W niedawnej wskazówce opisałem scenariusz, w którym instancja SQL Server 2016 wydawała się mieć problemy z czasami kontrolnymi. Dziennik błędów został wypełniony alarmującą liczbą wpisów FlushCache, takich jak ten:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Byłem trochę zakłopotany tym problemem, ponieważ system z pewnością nie był garbaty — mnóstwo rdzeni, 3 TB pamięci i pamięć XtremIO. I żaden z tych komunikatów FlushCache nigdy nie był sparowany z charakterystycznymi 15-sekundowymi ostrzeżeniami I/O w dzienniku błędów. Mimo to, jeśli umieścisz tam kilka baz danych o dużej liczbie transakcji, przetwarzanie w punktach kontrolnych może stać się dość powolne. Nie tyle z powodu bezpośredniego wejścia/wyjścia, ale więcej uzgodnień, które trzeba wykonać z ogromną liczbą brudnych stron (nie tylko z committed transakcji) rozproszonych po tak dużej ilości pamięci i potencjalnie oczekujących na lazywriter (ponieważ istnieje tylko jedna na całą instancję).
Zrobiłem szybkie „odświeżenie” kilku bardzo wartościowych postów:
- Jak działają punkty kontrolne i co jest rejestrowane
- Punkty kontrolne bazy danych (SQL Server)
- Co robi punkt kontrolny dla tempdb?
- Mit SQL Server DBA na co dzień:(15/30) punkt kontrolny zapisuje tylko strony z zatwierdzonych transakcji
- Wiadomości FlushCache mogą nie być rzeczywistym przestojem we/wy
- Pośredni punkt kontrolny i tempdb – dobry, zły i nieopłacalny harmonogram
- Zmień docelowy czas odzyskiwania bazy danych
- Jak to działa:Kiedy komunikat FlushCache jest dodawany do dziennika błędów programu SQL Server?
- Zmiany w zachowaniu SQL Server 2016 w punkcie kontrolnym
- Docelowy interwał odzyskiwania i pośredni punkt kontrolny — nowe domyślne ustawienie 60 sekund w SQL Server 2016
- SQL 2016 – po prostu działa szybciej:domyślny pośredni punkt kontrolny
- SQL Server:duże punkty kontrolne pamięci RAM i DB
Szybko zdecydowałem, że chcę śledzić czasy trwania punktów kontrolnych dla kilku z tych bardziej kłopotliwych baz danych, przed i po zmianie ich docelowego interwału odzyskiwania z 0 (stary sposób) na 60 sekund (nowy sposób). W styczniu pożyczyłem sesję Extended Events od przyjaciółki i koleżanki z Kanady Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Zaznaczyłem czas, w którym zmieniałem