Jednym z najczęstszych terminów pojawiających się w dyskusjach na temat dostrajania wydajności SQL Server jest statystyki oczekiwania . To sięga daleko wstecz, nawet przed tym dokumentem Microsoft z 2006 r. „SQL Server 2005 Waits and Queues”.
Oczekiwanie to absolutnie nie wszystko, a ta metodologia nie jest jedynym sposobem dostrojenia instancji, nie mówiąc już o indywidualnym zapytaniu. W rzeczywistości oczekiwania są często bezużyteczne, gdy jedyne, co masz, to zapytanie, które je spowodowało, i brak otaczającego kontekstu, zwłaszcza długo po fakcie. Dzieje się tak, ponieważ często to, na co czeka zapytanie nie jest jego winą . Jak wszystko, są wyjątki, ale jeśli wybierasz narzędzie lub skrypt tylko dlatego, że oferuje tę bardzo specyficzną funkcjonalność, myślę, że robisz sobie krzywdę. Zwykle stosuję się do rady, którą jakiś czas temu udzielił mi Paul Randal:
… generalnie polecam zacząć od czekania na całą instancję. Nigdy bym nie zaczął rozwiązywanie problemów, patrząc na indywidualne zapytania, które czekają.
Czasami tak, możesz chcieć zagłębić się w indywidualne zapytanie i zobaczyć, na co czeka; w rzeczywistości Microsoft niedawno dodał statystyki oczekiwania na poziomie zapytania, aby pokazać plan, aby pomóc w tej analizie. Ale te liczby zazwyczaj nie pomogą dostroić wydajności instancji jako całości, chyba że pomagają wskazać coś, co wpływa również na całe obciążenie. Jeśli zobaczysz jedno zapytanie z wczoraj, które trwało przez 5 minut, i zauważysz, że jego typ oczekiwania to LCK_M_S , co zamierzasz teraz z tym zrobić? Jak zamierzasz wyśledzić, co faktycznie blokowało zapytanie i powodowało ten typ oczekiwania? Mogło to być spowodowane transakcją, która nie została zatwierdzona z jakiegoś innego powodu, ale nie możesz tego zobaczyć, jeśli nie widzisz stanu całego systemu i skupiasz się tylko na pojedynczych zapytaniach i oczekiwaniach, których doświadczyli.
Jason Hall (@SQLSaurus) wspomniał mimochodem o czymś, co również mnie zainteresowało. Powiedział, że gdyby statystyki oczekiwania na poziomie zapytania były tak ważną częścią wysiłków dostrajających, to ta metodologia zostałaby zapisana w Query Store od samego początku. Został dodany niedawno (w SQL Server 2017). Ale nadal nie otrzymujesz statystyk oczekiwania na wykonanie; otrzymujesz średnie w czasie, takie jak statystyki zapytań i statystyki procedur widoczne w DMV. Tak więc nagłe anomalie mogą być widoczne na podstawie innych danych rejestrowanych przy każdym wykonaniu zapytania, ale nie na podstawie średnich czasów oczekiwania narysowanych na wszystkich egzekucje. Możesz dostosować zakres oczekiwania, który jest agregowany, ale w obciążonych systemach może to nie być wystarczająco szczegółowe, aby zrobić to, co Twoim zdaniem zrobi dla Ciebie.
Celem tego postu jest omówienie niektórych z bardziej powszechnych typów oczekiwania, które widzimy w naszej bazie klientów, oraz tego, jakie działania możesz (i nie powinieneś) podejmować, gdy się pojawią. Mamy bazę danych anonimowych statystyk oczekiwania, które zbieramy od naszych klientów Cloud Sync od dłuższego czasu, a od maja 2017 pokazujemy wszystkim, jak wyglądają one w bibliotece SQLskills Waits Library.
