W zeszłym miesiącu omówiłem wyzwanie Special Islands. Zadanie polegało na zidentyfikowaniu okresów aktywności dla każdego identyfikatora usługi, tolerując przerwę do wejściowej liczby sekund (@allowedgap ). Zastrzeżeniem było to, że rozwiązanie musiało być kompatybilne przed 2012 rokiem, więc nie można było używać funkcji takich jak LAG i LEAD ani agregować funkcji okien z ramką. W komentarzach Toby'ego Ovod-Everetta, Petera Larssona i Kamila Kosno dostałem szereg bardzo ciekawych rozwiązań. Pamiętaj, aby przejrzeć ich rozwiązania, ponieważ wszystkie są dość kreatywne.
Co ciekawe, wiele rozwiązań działało wolniej z zalecanym indeksem niż bez niego. W tym artykule proponuję wyjaśnienie tego.
Mimo że wszystkie rozwiązania były ciekawe, tutaj chciałem skupić się na rozwiązaniu Kamila Kosno, który jest programistą ETL w firmie Zopa. W swoim rozwiązaniu Kamil zastosował bardzo kreatywną technikę emulacji LAG i LEAD bez LAG i LEAD. Prawdopodobnie uznasz tę technikę za przydatną, jeśli musisz wykonać obliczenia podobne do LAG/LEAD przy użyciu kodu, który jest zgodny z wersjami sprzed 2012 roku.
Dlaczego niektóre rozwiązania są szybsze bez zalecanego indeksu?
Przypominam, że sugerowałem użycie poniższego indeksu jako wsparcia rozwiązań wyzwania:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Moje rozwiązanie kompatybilne z wersją sprzed 2012 roku było następujące:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Rysunek 1 przedstawia plan mojego rozwiązania z zalecanym indeksem.
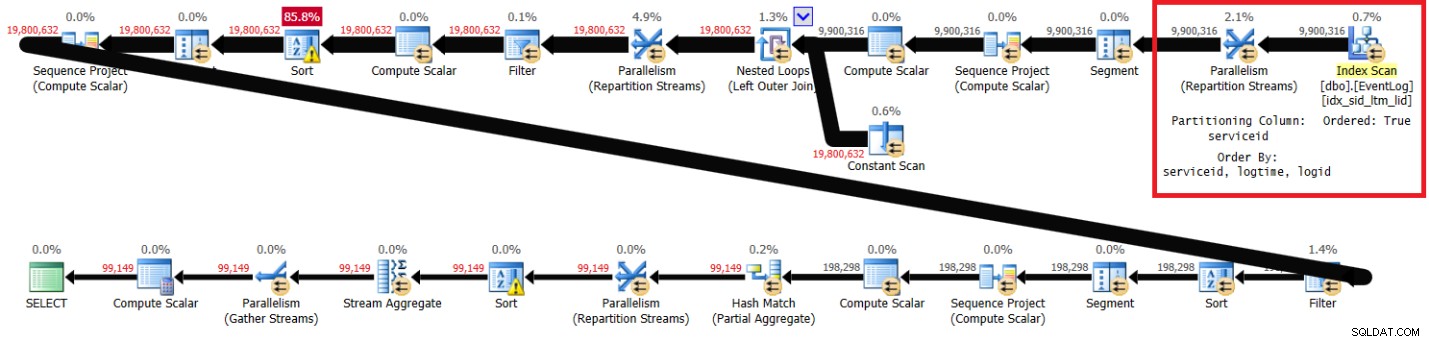 Rysunek 1:Zaplanuj rozwiązanie Itzika z zalecanym indeksem
Rysunek 1:Zaplanuj rozwiązanie Itzika z zalecanym indeksem
Zwróć uwagę, że plan skanuje zalecany indeks w kolejności klucza (właściwość Ordered ma wartość True), dzieli strumienie według identyfikatora usługi przy użyciu wymiany z zachowaniem kolejności, a następnie stosuje początkowe obliczenia numerów wierszy w oparciu o kolejność indeksów bez potrzeby sortowania. Poniżej znajdują się statystyki wydajności, które otrzymałem dla wykonania tego zapytania na moim laptopie (czas, który upłynął, czas procesora i oczekiwanie u góry wyrażone w sekundach):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
Następnie upuściłem zalecany indeks i ponownie uruchomiłem rozwiązanie:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Mam plan pokazany na rysunku 2.