każdą bazę danych, a następnie analizowałem wyniki z danych Extended Events za pomocą zapytania opublikowanego w oryginalnej wskazówce. Wyniki pokazały, że po zmianie na pośrednie punkty kontrolne, każda baza danych przeszła z punktów kontrolnych średnio 30 sekund do punktów kontrolnych średnio mniej niż jedną dziesiątą sekundy (i znacznie mniej punktów kontrolnych w większości przypadków). Z tej grafiki jest co rozpakować, ale to są surowe dane, których użyłem do przedstawienia mojej argumentacji (kliknij, aby powiększyć):
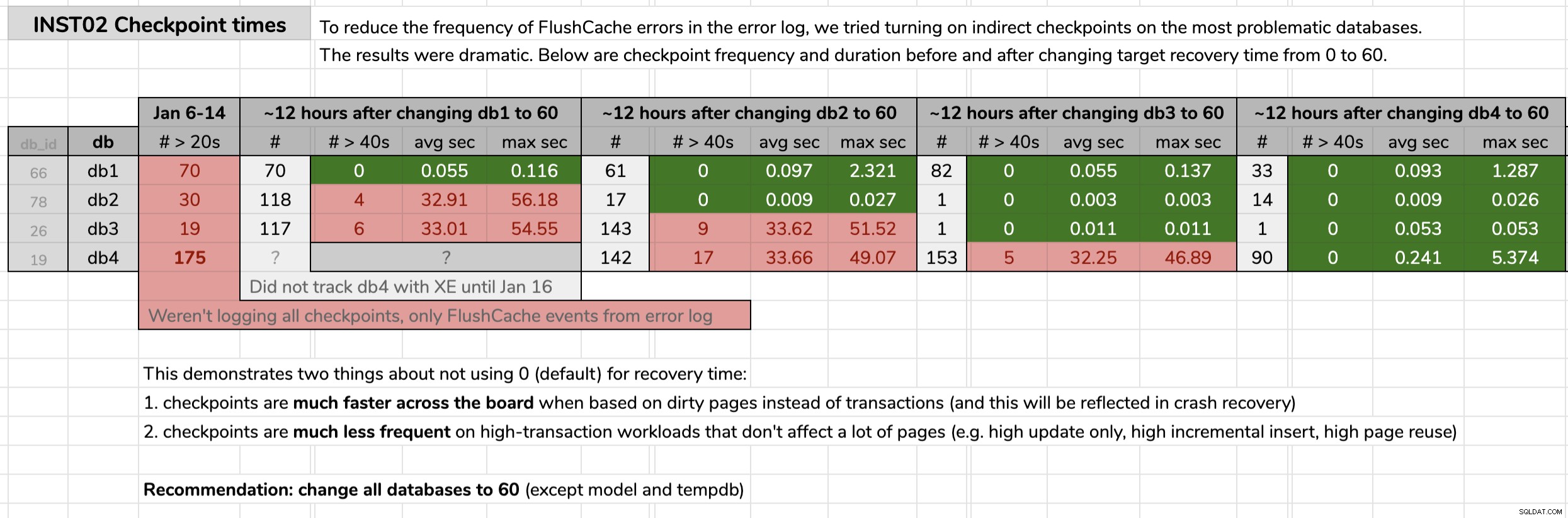 Moje dowody
Moje dowody
Kiedy udowodniłem swoją sprawę w tych problematycznych bazach danych, dostałem zielone światło, aby wdrożyć to we wszystkich naszych bazach danych użytkowników w naszym środowisku. Najpierw na etapie deweloperskim, a następnie produkcyjnym uruchomiłem następujące zapytanie za pomocą zapytania CMS, aby uzyskać wskaźnik dotyczący liczby baz danych, o których mówimy:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Kilka uwag na temat zapytania:
database_id > 4
Nie chciałem dotykaćmasterw ogóle i nie chciałem zmieniaćtempdbale ponieważ nie korzystamy z najnowszej CU programu SQL Server 2017 (zobacz KB #4497928 z jednego powodu, że szczegóły są ważne). Ta ostatnia wykluczamodel, ponieważ zmiana modelu wpłynęłaby natempdbprzy następnym przełączeniu awaryjnym / ponownym uruchomieniu. Mogłem zmienićmsdb, i być może w pewnym momencie do tego wrócę, ale skupiłem się tutaj na bazach danych użytkowników.
[state] / is_read_only / is_in_standby
Musimy upewnić się, że bazy danych, które próbujemy zmienić, są online, a nie tylko do odczytu (nacisnąłem tę, która była aktualnie ustawiona tylko do odczytu i będę musiał wrócić do niej później).
OUTER APPLY (...)
Chcemy ograniczyć nasze działania do baz danych, które są albo podstawowe w grupie AG, albo w ogóle nie są w grupie AG (a także muszą uwzględniać rozproszone grupy AG, w których możemy być podstawowymi i lokalnymi, ale nadal nie mamy możliwości zapisu) . Jeśli zdarzy ci się uruchomić sprawdzanie na dodatkowym, nie możesz tam naprawić problemu, ale nadal powinieneś otrzymać ostrzeżenie o tym. Dziękujemy Erikowi Darlingowi za pomoc w tej logice i Taylorowi Martellowi za motywowanie ulepszeń.
