Grupowanie to ważna funkcja, która pomaga organizować i porządkować dane. Można to zrobić na wiele sposobów, a jedną z najskuteczniejszych jest klauzula SQL GROUP BY.
Możesz użyć SQL GROUP BY, aby podzielić wiersze w wynikach na grupy za pomocą funkcji agregującej . Brzmi łatwo, aby zsumować, uśrednić lub zliczyć rekordy.
Ale czy robisz to dobrze?
„Racja” może być subiektywna. Kiedy działa bez błędów krytycznych z poprawnymi danymi wyjściowymi, uważa się, że jest w porządku. Jednak musi to być też szybkie.
W tym artykule rozważymy również prędkość. Zobaczysz wiele analiz zapytań przy użyciu odczytów logicznych i planów wykonania we wszystkich punktach.
Zacznijmy.
1. Filtruj wcześnie
Jeśli nie masz pewności, kiedy użyć GDZIE i MIEĆ, ten jest dla Ciebie. Ponieważ w zależności od warunków, które podasz, oba mogą dać ten sam wynik.
Ale są różne.
HAVING filtruje grupy przy użyciu kolumn w klauzuli SQL GROUP BY. WHERE filtruje wiersze przed grupowaniem i agregacją. Jeśli więc filtrujesz za pomocą klauzuli HAVING, grupowanie dotyczy wszystkich zwrócone wiersze.
A to źle.
Czemu? Krótka odpowiedź brzmi:jest powolny. Udowodnijmy to za pomocą 2 zapytań. Sprawdź poniższy kod. Przed uruchomieniem go w SQL Server Management Studio, najpierw naciśnij Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analiza
Powyższe 2 instrukcje SELECT zwrócą te same wiersze. Oba są poprawne w zwracaniu zamówień produktów według miesiąca w roku 2012. Ale pierwszy SELECT zajął 136 ms. uruchomić na moim laptopie, podczas gdy inny zajął 764 ms!
Dlaczego?
Sprawdźmy najpierw odczyty logiczne na rysunku 1. We/wy STATISTICS zwróciło te wyniki. Następnie wkleiłem go do StatisticsParser.com, aby uzyskać sformatowane wyjście.
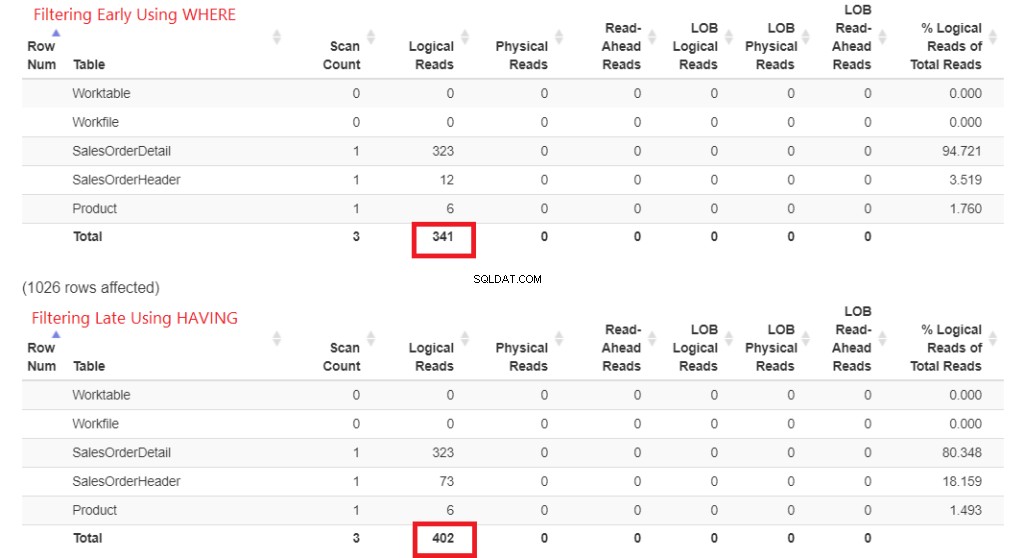
Rysunek 1 . Logiczne odczyty wczesnego filtrowania za pomocą GDZIE vs. filtrowania późnego za pomocą HAVING.
