Uwaga:ten post został pierwotnie opublikowany tylko w naszym e-booku, Techniki wysokiej wydajności dla SQL Server, tom 3. Możesz dowiedzieć się o naszych e-bookach tutaj.
Jednym z wymagań, które sporadycznie widzę, jest zwracanie zapytania z zamówieniami pogrupowanymi według klientów, pokazujące maksymalną sumę należną dla dowolnego zamówienia do tej pory („maksymalna praca”). Wyobraź sobie te przykładowe wiersze:
| SalesOrderID | Identyfikator klienta | Data zamówienia | Całkowity termin |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 02.01.2014 | 45.29 |
| 31 | 2 | 2014-01-03 | 24,56 |
| 32 | 2 | 04.01.2014 | 89,84 |
| 37 | 1 | 05.01.2014 | 32,56 |
| 44 | 2 | 06.01.2014 | 45,54 |
| 55 | 1 | 07.01.2014 | 99,24 |
| 62 | 2 | 08.01.2014 | 12,55 |
Kilka wierszy przykładowych danych
Pożądane wyniki z podanych wymagań są następujące – w uproszczeniu posortuj zamówienia każdego klienta według daty i wymień każde zamówienie. Jeśli jest to najwyższa wartość TotalDue dla wszystkich zamówień widzianych do tej daty, wydrukuj sumę tego zamówienia, w przeciwnym razie wydrukuj najwyższą wartość TotalDue ze wszystkich poprzednich zamówień:
| SalesOrderID | Identyfikator klienta | Data zamówienia | Całkowity termin | Maksymalna suma należności |
|---|---|---|---|---|
| 12 | 1 | 02.01.2014 | 45.29 | 45.29 |
| 23 | 1 | 05.01.2014 | 32,56 | 45.29 |
| 31 | 1 | 07.01.2014 | 99,24 | 99,24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24,56 | 37,55 |
| 44 | 2 | 04.01.2014 | 89,84 | 89,84 |
| 55 | 2 | 06.01.2014 | 45,54 | 89,84 |
| 62 | 2 | 08.01.2014 | 12,55 | 89,84 |
Przykładowe pożądane wyniki
Wiele osób instynktownie chciałoby użyć kursora lub pętli while, aby to osiągnąć, ale istnieje kilka podejść, które nie obejmują tych konstrukcji.
Skorelowane podzapytanie
To podejście wydaje się być najprostszym i najprostszym podejściem do problemu, ale wielokrotnie udowodniono, że nie skaluje się, ponieważ odczyty rosną wykładniczo wraz ze wzrostem tabeli:
SELECT /* Skorelowane podzapytanie */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =(SELECT MAX(TotalDue) FROM Sales.SalesOrderHeader WHERE CustomerID =h.CustomerID AND SalesOrderID <=h.SalesOrderID) FROM Sales.SalesOrderHeader AS h ORDER BY CustomerID, SalesOrderID;
Oto plan na AdventureWorks2014, korzystający z SQL Sentry Plan Explorer:
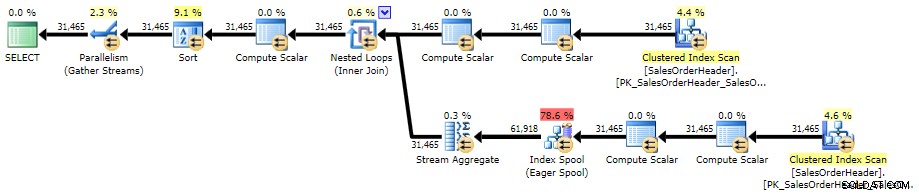 Plan wykonania skorelowanego podzapytania (kliknij, aby powiększyć)
Plan wykonania skorelowanego podzapytania (kliknij, aby powiększyć)
ZASTOSOWANIE KRZYŻA DO AUTOMATYCZNEGO
To podejście jest prawie identyczne z podejściem Skorelowane podzapytanie pod względem składni, kształtu planu i wydajności na dużą skalę.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDueFROM Sales.SalesOrderHeader AS hCROSS APPLY( SELECT MaxTotalDue =MAX(TotalDue) FROM Sales.SalesOrderHeader AS i i.CustomerID =h.CustomerID AND i.SalesOrderID <=h.SalesOrderID) AS xORDER BY h.CustomerID, h.SalesOrderID;
Plan jest dość podobny do skorelowanego planu podzapytań, jedyną różnicą jest rodzaj lokalizacji:
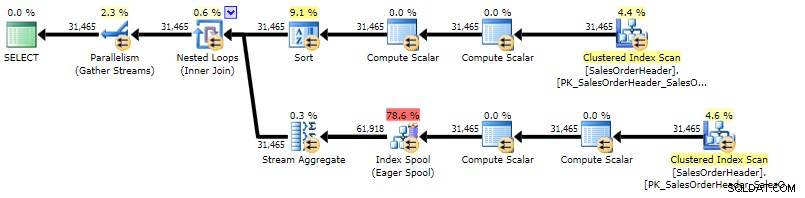 Plan wykonania CROSS APPLY (kliknij, aby powiększyć)
Plan wykonania CROSS APPLY (kliknij, aby powiększyć)
Rekursywne CTE
Za kulisami używa się pętli, ale dopóki go nie uruchomimy, możemy udawać, że tak nie jest (chociaż jest to z pewnością najbardziej skomplikowany fragment kodu, jaki kiedykolwiek chciałbym napisać, aby rozwiązać ten konkretny problem):
