W pierwszej części tego bloga przedstawiłem kilka wyników benchmarków pokazujących, jak zmieniła się wydajność PostgreSQL OLTP od wersji 8.3, wydanej w 2008 roku. W tej części planuję zrobić to samo, ale dla zapytań analitycznych / BI, przetwarzając duże ilości danych.
Istnieje wiele branżowych testów porównawczych do testowania tego obciążenia, ale prawdopodobnie najczęściej używanym jest TPC-H, więc tego użyję w tym poście na blogu. Istnieje również TPC-DS, kolejny benchmark TPC do testowania systemów wspomagania decyzji, który może być postrzegany jako ewolucja lub zamiennik TPC-H. Postanowiłem trzymać się TPC-H z kilku powodów.
Po pierwsze, TPC-DS jest znacznie bardziej złożony, zarówno pod względem schematu (więcej tabel), jak i liczby zapytań (22 vs. 99). Odpowiednie dostrojenie, szczególnie gdy mamy do czynienia z wieloma wersjami PostgreSQL, byłoby znacznie trudniejsze. Po drugie, niektóre zapytania TPC-DS wykorzystują funkcje, które nie są obsługiwane przez starsze wersje PostgreSQL (np. grupowanie zbiorów), przez co zapytania te nie mają znaczenia dla niektórych wersji. I na koniec powiedziałbym, że ludzie są znacznie bardziej zaznajomieni z TPC-H w porównaniu z TPC-DS.
Celem tego nie jest umożliwienie porównania z innymi produktami bazodanowymi, a jedynie zapewnienie rozsądnej długoterminowej charakterystyki ewolucji wydajności PostgreSQL od czasu PostgreSQL 8.3.
Uwaga :Aby uzyskać bardzo interesującą analizę benchmarku TPC-H, gorąco polecam artykuł „Analizy TPC-H:ukryte wiadomości i wnioski wyciągnięte z wpływowego testu porównawczego” autorstwa Boncza, Neumanna i Erlinga.
Sprzęt
Większość wyników w tym poście na blogu pochodzi z „większego pudełka”, które mam w naszym biurze, które ma następujące parametry:
- 2x E5-2620 v4 (16 rdzeni, 32 wątki)
- 64 GB pamięci RAM
- Intel Optane 900P 280 GB NVMe SSD (dane)
- 3 x 7,2 tys. SATA RAID0 (tymczasowy obszar tabel)
- jądro 5.6.15, system plików ext4
Jestem pewien, że można kupić znacznie mocniejsze maszyny, ale uważam, że jest to wystarczająco dobre, aby dostarczyć nam odpowiednich danych. Istniały dwa warianty konfiguracji – jeden z wyłączoną równoległością, drugi z włączoną równoległością. Większość wartości parametrów jest taka sama w obu przypadkach, dostosowana do dostępnych zasobów sprzętowych (procesor, pamięć RAM, pamięć masowa). Bardziej szczegółowe informacje o konfiguracji znajdziesz na końcu tego posta.
Wzorzec
Chcę jasno powiedzieć, że nie jest moim celem wdrożenie prawidłowego testu porównawczego TPC-H, który mógłby spełnić wszystkie kryteria wymagane przez TPC. Moim celem jest ocena, w jaki sposób wydajność różnych zapytań analitycznych zmieniała się w czasie, a nie ściganie jakiejś abstrakcyjnej miary wydajności na dolara lub coś w tym rodzaju.
Postanowiłem więc użyć tylko podzbioru TPC-H – zasadniczo po prostu załaduj dane i uruchom 22 zapytania (te same parametry we wszystkich wersjach). Brak odświeżania danych, zestaw danych jest statyczny po początkowym załadowaniu. Wybrałem kilka współczynników skali, 1, 10 i 75, aby uzyskać wyniki dla dopasowań do współdzielonych buforów (1), dopasowań do pamięci (10) i więcej niż w pamięci (75) . Wybrałbym 100, aby była to „ładna sekwencja”, która w niektórych przypadkach nie zmieściłaby się w pamięci 280 GB (dzięki indeksom, plikom tymczasowym itp.). Zwróć uwagę, że współczynnik skali 75 nie jest nawet rozpoznawany przez TPC-H jako prawidłowy współczynnik skali.
