Ponad trzy lata temu opublikowałem trzyczęściową serię o dzieleniu strun:
- Podziel struny we właściwy sposób – lub następny najlepszy sposób
- Rozdzielanie ciągów:kontynuacja
- Rozdzielanie ciągów:teraz z mniejszą ilością T-SQL
W styczniu podjąłem nieco bardziej skomplikowany problem:
- Porównywanie metod dzielenia/konkatenacji ciągów
Przez cały czas mój wniosek był następujący:PRZESTAŃ ROBIĆ TO W T-SQL . Użyj CLR lub, jeszcze lepiej, przekaż ustrukturyzowane parametry, takie jak DataTables, z aplikacji do parametrów wycenianych w tabeli (TVP) w swoich procedurach, unikając całkowicie konstrukcji i dekonstrukcji ciągów — co jest tak naprawdę częścią rozwiązania, która powoduje problemy z wydajnością.
I wtedy pojawił się SQL Server 2016…
Po wydaniu RC0 nowa funkcja została udokumentowana bez większych fanfar:STRING_SPLIT . Szybki przykład:
SELECT * FROM STRING_SPLIT('a,b,cd', ',');
/* result:
value
--------
a
b
cd
*/ Przyciągnęło to uwagę kilku kolegów, w tym Dave'a Ballantyne'a, który pisał o głównych funkcjach – ale był na tyle uprzejmy, że dał mi pierwszeństwo odmowy porównania wydajności.
Jest to głównie ćwiczenie akademickie, ponieważ przy dużym zestawie ograniczeń w pierwszej iteracji tej funkcji prawdopodobnie nie będzie to wykonalne dla dużej liczby przypadków użycia. Oto lista obserwacji dokonanych przeze mnie i Dave'a, z których niektóre mogą w pewnych sytuacjach złamać układ:
- funkcja wymaga, aby baza danych miała poziom zgodności 130;
- przyjmuje tylko ograniczniki jednoznakowe;
- nie ma możliwości dodania kolumn wyjściowych (takich jak kolumna wskazująca pozycję porządkową w ciągu);
- powiązane, nie ma możliwości kontrolowania sortowania – jedyne opcje to dowolne i alfabetyczne
ORDER BY value;
- powiązane, nie ma możliwości kontrolowania sortowania – jedyne opcje to dowolne i alfabetyczne
- do tej pory zawsze szacuje 50 wierszy wyjściowych;
- używając go do DML, w wielu przypadkach otrzymasz szpulę tabeli (dla ochrony Hallowe'en);
NULLwejście prowadzi do pustego wyniku;- nie ma możliwości przesuwania predykatów, jak eliminowanie duplikatów lub pustych ciągów z powodu kolejnych ograniczników;
- nie ma możliwości wykonania operacji na wartościach wyjściowych aż do momentu po fakcie (na przykład wiele funkcji dzielenia wykonuje
LTRIM/RTRIMlub jawne konwersje dla Ciebie –STRING_SPLITwypluwa wszystkie brzydkie, takie jak wiodące spacje).
Po ujawnieniu tych ograniczeń możemy przejść do testów wydajności. Biorąc pod uwagę historię firmy Microsoft z wbudowanymi funkcjami, które wykorzystują CLR pod przykrywkami (kaszel FORMAT() kaszel ), byłem sceptyczny, czy ta nowa funkcja może zbliżyć się do najszybszych metod, jakie testowałem do tej pory.
Użyjmy rozdzielaczy ciągów, aby oddzielić ciągi liczb oddzielone przecinkami, w ten sposób nasz nowy przyjaciel JSON również może przyjść i zagrać. I powiemy, że żadna lista nie może przekroczyć 8000 znaków, więc nie ma MAX typy są wymagane, a ponieważ są to liczby, nie mamy do czynienia z czymś egzotycznym, takim jak Unicode.
Najpierw stwórzmy nasze funkcje, z których kilka zaadaptowałem z pierwszego artykułu powyżej. Pominąłem parę, która według mnie nie będzie konkurować; Zostawię to jako ćwiczenie dla czytelnika, aby je przetestować.
