Wprowadzenie
Chętna szpula indeksu odczytuje wszystkie wiersze ze swojego operatora podrzędnego do indeksowanej tabeli roboczej, zanim zacznie zwracać wiersze do swojego operatora nadrzędnego. Pod pewnymi względami gorliwa szpula indeksu jest ostateczną sugestią braku indeksu , ale nie jest to zgłaszane jako takie.
Ocena kosztów
Wstawianie wierszy do indeksowanej tabeli roboczej jest stosunkowo tanie, ale nie bezpłatne. Optymalizator musi wziąć pod uwagę, że włożona praca pozwala zaoszczędzić więcej niż kosztuje. Aby to zadziałało na korzyść szpuli, należy oszacować, że plan będzie zużywał rzędy ze szpuli więcej niż raz. W przeciwnym razie może równie dobrze pominąć szpulę i po prostu wykonać podstawową operację ten jeden raz.
- Aby uzyskać dostęp więcej niż jeden raz, spool musi pojawić się po wewnętrznej stronie operatora łączenia zagnieżdżonych pętli.
- Każda iteracja pętli powinna dążyć do określonej wartości klucza buforowania indeksu dostarczonej przez zewnętrzną stronę pętli.
Oznacza to, że dołączenie musi być zastosowaniem , a nie połączenia zagnieżdżonych pętli . Aby dowiedzieć się, jaka jest różnica między tymi dwoma, zobacz mój artykuł Zastosuj a łączenie zagnieżdżonych pętli.
Wybitne funkcje
Podczas gdy gorliwa buforowanie indeksu może pojawić się tylko po wewnętrznej stronie zagnieżdżonych pętli zastosuj , nie jest to „szpula wydajności”. Nie można wyłączyć szybkiego buforowania indeksu za pomocą flagi śledzenia 8690 lub NO_PERFORMANCE_SPOOL wskazówka zapytania.
Wiersze wstawiane do buforu indeksu nie są zwykle wstępnie sortowane według kolejności kluczy indeksu, co może skutkować podziałami stron indeksu. Nieudokumentowana flaga śledzenia 9260 może zostać użyta do wygenerowania Sortowania operatora przed buforem indeksu, aby tego uniknąć. Minusem jest to, że dodatkowy koszt sortowania może w ogóle zniechęcić optymalizatora do wyboru opcji buforowania.
SQL Server nie obsługuje wstawiania równoległego do indeksu b-drzewa. Oznacza to, że wszystko poniżej równoległego szybkiego buforowania indeksu działa w jednym wątku. Operatory pod szpulą są nadal (mylnie) oznaczone ikoną równoległości. Wybrano jeden wątek do pisania do szpuli. Inne wątki czekają na EXECSYNC dopóki to się kończy. Po zapełnieniu szpuli można ją odczytać z przez równoległe wątki.
Buforowanie indeksu nie informuje optymalizatora, że obsługuje dane wyjściowe uporządkowane według kluczy indeksu buforu. Jeśli posortowane dane wyjściowe ze szpuli są wymagane, możesz zobaczyć niepotrzebne Sortowanie operator. Chętne szpule indeksujące i tak powinny być często zastępowane stałym indeksem, więc przez większość czasu jest to niewielki problem.
Istnieje pięć reguł optymalizujących, które mogą generować Eager Index Spool opcja (znana wewnętrznie jako indeks w locie ). Przyjrzymy się trzem z nich szczegółowo, aby zrozumieć, skąd pochodzą chętne buforowanie indeksu.
SelToIndexOnTheFly
To jest najczęstszy. Dopasowuje jeden lub więcej wyborów relacyjnych (czyli filtrów lub predykatów) tuż nad operatorem dostępu do danych. SelToIndexOnTheFly reguła zastępuje predykaty predykatem seek na szybkim buforowaniu indeksu.