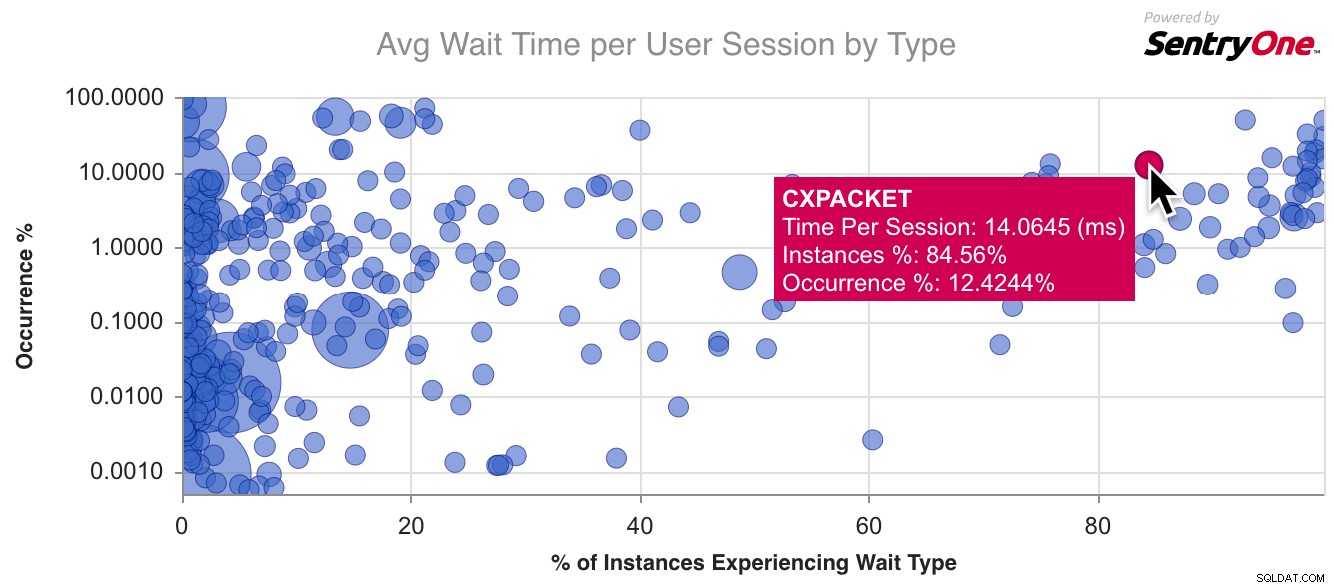
Paul opowiada o przyczynie powstania biblioteki, a także o naszej integracji z tą bezpłatną usługą. Zasadniczo wyszukujesz typ oczekiwania, którego doświadczasz lub jesteś ciekawy, a on wyjaśnia, co to znaczy i co możesz z tym zrobić. Uzupełniamy te jakościowe informacje o wykres pokazujący, jak powszechne jest obecne oczekiwanie wśród naszej bazy użytkowników, porównując to do wszystkich innych typów oczekiwań, które widzimy, dzięki czemu możesz szybko stwierdzić, czy masz do czynienia z powszechnym rodzajem oczekiwania, czy z czymś więcej egzotyczny. (Należy pamiętać, że SQL Sentry nie uwzględnia łagodnego oczekiwania w tle i oczekiwania w kolejce tak dużo szumu, jak i że większość skryptów, takich jak WAITFOR lub LAZYWRITER_SLEEP, jest odfiltrowywana – nie są to po prostu źródła problemów z wydajnością).
Oto przykładowy wykres dla CXPACKET , najczęstszy typ czekania:
Zacząłem iść nieco dalej, mapując niektóre z bardziej powszechnych typów oczekiwania i odnotowując niektóre wspólne właściwości. Przetłumaczone na pytania tunera dotyczące rodzaju oczekiwania, którego doświadczają:
- Czy typ oczekiwania można rozwiązać na poziomie zapytania?
- Czy główny objaw oczekiwania może mieć wpływ na inne zapytania?
- Czy prawdopodobnie będziesz potrzebować więcej informacji poza kontekstem pojedynczego zapytania i typami oczekiwania, których doświadczyłeś, aby „rozwiązać” problem?
Kiedy postanowiłem napisać ten post, moim celem było pogrupowanie najczęstszych typów oczekiwania, a następnie rozpoczęcie robienia notatek na ich temat w odniesieniu do powyższych pytań. Jason wyciągnął najpopularniejsze z biblioteki, a potem narysowałem na tablicy drapanie od kurczaka, które później trochę uporządkowałem. Te wstępne badania doprowadziły do przemówienia, które Jason wygłosił podczas najnowszego rejsu TechOutbound SQL na Alasce. Trochę się wstydzę, że rozmawiał na kilka miesięcy przed ukończeniem tego posta, więc po prostu zabierajmy się za to. Oto najważniejsze oczekiwania, które widzimy (które w dużej mierze pasują do ankiety Paula z 2014 r.), moje odpowiedzi na powyższe pytania i kilka komentarzy do każdego z nich:
Aby wejść w interakcję z linkami w poniższej tabeli, odwiedź tę stronę na szerszym ekranie.