Tabela liczb
Ten znowu wymaga trochę konfiguracji, ale może to być dość mały stół ze względu na sztuczne ograniczenia, które nakładamy:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 8000;
;WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number); Następnie funkcja:
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT [Value] = SUBSTRING(@List, [Number],
CHARINDEX(@Delimiter, @List + @Delimiter, [Number]) - [Number])
FROM dbo.Numbers WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter
); JSON
W oparciu o podejście ujawnione po raz pierwszy przez zespół silnika pamięci masowej, stworzyłem podobne opakowanie wokół OPENJSON , po prostu zauważ, że separatorem musi być w tym przypadku przecinek, lub musisz wykonać kilka ciężkich podstawień łańcucha przed przekazaniem wartości do funkcji natywnej:
CREATE FUNCTION dbo.SplitStrings_JSON
(
@List varchar(8000),
@Delimiter char(1) -- ignored but made automated testing easier
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Znaki CHAR(91)/CHAR(93) po prostu zastępują odpowiednio [ i ] z powodu problemów z formatowaniem.
XML
CREATE FUNCTION dbo.SplitStrings_XML
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(8000)')
FROM (SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)); CLR
Po raz kolejny pożyczyłem zaufany kod dzielący Adama Machanica sprzed prawie siedmiu lat, mimo że obsługuje Unicode, MAX typy i wieloznakowe ograniczniki (a właściwie, ponieważ nie chcę w ogóle zadzierać z kodem funkcji, ogranicza to nasze ciągi wejściowe do 4000 znaków zamiast 8000):
CREATE FUNCTION dbo.SplitStrings_CLR ( @List nvarchar(MAX), @Delimiter nvarchar(255) ) RETURNS TABLE ( value nvarchar(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
Dla zachowania spójności umieszczam otoczkę wokół STRING_SPLIT :
CREATE FUNCTION dbo.SplitStrings_Native
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM STRING_SPLIT(@List, @Delimiter));
Kontrola danych źródłowych i poprawności
Stworzyłem tę tabelę, aby służyła jako źródło ciągów wejściowych do funkcji:
CREATE TABLE dbo.SourceTable
(
RowNum int IDENTITY(1,1) PRIMARY KEY,
StringValue varchar(8000)
);
;WITH x AS
(
SELECT TOP (60000) x = STUFF((SELECT TOP (ABS(o.[object_id] % 20))
',' + CONVERT(varchar(12), c.[object_id]) FROM sys.all_columns AS c
WHERE c.[object_id] < o.[object_id] ORDER BY NEWID() FOR XML PATH(''),
TYPE).value(N'(./text())[1]', N'varchar(8000)'),1,1,'')
FROM sys.all_objects AS o CROSS JOIN sys.all_objects AS o2
ORDER BY NEWID()
)
INSERT dbo.SourceTable(StringValue)
SELECT TOP (50000) x
FROM x WHERE x IS NOT NULL
ORDER BY NEWID(); Dla porównania sprawdźmy, czy 50 000 wierszy znalazło się w tabeli i sprawdźmy średnią długość ciągu oraz średnią liczbę elementów w ciągu:
SELECT
[Values] = COUNT(*),
AvgStringLength = AVG(1.0*LEN(StringValue)),
AvgElementCount = AVG(1.0*LEN(StringValue)-LEN(REPLACE(StringValue, ',','')))
FROM dbo.SourceTable;
/* result:
Values AvgStringLength AbgElementCount
------ --------------- ---------------
50000 108.476380 8.911840
*/
I na koniec upewnijmy się, że każda funkcja zwraca właściwe dane dla każdego podanego RowNum , więc po prostu wybierzemy losowo jedną i porównamy wartości uzyskane za pomocą każdej metody. Twoje wyniki będą się oczywiście różnić.