Demo
AdventureWorks przykładowa baza danych jest pokazana poniżej:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
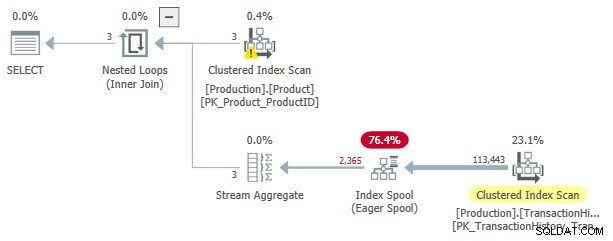
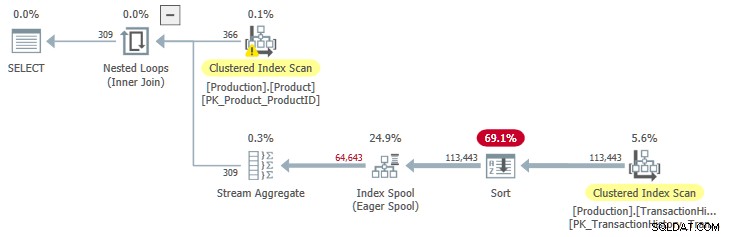
Ten plan wykonania ma szacunkowy koszt 3,0881 jednostki. Niektóre ciekawe miejsca:
- Łączenie wewnętrzne zagnieżdżonych pętli operator to zastosuj , z
ProductIDiSafetyStockLevelzProducttabela jako odniesienia zewnętrzne . - W pierwszej iteracji zastosowania Eager Index Bufor jest w pełni wypełniony z skanowania indeksu klastrowego
TransactionHistorystół. - Tabela robocza bufora ma indeks klastrowy z kluczem
(ProductID, Quantity). - Wiersze pasujące do predykatów
TH.ProductID = P.ProductIDiTH.Quantity < P.SafetyStockLevelsą odbierane przez szpulę za pomocą jej indeksu. Dotyczy to każdej iteracji zastosowania, łącznie z pierwszą. TransactionHistorytabela jest skanowana tylko raz.
Posortowane dane wejściowe do szpuli
Możliwe jest wymuszenie posortowanych danych wejściowych do szybkiego buforowania indeksu, ale ma to wpływ na szacowany koszt, jak wspomniano we wstępie. W powyższym przykładzie włączenie flagi śledzenia nieudokumentowanego tworzy plan bez buforowania:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
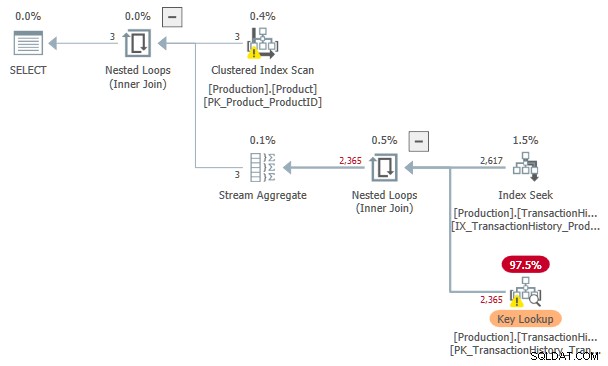
Szacunkowy koszt tego szukania indeksu i Wyszukiwanie kluczy plan to 3.11631 jednostki. To więcej niż koszt planu z samą szpulą indeksu, ale mniej niż plan z pulą indeksu i posortowanymi danymi wejściowymi.
Aby zobaczyć plan z posortowanymi danymi wejściowymi do szpuli, musimy zwiększyć oczekiwaną liczbę iteracji pętli. Daje to szpuli szansę na spłatę dodatkowego kosztu Sortowania . Jeden ze sposobów na zwiększenie liczby wierszy oczekiwanych od Product tabela ma na celu utworzenie Name orzeczenie mniej restrykcyjne:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); To daje nam plan wykonania z posortowanymi danymi wejściowymi do szpuli:
JoinToIndexOnTheFly
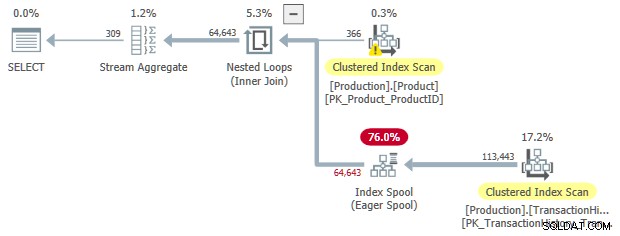
Ta reguła przekształca sprzężenie wewnętrzne do złóż wniosek , z chętną szpulą indeksującą po wewnętrznej stronie. Co najmniej jeden z predykatów złączenia musi być nierówny, aby ta reguła była dopasowana.