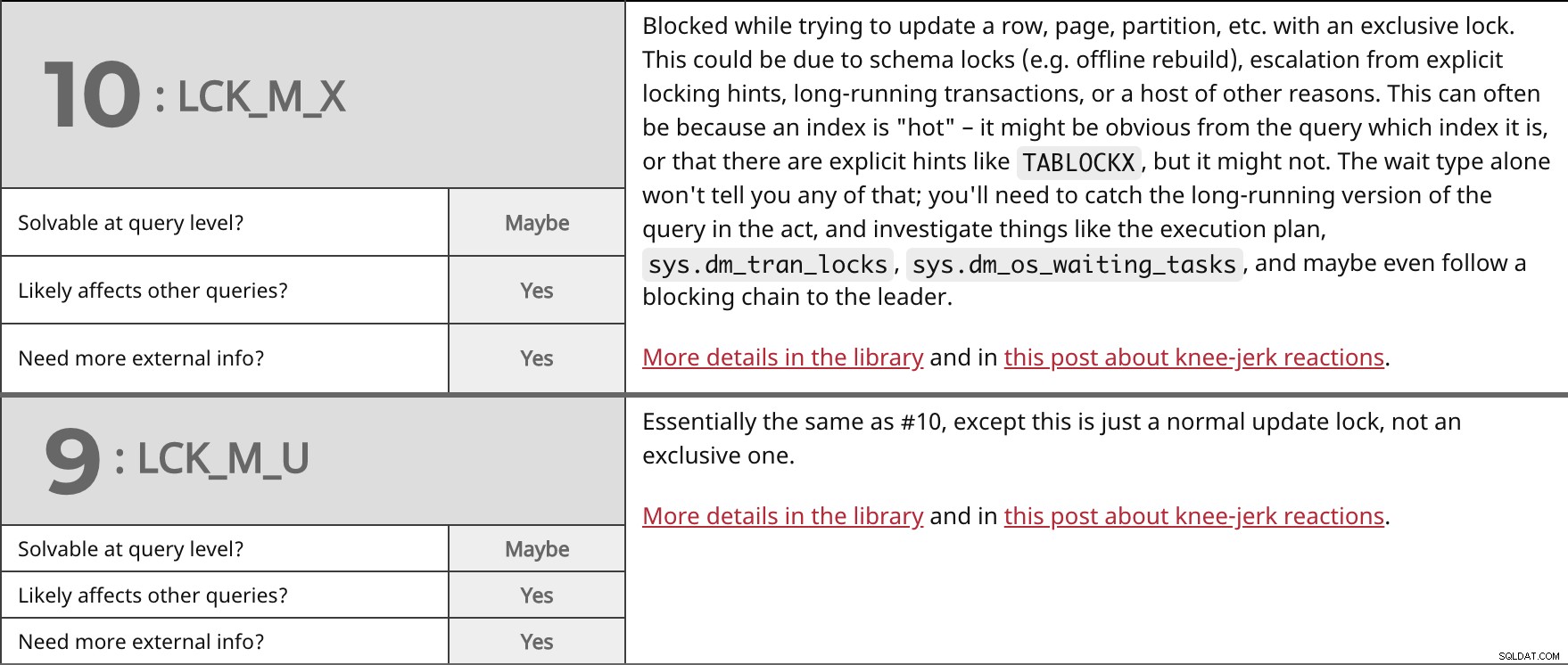
Zablokowane podczas próby aktualizacji wiersza, strony, partycji itp. z blokadą na wyłączność. Może to być spowodowane blokadami schematu (np. przebudowa offline), eskalacją jawnych wskazówek dotyczących blokowania, długotrwałymi transakcjami lub wieloma innymi przyczynami. Często może to wynikać z tego, że indeks jest „gorący” – z zapytania może wynikać, który to indeks, lub że istnieją wyraźne wskazówki, takie jak TABLOCKX , ale może nie. Sam typ oczekiwania nie powie ci tego; będziesz musiał przechwycić długo działającą wersję zapytania w akcie i zbadać takie rzeczy, jak plan wykonania, sys.dm_tran_locks , sys.dm_os_waiting_tasks , a może nawet podążać za łańcuchem blokującym do lidera. Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Tak | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
|
W zasadzie to samo co nr 10, z wyjątkiem tego, że jest to zwykła blokada aktualizacji, a nie wyłączna. Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Tak | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
|
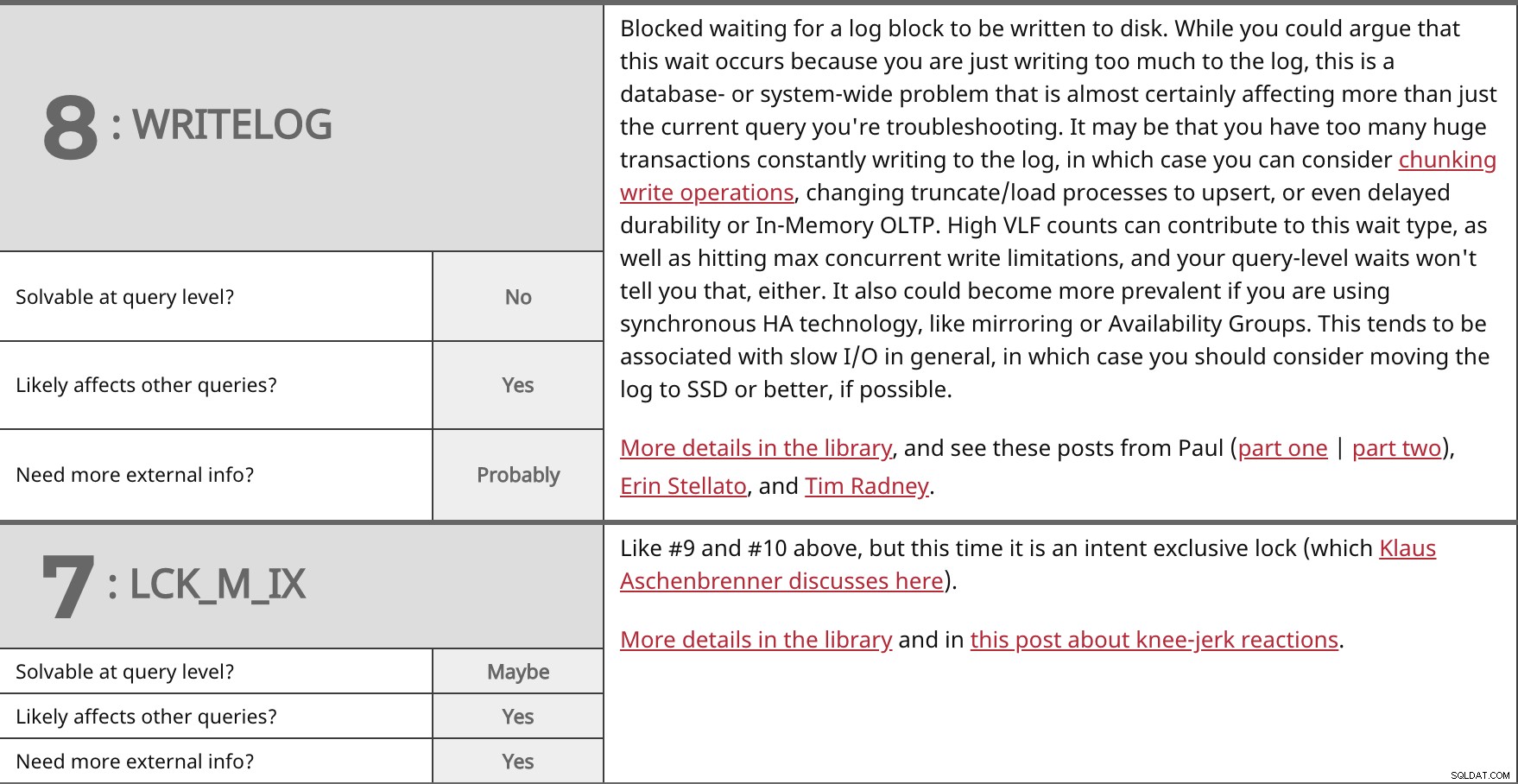
Zablokowane oczekiwanie na zapisanie bloku dziennika na dysku. Chociaż można argumentować, że to oczekiwanie występuje, ponieważ po prostu zapisujesz za dużo w dzienniku, jest to problem dotyczący bazy danych lub systemu, który prawie na pewno wpływa nie tylko na bieżące zapytanie, z którym rozwiązujesz problem. Może się zdarzyć, że masz zbyt wiele ogromnych transakcji, które stale zapisują w dzienniku, w takim przypadku możesz rozważyć podział operacji zapisu, zmianę procesów obcinania/ładowania na upsser, a nawet