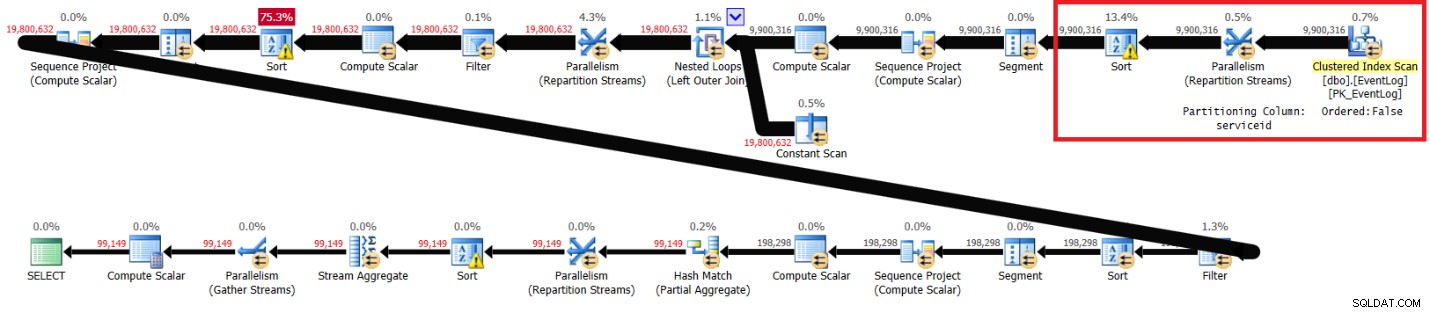 Rysunek 2:Plan rozwiązania Itzika bez zalecanego indeksu
Rysunek 2:Plan rozwiązania Itzika bez zalecanego indeksu
Wyróżnione sekcje w dwóch planach pokazują różnicę. Plan bez zalecanego indeksu wykonuje nieuporządkowane skanowanie indeksu klastrowego, dzieli strumienie według identyfikatora usługi przy użyciu wymiany bez zachowania kolejności, a następnie sortuje wiersze zgodnie z potrzebami funkcji okna (według identyfikatora usługi, czasu logowania, logidu). Reszta pracy wydaje się być taka sama w obu planach. Można by pomyśleć, że plan bez zalecanego indeksu powinien być wolniejszy, ponieważ ma dodatkowy rodzaj, którego nie ma inny plan. Ale oto statystyki wydajności, które otrzymałem dla tego planu na moim laptopie:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
W grę wchodzi więcej czasu procesora, co częściowo wynika z dodatkowego sortowania; w grę wchodzi więcej wejść/wyjść, prawdopodobnie z powodu dodatkowych wycieków sortowania; jednak upływający czas jest o około 30 procent krótszy. Co mogłoby to wyjaśnić? Jednym ze sposobów rozwiązania tego problemu jest uruchomienie zapytania w programie SSMS z włączoną opcją Statystyki zapytań na żywo. Kiedy to zrobiłem, najbardziej prawy operator równoległości (strumieni podziału) zakończył w 6 sekund bez zalecanego indeksu i w 35 sekund z zalecanym indeksem. Kluczową różnicą jest to, że ta pierwsza pobiera dane z indeksu i jest wymianą z zachowaniem kolejności. Ta ostatnia pobiera dane bez kolejności i nie jest wymianą zachowującą porządek. Giełdy z zachowaniem zamówienia są zwykle droższe niż te, które nie zachowują zamówienia. Ponadto, przynajmniej w skrajnej prawej części planu, aż do pierwszego sortowania, ten pierwszy dostarcza wiersze w tej samej kolejności, co kolumna partycjonowania wymiany, więc nie wszystkie wątki naprawdę przetwarzają wiersze równolegle. Później dostarcza wiersze nieuporządkowane, dzięki czemu wszystkie wątki przetwarzają wiersze naprawdę równolegle. Widać, że najwyższy czas oczekiwania w obu planach to CXPACKET, ale w pierwszym przypadku czas oczekiwania jest dwukrotnie dłuższy niż w drugim, co oznacza, że obsługa równoległości w drugim przypadku jest bardziej optymalna. W grę mogą wchodzić inne czynniki, o których nie myślę. Jeśli masz dodatkowe pomysły, które mogłyby wyjaśnić zaskakującą różnicę w wydajności, podziel się nimi.
Na moim laptopie spowodowało to wykonanie bez zalecanego indeksu, który był szybszy niż ten z zalecanym indeksem. Jednak na innej maszynie testowej było odwrotnie. W końcu masz dodatkowy rodzaj, z potencjałem rozlewu.