Ale czy w ogóle ma sens porównywanie zestawów danych 1 GB lub 10 GB? Ludzie zwykle skupiają się na znacznie większych bazach danych, więc zawracanie sobie głowy ich testowaniem może wydawać się nieco głupie. Ale nie sądzę, że byłoby to przydatne – większość baz danych w środowisku naturalnym jest dość mała, z mojego doświadczenia. Nawet gdy cała baza danych jest duża, ludzie zwykle pracują tylko z niewielkim jej podzbiorem nierozwiązane zamówienia itp. Uważam więc, że warto testować nawet z tymi małymi zestawami danych.
Ładowanie danych
Najpierw zobaczmy, jak długo trwa ładowanie danych do bazy danych – bez i z równoległością. Pokażę tylko wyniki z zestawu danych 75 GB, ponieważ ogólne zachowanie jest prawie takie samo w mniejszych przypadkach.
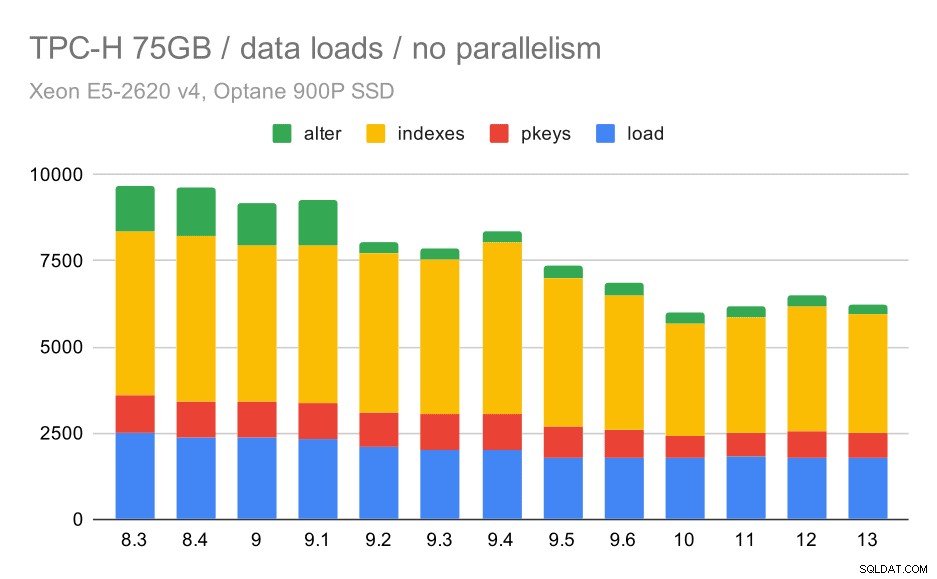
Czas ładowania danych TPC-H – skala 75 GB, brak równoległości
Widać wyraźnie, że istnieje stały trend ulepszeń, skracając około 30% czasu trwania jedynie poprzez poprawę wydajności we wszystkich czterech krokach – KOPIOWANIE, tworzenie kluczy podstawowych i indeksów oraz (zwłaszcza) konfigurowanie kluczy obcych. Poprawa „zmiany” w wersji 9.2 jest szczególnie wyraźna.
| KOPIUJ | PKEYS | INDEKSY | ZMIEŃ | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9,5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Zobaczmy teraz, jak włączenie równoległości zmienia zachowanie. Poniższy wykres porównuje wyniki z włączoną równoległością – oznaczonymi „(p)” – z wynikami z wyłączoną równoległością.
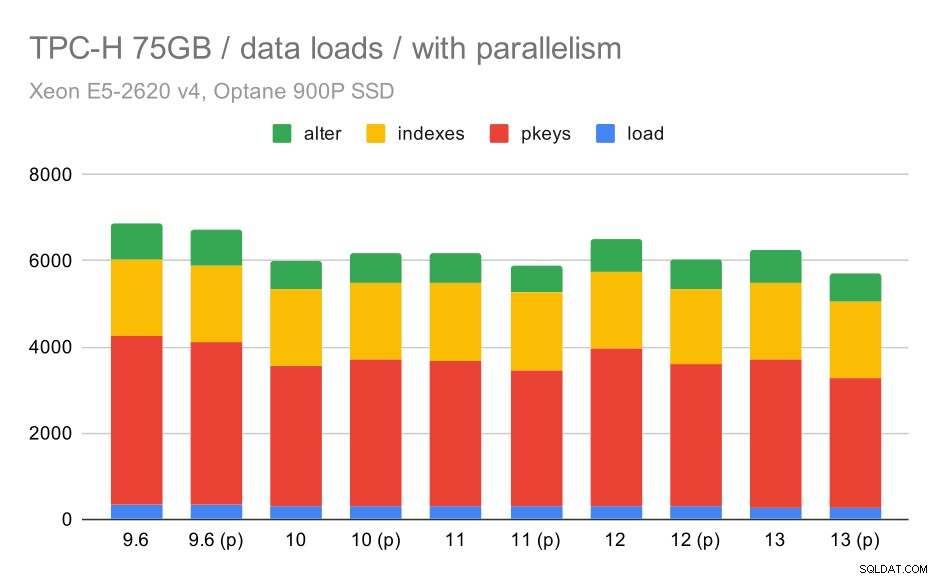
Czas ładowania danych TPC-H – skala 75 GB, włączona równoległość.