opóźnioną trwałość lub OLTP w pamięci. Wysoka liczba VLF może przyczynić się do tego typu oczekiwania, a także do osiągnięcia maksymalnych ograniczeń współbieżnego zapisu, a oczekiwania na poziomie zapytania również tego nie powiedzą. Może również stać się bardziej rozpowszechnione, jeśli używasz synchronicznej technologii HA, takiej jak dublowanie lub grupy dostępności. Zwykle wiąże się to z wolnymi operacjami we/wy, w takim przypadku należy rozważyć przeniesienie dziennika na dysk SSD lub lepszy, jeśli to możliwe. Więcej szczegółów w bibliotece i zobacz te posty Paula (część pierwsza | część druga), Erin Stellato i Tima Radneya. | ||
| Do rozwiązania na poziomie zapytania? | Nie | |
| Tak | ||
| Potrzebujesz więcej informacji zewnętrznych? | Prawdopodobnie | |
|
Podobnie jak #9 i #10 powyżej, ale tym razem jest to celowa blokada na wyłączność (którą omawia tutaj Klaus Aschenbrenner). Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Tak | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
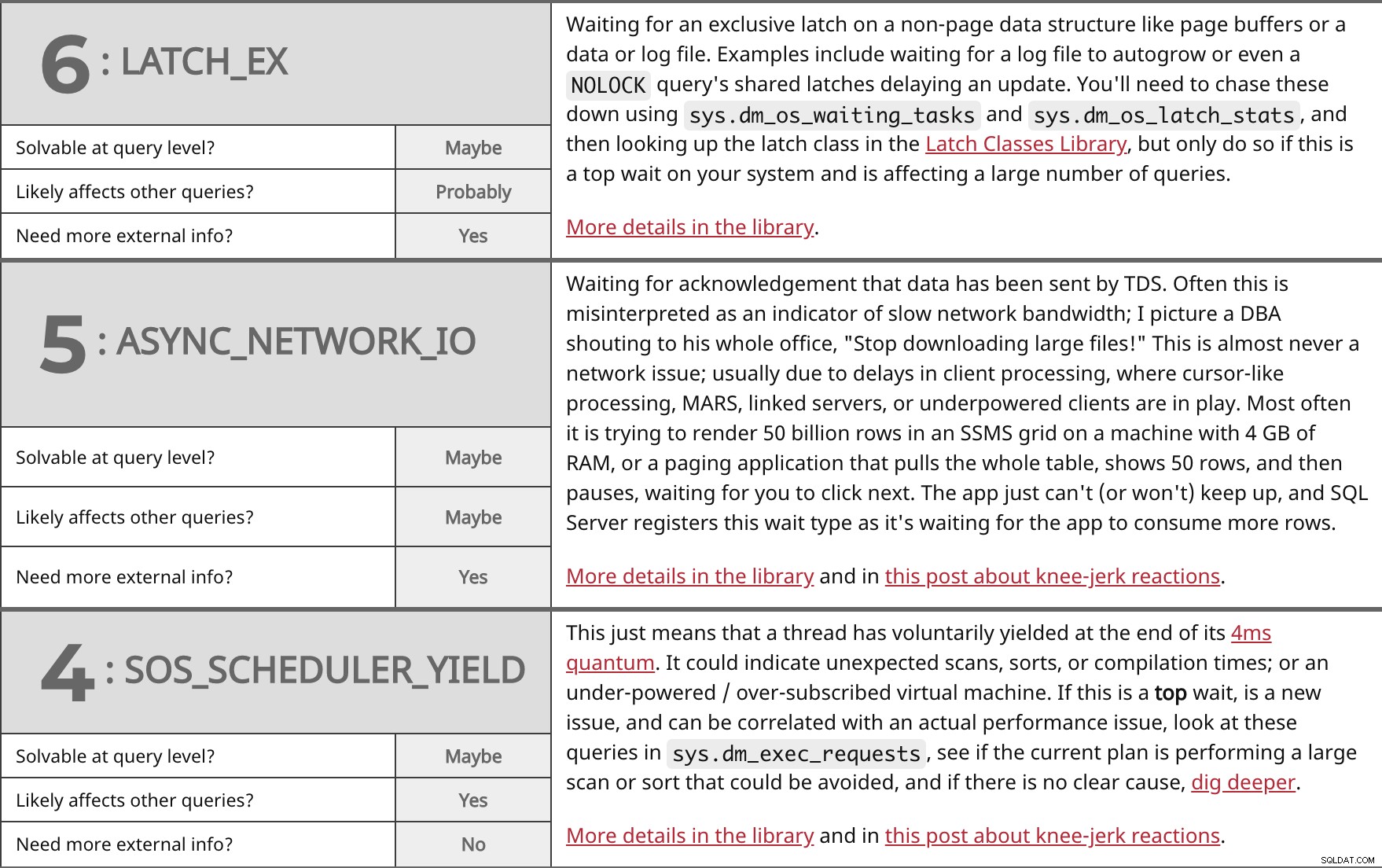
Oczekiwanie na wyłączne zatrzask w strukturze danych nie będącej stroną, takiej jak bufory stron lub plik danych lub dziennika. Przykłady obejmują oczekiwanie na automatyczny wzrost pliku dziennika lub nawet NOLOCK współdzielone zatrzaski zapytania opóźniają aktualizację. Musisz je ścigać za pomocą sys.dm_os_waiting_tasks i sys.dm_os_latch_stats , a następnie wyszukaj klasę latch w Bibliotece klas Latch, ale rób to tylko wtedy, gdy jest to najwyższy czas oczekiwania w systemie i wpływa na dużą liczbę zapytań. Więcej szczegółów w bibliotece. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Prawdopodobnie | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
