Kilka tygodni temu na PASS Summit firma Microsoft wydała CTP2.1 SQL Server 2019, a jednym z dużych ulepszeń funkcji zawartych w CTP jest skalarne podszycie UDF. Przed wydaniem tej wersji chciałem pobawić się różnicą wydajności między wstawianiem skalarnych funkcji UDF a wykonaniem RBAR (wiersz po rzędzie) skalarnych funkcji UDF we wcześniejszych wersjach SQL Server i natrafiłem na opcję składni dla UTWÓRZ FUNKCJĘ oświadczenie w SQL Server Books Online, którego nigdy wcześniej nie widziałem.
DDL dla TWORZENIA FUNKCJI obsługuje klauzulę WITH dla opcji funkcji i podczas czytania Books Online zauważyłem, że składnia zawiera:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
} Byłem bardzo ciekaw ZWROTY NULL NA NULL INPUT opcja funkcji, więc postanowiłem zrobić kilka testów. Byłem bardzo zaskoczony, gdy dowiedziałem się, że jest to forma skalarnej optymalizacji UDF, która jest obecna w produkcie od co najmniej SQL Server 2008 R2.
Okazuje się, że jeśli wiesz, że skalarny UDF zawsze zwróci wynik NULL, gdy podane zostanie wejście NULL, to UDF powinien ZAWSZE być utworzony z Zwraca NULL ON NULL INPUT opcji, ponieważ wtedy SQL Server w ogóle nie uruchamia definicji funkcji dla żadnych wierszy, w których dane wejściowe mają wartość NULL – w efekcie skracając je i unikając marnowania wykonania treści funkcji.
Aby pokazać to zachowanie, użyję instancji SQL Server 2017 z zastosowaną do niej najnowszą zbiorczą aktualizacją i AdventureWorks2017 baza danych z GitHub (możesz ją pobrać stąd), która jest dostarczana z dbo.ufnLeadingZeros funkcja, która po prostu dodaje wiodące zera do wartości wejściowej i zwraca ośmioznakowy ciąg, który zawiera te wiodące zera. Zamierzam utworzyć nową wersję tej funkcji, która zawiera RETURNS NULL ON NULL INPUT opcję, abym mógł porównać ją z oryginalną funkcją pod kątem wydajności wykonania.
USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GO W celu przetestowania różnic w wydajności wykonywania w ramach silnika bazy danych dwóch funkcji, zdecydowałem się utworzyć sesję Extended Events na serwerze w celu śledzenia sqlserver.module_end zdarzenie, które jest uruchamiane na końcu każdego wykonania skalarnego UDF dla każdego wiersza. To pozwoliło mi zademonstrować semantykę przetwarzania wiersz po wierszu, a także śledzić, ile razy funkcja została faktycznie wywołana podczas testu. Postanowiłem również zebrać sql_batch_completed i sql_statement_completed zdarzenia i filtruj wszystko według session_id aby upewnić się, że przechwytuję tylko informacje związane z sesją, na której faktycznie przeprowadzałem testy (jeśli chcesz powtórzyć te wyniki, musisz zmienić 74 we wszystkich miejscach w poniższym kodzie na dowolny identyfikator sesji testu kod będzie działał). Sesja wydarzenia używa TRACK_CAUSALITY dzięki czemu można łatwo policzyć, ile wykonań funkcji nastąpiło za pośrednictwem activity_id.seq_no wartość zdarzeń (która wzrasta o jeden dla każdego zdarzenia, które spełnia session_id filtr).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Po uruchomieniu sesji zdarzeń i otwarciu przeglądarki danych na żywo w Management Studio uruchomiłem dwa zapytania; jeden używający oryginalnej wersji funkcji do dopełniania zer do CurrencyRateID kolumna w Sales.SalesOrderHeader tabeli i nowej funkcji do generowania identycznych danych wyjściowych, ale przy użyciu ZWRACA NULL NA NULL INPUT i przechwyciłem informacje o rzeczywistym planie wykonania dla porównania.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
Przeglądanie danych o zdarzeniach rozszerzonych pokazało kilka interesujących rzeczy. Po pierwsze, oryginalna funkcja została uruchomiona 31 465 razy (od zliczenia module_end zdarzenia) i całkowity czas procesora dla sql_statement_completed wydarzenie trwało 204 ms i trwało 482 ms.
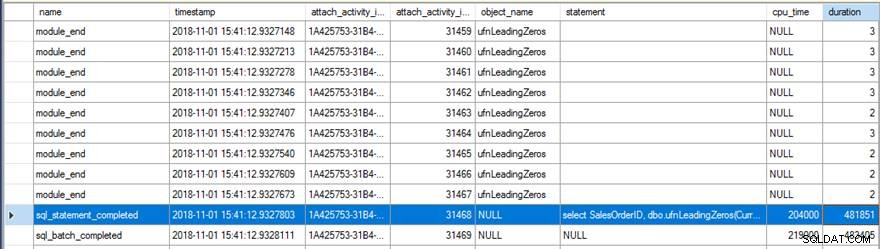
Nowa wersja z RETURNS NULL ON NULL INPUT określona opcja została uruchomiona tylko 13 976 razy (ponownie, licząc od liczby module_end zdarzenia) i czas procesora dla sql_statement_completed wydarzenie trwało 78 ms i trwało 359 ms.

Wydało mi się to interesujące, więc aby zweryfikować liczbę wykonań, uruchomiłem następujące zapytanie, aby zliczyć NOT NULL wiersze wartości, wiersze wartości NULL i wiersze sum w Sales.SalesOrderHeader tabela.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader;
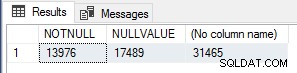
Te liczby odpowiadają dokładnie liczbie module_end zdarzenia dla każdego z testów, więc jest to zdecydowanie bardzo prosta optymalizacja wydajności dla skalarnych UDF, która powinna być używana, jeśli wiesz, że wynik funkcji będzie NULL, jeśli wartości wejściowe są NULL, aby skrócić/pominąć wykonanie funkcji całkowicie dla tych wierszy.
Informacje QueryTimeStats w rzeczywistych planach wykonania również odzwierciedlały wzrost wydajności:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" /> <QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />
Jest to dość znaczne skrócenie samego czasu procesora, co może być poważnym problemem dla niektórych systemów.
Użycie skalarnych funkcji UDF jest dobrze znanym antywzorcem projektowym zwiększającym wydajność i istnieje wiele metod przepisywania kodu, aby uniknąć ich użycia i obniżenia wydajności. Ale jeśli są już na miejscu i nie można ich łatwo zmienić lub usunąć, po prostu odtwórz UDF za pomocą RETURNS NULL ON NULL INPUT opcja może być bardzo prostym sposobem na zwiększenie wydajności, jeśli w zestawie danych, w którym używany jest UDF, jest wiele wejść NULL.