Kiedy jesteś głęboko zaangażowany w rozwiązywanie problemów w programie SQL Server, czasami chcesz poznać dokładną kolejność wykonywania zapytań. Widzę to w przypadku bardziej skomplikowanych procedur składowanych, które zawierają warstwy logiki, lub w scenariuszach, w których jest dużo nadmiarowego kodu. Zdarzenia rozszerzone są tutaj naturalnym wyborem, ponieważ są zwykle używane do przechwytywania informacji o wykonywaniu zapytań. Często możesz użyć identyfikatora sesji i znacznika czasu, aby zrozumieć kolejność zdarzeń, ale jest opcja sesji dla XE, która jest jeszcze bardziej niezawodna:Śledź przyczynowość.
Gdy włączysz śledzenie przyczynowości dla sesji, do każdego zdarzenia zostanie dodany identyfikator GUID i numer sekwencyjny, których można następnie użyć do prześledzenia kolejności występowania zdarzeń. Koszty ogólne są minimalne i mogą być znaczną oszczędnością czasu w wielu scenariuszach rozwiązywania problemów.
Konfiguracja
Korzystając z bazy danych WideWorldImporters, utworzymy procedurę składowaną do użycia:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Następnie utworzymy sesję wydarzenia:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); Zamierzamy również uruchamiać zapytania ad hoc, więc przechwytujemy zarówno sp_statement_completed (wypowiedzi ukończone w ramach procedury składowanej), jak i sql_statement_completed (ukończone instrukcje, które nie znajdują się w procedurze składowanej). Zauważ, że opcja TRACK_CAUSALITY dla sesji jest ustawiona na ON. Ponownie, to ustawienie jest specyficzne dla sesji zdarzenia i musi być włączone przed jej uruchomieniem. Nie możesz włączyć tego ustawienia w locie, na przykład możesz dodawać lub usuwać zdarzenia i cele podczas trwania sesji.
Aby rozpocząć sesję wydarzenia za pomocą interfejsu użytkownika, kliknij go prawym przyciskiem myszy i wybierz opcję Rozpocznij sesję.
Testowanie
W Management Studio uruchomimy następujący kod:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Oto nasze wyjście XE:

Zauważ, że pierwsze wykonane zapytanie, które jest podświetlone, to SELECT @@SPID i ma identyfikator GUID FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. Nie wykonaliśmy tego zapytania, wystąpiło ono w tle i chociaż sesja XE jest skonfigurowana do odfiltrowywania zapytań systemowych, to – z jakiegokolwiek powodu – jest nadal przechwytywane.
Następne cztery wiersze reprezentują kod, który faktycznie wykonaliśmy. Istnieją dwa zapytania z procedury składowanej, sama procedura składowana, a następnie nasze zapytanie ad hoc. Wszystkie mają ten sam GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Obok identyfikatora GUID znajduje się identyfikator sekwencji (seq), a zapytania są ponumerowane od jednego do czterech.
W naszym przykładzie nie użyliśmy GO do rozdzielenia instrukcji na różne partie. Zwróć uwagę, jak zmienia się wyjście, gdy to robimy:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

Nadal mamy taką samą liczbę wierszy, ale teraz mamy trzy identyfikatory GUID. Jeden dla SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), jeden dla trzech zapytań reprezentujących procedurę składowaną (F962B9A4-0665-4802-9E6C-B217634D8787) i jeden dla zapytania ad hoc (5DD6A5FE -9702-4DE5-8467-8D7CF55B5D80).
To najprawdopodobniej zobaczysz, patrząc na dane z aplikacji, ale zależy to od tego, jak aplikacja działa. Jeśli korzysta z puli połączeń, a połączenia są regularnie resetowane (co jest oczekiwane), każde połączenie będzie miało swój własny identyfikator GUID.
Możesz go odtworzyć, korzystając z przykładowego kodu PowerShell poniżej:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Oto przykład wyjścia zdarzeń rozszerzonych po krótkim czasie działania kodu:

Istnieją cztery różne identyfikatory GUID dla naszych pięciu instrukcji, a jeśli spojrzysz na powyższy kod, zobaczysz, że wykonano cztery różne połączenia. Jeśli zmienisz sesję zdarzenia tak, aby zawierała zdarzenie rpc_completed, możesz zobaczyć wpisy z exec sp_reset_connection.
Twoje dane wyjściowe XE będą zależeć od kodu i aplikacji; Wspomniałem na początku, że jest to przydatne przy rozwiązywaniu problemów z bardziej złożonymi procedurami składowanymi. Rozważ następujący przykład:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Tutaj mamy dwie procedury składowane, usp_TransctionInfo i usp_GetFullCustomerInfo, które są wywoływane przez inną procedurę składowaną, usp_GetCustomerData. Często zdarza się to, a nawet dodatkowe poziomy zagnieżdżenia z procedurami składowanymi. Jeśli wykonamy usp_GetCustomerData z Management Studio, zobaczymy:
EXEC [Sales].[usp_GetCustomerData] 981;

