabeli i jeden dla usuniętych wiersze pseudotabeli. Przykładowy plan wykonania:

MERGE, który wykonuje UPDATE, tworzy również plan wykonania z dwoma wstawkami do tej samej tabeli bazowej z podobnych powodów:

Plan wykonania wyzwalacza
Plan wykonania korpusu spustowego ma również kilka interesujących funkcji:
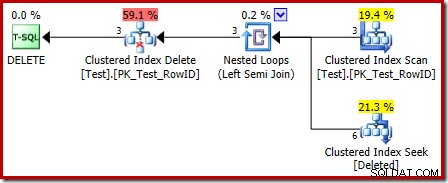
Pierwszą rzeczą, na którą należy zwrócić uwagę, jest to, że ikona graficzna używana dla usuniętej tabeli nie jest taka sama jak ikona używana w planach wyzwalania PO:
Reprezentacja w planie wyzwalania INSTEAD OF to Clustered Index Seek. Podstawowym obiektem jest ten sam wewnętrzny stół roboczy, który widzieliśmy wcześniej, chociaż tutaj jest nazwany usunięty zamiast podania nazwy tabeli bazowej, prawdopodobnie w celu zapewnienia spójności z wyzwalaczami AFTER.
Operacja wyszukiwania na usuniętych tabela może nie być taka, jakiej oczekiwałeś (jeśli oczekiwałeś wyszukiwania w RowID):
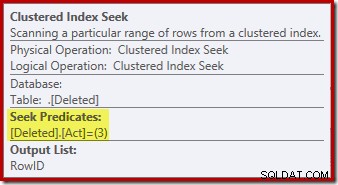
To „szukanie” zwraca wszystkie wiersze ze stołu roboczego, które mają kod akcji 3 (usuń), co jest dokładnie równoważne z Usuniętym skanowaniem operator widziany w planach AFTER wyzwalania. Ten sam wewnętrzny stół roboczy służy do przechowywania wierszy dla obu wstawionych i usunięte pseudo-tabele w wyzwalaczach INSTEAD OF. Odpowiednikiem wstawionego skanu jest wyszukiwanie kodu akcji 4 (co jest możliwe w przypadku usuwania wyzwalacz, ale wynik będzie zawsze pusty). W wewnętrznej tabeli roboczej nie ma żadnych indeksów poza nieunikalnym indeksem klastrowym w akcji sama kolumna. Ponadto z tym wewnętrznym indeksem nie są powiązane żadne statystyki.
Dotychczasowa analiza może sprawić, że będziesz się zastanawiać, gdzie jest wykonywane połączenie między kolumnami RowID. To porównanie ma miejsce dla operatora zagnieżdżonych pętli Left Semi Join jako predykatu rezydualnego:
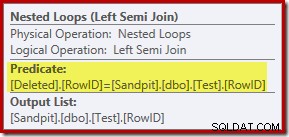
Teraz, gdy wiemy, że „szukanie” jest w rzeczywistości pełnym skanem usuniętych tabeli, plan wykonania wybrany przez optymalizator zapytań wydaje się dość nieefektywny. Ogólny przebieg planu wykonania polega na tym, że każdy wiersz z tabeli Test jest potencjalnie porównywany z całym zestawem usuniętych wierszy, co brzmi jak produkt kartezjański.
Oszczędność polega na tym, że złączenie jest sprzężeniem częściowym, co oznacza, że proces porównywania zatrzymuje się dla danego wiersza testowego, gdy tylko pierwszy usunięty wiersz spełnia predykat rezydualny. Niemniej strategia wydaje się ciekawa. Być może plan wykonania byłby lepszy, gdyby tabela Test zawierała więcej wierszy?