Niestety, wydaje się, że efekt paralelizmu jest w tym teście bardzo ograniczony – trochę pomaga, ale różnice są dość niewielkie. Więc ogólna poprawa pozostaje około 30%.
| KOPIUJ | PKEYS | INDEKSY | ZMIEŃ | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Zapytania
Teraz możemy przyjrzeć się zapytaniom. TPC-H ma 22 szablony zapytań – wygenerowałem jeden zestaw rzeczywistych zapytań i uruchomiłem je na wszystkich wersjach dwukrotnie – najpierw po porzuceniu wszystkich pamięci podręcznych i ponownym uruchomieniu instancji, a następnie z rozgrzaną pamięcią podręczną. Wszystkie liczby przedstawione na wykresach są najlepszymi z tych dwóch przebiegów (w większości przypadków jest to oczywiście druga).
Brak równoległości
Bez równoległości wyniki na najmniejszym zestawie danych są dość jasne – każdy słupek jest podzielony na wiele części o różnych kolorach dla każdego z 22 zapytań. Trudno powiedzieć, która część odwzorowuje konkretne zapytanie, ale wystarczy to do zidentyfikowania przypadków, w których jedno zapytanie poprawia się lub znacznie gorzej między dwoma uruchomieniami. Na przykład na pierwszym wykresie jest bardzo jasne, że Q21 stało się znacznie szybsze między 8,3 a 8,4.
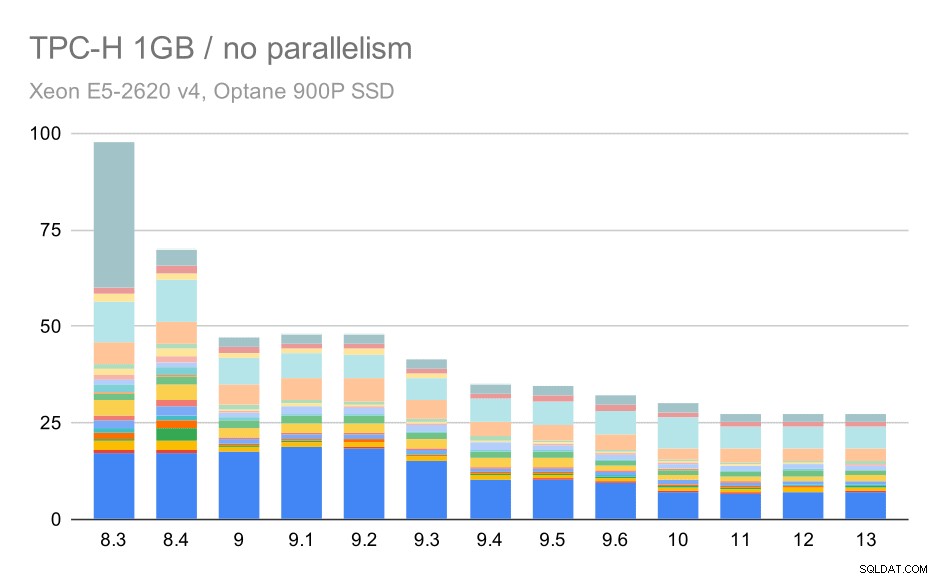
Zapytania TPC-H na małym zbiorze danych (1GB) – równoległość wyłączona
W przypadku skali 10 GB wyniki są nieco trudne do zinterpretowania, ponieważ w przypadku wersji 8.3 wykonanie jednego z zapytań (Q21) zajmuje tyle czasu, że przyćmiewa wszystko inne.
