Jest to czwarta część serii poświęconej rozwiązaniom wyzwania generatora szeregów liczbowych. Wielkie podziękowania dla Alana Bursteina, Joe Obbisha, Adama Machanica, Christophera Forda, Jeffa Modena, Charliego, NoamGr, Kamila Kosno, Dave'a Masona, Johna Nelsona #2, Eda Wagnera, Michaela Burbea i Paula White'a za podzielenie się swoimi pomysłami i komentarzami.
Uwielbiam prace Paula White'a. Ciągle jestem zszokowana jego odkryciami i zastanawiam się, jak u licha domyśla się, co robi. Uwielbiam też jego sprawny i elokwentny styl pisania. Często, czytając jego artykuły lub posty, kręcę głową i mówię mojej żonie Lilach, że kiedy dorosnę, chcę być taki jak Paul.
Kiedy pierwotnie opublikowałem wyzwanie, miałem potajemną nadzieję, że Paul opublikuje rozwiązanie. Wiedziałem, że jeśli to zrobi, będzie to bardzo wyjątkowe wydarzenie. Cóż, zrobił i to fascynujące! Ma doskonałą wydajność i można się z niego wiele nauczyć. Ten artykuł jest poświęcony rozwiązaniu Paula.
Przeprowadzę testy w tempdb, włączając statystyki we/wy i czasu:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Ograniczenia wcześniejszych pomysłów
Oceniając wcześniejsze rozwiązania, jednym z ważnych czynników uzyskania dobrej wydajności była możliwość zastosowania przetwarzania wsadowego. Ale czy wykorzystaliśmy to w maksymalnym możliwym stopniu?
Przyjrzyjmy się planom dwóch wcześniejszych rozwiązań, które wykorzystywały przetwarzanie wsadowe. W części 1 omówiłem funkcję dbo.GetNumsAlanCharlieItzikBatch, która łączyła pomysły Alana, Charliego i mnie.
Oto definicja funkcji:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO To rozwiązanie definiuje podstawowy konstruktor wartości tabeli z 16 wierszami oraz serię kaskadowych CTE z połączeniami krzyżowymi w celu zwiększenia liczby wierszy do potencjalnie 4B. Rozwiązanie wykorzystuje funkcję ROW_NUMBER do utworzenia podstawowej sekwencji liczb w CTE o nazwie Nums oraz filtr TOP do filtrowania żądanej liczności serii liczb. Aby umożliwić przetwarzanie wsadowe, rozwiązanie używa fikcyjnego sprzężenia lewego z fałszywym warunkiem między CTE Nums a tabelą o nazwie dbo.BatchMe, która ma indeks magazynu kolumn.
Użyj poniższego kodu, aby przetestować funkcję za pomocą techniki przypisywania zmiennych:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
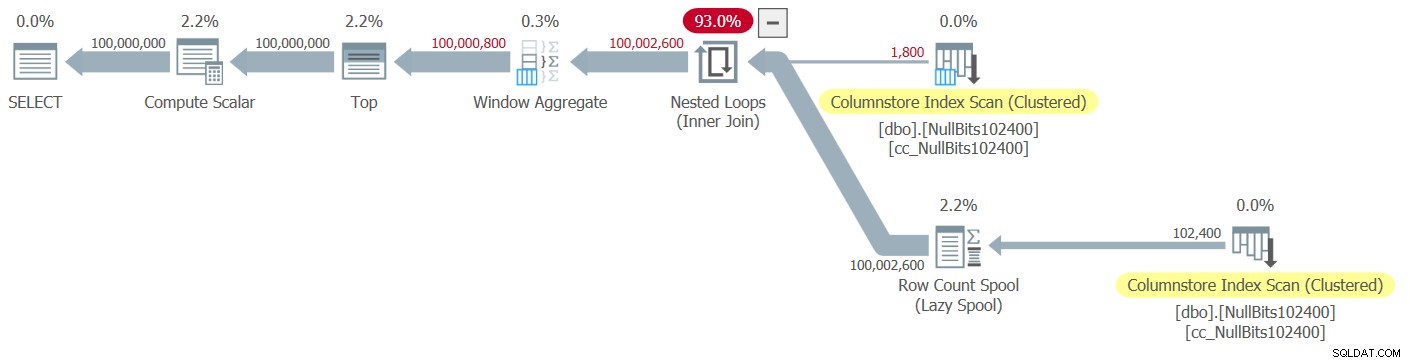
Eksplorator planów przedstawia rzeczywistą plan tego wykonania pokazano na rysunku 1.
 Rysunek 1:Plan dla funkcji dbo.GetNumsAlanCharlieItzikBatch
Rysunek 1:Plan dla funkcji dbo.GetNumsAlanCharlieItzikBatch
Podczas analizowania trybu wsadowego w porównaniu z przetwarzaniem w trybie wierszowym, całkiem fajnie jest móc stwierdzić, patrząc na plan na wysokim poziomie, którego trybu przetwarzania używał każdy operator. Rzeczywiście, Plan Explorer pokazuje jasnoniebieską figurę partii w dolnej lewej części operatora, gdy jego rzeczywistym trybem wykonania jest Wsad. Jak widać na rysunku 1, jedynym operatorem, który używał trybu wsadowego, jest operator Window Aggregate, który oblicza numery wierszy. Pozostali operatorzy nadal wykonują dużo pracy w trybie wierszowym.