Test wyzwalania z 1000 wierszy
Poniższy skrypt może służyć do testowania wyzwalacza z większą liczbą wierszy. Zaczniemy od 1000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Plan wykonania korpusu wyzwalacza to teraz:
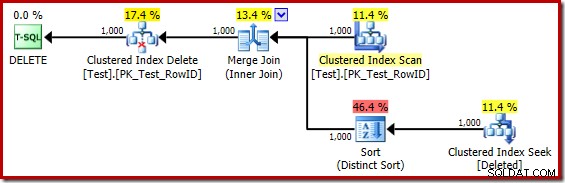
Mentalnie zastępując (wprowadzające w błąd) klastrowe wyszukiwanie indeksu usuniętym skanem, plan wygląda ogólnie całkiem nieźle. Optymalizator wybrał złącze scalające jeden-do-wielu zamiast sprzężenia półzagnieżdżonego pętli, co wydaje się rozsądne. Distinct Sort to ciekawy dodatek:
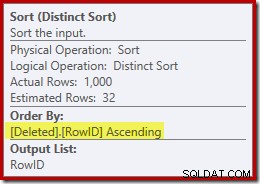
Ten rodzaj spełnia dwie funkcje. Po pierwsze, zapewnia sprzężenie scalające z posortowanymi danymi wejściowymi, których potrzebuje, co jest sprawiedliwe, ponieważ nie ma indeksu na wewnętrznym stole roboczym, aby zapewnić niezbędną kolejność. Drugą rzeczą, jaką robi sortowanie, jest rozróżnienie w RowID. Może się to wydawać dziwne, ponieważ RowID jest kluczem podstawowym tabeli podstawowej.
Problem polega na tym, że wiersze w usuniętych tabela to po prostu kandydujące wiersze zidentyfikowane przez pierwotne zapytanie DELETE. W przeciwieństwie do wyzwalacza AFTER, te wiersze nie zostały jeszcze sprawdzone pod kątem naruszeń ograniczeń lub kluczy, więc procesor zapytań nie ma gwarancji, że są one rzeczywiście unikatowe.
Ogólnie rzecz biorąc, jest to bardzo ważny punkt, o którym należy pamiętać w przypadku wyzwalaczy INSTEAD OF:nie ma gwarancji, że podane wiersze spełniają którekolwiek z ograniczeń tabeli podstawowej (w tym NOT NULL). Jest to ważne nie tylko dla autora wyzwalacza, aby pamiętać; ogranicza również uproszczenia i przekształcenia, jakie może wykonać optymalizator zapytań.
Drugim problemem pokazanym we właściwościach sortowania powyżej, ale nie wyróżnionym, jest to, że oszacowanie wyniku wynosi tylko 32 wiersze. Wewnętrzny stół roboczy nie ma z nim powiązanych statystyk, więc optymalizator zgaduje w wyniku operacji Distinct. „Wiemy”, że wartości RowID są unikalne, ale bez żadnych twardych informacji optymalizator źle zgaduje. Ten problem powróci, aby nas prześladować w następnym teście.
Test wyzwalania z 5000 wierszy
Teraz zmodyfikuj skrypt testowy, aby wygenerował 5000 wierszy:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Plan wykonania wyzwalacza to:
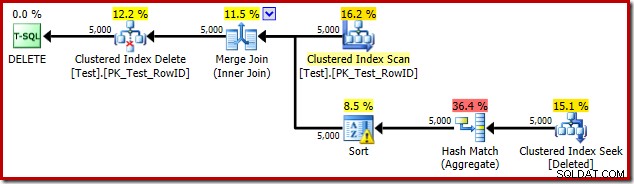
Tym razem optymalizator zdecydował się na rozdzielenie operacji wyodrębniania i sortowania. Odróżnienie w RowID jest wykonywane przez operator Hash Match (Aggregate):
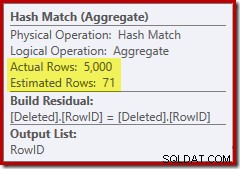
Zwróć uwagę, że oszacowanie optymalizatora dla wyniku wynosi 71 wierszy. W rzeczywistości wszystkie 5000 wierszy przetrwa odrębność, ponieważ RowID jest unikalny. Niedokładne oszacowanie oznacza, że niewystarczająca część przyznanej pamięci zapytania jest przydzielana do sortowania, co kończy się rozlewaniem do tempdb :
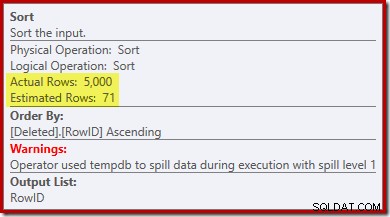
Ten test należy wykonać na SQL Server 2012 lub nowszym, aby zobaczyć ostrzeżenie sortowania w planie wykonania. W poprzednich wersjach plan nie zawierał informacji o rozlaniach — do jego ujawnienia potrzebny byłby ślad Profilera w zdarzeniu Sort Warnings (i trzeba by w jakiś sposób skorelować to z zapytaniem źródłowym).