Z ciekawości przetestowałem wykonanie seryjne (z opcją MAXDOP 1) z zalecanym indeksem i uzyskałem następujące statystyki wydajności na moim laptopie:
elapsed: 42, CPU: 40, logical reads: 143,519
Jak widać, czas wykonywania jest podobny do czasu wykonywania równoległego wykonywania z zalecanym indeksem. W laptopie mam tylko 4 logiczne procesory. Oczywiście Twój przebieg może się różnić w zależności od sprzętu. Chodzi o to, że warto przetestować różne alternatywy, w tym z indeksowaniem i bez indeksowania, które Twoim zdaniem powinno pomóc. Wyniki są czasami zaskakujące i sprzeczne z intuicją.
Rozwiązanie Kamila
Byłem bardzo zaintrygowany rozwiązaniem Kamila, a szczególnie spodobał mi się sposób, w jaki emulował LAG i LEAD z techniką zgodną z przed 2012 rokiem.
Oto kod implementujący pierwszy krok w rozwiązaniu:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
Ten kod generuje następujące dane wyjściowe (pokazując tylko dane dla identyfikatora usługi 1):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
Ten krok oblicza dwa numery wierszy, które są oddalone od siebie o jeden dla każdego wiersza, podzielone według identyfikatora usługi i uporządkowane według czasu rejestrowania. Bieżący numer wiersza reprezentuje czas zakończenia (nazwij go end_time), a bieżący numer wiersza minus jeden reprezentuje czas rozpoczęcia (nazwij go start_time).
Poniższy kod implementuje drugi krok rozwiązania:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; Ten krok generuje następujące dane wyjściowe:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
Ten krok przestawia każdy wiersz na dwa wiersze, duplikując każdy wpis dziennika — raz dla typu time start_time i drugi dla end_time. Jak widać, poza minimalną i maksymalną liczbą wierszy, każdy numer wiersza pojawia się dwukrotnie — raz z czasem rejestracji bieżącego zdarzenia (czas_początku) i drugi z czasem rejestracji poprzedniego zdarzenia (czas_końca).
Poniższy kod implementuje trzeci krok w rozwiązaniu:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; Ten kod generuje następujące dane wyjściowe:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
Ten krok przestawia dane, grupując pary wierszy o tym samym numerze wiersza i zwracając jedną kolumnę dla bieżącego czasu dziennika zdarzeń (czas_początku) i drugą dla poprzedniego czasu dziennika zdarzeń (czas_końca). Ta część skutecznie emuluje funkcję LAG.
Poniższy kod implementuje czwarty krok w rozwiązaniu:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; Ten kod generuje następujące dane wyjściowe:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
Ten krok filtruje pary, w których różnica między poprzednim czasem zakończenia a bieżącym czasem rozpoczęcia jest większa niż dozwolona przerwa, oraz wiersze z tylko jednym zdarzeniem. Teraz musisz połączyć czas rozpoczęcia każdego bieżącego wiersza z czasem zakończenia następnego wiersza. Wymaga to obliczeń podobnych do LEAD. Aby to osiągnąć, kod ponownie tworzy numery wierszy, które są od siebie oddalone, tylko tym razem bieżący numer wiersza reprezentuje czas rozpoczęcia (start_time_grp ), a bieżący numer wiersza minus jeden reprezentuje czas zakończenia (end_time_grp).
Podobnie jak poprzednio, kolejnym krokiem (numer 5) jest odwrócenie rzędów. Oto kod implementujący ten krok:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; Wyjście:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
Jak widać, kolumna grp jest unikalna dla każdej wyspy w ramach identyfikatora usługi.
Krok 6 to ostatni krok w rozwiązaniu. Oto kod implementujący ten krok, który jest również kompletnym kodem rozwiązania:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); Ten krok generuje następujące dane wyjściowe:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
Ten krok grupuje wiersze według identyfikatora usługi i grp, filtruje tylko odpowiednie grupy i zwraca minimalny czas_początku jako początek wyspy oraz maksymalny czas zakończenia jako koniec wyspy.
Rysunek 3 przedstawia plan, który otrzymałem dla tego rozwiązania z zalecanym indeksem:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Plan z zalecanym indeksem na rysunku 3.