;WITH /* Rekursywne CTE */ cte AS ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue FROM ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =TotalDue, rn =ROW_NUMBER() OVER (PARTDER BY CustomerID ORDER) BY SalesOrderID) FROM Sales.SalesOrderHeader ) AS x WHERE rn =1 UNION ALL SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue, MaxTotalDue =CASE WHEN r.TotalDue> cte.MaxTotalDuetal CTEN r.Total .MaxTotalDue END FROM cte CROSS APPLY ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, rn =ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID) FROM Sales.SalesOrderHeader AS h WHERE h.CustomerID =cte.CustomerID AND h>. cte.SalesOrderID ) AS r WHERE r.rn =1)SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDueFROM cteORDER BY CustomerID, SalesOrderIDOPTION (MAXRECURSION 0);
Od razu widać, że plan jest bardziej złożony niż dwa poprzednie, co nie jest zaskakujące, biorąc pod uwagę bardziej złożone zapytanie:
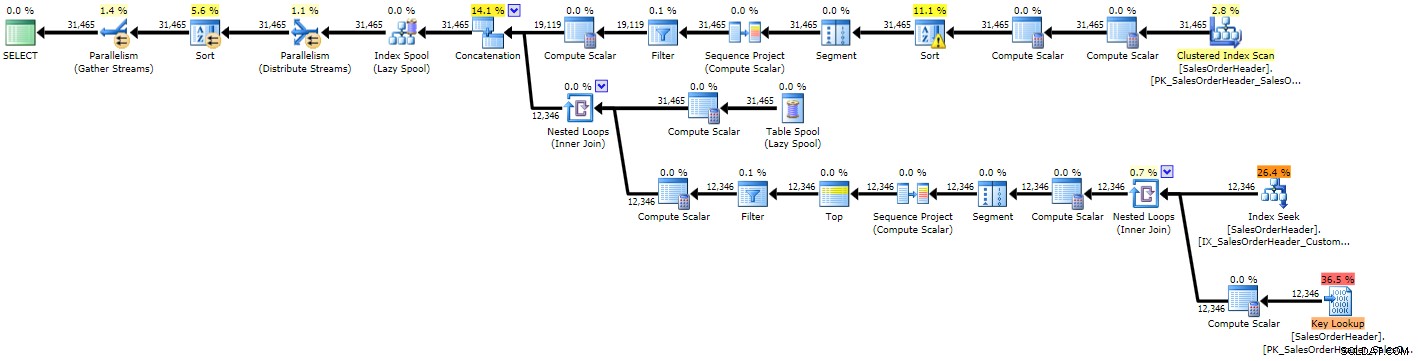 Plan wykonania rekurencyjnego CTE (kliknij, aby powiększyć)
Plan wykonania rekurencyjnego CTE (kliknij, aby powiększyć)
Z powodu pewnych błędnych szacunków widzimy wyszukiwanie indeksu z towarzyszącym mu wyszukiwaniem kluczy, które prawdopodobnie powinny zostać zastąpione pojedynczym skanowaniem, a także otrzymujemy operację sortowania, która ostatecznie musi zostać przeniesiona do tempdb (możesz to zobaczyć w podpowiedzi jeśli najedziesz kursorem na operator sortowania z ikoną ostrzeżenia):

MAX() PONAD (WIERSZE BEZ OGRANICZEŃ)
Jest to rozwiązanie dostępne tylko w SQL Server 2012 i nowszych, ponieważ wykorzystuje nowo wprowadzone rozszerzenia funkcji okien.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =MAX(TotalDue) OVER ( PARTITION BY CustomerID ORDER BY SalesOrderID ROWERS UNBOUNDED PRECEDING )FROM Sales.SalesOrderHeaderORDER BY CustomerID;<, SalesOrder /pre>Plan pokazuje dokładnie, dlaczego skaluje się lepiej niż wszystkie inne; ma tylko jedną operację skanowania indeksu klastrowego, w przeciwieństwie do dwóch (lub złego wyboru skanowania i wyszukiwania + wyszukiwania w przypadku rekurencyjnego CTE):
Plan wykonania funkcji MAX() OVER() (kliknij, aby powiększyć)
Porównanie wydajności
Plany z pewnością prowadzą nas do przekonania, że nowy
MAX() OVER()możliwości w SQL Server 2012 to prawdziwy zwycięzca, ale co z konkretnymi wskaźnikami czasu wykonywania? Oto porównanie egzekucji:
Pierwsze dwa zapytania były prawie identyczne; podczas gdy w tym przypadku
CROSS APPLYbył lepszy pod względem ogólnego czasu trwania o mały margines, skorelowane podzapytanie czasami go nieco przebija. Rekurencyjne CTE jest za każdym razem znacznie wolniejsze i można zobaczyć czynniki, które się do tego przyczyniają – mianowicie złe oszacowania, ogromna liczba odczytów, wyszukiwanie kluczy i dodatkowa operacja sortowania. Jak już wcześniej zademonstrowałem, korzystając z sum bieżących, rozwiązanie SQL Server 2012 jest lepsze niemal pod każdym względem.Wniosek
Jeśli korzystasz z SQL Server 2012 lub nowszego, zdecydowanie chcesz zapoznać się ze wszystkimi rozszerzeniami funkcji okienek wprowadzonych po raz pierwszy w SQL Server 2005 — mogą one zapewnić całkiem poważny wzrost wydajności podczas ponownego odwiedzania kodu, który wciąż działa” stary sposób." Jeśli chcesz dowiedzieć się więcej o niektórych z tych nowych możliwości, gorąco polecam książkę Itzika Ben-Gana, Microsoft SQL Server 2012 High-Performance T-SQL using Window Functions.
Jeśli nie korzystasz jeszcze z SQL Server 2012, przynajmniej w tym teście, możesz wybrać między
CROSS APPLYi skorelowane podzapytanie. Jak zawsze, powinieneś przetestować różne metody na swoich danych na swoim sprzęcie.