Oto liczby dotyczące wydajności, które uzyskałem w moim teście:
Czas procesora =10032 ms, upływ czasu =10025 ms.odczyty logiczne 0
Aby określić, którzy operatorzy zajęli najwięcej czasu, użyj opcji Actual Execution Plan w SSMS lub opcji Get Actual Plan w Eksploratorze planów. Upewnij się, że przeczytałeś niedawny artykuł Paula Zrozumienie czasów operatora planu wykonania. Artykuł opisuje, jak znormalizować raportowane czasy wykonania operatora, aby uzyskać prawidłowe liczby.
W planie na rysunku 1 większość czasu spędzają operatorzy najbardziej po lewej stronie zagnieżdżonych pętli i góra, wykonujących w trybie wierszowym. Poza tym, że tryb wierszowy jest mniej wydajny niż tryb wsadowy w przypadku operacji intensywnie korzystających z procesora, należy również pamiętać, że przełączanie z trybu wsadowego na tryb wsadowy iz powrotem wiąże się z dodatkowymi kosztami.
W części 2 omówiłem inne rozwiązanie wykorzystujące przetwarzanie wsadowe, zaimplementowane w funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2. To rozwiązanie połączyło pomysły Johna Number2, Dave Masona, Joe Obbish, Alana, Charliego i mnie. Główna różnica między poprzednim rozwiązaniem a tym polega na tym, że jako jednostka bazowa pierwsze z nich wykorzystuje wirtualny konstruktor wartości tabeli, a drugie używa rzeczywistej tabeli z indeksem magazynu kolumn, co zapewnia przetwarzanie wsadowe „za darmo”. Oto kod, który tworzy tabelę i wypełnia ją za pomocą instrukcji INSERT z 102 400 wierszami, aby ją skompresować:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Oto definicja funkcji:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Pojedyncze połączenie krzyżowe między dwoma instancjami tabeli bazowej wystarcza do wytworzenia znacznie przekraczającego pożądany potencjał rzędów 4B. Tutaj ponownie rozwiązanie wykorzystuje funkcję ROW_NUMBER do utworzenia podstawowej sekwencji liczb i filtru TOP, aby ograniczyć pożądaną liczność serii liczb.
Oto kod do testowania funkcji przy użyciu techniki przypisywania zmiennych:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 2.
 Rysunek 2:Plan dla funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Rysunek 2:Plan dla funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Zauważ, że tylko dwa operatory w tym planie korzystają z trybu wsadowego — górny skan indeksu magazynu kolumn w klastrze tabeli, który jest używany jako zewnętrzne dane wejściowe sprzężenia zagnieżdżonych pętli, oraz operator Window Aggregate, który służy do obliczania podstawowych liczb wierszy .
Do testu otrzymałem następujące dane dotyczące wydajności:
Czas procesora =9812 ms, upływ czasu =9813 ms.Tabela „NullBits102400”. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera stron 0, odczyty logiczne 8, odczyty fizyczne lobby 0, odczyty serwera stron lobby 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.
Tabela „NullBits102400”. Segment odczytuje 2, segment pominięty 0.
Ponownie, większość czasu na wykonanie tego planu spędzają operatorzy zagnieżdżonych pętli najbardziej po lewej stronie i Top, które działają w trybie wiersza.
Rozwiązanie Pawła
Zanim przedstawię rozwiązanie Paula, zacznę od mojej teorii dotyczącej procesu myślowego, przez który przeszedł. W rzeczywistości jest to świetne ćwiczenie edukacyjne i sugeruję, abyś przejrzał je, zanim przyjrzysz się rozwiązaniu. Paul dostrzegł wyniszczające skutki planu, który łączy zarówno tryb wsadowy, jak i rzędowy, i postawił sobie wyzwanie, aby znaleźć rozwiązanie, które zapewni plan obejmujący wszystkie partie. Jeśli się powiedzie, potencjał takiego rozwiązania do dobrego działania jest dość wysoki. Z pewnością intrygujące jest sprawdzenie, czy taki cel jest w ogóle osiągalny, biorąc pod uwagę, że wciąż istnieje wielu operatorów, którzy jeszcze nie obsługują trybu wsadowego i wiele czynników, które hamują przetwarzanie wsadowe. Na przykład w momencie pisania tego tekstu jedynym algorytmem łączenia obsługującym przetwarzanie wsadowe jest algorytm łączenia mieszającego. Sprzężenie krzyżowe jest optymalizowane przy użyciu algorytmu zagnieżdżonych pętli. Ponadto operator Top jest obecnie zaimplementowany tylko w trybie wierszowym. Te dwa elementy są krytycznymi podstawowymi elementami używanymi w planach wielu rozwiązań, które omówiłem do tej pory, w tym dwóch powyższych.
Zakładając, że wyzwanie polegające na stworzeniu rozwiązania z planem w trybie całościowym było przyzwoitą próbą, przejdźmy do drugiego ćwiczenia. Najpierw przedstawię rozwiązanie Paula w postaci, w jakiej je dostarczył, z jego komentarzami w tekście. Uruchomię go również, aby porównać jego wydajność z innymi rozwiązaniami. Wiele się nauczyłem, dekonstruując i rekonstruując jego rozwiązanie, krok po kroku, aby upewnić się, że dokładnie zrozumiałem, dlaczego użył każdej z technik, które zrobił. Sugeruję, abyś zrobił to samo, zanim przejdę do przeczytania moich wyjaśnień.