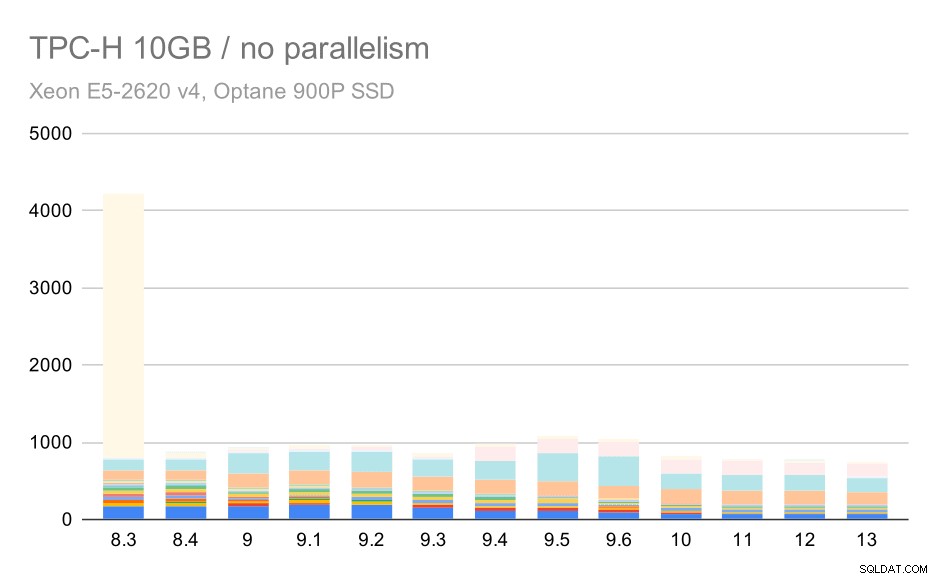
Zapytania TPC-H na średnim zestawie danych (10 GB) – równoległość wyłączona
Zobaczmy więc, jak wyglądałby wykres bez Q21:
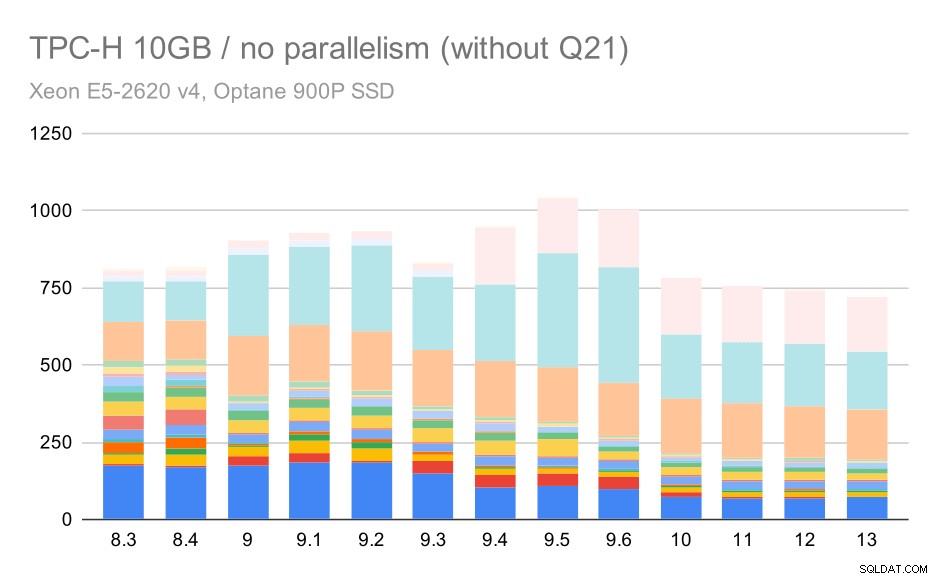
Zapytania TPC-H na średnim zestawie danych (10GB) – równoległość wyłączona, bez problematycznych Q2
OK, to jest łatwiejsze do odczytania. Widać wyraźnie, że większość zapytań (do 17. kw.) przyspieszyła, ale potem dwa zapytania (kw. 18 i 20) nieco wolniej. Podobny problem zobaczymy w największym zestawie danych, więc omówię, co może być wtedy główną przyczyną.
