W części 1 tej serii użyłeś Flask i Connexion do stworzenia interfejsu API REST zapewniającego operacje CRUD w prostej strukturze w pamięci o nazwie PEOPLE . To zadziałało, aby zademonstrować, w jaki sposób moduł Connexion pomaga w tworzeniu ładnego interfejsu API REST wraz z interaktywną dokumentacją.
Jak niektórzy zauważyli w komentarzach do Części 1, PEOPLE struktura jest ponownie inicjowana przy każdym ponownym uruchomieniu aplikacji. W tym artykule dowiesz się, jak przechowywać PEOPLE struktury i działań zapewnianych przez API do bazy danych przy użyciu SQLAlchemy i Marshmallow.
SQLAlchemy udostępnia obiektowy model relacyjny (ORM), który przechowuje obiekty Pythona w reprezentacji bazy danych zawierającej dane obiektu. To może pomóc ci w dalszym myśleniu w pythoniczny sposób i nie martwić się o to, jak dane obiektu będą reprezentowane w bazie danych.
Marshmallow zapewnia funkcjonalność serializacji i deserializacji obiektów Pythona, gdy wychodzą one z i do naszego interfejsu API REST opartego na JSON. Marshmallow konwertuje instancje klas Pythona na obiekty, które można przekonwertować na JSON.
Kod Pythona do tego artykułu znajdziesz tutaj.
Bezpłatny bonus: Kliknij tutaj, aby pobrać kopię przewodnika „Przykłady API REST” i uzyskać praktyczne wprowadzenie do zasad Pythona + API REST wraz z praktycznymi przykładami.
Dla kogo jest ten artykuł
Jeśli podobała Ci się część 1 tej serii, ten artykuł jeszcze bardziej rozszerzy Twój pasek narzędziowy. Będziesz używać SQLAlchemy, aby uzyskać dostęp do bazy danych w sposób bardziej Pythonowy niż prosty SQL. Będziesz także używać Marshmallow do serializacji i deserializacji danych zarządzanych przez REST API. Aby to zrobić, będziesz korzystać z podstawowych funkcji programowania obiektowego dostępnych w Pythonie.
Będziesz także używać SQLAlchemy do tworzenia bazy danych oraz do interakcji z nią. Jest to konieczne, aby uruchomić REST API z PEOPLE dane użyte w Części 1.
Aplikacja internetowa przedstawiona w części 1 będzie miała swoje pliki HTML i JavaScript zmodyfikowane w drobny sposób, aby wspierać również zmiany. Tutaj możesz przejrzeć ostateczną wersję kodu z Części 1.
Dodatkowe zależności
Zanim zaczniesz budować tę nową funkcjonalność, musisz zaktualizować virtualenv, który utworzyłeś, aby uruchomić kod części 1, lub utworzyć nowy dla tego projektu. Najprostszym sposobem na zrobienie tego po aktywacji virtualenv jest uruchomienie tego polecenia:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
To dodaje więcej funkcji do wirtualnego środowiska:
-
Flask-SQLAlchemydodaje SQLAlchemy, wraz z niektórymi powiązaniami z Flask, umożliwiając programom dostęp do baz danych. -
flask-marshmallowdodaje części Flask Marshmallow, które pozwalają programom konwertować obiekty Pythona do i ze struktur możliwych do serializacji. -
marshmallow-sqlalchemydodaje kilka zaczepów Marshmallow do SQLAlchemy, aby umożliwić programom serializację i deserializację obiektów Pythona generowanych przez SQLAlchemy. -
marshmallowdodaje większość funkcji Marshmallow.
Dane osób
Jak wspomniano powyżej, PEOPLE Struktura danych w poprzednim artykule to słownik języka Python w pamięci. W tym słowniku użyłeś nazwiska osoby jako klucza wyszukiwania. Struktura danych w kodzie wyglądała tak:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Modyfikacje, które wprowadzisz w programie, przeniosą wszystkie dane do tabeli bazy danych. Oznacza to, że dane zostaną zapisane na dysku i będą istnieć między uruchomieniami server.py program.
Ponieważ nazwisko było kluczem w słowniku, kod ograniczał możliwość zmiany nazwiska osoby:można było zmienić tylko imię. Ponadto przejście do bazy danych umożliwi zmianę nazwiska, ponieważ nie będzie ono już używane jako klucz wyszukiwania osoby.
Koncepcyjnie tabelę bazy danych można traktować jako dwuwymiarową tablicę, w której wiersze są rekordami, a kolumny są polami w tych rekordach.
Tabele bazy danych zwykle mają automatycznie zwiększającą się wartość całkowitą jako klucz wyszukiwania wierszy. Nazywa się to kluczem podstawowym. Każdy rekord w tabeli będzie miał klucz podstawowy, którego wartość jest unikalna w całej tabeli. Posiadanie klucza podstawowego niezależnego od danych przechowywanych w tabeli pozwala modyfikować dowolne inne pola w rzędzie.
Uwaga:
Autoinkrementacja klucza podstawowego oznacza, że baza danych dba o:
- Zwiększanie największego istniejącego pola klucza podstawowego za każdym razem, gdy nowy rekord jest wstawiany do tabeli
- Używanie tej wartości jako klucza podstawowego dla nowo wstawionych danych
Gwarantuje to unikalny klucz podstawowy w miarę wzrostu tabeli.