Spójrz na wszystkie logiczne odczyty każdego z nich. Aby zrozumieć te liczby, im więcej logicznych odczytów zajmie, tym wolniejsze będzie zapytanie. Dowodzi to więc, że używanie HAVING jest wolniejsze, a wczesne filtrowanie za pomocą funkcji WHERE jest szybsze.
Oczywiście nie oznacza to, że posiadanie jest bezużyteczne. Jedynym wyjątkiem jest użycie HAVING z agregatem takim jak HAVING SUM(sod.Linetotal)> 100000 . W jednym zapytaniu można połączyć klauzulę WHERE i klauzulę HAVING.
Zobacz plan wykonania na rysunku 2.
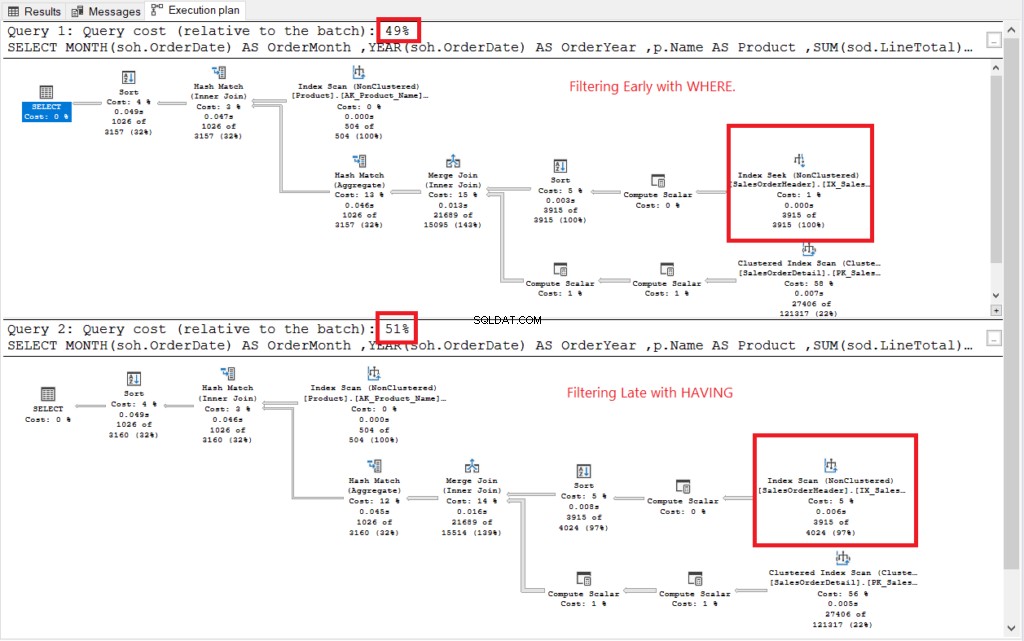
Rysunek 2 . Wykonywanie planów filtrowania wczesnego i filtrowania późnego.
Oba plany egzekucji wyglądały podobnie, z wyjątkiem tych w czerwonym pudełku. Wczesne filtrowanie używało operatora Index Seek, podczas gdy inne używało Index Scan. Wyszukiwanie jest szybsze niż skanowanie w dużych tabelach.
Nie te: Wczesne filtrowanie kosztuje mniej niż późne filtrowanie. Najważniejsze jest więc wczesne filtrowanie wierszy, które może poprawić wydajność.
2. Najpierw grupuj, dołącz później
Dołączenie do niektórych stolików, których będziesz potrzebować później, może również poprawić wydajność.
Załóżmy, że chcesz mieć comiesięczną sprzedaż produktów. Musisz również uzyskać nazwę produktu, numer i podkategorię w tym samym zapytaniu. Te kolumny znajdują się w innej tabeli. Aby zapewnić pomyślne wykonanie, wszystkie muszą zostać dodane w klauzuli GROUP BY. Oto kod.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
To będzie działać dobrze. Ale jest lepszy, szybszy sposób. Nie będzie to wymagać dodania 3 kolumn dla nazwy produktu, numeru i podkategorii w klauzuli GROUP BY. Będzie to jednak wymagało nieco więcej naciśnięć klawiszy. Oto on.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analiza
Dlaczego to jest szybsze? Połączenia z Produktem i Podkategoria Produktu są robione później. Oba nie są objęte klauzulą GROUP BY. Udowodnijmy to liczbami w IO STATYSTYKI. Zobacz rysunek 4.