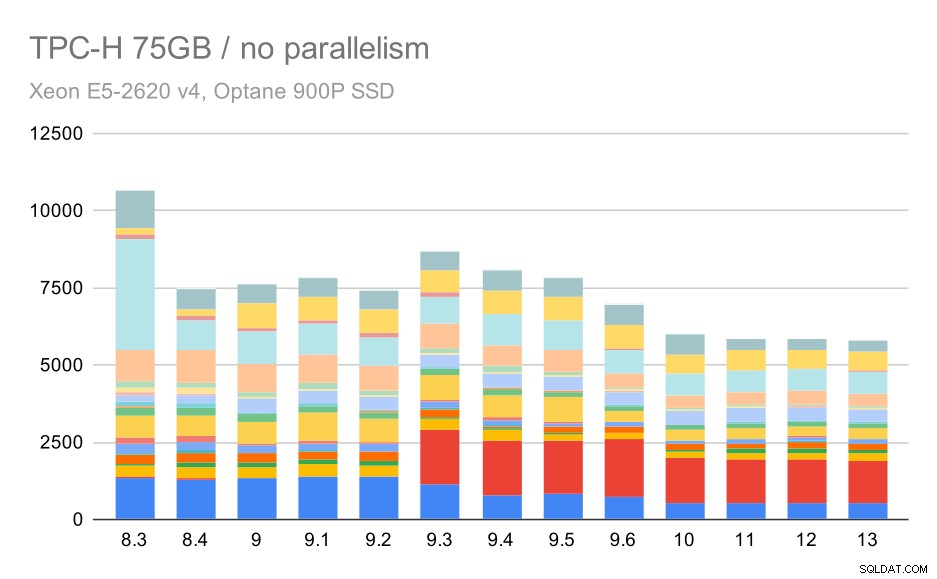
Zapytania TPC-H na dużym zbiorze danych (75 GB) – równoległość wyłączona
Ponownie widzimy nagły wzrost dla jednego z zapytań w 9.3 – tym razem jest to Q2, bez którego wykres wygląda tak:
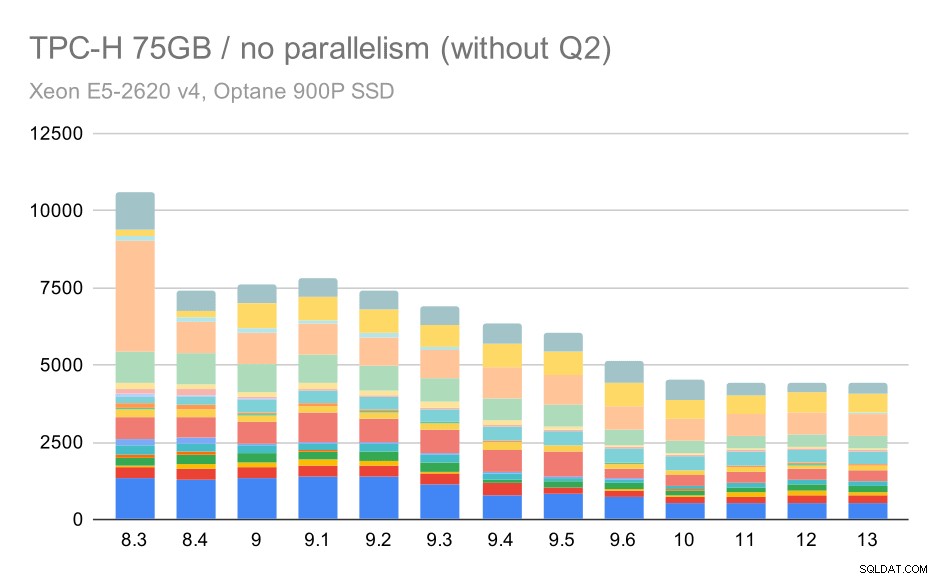
Zapytania TPC-H na dużym zbiorze danych (75 GB) – równoległość wyłączona, bez problematycznych Q2
Ogólnie rzecz biorąc, jest to całkiem niezłe ulepszenie, przyspieszając całe wykonanie z ~2,7 godziny do tylko ~1,2 godz., po prostu przez uczynienie planera i optymalizator bardziej inteligentnym oraz przez zwiększenie wydajności executora (pamiętaj, że równoległość była wyłączona w tych uruchomieniach) .