Oto rozwiązanie Paula, które obejmuje pomocniczą tabelę magazynu kolumn o nazwie dbo.CS i funkcję o nazwie dbo.GetNums_SQLkiwi:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Oto kod, którego użyłem do przetestowania funkcji za pomocą techniki przypisywania zmiennych:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Do testu dostałem plan pokazany na rysunku 3.
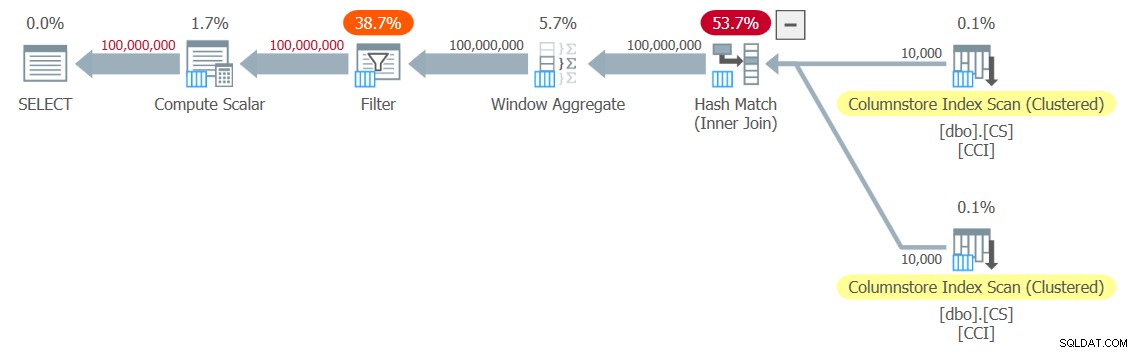 Rysunek 3:Plan dla funkcji dbo.GetNums_SQLkiwi
Rysunek 3:Plan dla funkcji dbo.GetNums_SQLkiwi
To plan całościowy! To imponujące.
Oto numery wydajności, które otrzymałem w tym teście na moim komputerze:
Czas procesora =7812 ms, upływ czasu =7876 ms.Tabela „CS”. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera stron 0, odczyty logiczne 44, odczyty fizyczne lobby 0, odczyty serwera stron lobby 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.
Tabela „CS”. Segment odczytuje 2, segment pominięty 0.
Sprawdźmy również, czy jeśli musisz zwrócić liczby uporządkowane przez n, rozwiązaniem jest zachowanie kolejności względem rn — przynajmniej w przypadku używania stałych jako danych wejściowych — a tym samym unikanie jawnego sortowania w planie. Oto kod do przetestowania z zamówieniem:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Otrzymujesz ten sam plan, co na rysunku 3, a zatem podobne wskaźniki wydajności:
Czas procesora =7765 ms, upływ czasu =7822 ms.Tabela „CS”. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera stron 0, odczyty logiczne 44, odczyty fizyczne lobby 0, odczyty serwera stron lobby 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.
Tabela „CS”. Segment odczytuje 2, segment pominięty 0.
To ważna strona rozwiązania.
Zmieniamy naszą metodologię testowania
Wydajność rozwiązania Paula to przyzwoita poprawa zarówno czasu, jaki upłynął, jak i czasu procesora w porównaniu z dwoma poprzednimi rozwiązaniami, ale nie wydaje się, aby była to bardziej radykalna poprawa, jakiej można by oczekiwać od planu całościowego. Może czegoś nam brakuje?
Spróbujmy przeanalizować czasy wykonania operatora, patrząc na rzeczywisty plan wykonania w SSMS, jak pokazano na rysunku 4.
