Po blogowaniu o tym, jak filtrowane indeksy mogą być bardziej wydajne, a ostatnio o tym, jak można je uczynić bezużytecznymi przez wymuszoną parametryzację, wracam do tematu filtrowanych indeksów/parametryzacji. Pozornie zbyt proste rozwiązanie pojawiło się ostatnio w pracy i musiałem się podzielić.
Weźmy następujący przykład, gdzie mamy bazę danych sprzedaży zawierającą tabelę zamówień. Czasami potrzebujemy tylko listy (lub liczby) tylko zamówień, które nie zostały jeszcze wysłane — które z czasem (miejmy nadzieję!) stanowią coraz mniejszy procent całej tabeli:
CREATE DATABASE Sales;
GO
USE Sales;
GO
-- simplified, obviously:
CREATE TABLE dbo.Orders
(
OrderID int IDENTITY(1,1) PRIMARY KEY,
OrderDate datetime NOT NULL,
filler char(500) NOT NULL DEFAULT '',
IsShipped bit NOT NULL DEFAULT 0
);
GO
-- let's put some data in there; 7,000 shipped orders, and 50 unshipped:
INSERT dbo.Orders(OrderDate, IsShipped)
-- random dates over two years
SELECT TOP (7000) DATEADD(DAY, ABS(object_id % 730), '20171101'), 1
FROM sys.all_columns
UNION ALL
-- random dates from this month
SELECT TOP (50) DATEADD(DAY, ABS(object_id % 30), '20191201'), 0
FROM sys.all_columns; W tym scenariuszu sensowne może być utworzenie filtrowanego indeksu w ten sposób (co ułatwia pracę z dowolnymi zapytaniami, które próbują uzyskać w tych niewysłanych zamówieniach):
CREATE INDEX ix_OrdersNotShipped ON dbo.Orders(IsShipped, OrderDate) WHERE IsShipped = 0;
Możemy uruchomić szybkie zapytanie, takie jak to, aby zobaczyć, jak wykorzystuje filtrowany indeks:
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0;
Plan wykonania jest dość prosty, ale jest ostrzeżenie o UnmatchedIndexes:
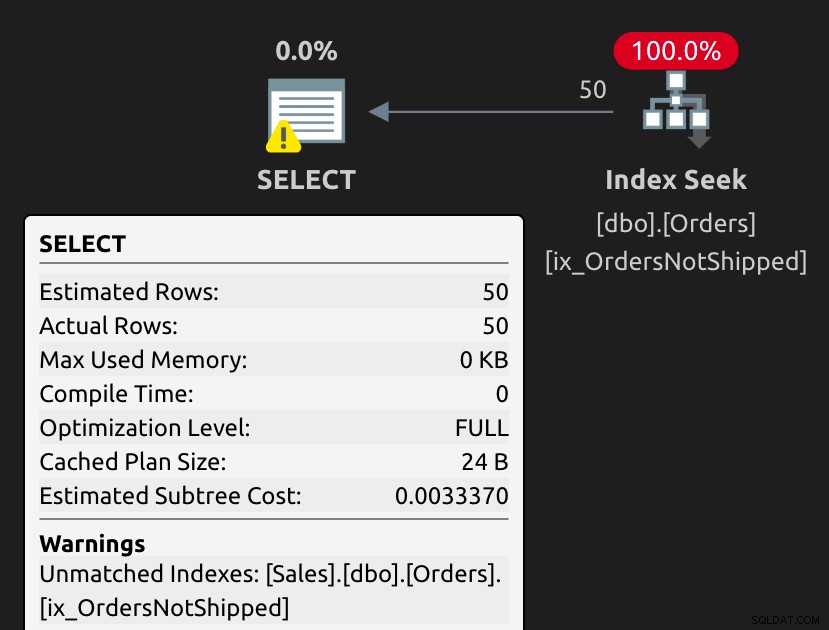
Nazwa ostrzeżenia jest nieco myląca — optymalizator mógł ostatecznie użyć indeksu, ale sugeruje, że byłoby „lepiej” bez parametrów (których wprost nie użyliśmy), mimo że oświadczenie wygląda tak, jakby było sparametryzowane:

Jeśli naprawdę chcesz, możesz wyeliminować ostrzeżenie, bez różnicy w rzeczywistej wydajności (byłoby to tylko kosmetyczne). Jednym ze sposobów jest dodanie predykatu o zerowym wpływie, takiego jak AND (1 > 0) :
SELECT wadd = OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 AND (1 > 0);
Innym (prawdopodobnie bardziej powszechnym) jest dodanie OPTION (RECOMPILE) :
SELECT wrecomp = OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 OPTION (RECOMPILE);
Obie te opcje dają ten sam plan (poszukiwanie bez ostrzeżeń):
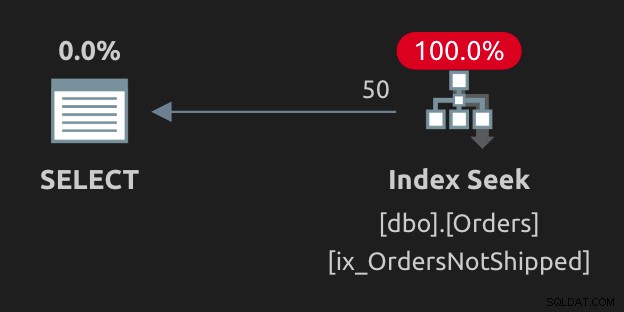
Jak na razie dobrze; nasz filtrowany indeks jest używany (zgodnie z oczekiwaniami). To oczywiście nie jedyne sztuczki; zobacz poniższe komentarze dla innych, które czytelnicy już przesłali.
W takim razie komplikacja
Ponieważ baza danych podlega dużej liczbie zapytań ad hoc, ktoś włącza wymuszoną parametryzację, próbując zmniejszyć kompilację i wyeliminować plany o niskim i jednorazowym użyciu z zaśmiecania pamięci podręcznej planów:
ALTER DATABASE Sales SET PARAMETERIZATION FORCED;
Teraz nasze oryginalne zapytanie nie może używać filtrowanego indeksu; jest zmuszony do skanowania indeksu klastrowego:
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0;
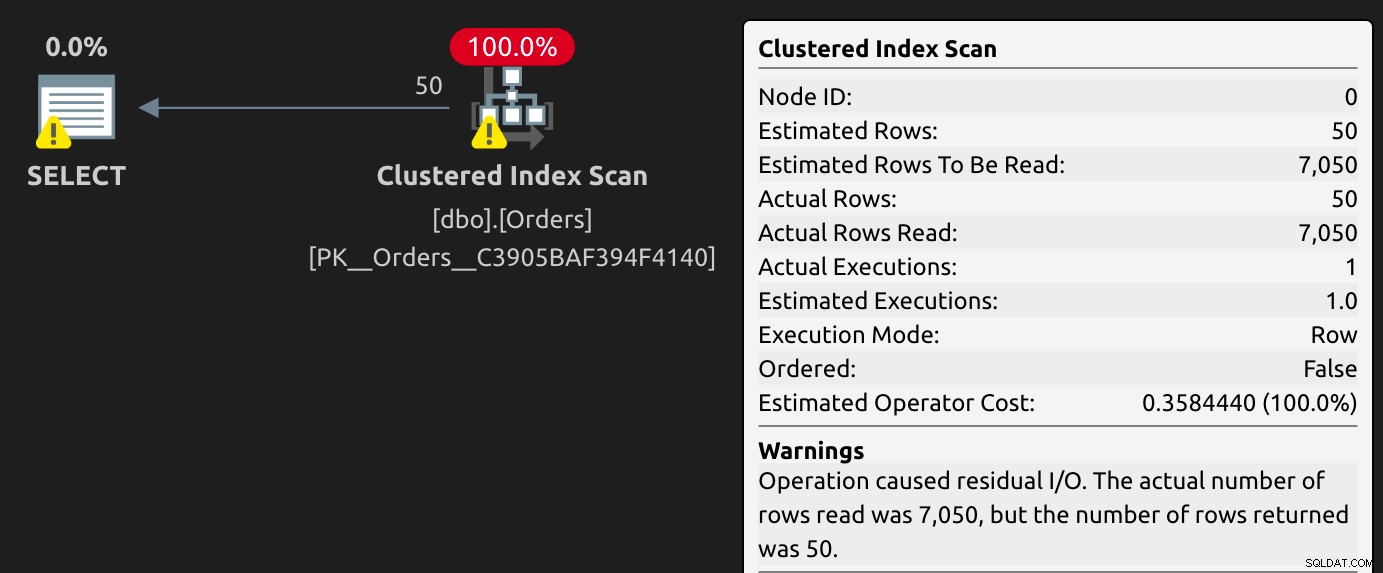
Powraca ostrzeżenie o niedopasowanych indeksach i otrzymujemy nowe ostrzeżenia o szczątkowych I/O. Zauważ, że instrukcja jest sparametryzowana, ale wygląda trochę inaczej:

Jest to zgodne z projektem, ponieważ jedynym celem wymuszonej parametryzacji jest parametryzacja zapytań takich jak ta. Ale jest to sprzeczne z celem naszego filtrowanego indeksu, ponieważ ma on wspierać pojedynczą wartość w predykacie, a nie parametr, który może się zmienić.