Jest to znacznie bardziej wyspecjalizowana reguła niż SelToIndexOnTheFly , ale idea jest bardzo podobna. W takim przypadku selekcja (predykat) przekształcana w wyszukiwanie do buforowania indeksu jest skojarzona z łączeniem. Transformacja z dołącz do zastosuj pozwala na przeniesienie predykatu złączenia z samego złączenia na wewnętrzną stronę zastosowania.
Demo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
Tak jak poprzednio, możemy zażądać posortowanych danych wejściowych do szpuli:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
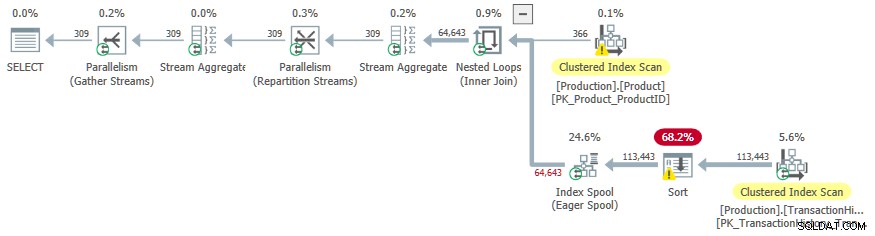
Tym razem dodatkowy koszt sortowania zachęcił optymalizatora do wybrania planu równoległego.
Niepożądanym efektem ubocznym jest sortowanie operator przelewa się do tempdb . Całkowity przydział pamięci dostępny do sortowania jest wystarczający, ale jest równomiernie dzielony między równoległe wątki (jak zwykle). Jak zauważono we wstępie, SQL Server nie obsługuje równoległych operacji wstawiania do indeksu b-drzewa, więc operatory pod gorącą szpulą indeksu działają w jednym wątku. Ten pojedynczy wątek otrzymuje tylko ułamek przyznanej pamięci, więc Sort przelewa się do tempdb .
Ten efekt uboczny jest prawdopodobnie jednym z powodów, dla których flaga śledzenia jest nieudokumentowana i nieobsługiwana.
SelSTVFToIdxOnFly
Ta reguła działa tak samo jak SelToIndexOnTheFly , ale dla strumieniowej funkcji z wartościami tabelarycznymi (sTVF) źródło wiersza. Te sTVF są szeroko stosowane wewnętrznie między innymi do wdrażania DMV i DMF. Pojawiają się w nowoczesnych planach wykonania jako Funkcja o wartościach tabeli operatorów (pierwotnie jako zdalne skanowanie tabeli ).
W przeszłości wiele z tych sTVF nie mogło akceptować skorelowanych parametrów z aplikacji. Mogli akceptować literały, zmienne i parametry modułów, ale nie stosować odniesienia zewnętrzne. W dokumentacji wciąż znajdują się ostrzeżenia na ten temat, ale są one teraz nieco nieaktualne.
W każdym razie chodzi o to, że czasami SQL Server nie może przekazać aplikacji odwołanie zewnętrzne jako parametr do sTVF. W takiej sytuacji sensowne może być zmaterializowanie części wyniku sTVF w chciwym buforowaniu indeksu. Obecna zasada zapewnia taką możliwość.
Demo
Następny przykład kodu pokazuje zapytanie DMV, które zostało pomyślnie przekonwertowane z sprzężenia na zastosuj . Odniesienia zewnętrzne są przekazywane jako parametry do drugiego DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
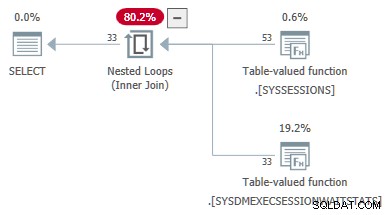
Właściwości planu statystyk oczekiwania TVF pokazują parametry wejściowe. Wartość drugiego parametru jest podana jako odniesienie zewnętrzne z sesji DMV:
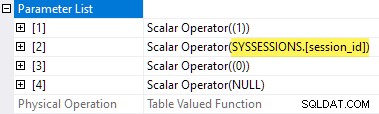
Szkoda, że sys.dm_exec_session_wait_stats jest widokiem, a nie funkcją, ponieważ uniemożliwia nam to napisanie apply bezpośrednio.