SELECT f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f WHERE s.RowNum = 37219 ORDER BY f.value;
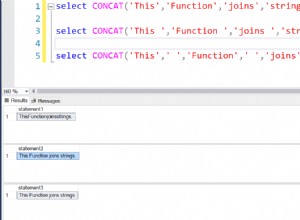
Rzeczywiście, wszystkie funkcje działają zgodnie z oczekiwaniami (sortowanie nie jest numeryczne; pamiętaj, że funkcje wyprowadzają łańcuchy):
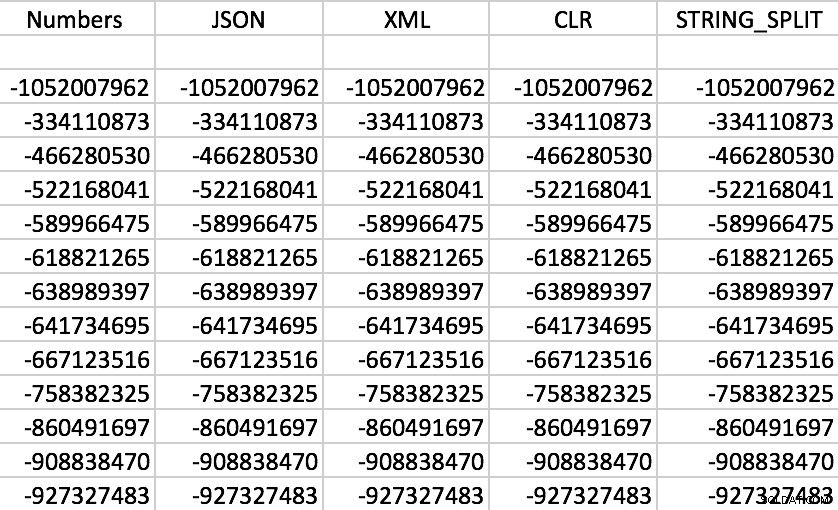 Przykładowy zestaw danych wyjściowych każdej z funkcji
Przykładowy zestaw danych wyjściowych każdej z funkcji
Testowanie wydajności
SELECT SYSDATETIME(); GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue,',') AS f; GO 100 SELECT SYSDATETIME();
Uruchomiłem powyższy kod 10 razy dla każdej metody i uśredniłem czasy dla każdej z nich. I tu właśnie pojawiła się dla mnie niespodzianka. Biorąc pod uwagę ograniczenia w natywnym STRING_SPLIT moim założeniem było to, że zostało to zmontowane szybko i że wydajność to uwiarygodnia. Chłopiec był rezultatem innym niż się spodziewałem:
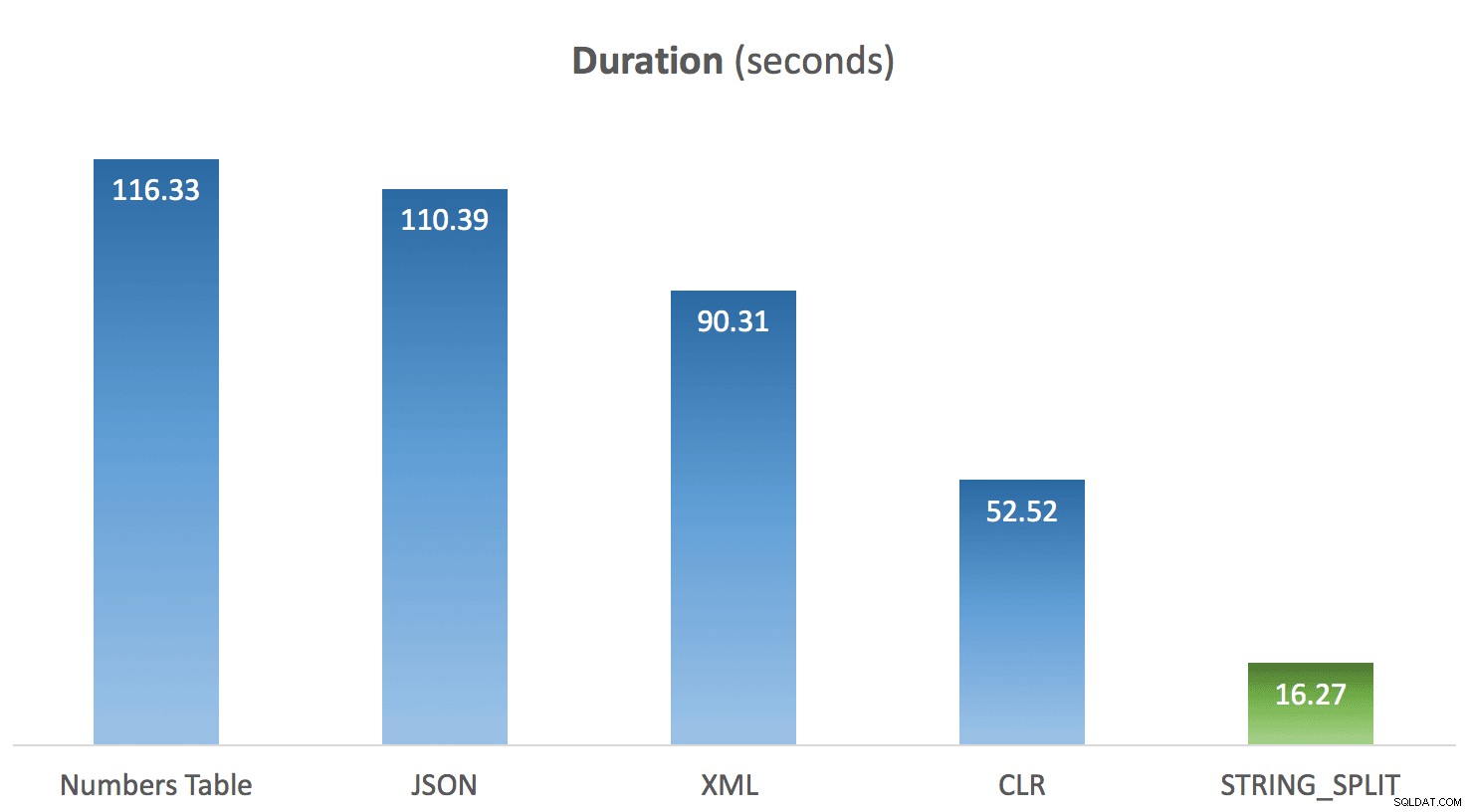 Średni czas trwania STRING_SPLIT w porównaniu z innymi metodami
Średni czas trwania STRING_SPLIT w porównaniu z innymi metodami
Aktualizacja 2016-03-20
W oparciu o poniższe pytanie od Larsa, przeprowadziłem testy ponownie z kilkoma zmianami:
- Monitorowałem moją instancję za pomocą SQL Sentry Performance Advisor, aby przechwycić profil procesora podczas testu;
- Zrobiłem statystyki oczekiwania na poziomie sesji pomiędzy każdą partią;
- Wstawiłem opóźnienie między partiami, aby aktywność była wizualnie odmienna w panelu Performance Advisor.