Wygłup
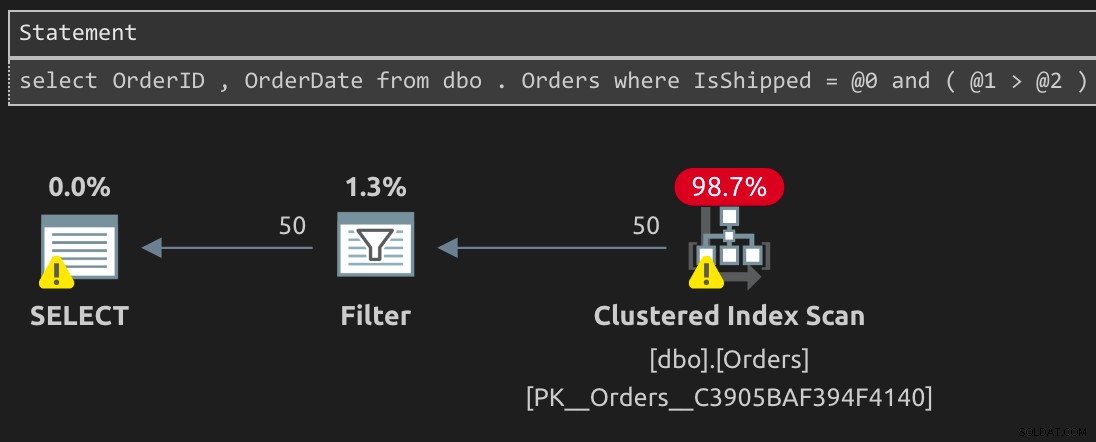
Nasze „podstępne” zapytanie, które używa dodatkowego predykatu, również nie może użyć filtrowanego indeksu i kończy się nieco bardziej skomplikowanym planem uruchamiania:
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 AND (1 > 0);
OPCJA (REKOMPILACJA)
Typową reakcją w tym przypadku, podobnie jak w przypadku wcześniejszego usunięcia ostrzeżenia, jest dodanie OPTION (RECOMPILE) do oświadczenia. To działa i pozwala wybrać filtrowany indeks w celu wydajnego wyszukiwania…
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 OPTION (RECOMPILE);
…ale dodając OPTION (RECOMPILE) i branie tego dodatkowego trafienia kompilacji na każde wykonanie zapytania nie zawsze będzie akceptowalne w środowiskach o dużym natężeniu ruchu (zwłaszcza jeśli są one już powiązane z procesorem).
Wskazówki
Ktoś zasugerował, aby wyraźnie zasugerować filtrowany indeks, aby uniknąć kosztów ponownej kompilacji. Ogólnie jest to dość kruche, ponieważ opiera się na indeksie, który przetrwał kod; Zwykle używam tego w ostateczności. W tym przypadku i tak jest nieważne. Gdy reguły parametryzacji uniemożliwiają optymalizatorowi automatyczne wybranie przefiltrowanego indeksu, uniemożliwiają również wybranie go ręcznie. Ten sam problem z ogólnym FORCESEEK wskazówka:
SELECT OrderID, OrderDate FROM dbo.Orders WITH (INDEX (ix_OrdersNotShipped)) WHERE IsShipped = 0; SELECT OrderID, OrderDate FROM dbo.Orders WITH (FORCESEEK) WHERE IsShipped = 0;
Oba powodują ten błąd:
Msg 8622, poziom 16, stan 1Procesor kwerend nie może utworzyć planu kwerendy z powodu wskazówek zdefiniowanych w tej kwerendzie. Ponownie prześlij zapytanie bez określania żadnych wskazówek i bez użycia SET FORCEPLAN.