Więc jaki może być problem z Q2, spowalniając go w wersji 9.3? Prosta odpowiedź jest taka, że za każdym razem, gdy robisz planer i optymalizator mądrzejszy – albo konstruując nowe typy ścieżek/planów, albo uzależniając je od niektórych statystyk, oznacza to również, że mogą zostać popełnione nowe błędy, gdy statystyki lub szacunki są błędne. W drugim kwartale klauzula WHERE odwołuje się do podzapytania agregującego – uproszczona wersja zapytania może wyglądać tak:
Wybierz 1 od częściupphere Ps_Supplycost =(Wybierz min (PS_Supplycost) z częścipp, dostawca, naród, region, w którym p_partkey =ps_partkey i s_suppkey =ps_suppkey i s_nalikey =n_nationkey i n_regionkey =r_regionkey i r_name ='AmerykaProblem polega na tym, że nie znamy wartości średniej w czasie planowania, co uniemożliwia obliczenie wystarczająco dobrych szacunków dla warunku WHERE. Rzeczywisty II kwartał zawiera dodatkowe złączenia, a ich zaplanowanie zasadniczo zależy od dobrych szacunków łączonych relacji. Wydaje się, że w starszych wersjach optymalizator działał właściwie, ale w wersji 9.3 uczyniliśmy go w jakiś sposób mądrzejszym, ale przy kiepskich szacunkach nie podejmuje właściwej decyzji. Innymi słowy, dobre plany w starszych wersjach były po prostu szczęściem, dzięki ograniczeniom planisty.
Założę się, że regresje Q18 i Q20 na mniejszym zestawie danych są również spowodowane czymś podobnym, chociaż nie badałem ich szczegółowo.