Utworzyłem nową tabelę do przechwytywania informacji o czekaniu:
CREATE TABLE dbo.Timings ( dt datetime, test varchar(64), point varchar(64), session_id smallint, wait_type nvarchar(60), wait_time_ms bigint, );
Następnie kod dla każdego testu zmienił się na następujący:
WAITFOR DELAY '00:00:30'; DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = /* 'method' */, point = 'Start', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f GO 100 DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, /* 'method' */, 'End', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
Przeprowadziłem test, a następnie uruchomiłem następujące zapytania:
-- validate that timings were in same ballpark as previous tests
SELECT test, DATEDIFF(SECOND, MIN(dt), MAX(dt))
FROM dbo.Timings WITH (NOLOCK)
GROUP BY test ORDER BY 2 DESC;
-- determine window to apply to Performance Advisor dashboard
SELECT MIN(dt), MAX(dt) FROM dbo.Timings;
-- get wait stats registered for each session
SELECT test, wait_type, delta FROM
(
SELECT f.test, rn = RANK() OVER (PARTITION BY f.point ORDER BY f.dt),
f.wait_type, delta = f.wait_time_ms - COALESCE(s.wait_time_ms, 0)
FROM dbo.Timings AS f
LEFT OUTER JOIN dbo.Timings AS s
ON s.test = f.test
AND s.wait_type = f.wait_type
AND s.point = 'Start'
WHERE f.point = 'End'
) AS x
WHERE delta > 0
ORDER BY rn, delta DESC; Od pierwszego zapytania czasy pozostały zgodne z poprzednimi testami (wykreśliłbym je ponownie, ale to nie ujawniłoby niczego nowego).