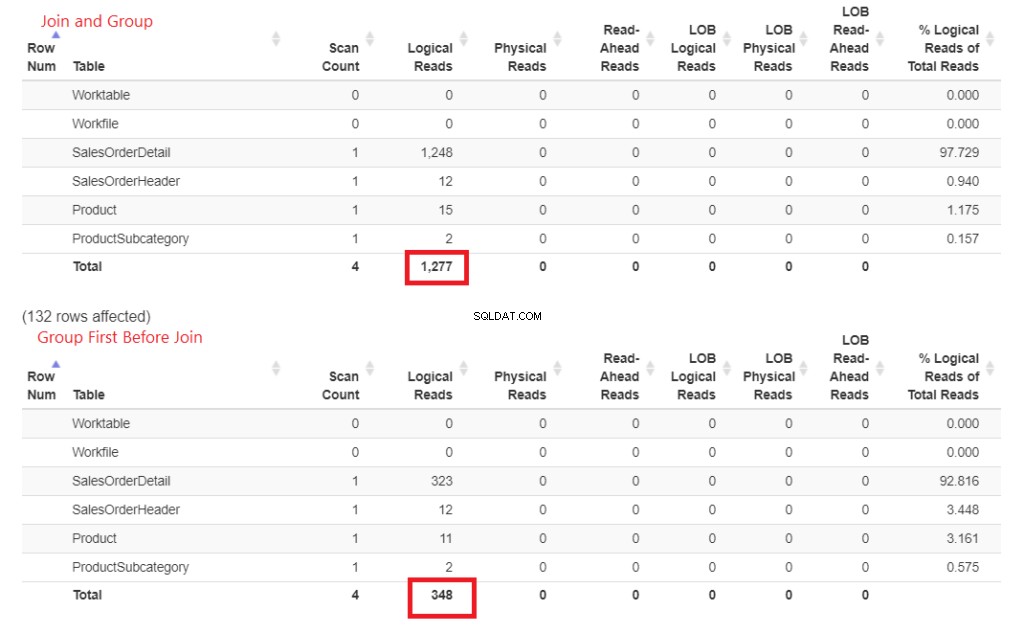
Rysunek 3 . Dołączanie wcześnie, a następnie grupowanie pochłaniało więcej logicznych odczytów niż późniejsze dołączanie.
Widzisz te logiczne odczyty? Różnica jest duża, a zwycięzca jest oczywisty.
Porównajmy plan wykonania 2 zapytań, aby zobaczyć przyczynę powyższych liczb. Najpierw zobacz Rysunek 4, aby zobaczyć plan wykonania zapytania ze wszystkimi tabelami połączonymi podczas grupowania.
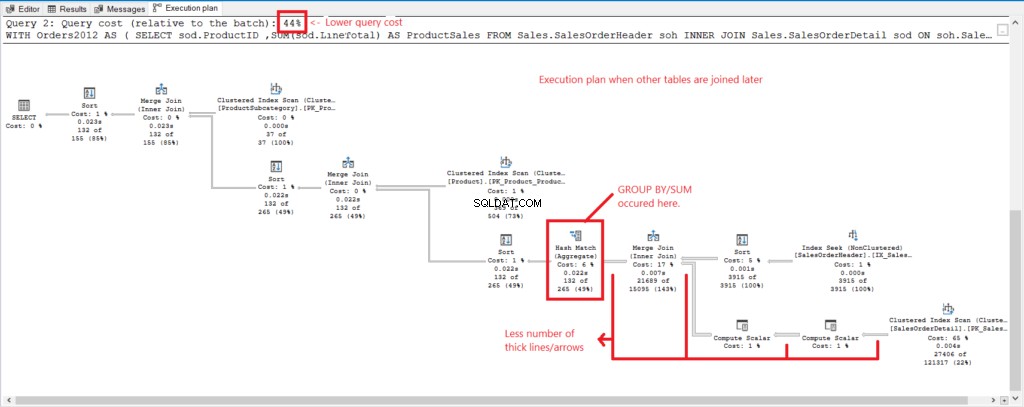
Rysunek 4 . Plan wykonania, gdy wszystkie stoły zostaną połączone.
I mamy następujące obserwacje:
- GROUP BY i SUM zostały wykonane na późnym etapie procesu po dołączeniu do wszystkich stołów.
