AKTUALIZACJA:2 września 2021 (Pierwotnie opublikowany 26 lipca 2012 r.)
W ciągu kilku głównych wersji naszej ulubionej platformy bazodanowej wiele się zmieniło. SQL Server 2016 przyniósł nam STRING_SPLIT, natywną funkcję, która eliminuje potrzebę wielu niestandardowych rozwiązań, których potrzebowaliśmy wcześniej. Jest też szybki, ale nie idealny. Na przykład obsługuje tylko ogranicznik jednoznakowy i nie zwraca niczego, aby wskazać kolejność elementów wejściowych. Napisałem kilka artykułów na temat tej funkcji (i STRING_AGG, który pojawił się w SQL Server 2017) od czasu napisania tego posta:
- Niespodzianki i założenia dotyczące wydajności:STRING_SPLIT()
- STRING_SPLIT() w SQL Server 2016:kontynuacja nr 1
- STRING_SPLIT() w SQL Server 2016:kontynuacja nr 2
- Kod zastępujący dzielony ciąg SQL Server za pomocą STRING_SPLIT
- Porównywanie metod dzielenia/konkatenacji ciągów
- Rozwiąż stare problemy za pomocą nowych funkcji STRING_AGG i STRING_SPLIT w SQL Server
- Zajmowanie się jednoznakowym ogranicznikiem w funkcji STRING_SPLIT serwera SQL
- Pomóż przy ulepszeniach STRING_SPLIT
- Sposób na ulepszenie STRING_SPLIT w SQL Server – a Ty możesz pomóc
Zostawię tutaj poniższą treść dla potomności i znaczenia historycznego, a także dlatego, że niektóre metodologie testowania są istotne dla innych problemów poza dzieleniem ciągów, ale proszę zapoznać się z niektórymi z powyższych odnośników, aby uzyskać informacje o tym, jak należy dzielić ciągi w nowoczesnych, obsługiwanych wersjach SQL Server – a także ten post, który wyjaśnia, dlaczego dzielenie ciągów może nie jest problemem, który chcesz rozwiązać w bazie danych, czy to nowa funkcja, czy nie.
- Rozdzielanie ciągów:teraz z mniejszą ilością T-SQL
Wiem, że wiele osób jest znudzonych problemem „split strings”, ale wciąż wydaje się, że pojawia się on prawie codziennie na forum i stronach z pytaniami i odpowiedziami, takich jak Stack Overflow. Jest to problem polegający na tym, że ludzie chcą przekazać ciąg znaków taki jak ten:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
W ramach procedury chcą zrobić coś takiego:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); To nie działa, ponieważ @FavoriteTeams jest pojedynczym ciągiem, a powyższe przekłada się na:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); Dlatego SQL Server spróbuje znaleźć zespół o nazwie Patriots,Red Sox,Bruins i domyślam się, że takiego zespołu nie ma. To, czego naprawdę chcą tutaj, to odpowiednik:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Ale ponieważ w SQL Server nie ma typu tablicy, w ogóle nie tak interpretuje się zmienną – wciąż jest to prosty, pojedynczy ciąg, który zawiera przecinki. Pomijając wątpliwy projekt schematu, w tym przypadku listę oddzieloną przecinkami należy „podzielić” na poszczególne wartości – i to jest pytanie, które często wywołuje wiele „nowych” debat i komentarzy na temat najlepszego rozwiązania, aby to osiągnąć.
Prawie zawsze odpowiedź wydaje się być taka, że powinieneś używać CLR. Jeśli nie możesz używać CLR – a wiem, że jest wielu z was, którzy nie mogą tego zrobić ze względu na politykę firmy, szefa ze spiczastymi włosami lub upór – wtedy używacie jednego z wielu istniejących obejść. Istnieje wiele obejść.
Ale którego należy użyć?