A to ma sens, ponieważ nie ma sposobu, aby dowiedzieć się, że nieznana wartość dla IsShipped parametr będzie pasował do filtrowanego indeksu (lub będzie obsługiwał operację wyszukiwania na dowolnym indeksie).
Dynamiczny SQL?
Zasugerowałem, że możesz użyć dynamicznego SQL, aby przynajmniej zapłacić za trafienie rekompilacji tylko wtedy, gdy wiesz, że chcesz trafić na mniejszy indeks:
DECLARE @IsShipped bit = 0;
DECLARE @sql nvarchar(max) = N'SELECT dynsql = OrderID, OrderDate FROM dbo.Orders'
+ CASE WHEN @IsShipped IS NOT NULL THEN N' WHERE IsShipped = @IsShipped'
ELSE N'' END
+ CASE WHEN @IsShipped = 0 THEN N' OPTION (RECOMPILE)' ELSE N'' END;
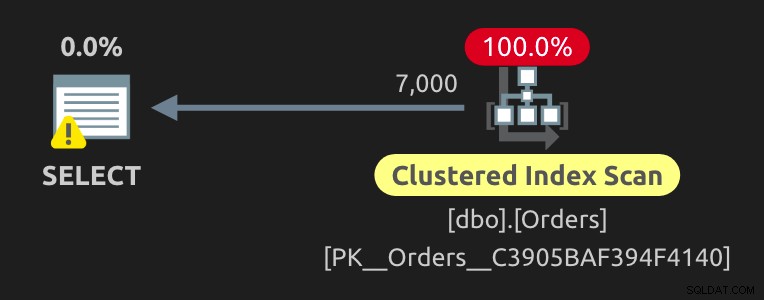
EXEC sys.sp_executesql @sql, N'@IsShipped bit', @IsShipped;
Prowadzi to do tego samego efektywnego planu, co powyżej. Jeśli zmieniłeś zmienną na @IsShipped = 1 , otrzymasz droższe skanowanie indeksu klastrowego, jakiego powinieneś się spodziewać:
Ale nikt nie lubi używać dynamicznego SQL w tak skrajnym przypadku — sprawia to, że kod jest trudniejszy do odczytania i utrzymania, a nawet gdyby ten kod znajdował się w aplikacji, nadal należałoby tam dodać dodatkową logikę, co czyni ją mniej niż pożądaną .
Coś prostszego
Rozmawialiśmy krótko o zaimplementowaniu przewodnika po planie, co z pewnością nie jest prostsze, ale potem kolega zasugerował, że można oszukać optymalizator, „ukrywając” sparametryzowaną instrukcję wewnątrz procedury składowanej, widoku lub wbudowanej funkcji z wartościami tabelarycznymi. To było tak proste, że nie wierzyłem, że to zadziała.
Ale potem spróbowałem:
CREATE PROCEDURE dbo.GetUnshippedOrders AS BEGIN SET NOCOUNT ON; SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0; END GO CREATE VIEW dbo.vUnshippedOrders AS SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0; GO CREATE FUNCTION dbo.fnUnshippedOrders() RETURNS TABLE AS RETURN (SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0); GO
Wszystkie trzy z tych zapytań wykonują efektywne wyszukiwanie według filtrowanego indeksu:
EXEC dbo.GetUnshippedOrders; GO SELECT OrderID, OrderDate FROM dbo.vUnshippedOrders; GO SELECT OrderID, OrderDate FROM dbo.fnUnshippedOrders();
Wniosek
Byłem zaskoczony, że to było tak skuteczne. Oczywiście wymaga to zmiany aplikacji; jeśli nie możesz zmienić kodu aplikacji, aby wywołać procedurę składowaną lub odwołać się do widoku lub funkcji (lub nawet dodać OPTION (RECOMPILE) ), będziesz musiał szukać innych opcji. Ale jeśli możesz zmienić kod aplikacji, umieszczenie predykatu w innym module może być po prostu dobrym rozwiązaniem.