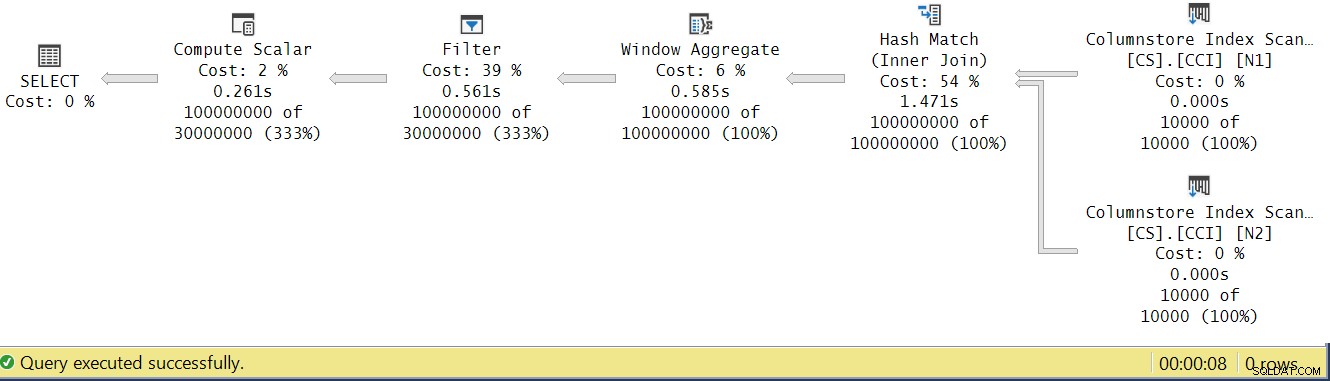 Rysunek 4:Czasy wykonania operatora dla funkcji dbo.GetNums_SQLkiwi
Rysunek 4:Czasy wykonania operatora dla funkcji dbo.GetNums_SQLkiwi
W artykule Paula o analizowaniu czasów wykonania operatorów wyjaśnia, że każdy operator w trybie wsadowym zgłasza swój własny czas wykonania. Jeśli zsumujesz czasy wykonania wszystkich operatorów w tym rzeczywistym planie, otrzymasz 2,878 sekundy, ale wykonanie planu zajęło 7,876. Wydaje się, że brakuje 5 sekund czasu wykonania. Odpowiedź na to pytanie leży w technice testowania, której używamy, z przypisaniem zmiennych. Przypomnijmy, że zdecydowaliśmy się użyć tej techniki, aby wyeliminować potrzebę wysyłania wszystkich wierszy z serwera do wywołującego i uniknąć operacji we/wy, które byłyby zaangażowane w zapisywanie wyniku do tabeli. Wydawało się to idealną opcją. Jednak prawdziwy koszt przypisania zmiennej jest ukryty w tym planie i oczywiście jest wykonywany w trybie wierszowym. Tajemnica rozwiązana.
Oczywiście pod koniec dnia dobry test to taki, który odpowiednio odzwierciedla Twoje produkcyjne wykorzystanie rozwiązania. Jeśli zwykle zapisujesz dane w tabeli, musisz to odzwierciedlić w teście. Jeśli wyślesz wynik dzwoniącemu, musisz to odzwierciedlić w teście. W każdym razie przypisanie zmiennej wydaje się reprezentować dużą część czasu wykonania w naszym teście i wyraźnie jest mało prawdopodobne, aby reprezentowało typowe produkcyjne użycie funkcji. Paul zasugerował, że zamiast przypisywania zmiennych test może zastosować prostą agregację, taką jak MAX, do kolumny zwróconej liczby (n/rn/op). Operator agregacji może wykorzystywać przetwarzanie wsadowe, więc plan nie wymagałby konwersji z trybu wsadowego na wiersz w wyniku jego użycia, a jego udział w całkowitym czasie wykonywania powinien być dość mały i znany.
Przetestujmy więc ponownie wszystkie trzy rozwiązania omówione w tym artykule. Oto kod do testowania funkcji dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Mam plan pokazany na Rysunku 5 dla tego testu.
 Rysunek 5:Plan dla funkcji dbo.GetNumsAlanCharlieItzikBatch z agregacją
Rysunek 5:Plan dla funkcji dbo.GetNumsAlanCharlieItzikBatch z agregacją
Oto numery wydajności, które otrzymałem w tym teście:
Czas procesora =8469 ms, upływ czasu =8733 ms.odczyty logiczne 0
Zauważ, że czas działania spadł z 10,025 sekundy przy użyciu techniki przypisywania zmiennych do 8,733 przy użyciu techniki agregacji. To nieco ponad sekundę czasu wykonania, który możemy przypisać tutaj przypisaniu zmiennej.
Oto kod do testowania funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Mam plan pokazany na rysunku 6 dla tego testu.
 Rysunek 6:Plan dla funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 z agregacją
Rysunek 6:Plan dla funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 z agregacją
Oto numery wydajności, które otrzymałem w tym teście:
Czas procesora =7031 ms, upływ czasu =7053 ms.Tabela „NullBits102400”. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera stron 0, odczyty logiczne 8, odczyty fizyczne lobby 0, odczyty serwera stron lobby 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.
Tabela „NullBits102400”. Segment odczytuje 2, segment pominięty 0.
Zauważ, że czas działania spadł z 9,813 sekundy przy użyciu techniki przypisywania zmiennych do 7,053 przy użyciu techniki agregacji. To nieco ponad dwie sekundy czasu wykonania, które możemy przypisać tutaj przypisaniu zmiennej.
A oto kod do testowania rozwiązania Paula:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Otrzymuję plan pokazany na Rysunku 7 dla tego testu.
 Rysunek 7:Plan dla funkcji dbo.GetNums_SQLkiwi z agregacją
Rysunek 7:Plan dla funkcji dbo.GetNums_SQLkiwi z agregacją
A teraz wielka chwila. W tym teście otrzymałem następujące dane dotyczące wydajności:
Czas procesora =3125 ms, upływ czasu =3149 ms.Tabela „CS”. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera stron 0, odczyty logiczne 44, odczyty fizyczne lobby 0, odczyty serwera stron lobby 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.
Tabela „CS”. Segment odczytuje 2, segment pominięty 0.
Czas działania spadł z 7,822 sekundy do 3,149 sekundy! Zbadajmy czasy wykonania operatora w rzeczywistym planie w SSMS, jak pokazano na rysunku 8.