Porównam wydajność kilku rozwiązań – i skoncentruję się na pytaniu, które wszyscy zawsze zadają:„Który jest najszybszy?” Nie będę rozwodził się nad dyskusją wokół *wszystkich* potencjalnych metod, ponieważ kilka zostało już wyeliminowanych z powodu tego, że po prostu nie skalują się. Być może odwiedzę to ponownie w przyszłości, aby zbadać wpływ na inne wskaźniki, ale na razie skupię się tylko na czasie trwania. Oto konkurenci, których porównam (używając SQL Server 2012, 11.00.2316, na maszynie wirtualnej Windows 7 z 4 procesorami i 8 GB pamięci RAM):
CLR
Jeśli chcesz używać CLR, zdecydowanie powinieneś pożyczyć kod od innego MVP Adama Machanica, zanim pomyślisz o napisaniu własnego (wcześniej pisałem na blogu o ponownym wymyśleniu koła i dotyczy to również darmowych fragmentów kodu, takich jak ten). Spędził dużo czasu na dostrajaniu tej funkcji CLR, aby wydajnie analizować ciąg. Jeśli obecnie używasz funkcji CLR, a to nie jest to, zdecydowanie polecam ją wdrożyć i porównać – przetestowałem ją ze znacznie prostszą, opartą na VB procedurą CLR, która była funkcjonalnie równoważna, ale podejście VB działało około trzy razy gorzej niż Adama.
Wziąłem więc funkcję Adama, skompilowałem kod do biblioteki DLL (używając csc) i wdrożyłem właśnie ten plik na serwerze. Następnie dodałem następujący zestaw i funkcję do mojej bazy danych:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Jest to typowa funkcja, której używam w jednorazowych scenariuszach, w których wiem, że dane wejściowe są „bezpieczne”, ale nie jest to funkcja, którą polecam w środowiskach produkcyjnych (więcej na ten temat poniżej).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO W podejściu XML musi obowiązywać bardzo mocne zastrzeżenie:można go użyć tylko wtedy, gdy możesz zagwarantować, że twój ciąg wejściowy nie zawiera żadnych niedozwolonych znaków XML. Jedna nazwa z <,> lub &i funkcja zostanie wysadzony. Więc niezależnie od wydajności, jeśli zamierzasz użyć tego podejścia, pamiętaj o ograniczeniach – nie powinno to być uważane za realną opcję dla ogólnego rozdzielacza ciągów. Uwzględniam to w tym podsumowaniu, ponieważ możesz mieć przypadek, w którym możesz ufaj danemu wejściowemu – na przykład możliwe jest użycie dla oddzielonych przecinkami list liczb całkowitych lub identyfikatorów GUID.
Tabela liczb
To rozwiązanie wykorzystuje tabelę liczb, którą musisz sam zbudować i wypełnić. (Od wieków prosiliśmy o wersję wbudowaną). Tabela Numbers powinna zawierać wystarczającą liczbę wierszy, aby przekroczyć długość najdłuższego ciągu, który będzie dzielony. W tym przypadku użyjemy 1 000 000 wierszy:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Korzystanie z kompresji danych drastycznie zmniejszy liczbę wymaganych stron, ale oczywiście powinieneś używać tej opcji tylko wtedy, gdy korzystasz z wersji Enterprise Edition. W tym przypadku skompresowane dane wymagają 1360 stron, w porównaniu do 2102 stron bez kompresji – około 35% oszczędności. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Wspólne wyrażenie tabeli
To rozwiązanie wykorzystuje rekurencyjne CTE do wyodrębnienia każdej części ciągu z „pozostałości” poprzedniej części. Jako rekurencyjne CTE ze zmiennymi lokalnymi, zauważysz, że musiała to być wieloinstrukcyjna funkcja z wartościami tabelarycznymi, w przeciwieństwie do innych, które wszystkie są wbudowane.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Rozgałęźnik Jeffa Modena Funkcja oparta na rozdzielaczu Jeffa Modena z niewielkimi zmianami w celu obsługi dłuższych ciągów
Powyżej na SQLServerCentral Jeff Moden zaprezentował funkcję rozdzielającą, która rywalizowała z wydajnością CLR, więc pomyślałem, że sprawiedliwe będzie uwzględnienie w tym podsumowaniu odmiany przy użyciu podobnego podejścia. Musiałem dokonać kilku drobnych zmian w jego funkcji, aby obsłużyć nasz najdłuższy ciąg (500 000 znaków), a także upodobnić konwencje nazewnictwa:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Na marginesie, dla tych, którzy używają rozwiązania Jeffa Modena, możesz rozważyć użycie tabeli liczb jak powyżej i poeksperymentowanie z niewielką zmianą funkcji Jeffa:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (To zamieni nieco wyższe odczyty na nieco niższy procesor, więc może być lepsze w zależności od tego, czy twój system jest już powiązany z procesorem, czy we/wy).