Uważam, że niektóre z tych problemów z optymalizatorami można naprawić, dostosowując parametry kosztów (np. random_page_cost itp.), ale nie próbowałem tego ze względu na ograniczenia czasowe. Pokazuje jednak, że aktualizacje nie poprawiają automatycznie wszystkich zapytań – czasami aktualizacja może wywołać regresję, więc dobrym pomysłem jest odpowiednie przetestowanie aplikacji.
Równoległość
Zobaczmy więc, jak bardzo równoległość zapytań zmienia wyniki. Ponownie, przyjrzymy się tylko wynikom z wydań od wersji 9.6, oznaczając wyniki za pomocą „(p)”, gdzie zapytania równoległe są włączone.
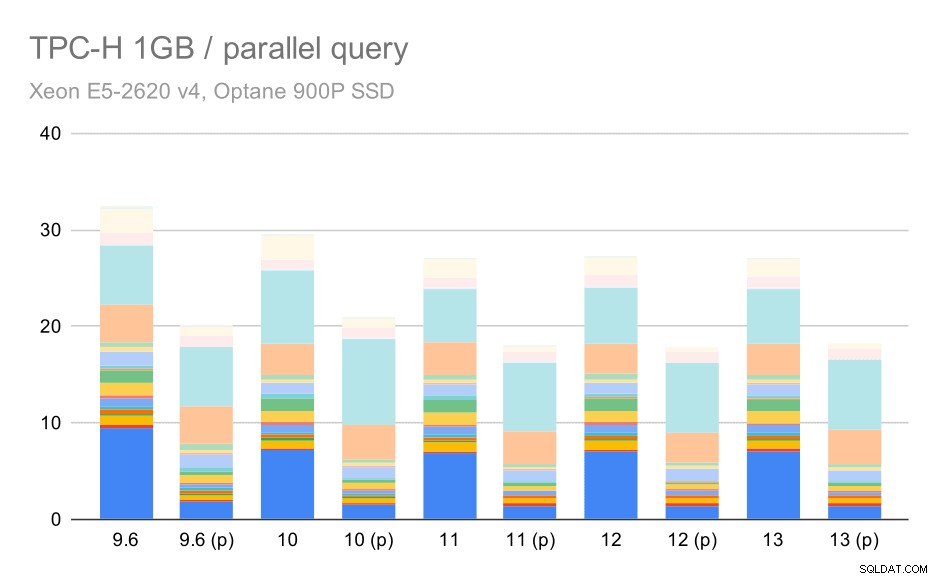
Zapytania TPC-H na małym zbiorze danych (1GB) – włączony równoległość
Oczywiście paralelizm pomaga całkiem sporo – goli o około 30% nawet na tym małym zestawie danych. Na średnim zestawie danych nie ma dużej różnicy między przebiegami zwykłymi i równoległymi:
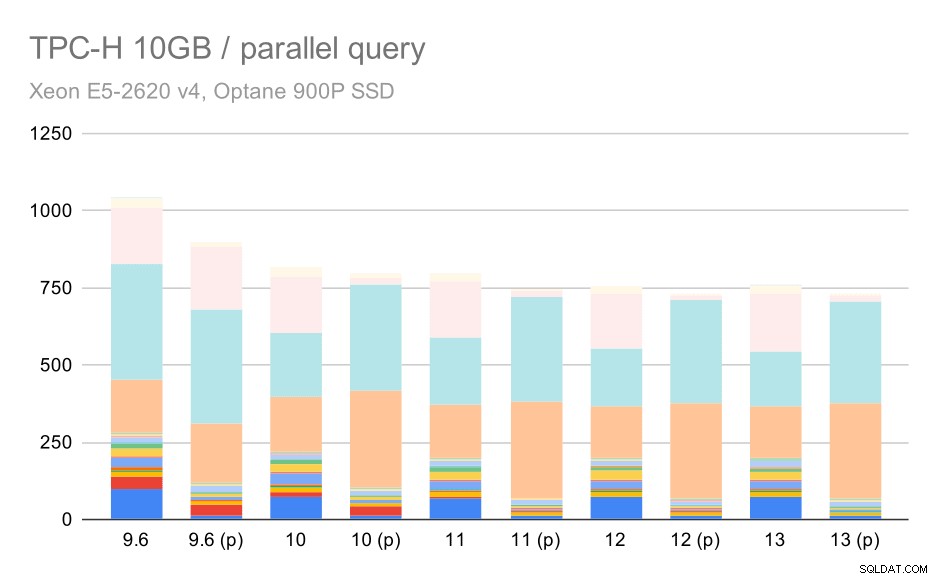
Zapytania TPC-H na średnim zestawie danych (10 GB) – włączony równoległość
To kolejna demonstracja omawianego już problemu – włączenie równoległości pozwala na rozważenie dodatkowych planów zapytań, a szacunkowe lub kosztorysowanie wyraźnie nie odpowiada rzeczywistości, co skutkuje słabymi wyborami planów.
I wreszcie duży zestaw danych, gdzie pełne wyniki wyglądają tak:
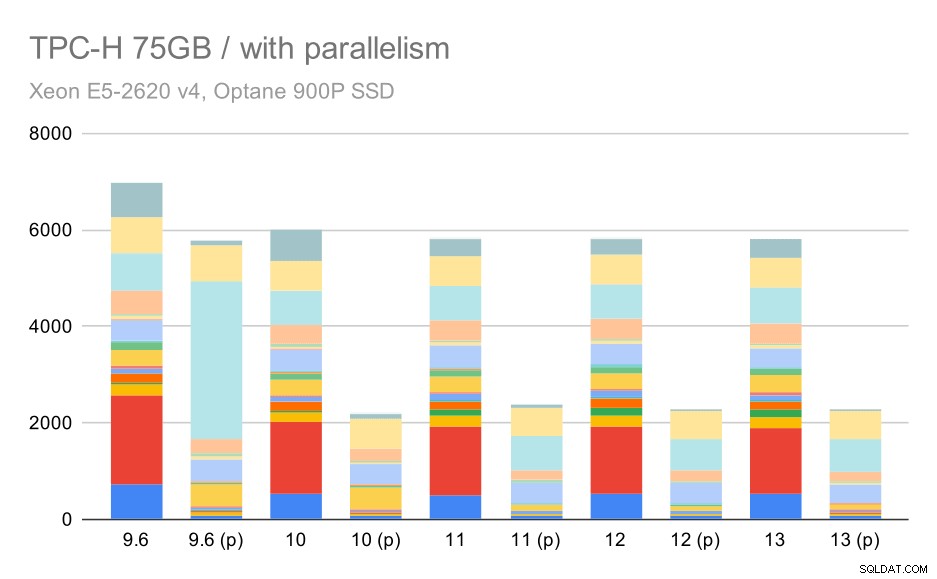
Zapytania TPC-H na dużym zbiorze danych (75 GB) – włączony równoległość
Tutaj włączenie równoległości działa na naszą korzyść – optymalizatorowi udaje się zbudować tańszy plan równoległy dla Q2, zastępując kiepski wybór planu wprowadzony w 9.3. Ale tylko dla kompletności, oto wyniki bez Q2.