|
Oczekiwanie na potwierdzenie wysłania danych przez TDS. Często jest to błędnie interpretowane jako wskaźnik wolnej przepustowości sieci; Wyobrażam sobie DBA krzyczącego do całego biura:„Przestań pobierać duże pliki!” To prawie nigdy nie jest problem z siecią; zwykle z powodu opóźnień w przetwarzaniu klienta, gdzie w grę wchodzą przetwarzanie podobne do kursora, MARS, serwery połączone lub klienci o słabej mocy. Najczęściej jest to próba renderowania 50 miliardów wierszy w siatce SSMS na maszynie z 4 GB pamięci RAM lub aplikacji stronicowania, która ściąga całą tabelę, pokazuje 50 wierszy, a następnie zatrzymuje się, czekając, aż klikniesz dalej. Aplikacja po prostu nie może (lub nie będzie) nadążyć, a SQL Server rejestruje ten typ oczekiwania, ponieważ czeka, aż aplikacja zużyje więcej wierszy. Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Być może | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
Oznacza to po prostu, że wątek dobrowolnie ustąpił na końcu swojego kwantu 4 ms. Może wskazywać na nieoczekiwane skanowanie, sortowanie lub czasy kompilacji; lub maszyna wirtualna o słabym zasilaniu/nadmiernej subskrypcji. Jeśli to jest top czekaj, jest nowym problemem i może być skorelowany z rzeczywistym problemem z wydajnością, spójrz na te zapytania w sys.dm_exec_requests , sprawdź, czy obecny plan wykonuje duże skanowanie lub sortowanie, których można by uniknąć, a jeśli nie ma jasnej przyczyny, poszukaj głębiej. Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Tak | ||
| Potrzebujesz więcej informacji zewnętrznych? | Nie | |