Sprawdzanie stanu zdrowia
Aby mieć pewność, że jesteśmy na dobrej drodze, możemy sprawdzić, czy wszystkie pięć funkcji zwraca oczekiwane wyniki:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
W rzeczywistości są to wyniki, które widzimy we wszystkich pięciu przypadkach…

Dane testowe
Teraz, gdy wiemy, że funkcje zachowują się zgodnie z oczekiwaniami, możemy przejść do zabawnej części:testowania wydajności na różnych liczbach ciągów znaków o różnej długości. Ale najpierw potrzebujemy stołu. Stworzyłem następujący prosty obiekt:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Wypełniłem tę tabelę zestawem ciągów o różnej długości, upewniając się, że w każdym teście zostanie użyty mniej więcej ten sam zestaw danych – najpierw 10 000 wierszy, w których ciąg ma 50 znaków, a następnie 1000 wierszy, w których ciąg ma 500 znaków , 100 wierszy, w których ciąg ma 5 000 znaków, 10 wierszy, w których ciąg ma 50 000 znaków, i tak dalej do 1 wiersza zawierającego 500 000 znaków. Zrobiłem to zarówno po to, aby porównać tę samą ilość ogólnych danych przetwarzanych przez funkcje, jak również po to, aby moje czasy testowania były nieco przewidywalne.
Używam tabeli #temp, dzięki czemu mogę po prostu użyć GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Utworzenie i wypełnienie tej tabeli na moim komputerze zajęło około 20 sekund, a tabela reprezentuje około 6 MB danych (około 500 000 znaków razy 2 bajty lub 1 MB na string_type plus narzut wierszy i indeksów). Nie jest to duża tabela, ale powinna być wystarczająco duża, aby podkreślić wszelkie różnice w wydajności między funkcjami.
Testy