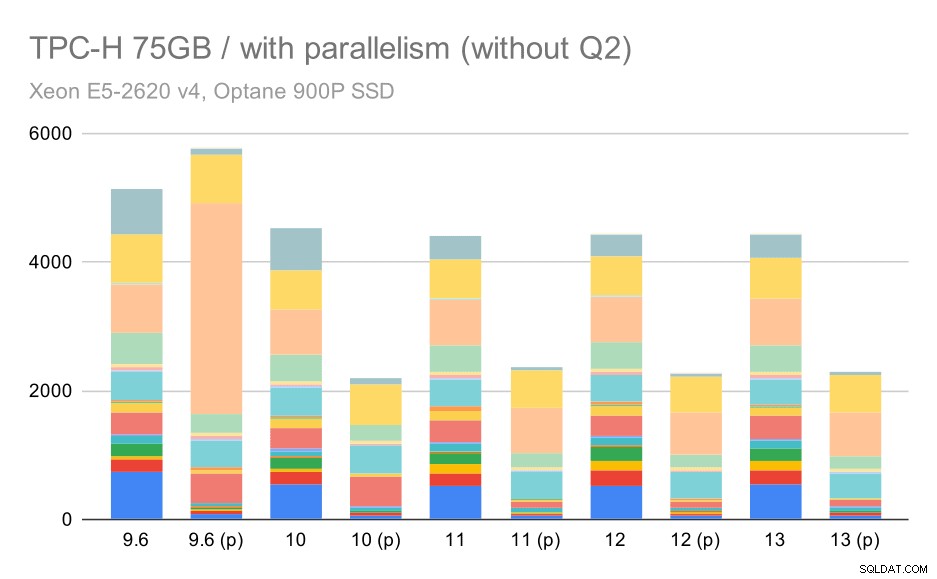
Zapytania TPC-H na dużym zbiorze danych (75 GB) – włączony równoległość, bez problematycznych Q2
Nawet tutaj można zauważyć słabe wybory planów równoległych – na przykład plan równoległy dla Q9 jest gorszy do 11, gdzie robi się szybszy – prawdopodobnie dzięki 11 obsługującym dodatkowe równoległe węzły wykonawcze. Z drugiej strony niektóre równoległe zapytania (Q18, Q20) stają się wolniejsze na 11, więc to nie tylko tęcze i jednorożce.
Podsumowanie i przyszłość
Myślę, że te wyniki dobrze pokazują, jakie optymalizacje są wdrażane od czasu PostgreSQL 8.3. Testy z wyłączoną równoległością ilustrują poprawę wydajności (tj. robienie więcej przy tej samej ilości zasobów) – ładowanie danych było ~30% szybsze, a zapytania ~2x szybsze. To prawda, że napotkałem pewne problemy z nieefektywnymi planami zapytań, ale jest to nieodłączne ryzyko, gdy planer zapytań staje się inteligentniejszy. Nieustannie pracujemy nad tym, aby wyniki były bardziej wiarygodne i jestem pewien, że mógłbym złagodzić większość tych problemów, nieco dostosowując konfigurację.
Wyniki z włączoną równoległością pokazują, że możemy efektywnie wykorzystać dodatkowe zasoby (w szczególności rdzenie CPU). Ładunki danych nie wydają się na tym zbytnio korzystać – przynajmniej nie w tym teście, ale wpływ na wykonywanie zapytań jest znaczny, co skutkuje ~2x przyspieszeniem (chociaż oczywiście różnie wpływa to na różne zapytania).
Istnieje wiele możliwości ulepszenia tego w przyszłych wersjach PostgreSQL. Na przykład istnieje seria poprawek implementująca równoległość dla COPY, przyspieszająca ładowanie danych. Istnieją różne łatki usprawniające wykonywanie zapytań analitycznych – od małych zlokalizowanych optymalizacji po duże projekty, takie jak przechowywanie i wykonywanie kolumnowe, agregacja push-down itp. Wiele można zyskać również stosując partycjonowanie deklaratywne – funkcja, którą w większości ignorowałem podczas pracy nad tym benchmark, po prostu dlatego, że zbytnio zwiększyłby zakres. Jestem pewien, że istnieje wiele innych możliwości, których nawet nie mogę sobie wyobrazić, ale mądrzejsi ludzie w społeczności PostgreSQL już nad nimi pracują.
Dodatek:Konfiguracja PostgreSQL
Równoległość wyłączona
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0#optimrdefault_statistics_target =1000random_page_cost =60efektywny_rozmiar_cache =32GB
Włączona równoległość
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32#optimrdefault_statistics_target =1000random_page_cost =60efektywna_cache_size =32GB