W drugim zapytaniu udało mi się wyróżnić ten zakres na pulpicie nawigacyjnym Performance Advisor, a stamtąd łatwo było zidentyfikować każdą partię:
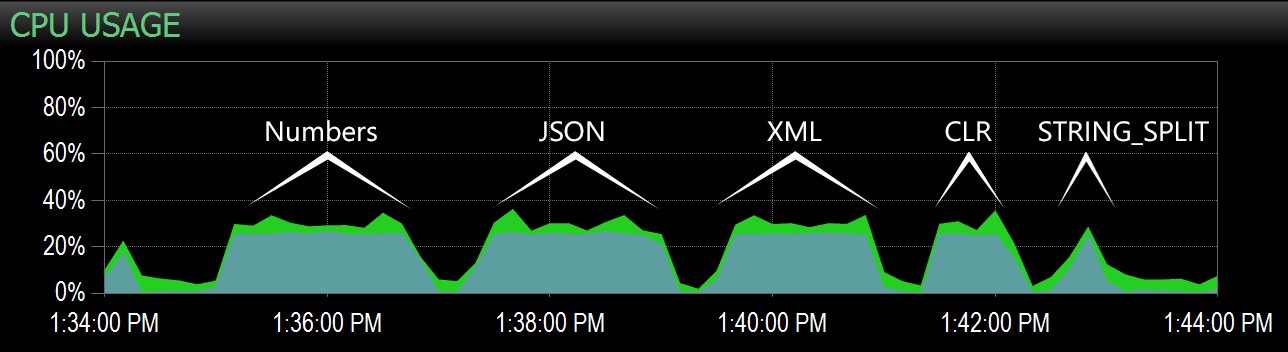 Pakiety przechwycone na wykresie procesora w panelu Performance Advisor
Pakiety przechwycone na wykresie procesora w panelu Performance Advisor
Oczywiście wszystkie metody *oprócz* STRING_SPLIT Ustalono pojedynczy rdzeń na czas trwania testu (jest to maszyna czterordzeniowa, a procesor ma stale 25%). Jest prawdopodobne, że Lars sugerował poniżej, że STRING_SPLIT jest szybszy kosztem bicia procesora, ale wydaje się, że tak nie jest.
Wreszcie, z trzeciego zapytania, mogłem zobaczyć następujące statystyki oczekiwania naliczane po każdej partii:
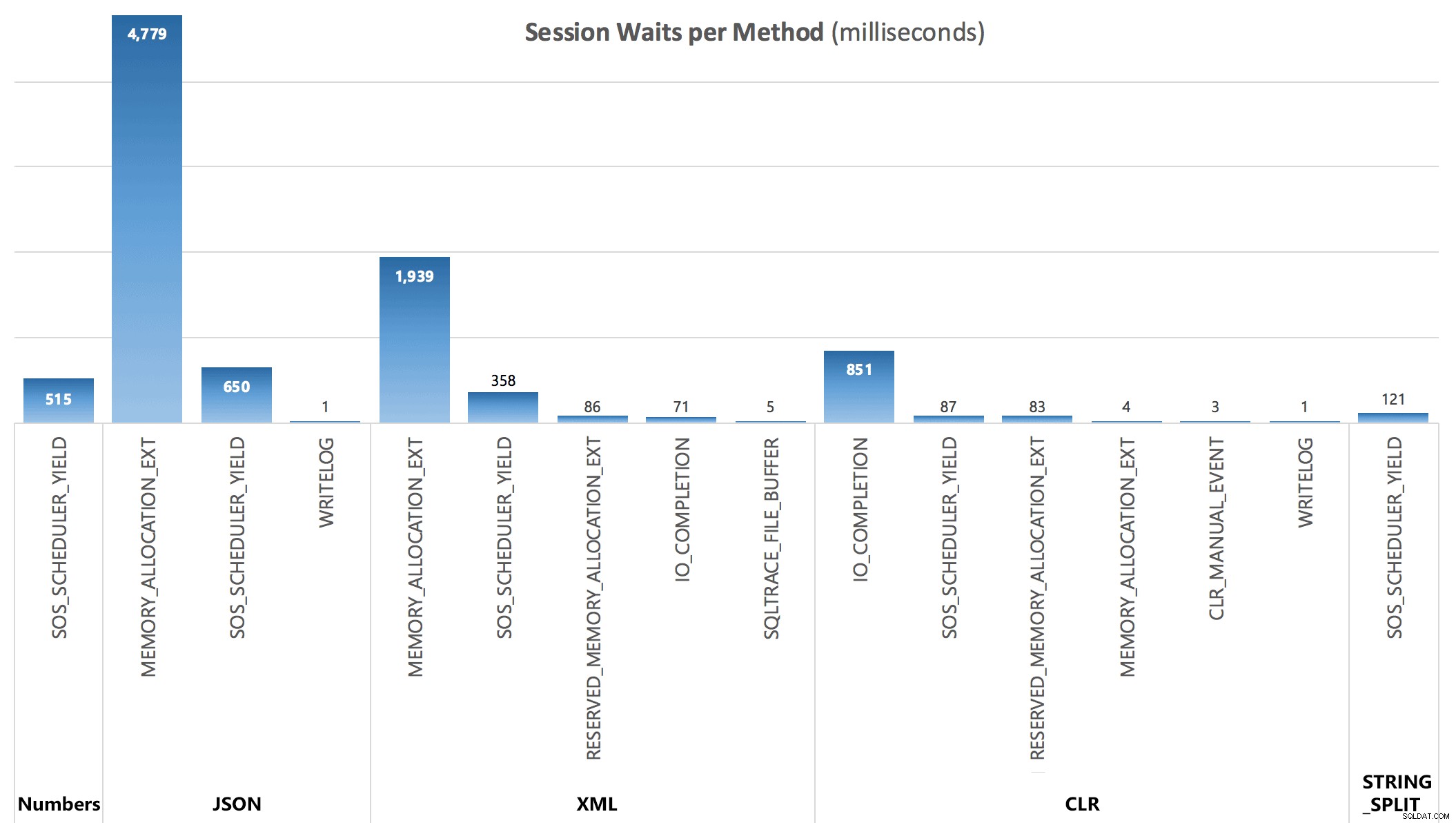 Oczekiwanie na sesję, w milisekundach
Oczekiwanie na sesję, w milisekundach
Oczekiwania przechwycone przez DMV nie wyjaśniają w pełni czasu trwania zapytań, ale służą do pokazania, gdzie dodatkowe ponoszone są oczekiwania.
Wniosek
Podczas gdy niestandardowy CLR nadal wykazuje ogromną przewagę nad tradycyjnymi podejściami T-SQL, a użycie JSON do tej funkcji wydaje się niczym więcej niż nowością, STRING_SPLIT był wyraźnym zwycięzcą – o milę. Tak więc, jeśli potrzebujesz tylko podzielić łańcuch i możesz poradzić sobie ze wszystkimi jego ograniczeniami, wygląda na to, że jest to znacznie bardziej opłacalna opcja, niż bym się spodziewał. Mamy nadzieję, że w przyszłych kompilacjach zobaczymy dodatkowe funkcje, takie jak kolumna wyjściowa wskazująca pozycję porządkową każdego elementu, możliwość filtrowania duplikatów i pustych ciągów oraz wieloznakowe ograniczniki.
W dwóch kolejnych postach zwracam się do wielu komentarzy poniżej:
- STRING_SPLIT() w SQL Server 2016:kontynuacja nr 1
- STRING_SPLIT() w SQL Server 2016:kontynuacja nr 2