Mając funkcje na swoim miejscu i tabelę odpowiednio wypełnioną dużymi ciągami do przeżuwania, możemy wreszcie przeprowadzić kilka rzeczywistych testów, aby zobaczyć, jak różne funkcje działają na rzeczywistych danych. Aby zmierzyć wydajność bez uwzględniania obciążenia sieci, użyłem SQL Sentry Plan Explorer, uruchamiając każdy zestaw testów 10 razy, zbierając metryki czasu trwania i uśredniając.
Pierwszy test po prostu wyciągnął elementy z każdego ciągu jako zestaw:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Wyniki pokazują, że gdy struny stają się większe, przewaga CLR naprawdę błyszczy. W dolnej części wyniki były mieszane, ale znowu metoda XML powinna mieć obok siebie gwiazdkę, ponieważ jej użycie zależy od danych wejściowych bezpiecznych dla XML. W tym konkretnym przypadku użycia tabela Liczb konsekwentnie wypadała najgorzej:
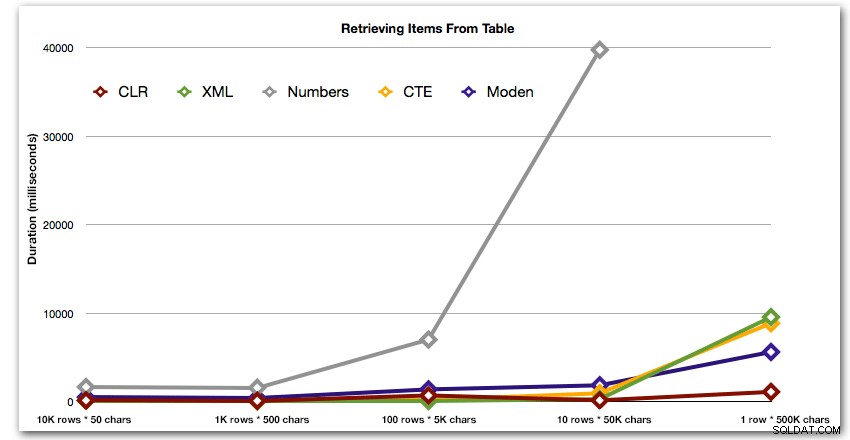
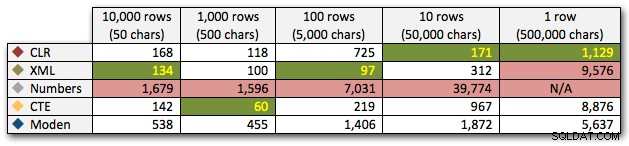
Czas trwania w milisekundach
Po hiperbolicznym 40-sekundowym występie tabeli liczb w 10 rzędach po 50 000 znaków, odrzuciłem go z biegu w ostatnim teście. Aby lepiej pokazać względną wydajność czterech najlepszych metod w tym teście, całkowicie pominąłem wyniki liczb z wykresu:
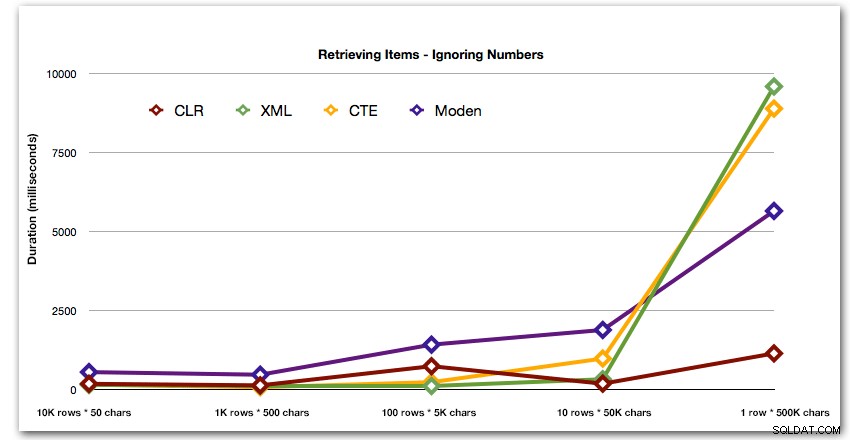
Następnie porównajmy, kiedy przeprowadzamy wyszukiwanie względem wartości oddzielonych przecinkami (np. zwracamy wiersze, w których jednym z ciągów jest „foo”). Ponownie użyjemy pięciu powyższych funkcji, ale porównamy również wynik z wyszukiwaniem przeprowadzonym w czasie wykonywania przy użyciu funkcji LIKE zamiast zawracania sobie głowy dzieleniem.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Wyniki te pokazują, że w przypadku małych ciągów CLR był w rzeczywistości najwolniejszy, a najlepszym rozwiązaniem będzie wykonanie skanowania przy użyciu funkcji LIKE, bez zawracania sobie głowy dzieleniem danych. Ponownie porzuciłem rozwiązanie tabeli liczb z piątego podejścia, kiedy stało się jasne, że jego czas trwania będzie wzrastał wykładniczo wraz ze wzrostem rozmiaru łańcucha:
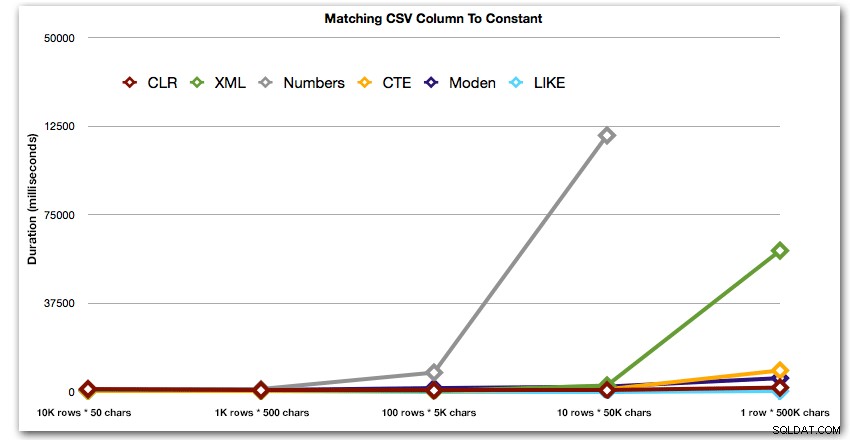
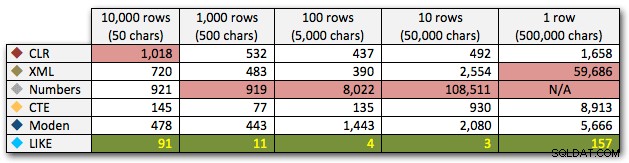
Czas trwania w milisekundach
Aby lepiej zademonstrować wzorce dla 4 najlepszych wyników, wyeliminowałem z wykresu rozwiązania Numbers i XML:
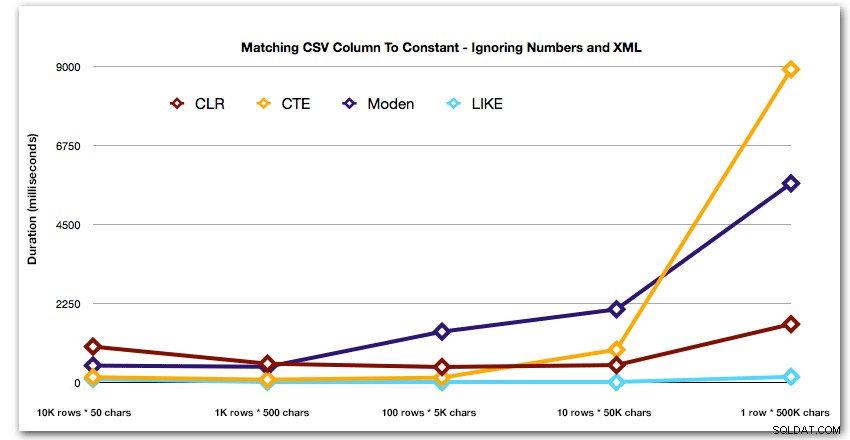
Następnie spójrzmy na replikację przypadku użycia z początku tego postu, w którym próbujemy znaleźć wszystkie wiersze w jednej tabeli, które istnieją na liście, która jest przekazywana. Podobnie jak w przypadku danych w tabeli, którą utworzyliśmy powyżej, utworzymy ciągi o różnej długości od 50 do 500 000 znaków, zapiszemy je w zmiennej, a następnie sprawdzimy, czy na liście znajduje się wspólny widok katalogu.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Wyniki te pokazują, że w przypadku tego wzorca czas trwania kilku metod rośnie wykładniczo wraz ze wzrostem rozmiaru struny. Na niższym poziomie XML utrzymuje dobre tempo z CLR, ale to również szybko się pogarsza. CLR jest tutaj niezmiennie wyraźnym zwycięzcą:
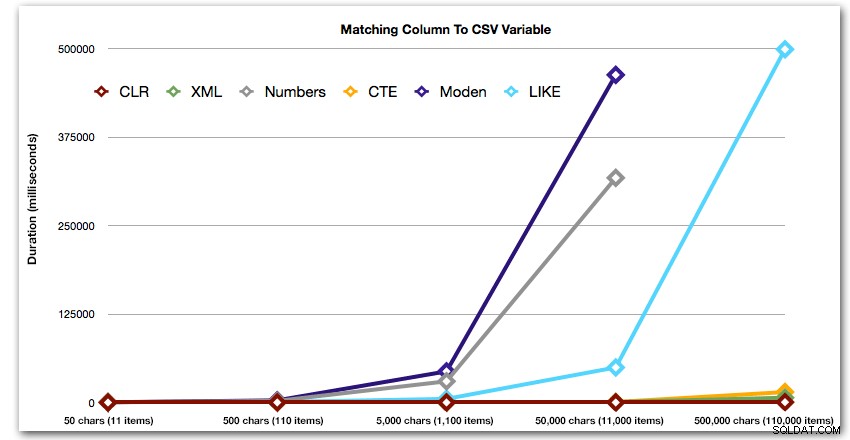
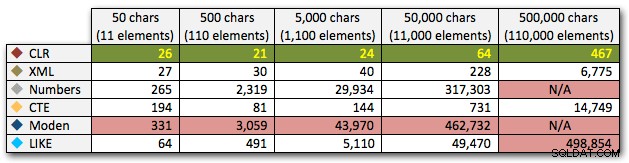
Czas trwania w milisekundach
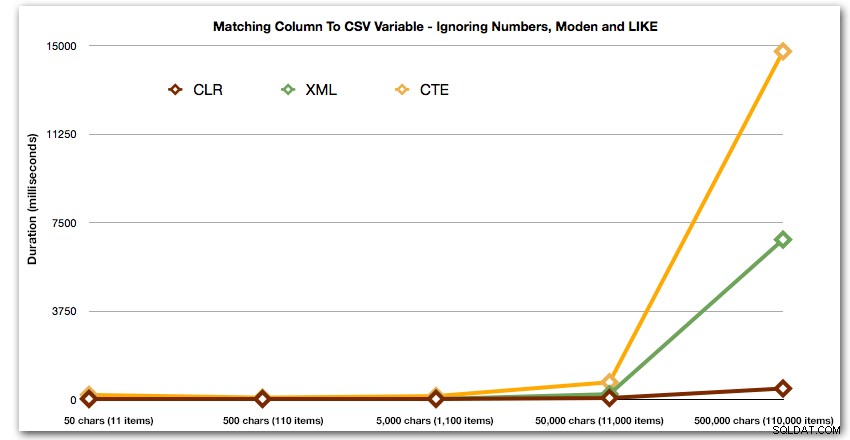
I znowu bez metod, które eksplodują w górę pod względem czasu trwania:
Na koniec porównajmy koszt pobrania danych z pojedynczej zmiennej o różnej długości, pomijając koszt odczytu danych z tabeli. Ponownie wygenerujemy ciągi o różnej długości, od 50 do 500 000 znaków, a następnie po prostu zwrócimy wartości jako zestaw:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Wyniki te pokazują również, że CLR jest dość płaski pod względem czasu trwania, aż do 110 000 pozycji w zestawie, podczas gdy inne metody utrzymują przyzwoite tempo do pewnego czasu po 11 000 pozycji:
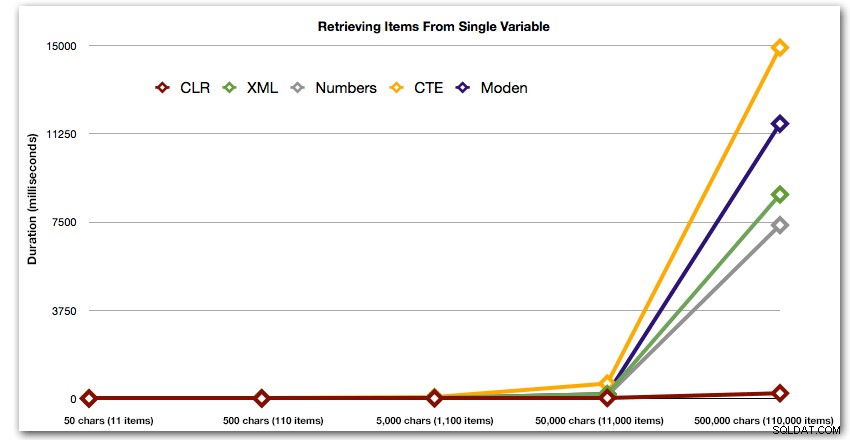
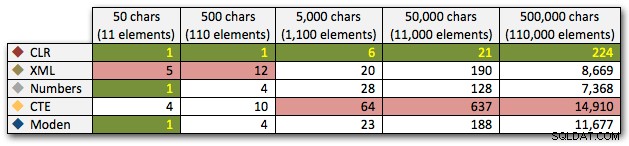
Czas trwania w milisekundach
Wniosek
W prawie wszystkich przypadkach rozwiązanie CLR wyraźnie przewyższa inne podejścia – w niektórych przypadkach jest to zwycięstwo osuwiskowe, zwłaszcza w miarę wzrostu rozmiarów strun; w kilku innych jest to wykończenie zdjęcia, które może spaść w obie strony. W pierwszym teście zobaczyliśmy, że XML i CTE przewyższają CLR na najniższym poziomie, więc jeśli jest to typowy przypadek użycia *i* masz pewność, że twoje ciągi mają zakres od 1 do 10 000 znaków, jedno z tych podejść może być lepszą opcją. Jeśli rozmiary twoich strun są mniej przewidywalne niż to, CLR jest prawdopodobnie nadal najlepszym rozwiązaniem – tracisz kilka milisekund na dolnym końcu, ale dużo zyskujesz na górnym końcu. Oto wybory, których dokonałbym w zależności od zadania, z wyróżnieniem drugiego miejsca w przypadkach, w których CLR nie jest opcją. Zauważ, że XML jest moją preferowaną metodą tylko wtedy, gdy wiem, że dane wejściowe są bezpieczne dla XML; niekoniecznie są to najlepsze alternatywy, jeśli masz mniejszą wiarę w swój wkład.
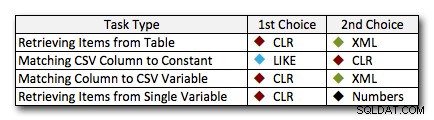
Jedynym prawdziwym wyjątkiem, w którym CLR nie jest moim wyborem, jest przypadek, w którym faktycznie przechowujesz listy oddzielone przecinkami w tabeli, a następnie znajdujesz wiersze, w których zdefiniowana encja znajduje się na tej liście. W tym konkretnym przypadku prawdopodobnie najpierw zaleciłbym przeprojektowanie i prawidłową normalizację schematu, aby te wartości były przechowywane osobno, zamiast używać ich jako wymówki, aby nie używać CLR do dzielenia.