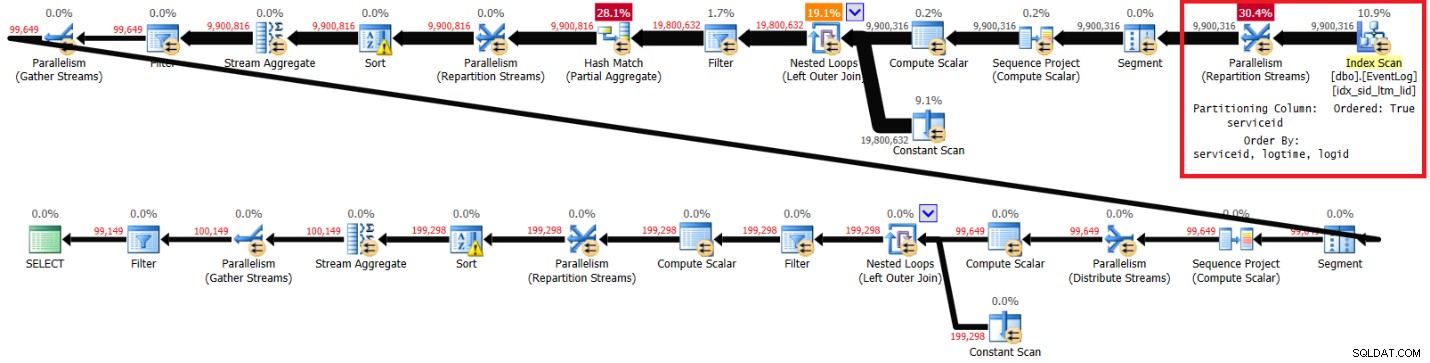 Rysunek 3:Plan rozwiązania Kamila z zalecanym indeksem
Rysunek 3:Plan rozwiązania Kamila z zalecanym indeksem
Oto statystyki wydajności, które uzyskałem dla tego wykonania na moim laptopie:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
Następnie upuściłem zalecany indeks i ponownie uruchomiłem rozwiązanie:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Otrzymałem plan pokazany na rysunku 4 do wykonania bez zalecanego indeksu.
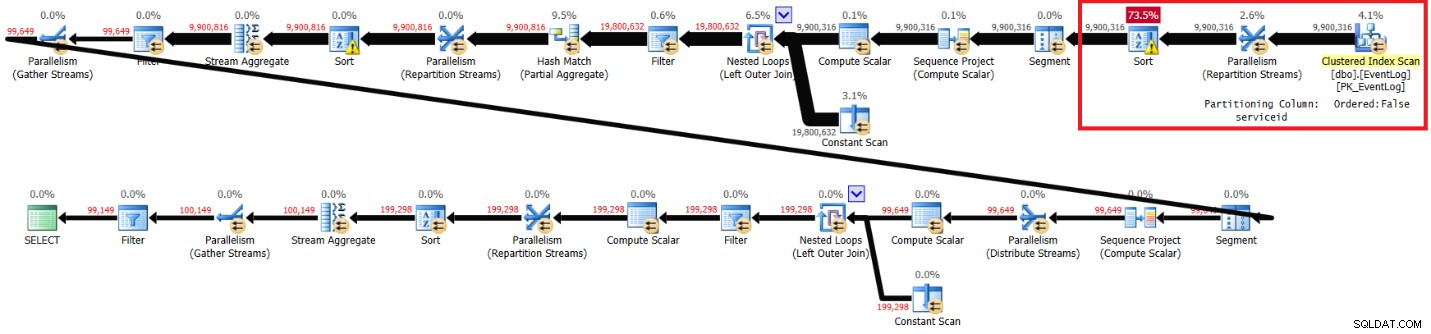 Rysunek 4:Plan rozwiązania Kamila bez zalecanego indeksu
Rysunek 4:Plan rozwiązania Kamila bez zalecanego indeksu
Oto statystyki wydajności, które uzyskałem dla tego wykonania:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
Czasy działania, czasy procesora i czasy oczekiwania CXPACKET są bardzo podobne do mojego rozwiązania, chociaż odczyty logiczne są niższe. Rozwiązanie Kamila działa również szybciej na moim laptopie bez zalecanego indeksu i wydaje się, że dzieje się tak z podobnych powodów.
Wniosek
Anomalie to dobra rzecz. Sprawiają, że stajesz się ciekawy i sprawia, że idziesz i badasz pierwotną przyczynę problemu, a w rezultacie uczysz się nowych rzeczy. Interesujące jest to, że niektóre zapytania na niektórych komputerach działają szybciej bez zalecanego indeksowania.
Jeszcze raz dziękuję Toby'emu, Peterowi i Kamilowi za Wasze rozwiązania. W tym artykule omówiłem rozwiązanie Kamila, z jego kreatywną techniką emulowania LAG i LEAD za pomocą numerów wierszy, unpivoting i pivoting. Ta technika okaże się przydatna, gdy potrzebujesz obliczeń typu LAG i LEAD, które muszą być obsługiwane w środowiskach sprzed 2012 r.