- Dużo grubszych linii i strzałek – to wyjaśnia 1277 odczytów logicznych.
- Połączone 2 zapytania stanowią 100% kosztu zapytania. Ale plan tego zapytania ma wyższy koszt zapytania (56%).
Oto plan wykonania, kiedy najpierw grupujemy się i dołączamy do Produktu i Podkategoria Produktu tabele później. Sprawdź Rysunek 5.
Rysunek 5 . Plan wykonania, gdy grupa po raz pierwszy, dołącza później.
I mamy następujące obserwacje na rysunku 5.
- GROUP BY i SUM zakończyły się wcześnie.
- Mniejsza liczba grubych linii i strzałek – to wyjaśnia tylko 348 logicznych odczytów.
- Niższy koszt zapytania (44%).
3. Grupuj indeksowaną kolumnę
Za każdym razem, gdy w kolumnie wykonywane jest polecenie SQL GROUP BY, kolumna ta powinna mieć indeks. Zwiększysz szybkość wykonywania po zgrupowaniu kolumny z indeksem. Zmodyfikujmy poprzednie zapytanie i użyjmy daty wysyłki zamiast daty zamówienia. Kolumna daty wysyłki nie ma indeksu w SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Naciśnij Ctrl-M, a następnie uruchom powyższe zapytanie w SSMS. Następnie utwórz indeks nieklastrowy na Data Wysyłki kolumna. Zanotuj odczyty logiczne i plan wykonania. Na koniec ponownie uruchom powyższe zapytanie na innej karcie zapytań. Zwróć uwagę na różnice w odczytach logicznych i planach wykonania.
Oto porównanie odczytów logicznych na rysunku 6.
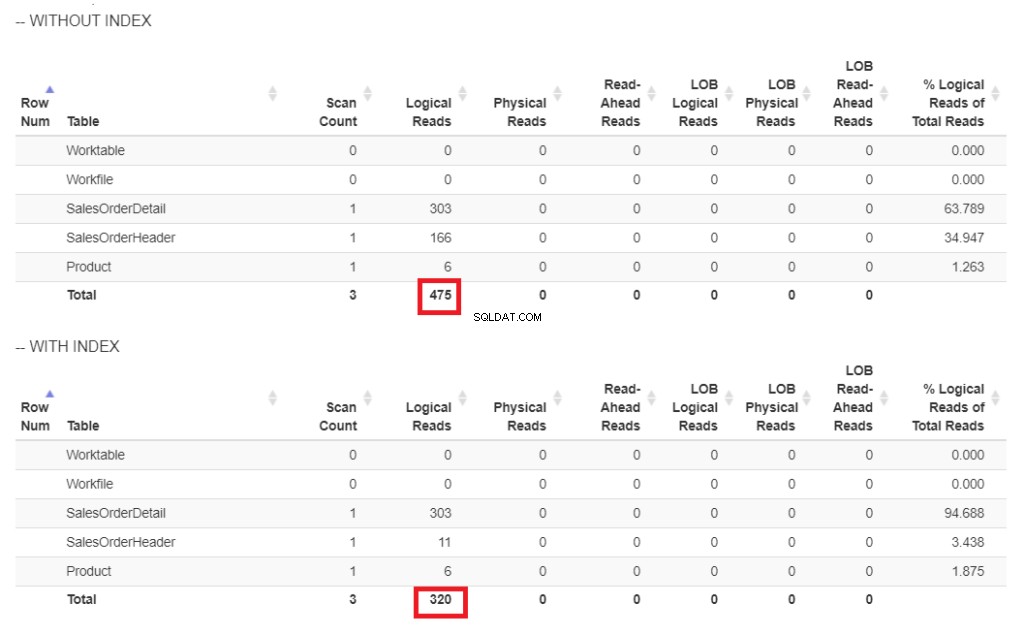
Rysunek 6 . Odczyty logiczne naszego przykładu zapytania z indeksem i bez indeksu daty wysyłki.
Na rysunku 6 są wyższe logiczne odczyty zapytania bez indeksu w dniu ShipDate .
Teraz zajmijmy się planem wykonania, gdy brak indeksu w dniu Data Wysyłki istnieje na rysunku 7.