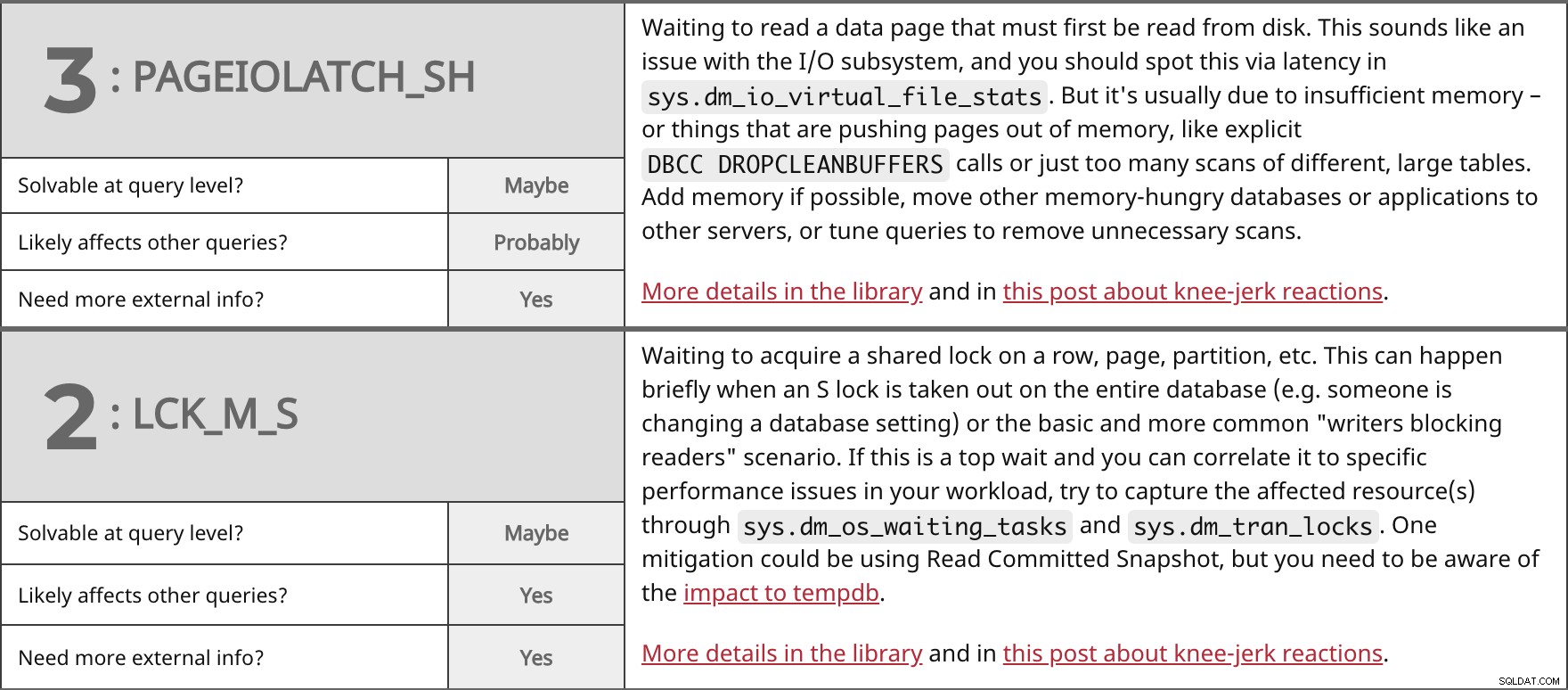
Oczekiwanie na odczytanie strony danych, która musi być najpierw odczytana z dysku. Brzmi to jak problem z podsystemem we/wy i powinieneś zauważyć to przez opóźnienie w sys.dm_io_virtual_file_stats . Ale zwykle jest to spowodowane niewystarczającą ilością pamięci — lub rzeczami, które wypychają strony z pamięci, takie jak jawne DBCC DROPCLEANBUFFERS połączeń lub po prostu zbyt wiele skanów różnych, dużych tabel. Jeśli to możliwe, dodaj pamięć, przenieś inne wymagające pamięci bazy danych lub aplikacje na inne serwery lub dostosuj zapytania, aby usunąć niepotrzebne skanowanie. Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Prawdopodobnie | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
Oczekiwanie na uzyskanie wspólnej blokady w wierszu, stronie, partycji itp. Może się to zdarzyć na krótko, gdy blokada S zostanie zdjęta w całej bazie danych (np. ktoś się zmienia ustawienie bazy danych) lub podstawowy i bardziej powszechny scenariusz „writers blocking readers”. Jeśli jest to najważniejszy moment oczekiwania i możesz go skorelować z konkretnymi problemami z wydajnością w swoim obciążeniu, spróbuj przechwycić zasoby, których dotyczy problem, za pomocą sys.dm_os_waiting_tasks i sys.dm_tran_locks . Jednym ze środków zaradczych może być użycie odczytu zatwierdzonej migawki, ale musisz mieć świadomość wpływu na tempdb. Więcej szczegółów w bibliotece i w tym poście o odruchowych reakcjach. | ||
| Do rozwiązania na poziomie zapytania? | Być może | |
| Tak | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
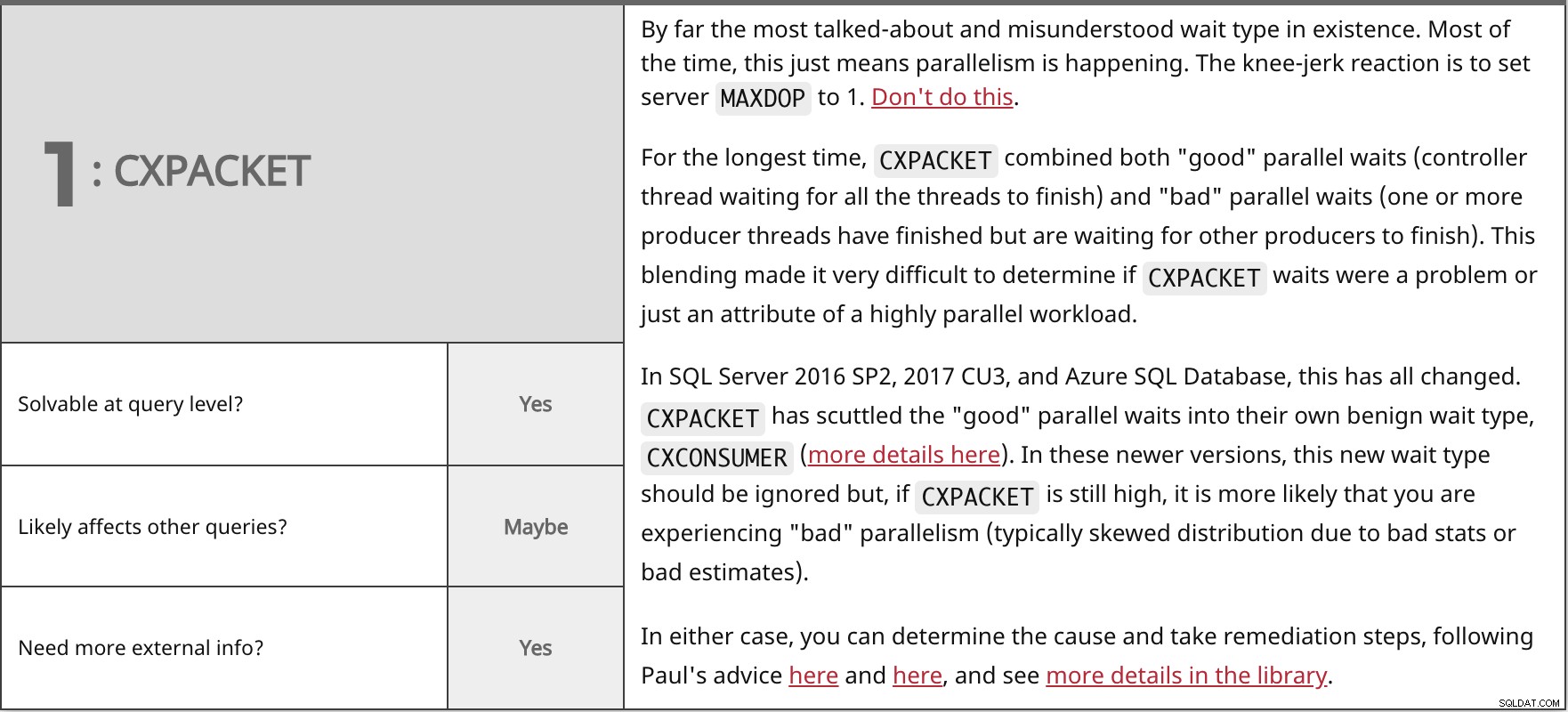