Tutaj wszystkie wykonania wystąpiły na tym samym identyfikatorze GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, i możemy zobaczyć kolejność wykonywania zapytania od jednego do ośmiu przy użyciu kolumny seq. W przypadkach, w których wywoływanych jest wiele procedur składowanych, często zdarza się, że wartość identyfikatora sekwencji sięga setek lub tysięcy.
Wreszcie, w przypadku, gdy patrzysz na wykonanie zapytania i uwzględniłeś przyczynę śledzenia, i znajdujesz zapytanie, które ma niską skuteczność – ponieważ posortowałeś dane wyjściowe na podstawie czasu trwania lub jakiegoś innego wskaźnika, pamiętaj, że możesz znaleźć inne zapytania grupując według GUID:
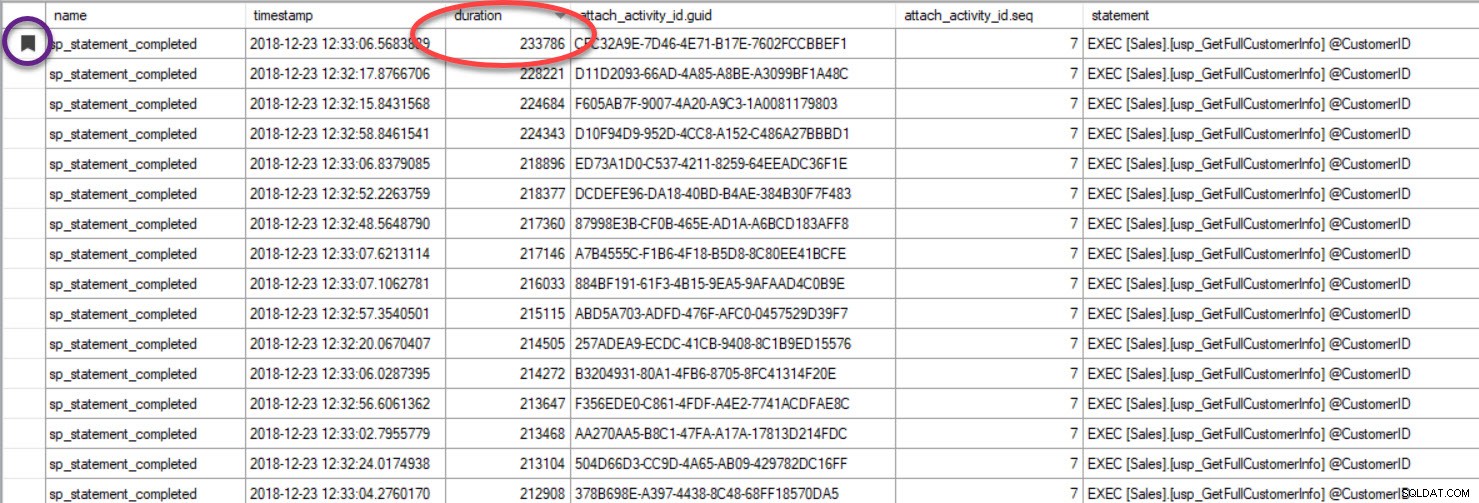
Dane wyjściowe zostały posortowane według czasu trwania (najwyższa wartość zakreślona na czerwono) i dodałem je do zakładek (na fioletowo) za pomocą przycisku Przełącz zakładkę. Jeśli chcemy zobaczyć inne zapytania dotyczące identyfikatora GUID, pogrupuj według identyfikatora GUID (kliknij prawym przyciskiem myszy nazwę kolumny u góry, a następnie wybierz opcję Grupuj według tej kolumny), a następnie użyj przycisku Następna zakładka, aby wrócić do naszego zapytania:
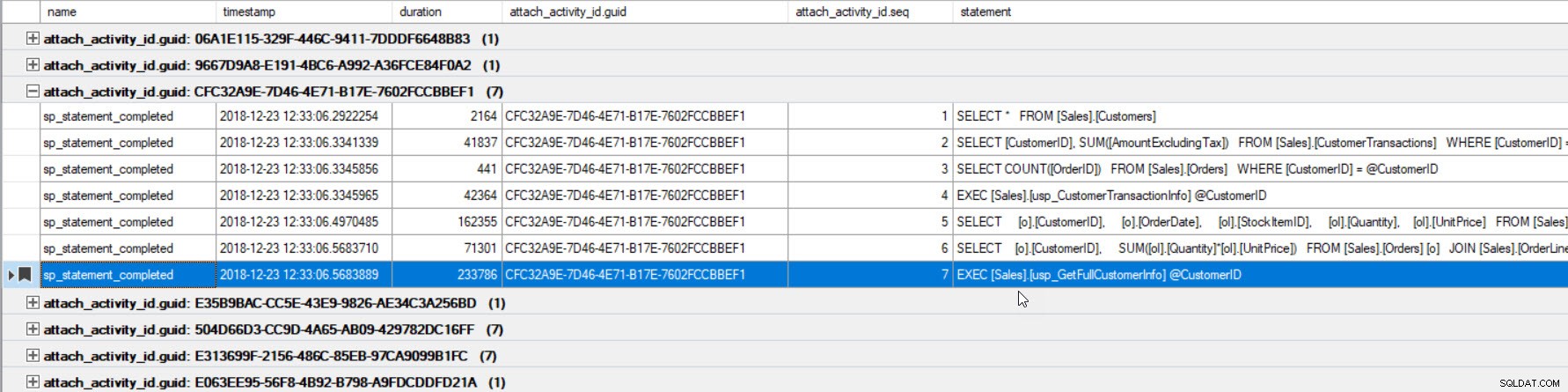
Teraz możemy zobaczyć wszystkie zapytania, które zostały wykonane w ramach tego samego połączenia i w wykonanej kolejności.
Wniosek
Opcja Śledź przyczynowość może być niezwykle przydatna podczas rozwiązywania problemów z wydajnością zapytań i próby zrozumienia kolejności zdarzeń w SQL Server. Jest to również przydatne podczas konfigurowania sesji zdarzenia, która korzysta z celu pair_matching, aby upewnić się, że dopasowujesz właściwe pole/działanie i znajdujesz właściwe niedopasowane zdarzenie. Ponownie, jest to ustawienie na poziomie sesji, więc należy je zastosować przed rozpoczęciem sesji wydarzenia. W przypadku trwającej sesji zatrzymaj sesję zdarzeń, włącz opcję, a następnie uruchom ją ponownie.