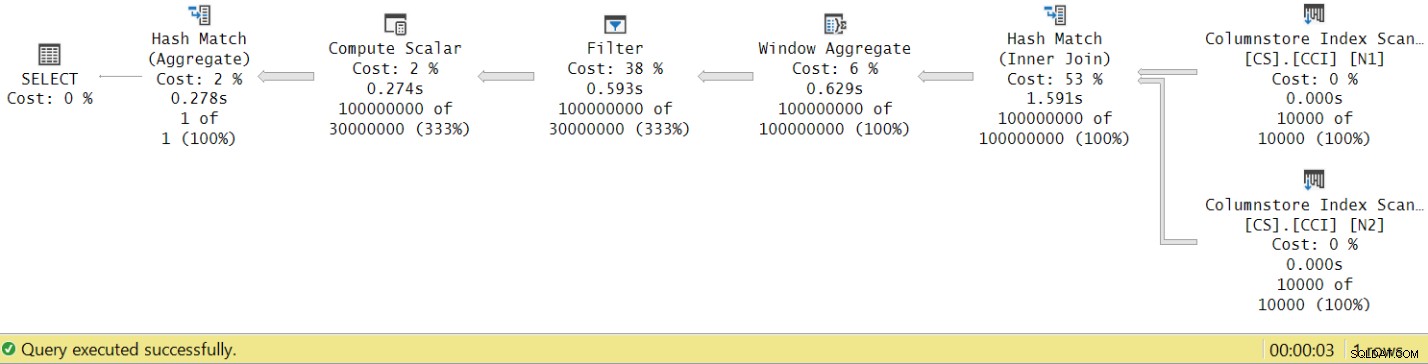 Rysunek 8:Czasy wykonania operatora dla funkcji dbo.GetNums z agregacją
Rysunek 8:Czasy wykonania operatora dla funkcji dbo.GetNums z agregacją
Teraz, jeśli zsumujesz czasy wykonania poszczególnych operatorów, otrzymasz podobną liczbę do całkowitego czasu wykonania planu.
Rysunek 9 przedstawia porównanie wydajności pod względem czasu, jaki upłynął między trzema rozwiązaniami przy użyciu zarówno technik przypisywania zmiennych, jak i technik testowania agregatów.
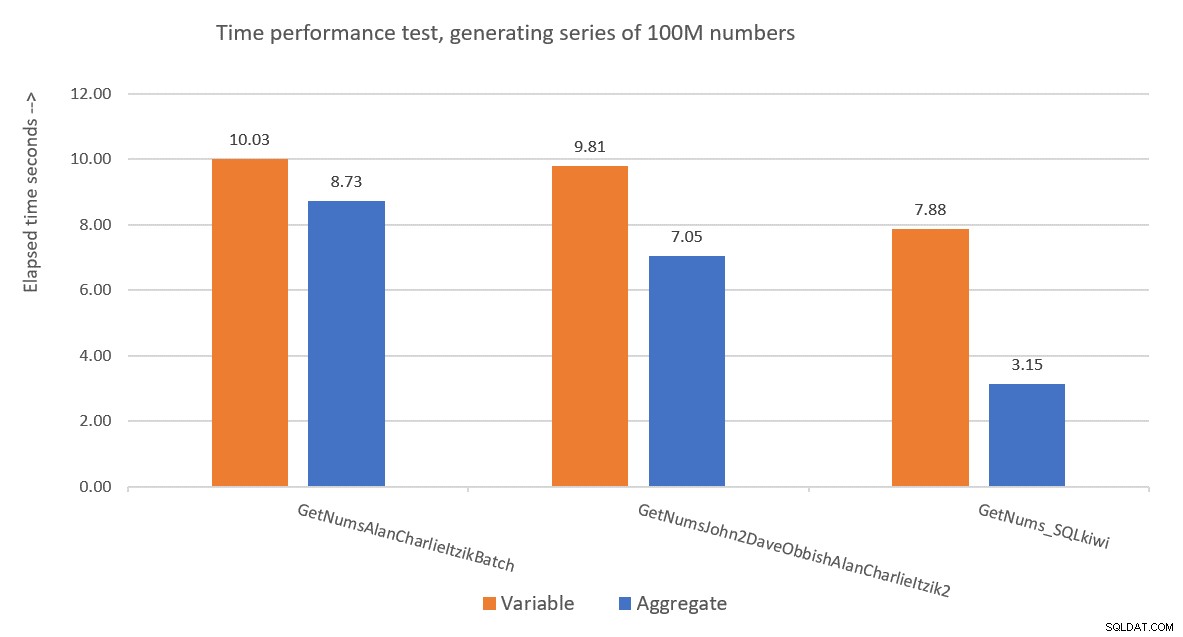 Rysunek 9:Porównanie wydajności
Rysunek 9:Porównanie wydajności
Rozwiązanie Paula jest wyraźnym zwycięzcą, co jest szczególnie widoczne przy użyciu techniki badania kruszywa. Co za imponujący wyczyn!
Dekonstruowanie i rekonstruowanie rozwiązania Paula
Dekonstrukcja, a następnie rekonstrukcja rozwiązania Paula to świetne ćwiczenie i możesz się przy tym wiele nauczyć. Jak zasugerowano wcześniej, przed dalszą lekturą zalecam samodzielne przejście przez ten proces.