Zdecydowanie najczęściej omawiany i niezrozumiany typ oczekiwania. W większości przypadków oznacza to po prostu paralelizm. Odruchową reakcją jest ustawienie serwera MAXDOP do 1. Nie rób tego.
Najdłużej
W SQL Server 2016 SP2, 2017 CU3 i Azure SQL Database wszystko się zmieniło. W obu przypadkach możesz określić przyczynę i podjąć kroki naprawcze, postępując zgodnie z radą Paula tutaj i tutaj, i zobaczyć więcej szczegółów w bibliotece. | ||
| Do rozwiązania na poziomie zapytania? | Tak | |
| Być może | ||
| Potrzebujesz więcej informacji zewnętrznych? | Tak | |
Podsumowanie
W większości takich przypadków lepiej jest przyjrzeć się oczekiwaniom na poziomie wystąpienia i skupiać się na oczekiwaniu na poziomie zapytania tylko podczas rozwiązywania konkretnych zapytań, które wykazują problemy z wydajnością niezależnie od typu oczekiwania. Są to rzeczy, które pojawiają się z innych powodów, takich jak długi czas trwania, wysoki procesor lub duża liczba operacji we/wy, i nie można ich wyjaśnić prostszymi rzeczami (np. skanowanie indeksu klastrowego, gdy oczekiwano wyszukiwania).
Nawet na poziomie instancji nie ścigaj każdego oczekiwania, które staje się najwyższym oczekiwaniem w twoim systemie – będziesz ZAWSZE poczekaj na szczyt, a nigdy nie będziesz w stanie przestać go gonić. Upewnij się, że ignorujesz łagodne oczekiwanie (Paul prowadzi listę) i martwisz się tylko oczekiwaniem, które możesz powiązać z rzeczywistym problemem z wydajnością, którego doświadczasz. Jeśli CXPACKET oczekiwania są wysokie, więc co z tego? Czy oprócz tego, że liczba jest „wysoka” lub znajduje się na szczycie listy, są jakieś inne objawy?