Poniższe przepisanie wystarczy, aby pokonać wewnętrzną konwersję:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Z session_id predykaty nie są teraz używane jako parametry, SelSTVFToIdxOnFly reguła może za darmo przekonwertować je na gorącą szpulę indeksu:
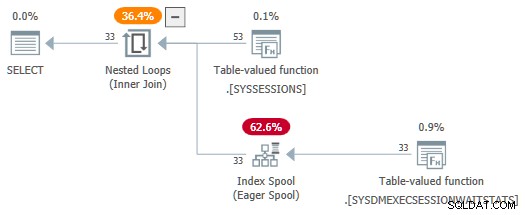
Nie chcę pozostawiać wrażenia, że potrzebne są skomplikowane przepisania, aby uzyskać gorącą szpulę indeksu nad źródłem DMV – to po prostu ułatwia demo. Jeśli zdarzy ci się napotkać zapytanie ze złączeniami DMV, które tworzy plan z szybkim buforowaniem, przynajmniej wiesz, jak to się tam znalazło.
Nie możesz tworzyć indeksów na DMV, więc może być konieczne użycie skrótu lub scalenia, jeśli plan wykonania nie działa wystarczająco dobrze.
Rekurencyjne CTE
Pozostałe dwie reguły to SelIterToIdxOnFly i JoinIterToIdxOnFly . Są bezpośrednimi odpowiednikami SelToIndexOnTheFly i JoinToIndexOnTheFly dla rekurencyjnych źródeł danych CTE. Z mojego doświadczenia wynika to niezwykle rzadko, więc nie zamierzam dostarczać dla nich dem. (Tak samo Iter część nazwy reguły ma sens:wynika z faktu, że SQL Server implementuje rekursję ogonową jako iterację zagnieżdżoną.)
Gdy rekurencyjne CTE jest wielokrotnie przywoływane wewnątrz zastosowania, inna reguła (SpoolOnIterator ) może buforować wynik CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Plan wykonania zawiera rzadką szpulę zliczania rzędów chętnych :
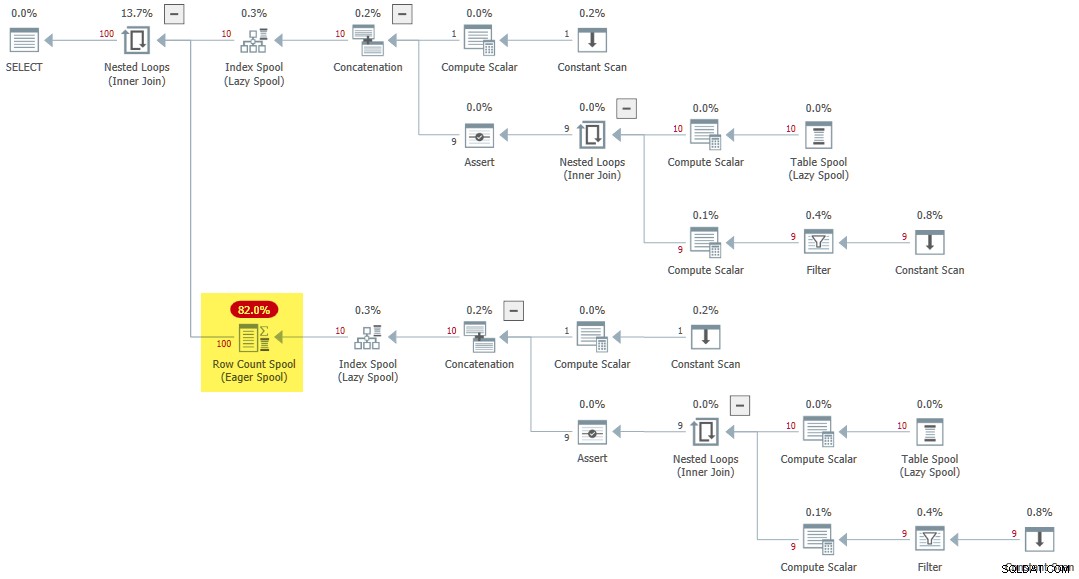
Końcowe myśli
Chętne bufory indeksów są często oznaką braku przydatnego stałego indeksu w schemacie bazy danych. Nie zawsze tak jest, jak pokazują przykłady funkcji z wartościami tabelarycznymi przesyłania strumieniowego.