Jeśli nie możesz używać CLR z innych powodów, nie ma wyraźnego „drugiego miejsca” ujawnionego przez te testy; moje odpowiedzi powyżej opierały się na ogólnej skali, a nie na żadnym konkretnym rozmiarze ciągu. Każde rozwiązanie tutaj znalazło się na drugim miejscu w co najmniej jednym scenariuszu – więc chociaż CLR jest wyraźnie wyborem, kiedy możesz go użyć, to, czego powinieneś użyć, gdy nie możesz, jest bardziej odpowiedzią „to zależy” – musisz oceniać na podstawie Twoje przypadki użycia i powyższe testy (lub konstruując własne testy), która alternatywa jest dla Ciebie lepsza.
Uzupełnienie:alternatywa dla dzielenia w pierwszej kolejności
Powyższe podejścia nie wymagają żadnych zmian w istniejących aplikacjach, zakładając, że już gromadzą ciąg oddzielony przecinkami i wrzucają go do bazy danych, aby się z nim uporać. Jedną z opcji, którą należy rozważyć, jeśli CLR nie jest opcją i/lub można zmodyfikować aplikację (aplikacje), jest użycie parametrów z wartościami tabelarycznymi (TVP). Oto szybki przykład wykorzystania TVP w powyższym kontekście. Najpierw utwórz typ tabeli z kolumną z pojedynczym ciągiem:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Następnie procedura składowana może przyjąć to TVP jako dane wejściowe i dołączyć do treści (lub użyć jej w inny sposób – to tylko jeden przykład):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Teraz w kodzie C#, na przykład, zamiast tworzyć ciąg rozdzielany przecinkami, wypełnij DataTable (lub użyj dowolnej zgodnej kolekcji, która może już zawierać Twój zestaw wartości):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Możesz uznać to za prequel kolejnego posta.
Oczywiście nie działa to dobrze z JSON i innymi interfejsami API – dość często jest to powód, dla którego ciąg oddzielony przecinkami jest przekazywany do SQL Server.