Pierwszym wyborem, którego musisz dokonać, jest technika, której użyjesz do wygenerowania pożądanej potencjalnej liczby rzędów 4B. Paul zdecydował się na użycie tabeli magazynu kolumn i wypełnienie jej tyloma wierszami, ile wynosi pierwiastek kwadratowy wymaganej liczby, co oznacza 65 536 wierszy, tak aby przy pojedynczym sprzężeniu krzyżowym uzyskać wymaganą liczbę. Być może myślisz, że przy mniej niż 102 400 wierszach nie uzyskasz skompresowanej grupy wierszy, ale ma to zastosowanie, gdy wypełniasz tabelę instrukcją INSERT, tak jak zrobiliśmy to z tabelą dbo.NullBits102400. Nie dotyczy to tworzenia indeksu magazynu kolumn w wstępnie wypełnionej tabeli. Dlatego Paul użył instrukcji SELECT INTO, aby utworzyć i zapełnić tabelę jako stertę opartą na magazynie wierszy z 65 536 wierszami, a następnie utworzył klastrowany indeks magazynu kolumn, co dało skompresowaną grupę wierszy.
Kolejnym wyzwaniem jest ustalenie, jak uzyskać połączenie krzyżowe do przetworzenia za pomocą operatora trybu wsadowego. W tym celu potrzebny jest algorytm łączenia jako hash. Pamiętaj, że łączenie krzyżowe jest optymalizowane za pomocą algorytmu zagnieżdżonych pętli. Musisz jakoś oszukać optymalizator, aby pomyślał, że używasz wewnętrznego equijoin (skrót wymaga co najmniej jednego predykatu opartego na równości), ale w praktyce uzyskaj sprzężenie krzyżowe.
Oczywistą pierwszą próbą jest użycie sprzężenia wewnętrznego z predykatem sztucznego sprzężenia, który zawsze jest prawdziwy, na przykład:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Ale ten kod kończy się niepowodzeniem z następującym błędem:
Msg 8622, poziom 16, stan 1, wiersz 246Procesor kwerend nie może utworzyć planu kwerendy z powodu wskazówek zdefiniowanych w tej kwerendzie. Ponownie prześlij zapytanie bez określania żadnych wskazówek i bez użycia SET FORCEPLAN.
Optymalizator SQL Server rozpoznaje, że jest to predykat sztucznego sprzężenia wewnętrznego, upraszcza sprzężenie wewnętrzne do sprzężenia krzyżowego i wyświetla błąd informujący, że nie może pomieścić podpowiedzi, aby wymusić algorytm sprzężenia mieszającego.
Aby rozwiązać ten problem, Paul utworzył w swojej tabeli dbo.CS kolumnę INT NOT NULL (więcej o tym, dlaczego wkrótce ta specyfikacja) o nazwie n1 i wypełnił ją 0 we wszystkich wierszach. Następnie użył predykatu złączenia N2.n1 =N1.n1, skutecznie uzyskując propozycję 0 =0 we wszystkich ocenach dopasowania, przy jednoczesnym spełnieniu minimalnych wymagań algorytmu łączenia mieszającego.
To działa i tworzy plan dla wszystkich partii:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Jeśli chodzi o powód, dla którego n1 ma być zdefiniowane jako INT NOT NULL; dlaczego nie zezwalać na wartości NULL i dlaczego nie używać BIGINT? Powodem tych wyborów jest uniknięcie pozostałości sondy mieszającej (dodatkowy filtr, który jest stosowany przez operatora łączenia mieszającego poza pierwotnym predykatem łączenia), co może skutkować dodatkowymi niepotrzebnymi kosztami. Zobacz artykuł Paula Join Performance, Implicit Conversions and Residuals, aby uzyskać szczegółowe informacje. Oto fragment artykułu, który jest dla nas istotny:
„Jeśli sprzężenie jest w jednej kolumnie wpisanej jako tinyint, smallint lub integer i jeśli obie kolumny są ograniczone do wartości NOT NULL, funkcja skrótu jest„doskonała” – co oznacza, że nie ma możliwości kolizji skrótów, a procesor zapytań nie musi ponownie sprawdzać wartości, aby upewnić się, że naprawdę pasują.Pamiętaj, że ta optymalizacja nie dotyczy kolumn bigint."
Aby sprawdzić ten aspekt, stwórzmy kolejną tabelę o nazwie dbo.CS2 z kolumną n1 dopuszczającą wartość null:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Najpierw przetestujmy zapytanie względem dbo.CS (gdzie n1 jest zdefiniowane jako INT NOT NULL), generując podstawowe numery wierszy o wielkości 4B w kolumnie o nazwie rn i stosując agregację MAX do kolumny:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Porównamy plan dla tego zapytania z planem dla podobnego zapytania z dbo.CS2 (gdzie n1 jest zdefiniowane jako INT NULL):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Plany dla obu zapytań pokazano na rysunku 10.