Test wyzwalania z 5000 wierszy w SQL Server 2014
Jeśli poprzedni test zostanie powtórzony na SQL Server 2014, w bazie danych ustawionej na poziom zgodności 120, więc używany jest nowy estymator kardynalności (CE), plan wykonania wyzwalacza jest znowu inny:
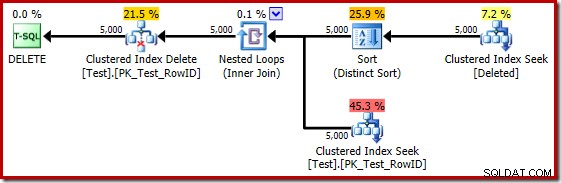
Pod pewnymi względami ten plan wykonania wydaje się być ulepszeniem. (Niepotrzebne) odrębne sortowanie nadal istnieje, ale ogólna strategia wydaje się bardziej naturalna:dla każdego odrębnego kandydata RowID w usuniętym tabeli, dołącz do tabeli podstawowej (sprawdzając, czy wiersz kandydata rzeczywiście istnieje), a następnie go usuń.
Niestety, plan 2014 jest oparty na gorszych szacunkach kardynalności niż widzieliśmy w SQL Server 2012. Przełączenie Eksploratora planów SQL Sentry na wyświetlanie szacowanego liczba wierszy wyraźnie pokazuje problem:
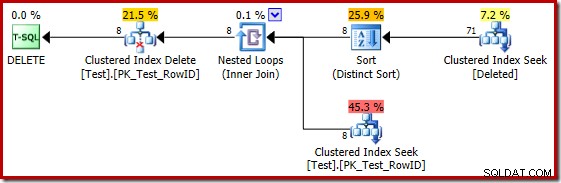
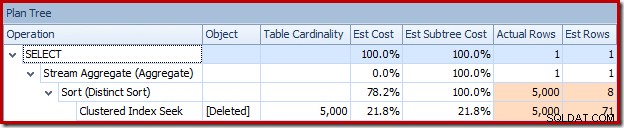
Optymalizator wybrał strategię zagnieżdżonych pętli dla złączenia, ponieważ oczekiwał bardzo małej liczby wierszy na swoim górnym wejściu. Pierwszy problem występuje w Clustered Index Seek. Optymalizator wie, że usunięta tabela zawiera w tym momencie 5000 wierszy, co możemy zobaczyć, przełączając się do widoku drzewa planów i dodając opcjonalną kolumnę Kardynalność tabeli (którą chciałbym, aby była domyślnie uwzględniona):
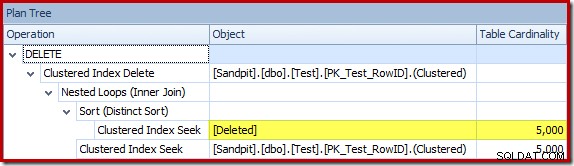
„Stary” estymator liczności w SQL Server 2012 i wcześniejszych wersjach jest na tyle sprytny, że wie, że „szukanie” w wewnętrznym stole roboczym zwróci wszystkie 5000 wierszy (a więc wybrał łączenie scalające). Nowa CE nie jest tak sprytna. Postrzega stół roboczy jako „czarną skrzynkę” i zgaduje wpływ wyszukiwania na kod akcji =3:
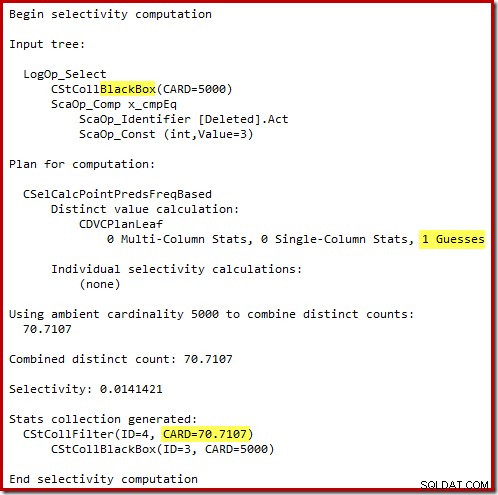
Przypuszczenie 71 wierszy (zaokrąglone w górę) to dość mizerny wynik, ale błąd jest spotęgowany, gdy nowa CE szacuje wiersze dla odrębnej operacji na tych 71 wierszach:
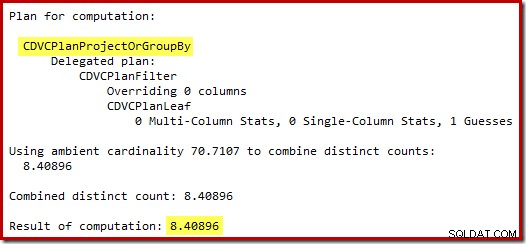
Na podstawie oczekiwanych 8 wierszy optymalizator wybiera strategię zagnieżdżonych pętli. Innym sposobem zobaczenia tych błędów estymacji jest dodanie następującej instrukcji do treści wyzwalacza (tylko do celów testowych):
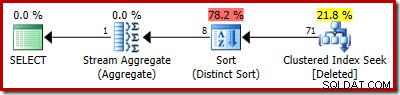
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Szacowany plan wyraźnie pokazuje błędy oszacowania:
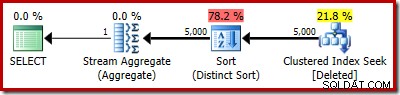
Rzeczywisty plan nadal pokazuje oczywiście 5000 wierszy:
Możesz też porównać oszacowanie z rzeczywistym w tym samym czasie w widoku drzewa planów:
Milion wierszy…
Słabe oszacowania przy użyciu estymatora kardynalności z 2014 r. powodują, że optymalizator wybiera strategię zagnieżdżonych pętli, nawet jeśli tabela Test zawiera milion wierszy. szacowana wartość CE na rok 2014 plan dla tego testu to:
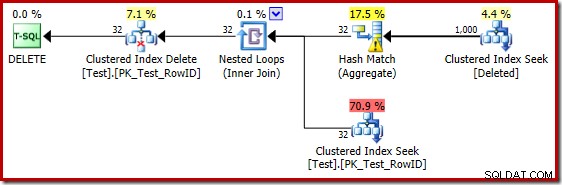
„Szukanie” szacuje 1000 wierszy ze znanej kardynalności 1 000 000, a odrębne szacunki to 32 wiersze. Plan powykonawczy ujawnia wpływ na pamięć zarezerwowaną dla Hash Match:
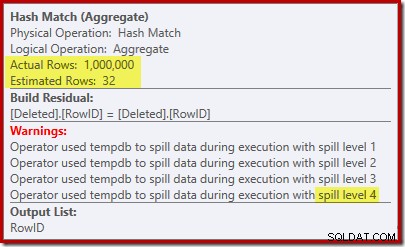
Spodziewając się tylko 32 wierszy, Hash Match wpada w poważne kłopoty, rekursywnie wyrzucając tablicę haszującą, zanim w końcu się zakończy.
Ostateczne myśli
Chociaż prawdą jest, że nigdy nie należy pisać wyzwalacza, aby zrobić coś, co można osiągnąć dzięki deklaratywnej integralności referencyjnej, prawdą jest również, że dobrze napisany wyzwalacz, który wykorzystuje wydajny plan wykonania może być porównywalny pod względem wydajności z kosztem utrzymania dodatkowego indeksu nieklastrowanego.
Z powyższym stwierdzeniem wiążą się dwa praktyczne problemy. Po pierwsze (i z najlepszą wolą na świecie) ludzie nie zawsze piszą dobry kod wyzwalacza. Po drugie, uzyskanie dobrego planu wykonania z optymalizatora zapytań w każdych okolicznościach może być trudne. Natura wyzwalaczy polega na tym, że są wywoływane z szerokim zakresem kardynalności danych wejściowych i dystrybucji danych.
Nawet w przypadku wyzwalaczy AFTER brak indeksów i statystyk dotyczących usuniętych i wstawione pseudotabele oznaczają, że wybór planu często opiera się na domysłach lub błędnych informacjach. Nawet w przypadku początkowego wyboru dobrego planu, późniejsze wykonania mogą ponownie wykorzystać ten sam plan, gdy ponowna kompilacja byłaby lepszym wyborem. Istnieją sposoby obejścia ograniczeń, głównie poprzez użycie tabel tymczasowych i jawnych indeksów/statystyk, ale nawet tam wymagana jest duża ostrożność (ponieważ wyzwalacze są formą procedury składowanej).
W przypadku wyzwalaczy INSTEAD OF ryzyko może być jeszcze większe, ponieważ zawartość wstawiona i usunięte tabele są niezweryfikowanymi kandydatami — optymalizator zapytań nie może używać ograniczeń tabeli podstawowej w celu uproszczenia i udoskonalenia planu wykonania. Nowy estymator kardynalności w SQL Server 2014 stanowi również prawdziwy krok wstecz, jeśli chodzi o plany wyzwalania INSTEAD OF. Odgadywanie efektu operacji wyszukiwania, którą wprowadził sam silnik, jest zaskakującym i niepożądanym przeoczeniem.