- Jeśli masz instancje ze starszymi wersjami, takimi jak SQL Server 2008 R2 (znalazłem jedną!), będziesz musiał to trochę poprawić, ponieważ
target_recovery_time_in_secondskolumna tam nie istnieje. W jednym przypadku musiałem użyć dynamicznego SQL, aby obejść ten problem, ale możesz także tymczasowo przenieść lub usunąć te instancje w hierarchii CMS. Nie możesz też być leniwym jak ja i uruchamiać kod w Powershell zamiast okna zapytań CMS, w którym możesz łatwo odfiltrować bazy danych o dowolnej liczbie właściwości, zanim napotkasz problemy z kompilacją.
W środowisku produkcyjnym były 102 instancje (około połowa) i łącznie 1590 baz danych przy użyciu starego ustawienia. Wszystko było na SQL Server 2017, więc dlaczego to ustawienie było tak powszechne? Ponieważ zostały utworzone, zanim pośrednie punkty kontrolne stały się domyślnymi w SQL Server 2016. Oto próbka wyników:
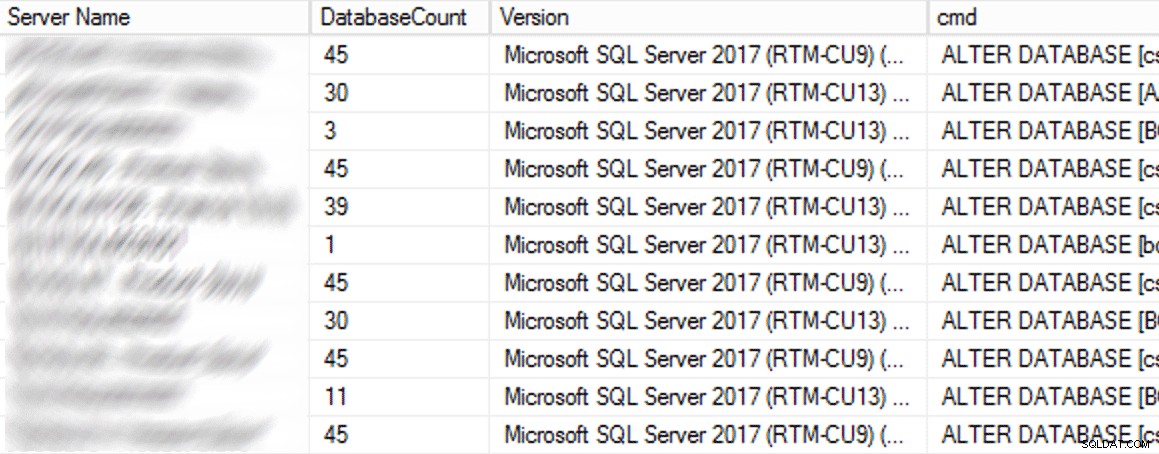 Częściowe wyniki zapytania CMS.
Częściowe wyniki zapytania CMS.
Następnie ponownie uruchomiłem zapytanie CMS, tym razem z sys.sp_executesql nieskomentowane. Uruchomienie tego we wszystkich 1590 bazach danych zajęło około 12 minut. W ciągu godziny otrzymywałem już raporty o ludziach obserwujących znaczny spadek procesora w niektórych bardziej ruchliwych instancjach.
Mam jeszcze więcej do zrobienia. Na przykład muszę przetestować potencjalny wpływ na tempdb i czy w naszym przypadku użycia jest jakaś waga dla opowieści grozy, które słyszałem. Musimy się upewnić, że ustawienie 60 sekund jest częścią naszej automatyzacji i wszystkich żądań utworzenia bazy danych, zwłaszcza tych, które są oskryptowane lub przywracane z kopii zapasowych.