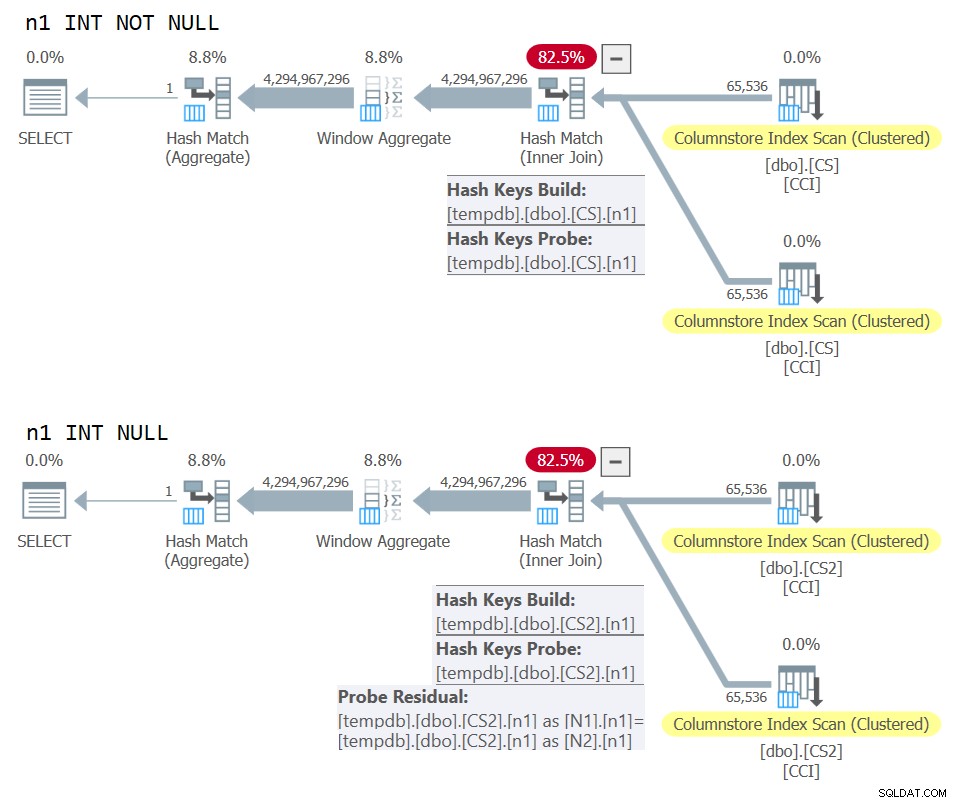 Rysunek 10:Porównanie planów dla klucza łączenia NOT NULL i NULL
Rysunek 10:Porównanie planów dla klucza łączenia NOT NULL i NULL
Możesz wyraźnie zobaczyć dodatkową pozostałość sondy, która jest zastosowana w drugim planie, ale nie w pierwszym.
Na moim komputerze zapytanie o dbo.CS zostało zakończone w 91 sekund, a zapytanie o dbo.CS2 w 92 sekundy. W artykule Paul informuje o 11% różnicy na korzyść przypadku NOT NULL dla przykładu, którego użył.
BTW, ci z was bystrym okiem zauważą użycie ORDER BY @@TRANCOUNT jako specyfikacji zamawiania funkcji ROW_NUMBER. Jeśli uważnie przeczytasz wbudowane komentarze Paula w jego rozwiązaniu, wspomni on, że użycie funkcji @@TRANCOUNT jest inhibitorem równoległości, podczas gdy użycie @@SPID nie. Możesz więc użyć @@TRANCOUNT jako stałej czasu wykonywania w specyfikacji zamówienia, gdy chcesz wymusić plan szeregowy i @@SPID, gdy tego nie zrobisz.
Jak wspomniano, uruchomienie zapytania przeciwko dbo.CS na moim komputerze zajęło 91 sekund. W tym momencie może być interesujące przetestowanie tego samego kodu z prawdziwym łączeniem krzyżowym, pozwalając optymalizatorowi na użycie algorytmu łączenia zagnieżdżonych pętli w trybie wiersza:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Ukończenie tego kodu na moim komputerze zajęło 104 sekundy. Tak więc uzyskujemy znaczną poprawę wydajności dzięki łączeniu mieszającemu w trybie wsadowym.
Naszym kolejnym problemem jest to, że używając TOP do filtrowania żądanej liczby wierszy, otrzymujesz plan z operatorem Top w trybie wierszowym. Oto próba zaimplementowania funkcji dbo.GetNums_SQLkiwi z filtrem TOP:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Przetestujmy funkcję:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Do tego testu dostałem plan pokazany na rysunku 11.
 Rysunek 11:Planowanie z filtrem TOP
Rysunek 11:Planowanie z filtrem TOP
Zauważ, że operator Top jest jedynym w planie, który używa przetwarzania w trybie wiersza.
Otrzymałem następujące statystyki czasu dla tego wykonania:
Czas procesora =6078 ms, upływ czasu =6071 ms.Największą część czasu działania w tym planie spędza operator Top trybu wiersza i fakt, że plan musi przejść przez konwersję w trybie wsadowym do wiersza iz powrotem.
Naszym wyzwaniem jest znalezienie alternatywy dla filtrowania w trybie wsadowym dla TOP w trybie wierszowym. Filtry oparte na predykatach, takie jak te stosowane z klauzulą WHERE, mogą potencjalnie być obsługiwane przez przetwarzanie wsadowe.