Wszystko sprowadza się do tego, dlaczego w pierwszej kolejności rozwiązujesz problemy. Czy pojedynczy użytkownik skarży się na pojedyncze wystąpienie nieuczciwego zapytania? Czy Twój serwer na kolanach? Coś pomiędzy? W pierwszym przypadku wiedza o tym, dlaczego zapytanie jest powolne, może być przydatna, ale śledzenie (nieważne, że w nieskończoność) wszystkich czekań związanych z każdym pojedynczym zapytaniem jest dość kosztowne, przez cały dzień, każdego dnia, przy nieoczekiwanej okazji chcesz wrócić i przejrzeć je później. Jeśli jest to powszechny problem izolowany dla tego zapytania, powinieneś być w stanie określić, co spowalnia to zapytanie, uruchamiając je ponownie i zbierając plan wykonania, czas kompilacji i inne metryki środowiska uruchomieniowego. Jeśli była to jednorazowa rzecz, która wydarzyła się w zeszły wtorek, niezależnie od tego, czy masz oczekiwania na to pojedyncze wystąpienie zapytania, czy nie, możesz nie być w stanie rozwiązać problemu bez większego kontekstu. Może było blokowanie, ale nie będziesz wiedział, przez co, a może wystąpił skok we/wy, ale musisz osobno wyśledzić ten problem. Sam typ oczekiwania zwykle nie dostarcza wystarczającej ilości informacji, z wyjątkiem, w najlepszym przypadku, wskaźnika do czegoś innego.
Oczywiście, tutaj też muszę zarobić na swoje utrzymanie. Nasz flagowy produkt, SQL Sentry, prezentuje całościowe podejście do monitoringu. Zbieramy statystyki oczekiwania dla całej instancji, klasyfikujemy je dla Ciebie i przedstawiamy na wykresie na naszym pulpicie nawigacyjnym:
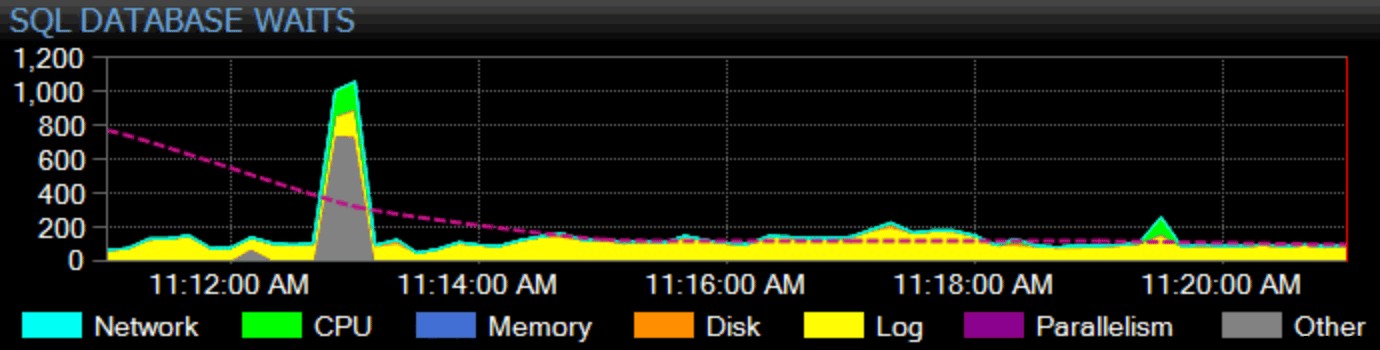
Możesz dostosować kategoryzację każdego indywidualnego oczekiwania i czy ta kategoria pojawia się na pulpicie nawigacyjnym. Możesz porównać bieżące statystyki oczekiwania z wbudowanymi lub niestandardowymi liniami bazowymi, a nawet skonfigurować alerty lub akcje, gdy przekroczą określone odchylenie od linii bazowej. I, co być może najważniejsze, możesz spojrzeć na punkt danych z przeszłości i zsynchronizować cały pulpit nawigacyjny do tego punktu w czasie, aby uchwycić cały otaczający kontekst i każdą inną sytuację, która mogła mieć wpływ na problem. Gdy znajdziesz bardziej szczegółowe rzeczy, na których można się skoncentrować, takie jak blokowanie, duże opóźnienia dysku lub zapytania z wysokimi operacjami we/wy lub długim czasem trwania, możesz drążyć te metryki i dość szybko dotrzeć do źródła problemu.
Aby uzyskać więcej informacji na temat ogólnych statystyk oczekiwania, a konkretnie naszego rozwiązania, możesz zapoznać się z dokumentem Kevina Kline'a Rozwiązywanie problemów ze statystykami oczekiwania na serwer SQL, a także pobrać dwuczęściowe seminarium internetowe przedstawione przez Paula Randala, Andy'ego Yuna (@SQLBek). i Andy Mallon (@AMtwo):
- Część 1:Rozwiązywanie problemów z wydajnością za pomocą statystyk oczekiwania
- Część 2:Szybka analiza statystyk oczekiwania za pomocą SentryOne
A jeśli chcesz wypróbować platformę SentryOne, możesz zacząć tutaj, korzystając z oferty ograniczonej czasowo:
Pobierz 15-dniowy bezpłatny okres próbny