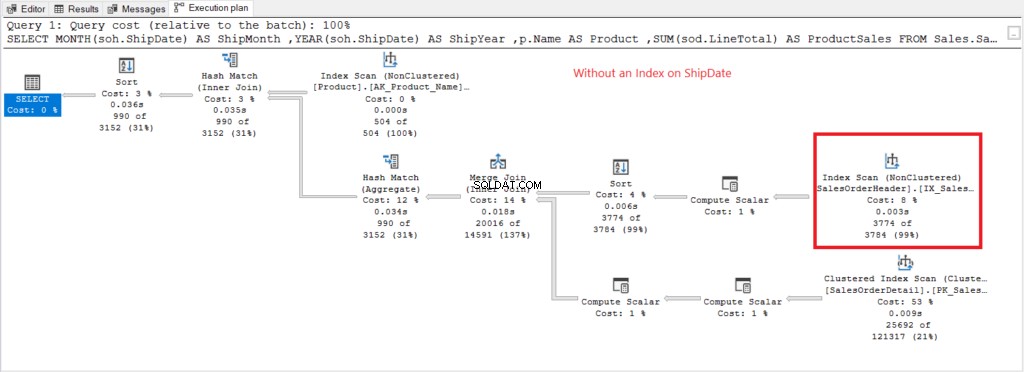
Rysunek 7 . Plan wykonania w przypadku korzystania z funkcji GROUP BY w dniu wysyłki bez indeksowania.
Skanowanie indeksu Operator użyty w planie na rysunku 7 wyjaśnia wyższe odczyty logiczne (475). Oto plan wykonania po zindeksowaniu Data Wysyłki kolumna.
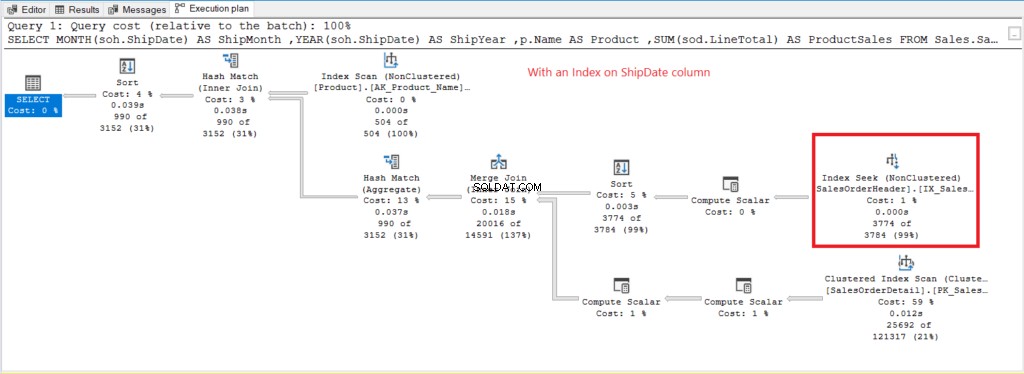
Rysunek 8 . Plan wykonania w przypadku korzystania z funkcji GROUP BY na zindeksowaną datę wysyłki.
Zamiast skanowania indeksu, po zindeksowaniu Data Wysyłki kolumna. To wyjaśnia niższe logiczne odczyty na rysunku 6.
Tak więc, aby poprawić wydajność podczas korzystania z funkcji GROUP BY, rozważ indeksowanie kolumn użytych do grupowania.
Na wynos w korzystaniu z SQL GROUP BY
SQL GROUP BY jest łatwy w użyciu. Musisz jednak zrobić kolejny krok, aby wyjść poza podsumowywanie danych do raportów. Oto punkty ponownie:
- Filtruj wcześnie . Usuń wiersze, których nie musisz podsumowywać, używając klauzuli WHERE zamiast klauzuli HAVING.
- Najpierw grupuj, dołącz później . Czasami oprócz kolumn, które grupujesz, musisz dodać kolumny. Zamiast włączać je do klauzuli GROUP BY, podziel zapytanie za pomocą CTE i dołącz później do innych tabel.
- Użyj GROUP BY z indeksowanymi kolumnami . Ta podstawowa rzecz może się przydać, gdy baza danych jest szybka jak ślimak.
Mam nadzieję, że pomoże to w podniesieniu poziomu gry w wynikach grupowania.
Jeśli podoba Ci się ten post, udostępnij go na swoich ulubionych platformach społecznościowych.