Podejście Paula polegało na wprowadzeniu drugiej kolumny typu INT (patrz komentarz w wierszu „wszystko i tak jest znormalizowane do 64-bitowego w trybie magazynu kolumn/wsadowym” ) o nazwie n2 do tabeli dbo.CS i wypełnij ją sekwencją liczb całkowitych od 1 do 65 536. W kodzie rozwiązania zastosował dwa filtry oparte na predykatach. Jednym z nich jest filtr zgrubny w zapytaniu wewnętrznym z predykatami obejmującymi kolumnę n2 z obu stron sprzężenia. Ten filtr zgrubny może skutkować niektórymi fałszywymi alarmami. Oto pierwsza uproszczona próba takiego filtra:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) Z wejściami 1 i 100 000 000 jako @low i @high, nie otrzymujesz fałszywych alarmów. Ale spróbuj z 1 i 100 000 001, a otrzymasz trochę. Otrzymasz sekwencję 100 020 001 liczb zamiast 100 000 001.
Aby wyeliminować fałszywe alarmy, Paul dodał drugi, precyzyjny filtr obejmujący kolumnę rn w zewnętrznym zapytaniu. Oto pierwsza uproszczona próba stworzenia tak precyzyjnego filtra:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Zmieńmy definicję funkcji, aby użyć powyższych filtrów opartych na predykatach zamiast TOP, weźmy 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Przetestujmy funkcję:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Mam plan pokazany na rysunku 12 dla tego testu.
 Rysunek 12:Planuj z filtrem WHERE, weź 1
Rysunek 12:Planuj z filtrem WHERE, weź 1
Niestety, coś poszło nie tak. SQL Server przekonwertował nasz filtr oparty na predykatach, obejmujący kolumnę rn, na filtr oparty na TOP i zoptymalizował go za pomocą operatora Top — czego dokładnie staraliśmy się uniknąć. Aby dodać obrazę do kontuzji, optymalizator zdecydował się również na użycie algorytmu zagnieżdżonych pętli do łączenia.
Zajęło to 18,8 sekundy, aby zakończyć na moim komputerze. Nie wygląda dobrze.
Jeśli chodzi o łączenie zagnieżdżonych pętli, jest to coś, o co moglibyśmy łatwo zadbać za pomocą wskazówki dotyczącej złączenia w zapytaniu wewnętrznym. Aby zobaczyć wpływ na wydajność, oto test z wskazówką dotyczącą wymuszonego łączenia haszującego użytą w samym zapytaniu testowym:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Czas działania skraca się do 13,2 sekundy.
Nadal mamy problem z konwersją filtra WHERE z rn na filtr TOP. Spróbujmy zrozumieć, jak to się stało. W zewnętrznym zapytaniu użyliśmy następującego filtra:
WHERE N.rn < @high - @low + 2
Pamiętaj, że rn reprezentuje niezmanipulowane wyrażenie oparte na ROW_NUMBER. Filtr oparty na takim niemanipulowanym wyrażeniu znajdującym się w danym zakresie jest często optymalizowany operatorem Top, co dla nas jest złą wiadomością ze względu na zastosowanie przetwarzania w trybie wierszowym.
Obejściem Paula było użycie równoważnego predykatu, ale takiego, który stosuje manipulację do rn, na przykład:
WHERE @low - 2 + N.rn < @high
Filtrowanie wyrażenia, które dodaje manipulację do wyrażenia opartego na ROW_NUMBER, hamuje konwersję filtru opartego na predykacie na filtr oparty na TOP. To genialne!
Zweryfikujmy definicję funkcji, aby użyć powyższego predykatu WHERE, weźmy 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Przetestuj funkcję ponownie, bez żadnych specjalnych wskazówek ani niczego:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Naturalnie otrzymuje plan w trybie całościowym z algorytmem łączenia mieszającego i bez operatora Top, co skutkuje czasem wykonania wynoszącym 3,177 sekundy. Wygląda dobrze.
Następnym krokiem jest sprawdzenie, czy rozwiązanie dobrze radzi sobie ze złymi danymi wejściowymi. Spróbujmy z ujemną deltą:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
To wykonanie kończy się niepowodzeniem z następującym błędem.
Msg 3623, Poziom 16, Stan 1, Wiersz 436Wystąpiła nieprawidłowa operacja zmiennoprzecinkowa.
Niepowodzenie jest spowodowane próbą zastosowania pierwiastka kwadratowego z liczby ujemnej.
Rozwiązanie Paula obejmowało dwa dodatki. Jednym z nich jest dodanie następującego predykatu do klauzuli WHERE wewnętrznego zapytania:
@high >= @low
Ten filtr robi więcej, niż się początkowo wydaje. Jeśli uważnie przeczytałeś wbudowane komentarze Paula, możesz znaleźć tę część:
„Staraj się unikać SQRT na liczbach ujemnych i włącz uproszczenie do pojedynczego stałego skanowania, jeśli @low> @high (z literałami). Brak filtrów startowych w trybie wsadowym.”Intrygującą częścią jest tutaj możliwość użycia stałego skanowania ze stałymi jako danymi wejściowymi. Zaraz do tego przejdę.
Innym dodatkiem jest zastosowanie funkcji IIF do wyrażenia wejściowego do funkcji PIERWIASTEK. Ma to na celu uniknięcie ujemnych danych wejściowych podczas używania niestałych jako danych wejściowych do naszej funkcji liczbowej oraz w przypadku, gdy optymalizator zdecyduje się obsłużyć predykat obejmujący SQRT przed predykatem @high>=@low.
Na przykład przed dodaniem IIF predykat zawierający N1.n2 wyglądał tak:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Try it:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Wniosek
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.