Będziesz postępować zgodnie z konwencją bazy danych nazywania tabeli jako liczby pojedynczej, więc tabela będzie nazywać się person . Tłumaczenie naszych PEOPLE struktura powyżej do tabeli bazy danych o nazwie person daje ci to:
| person_id | Nazwa | fname | sygnatura czasowa |
|---|---|---|---|
| 1 | Farrel | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Wielkanoc | Królik | 2018-08-08 21:16:01.886834 |
Każda kolumna w tabeli ma nazwę pola w następujący sposób:
person_id: pole klucza podstawowego dla każdej osobylname: nazwisko osobyfname: imię osobytimestamp: znacznik czasu związany z czynnościami wstawiania/aktualizacji
Interakcja z bazą danych
Użyjesz SQLite jako silnika bazy danych do przechowywania PEOPLE dane. SQLite jest najbardziej rozpowszechnioną bazą danych na świecie i jest dostarczana z Pythonem za darmo. Jest szybki, wykonuje całą swoją pracę przy użyciu plików i nadaje się do bardzo wielu projektów. Jest to kompletny system zarządzania bazą danych RDBMS (Relational Database Management System), który obejmuje SQL, język wielu systemów baz danych.
Na chwilę wyobraź sobie person tabela już istnieje w bazie danych SQLite. Jeśli miałeś jakieś doświadczenie z RDBMS, prawdopodobnie znasz SQL, strukturalny język zapytań, którego większość systemów RDBMS używa do interakcji z bazą danych.
W przeciwieństwie do języków programowania, takich jak Python, SQL nie definiuje jak aby uzyskać dane:opisuje co dane są pożądane, pozostawiając jak do silnika bazy danych.
Zapytanie SQL pobierające wszystkie dane w naszej person tabela posortowana według nazwiska wyglądałaby tak:
SELECT * FROM person ORDER BY 'lname';
Zapytanie to mówi silnikowi bazy danych, aby pobrał wszystkie pola z tabeli osoby i posortował je w domyślnej kolejności rosnącej przy użyciu lname pole.
Gdybyś miał uruchomić to zapytanie w bazie danych SQLite zawierającej person tabeli, wynikiem byłby zestaw rekordów zawierający wszystkie wiersze w tabeli, przy czym każdy wiersz zawierałby dane ze wszystkich pól tworzących wiersz. Poniżej znajduje się przykład użycia narzędzia wiersza poleceń SQLite, które uruchamia powyższe zapytanie względem person tabela bazy danych:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Powyższe dane wyjściowe to lista wszystkich wierszy w person tabela bazy danych ze znakami kreskowymi („|”) oddzielającymi pola w wierszu, co jest wykonywane przez SQLite na potrzeby wyświetlania.
Python jest w pełni zdolny do łączenia się z wieloma silnikami baz danych i wykonywania powyższego zapytania SQL. Wynikiem najprawdopodobniej byłaby lista krotek. Zewnętrzna lista zawiera wszystkie rekordy w person stół. Każda pojedyncza wewnętrzna krotka zawierałaby wszystkie dane reprezentujące każde pole zdefiniowane dla wiersza tabeli.
Pobieranie danych w ten sposób nie jest zbyt Pythonowe. Lista rekordów jest w porządku, ale każdy pojedynczy rekord to tylko krotka danych. Od programu zależy znajomość indeksu każdego pola w celu pobrania konkretnego pola. Poniższy kod Pythona używa SQLite, aby zademonstrować, jak uruchomić powyższe zapytanie i wyświetlić dane:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Powyższy program wykonuje następujące czynności:
-
Wiersz 1 importuje
sqlite3moduł. -
Linia 3 tworzy połączenie z plikiem bazy danych.
-
Wiersz 4 tworzy kursor z połączenia.
-
Wiersz 5 używa kursora do wykonania
SQLzapytanie wyrażone jako ciąg. -
Linia 6 pobiera wszystkie rekordy zwrócone przez
SQLzapytanie i przypisuje je dopeoplezmienna. -
Linia 7 i 8 iteruj po
peoplewypisz zmienną i wydrukuj imię i nazwisko każdej osoby.
people zmienna z Wierszu 6 powyżej wyglądałoby tak w Pythonie:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Wynik działania powyższego programu wygląda tak:
Kent Brockman
Bunny Easter
Doug Farrell
W powyższym programie musisz wiedzieć, że imię osoby znajduje się w indeksie 2 , a nazwisko osoby znajduje się w indeksie 1 . Co gorsza, wewnętrzna struktura person musi być również znany za każdym razem, gdy przekazujesz zmienną iteracyjną person jako parametr funkcji lub metody.
Byłoby znacznie lepiej, gdyby to, co otrzymałeś dla person był obiektem Pythona, gdzie każde z pól jest atrybutem obiektu. To jedna z rzeczy, które robi SQLAlchemy.
Małe stoliki Bobby
W powyższym programie instrukcja SQL jest prostym ciągiem znaków przekazywanym bezpośrednio do bazy danych w celu wykonania. W tym przypadku nie stanowi to problemu, ponieważ SQL jest literałem łańcuchowym całkowicie pod kontrolą programu. Jednak przypadek użycia interfejsu API REST będzie pobierał dane wejściowe użytkownika z aplikacji sieci Web i używał ich do tworzenia zapytań SQL. Może to otworzyć twoją aplikację do ataku.
Przypomnij sobie z części 1, że REST API pozwala uzyskać jedną person od PEOPLE dane wyglądały tak:
GET /api/people/{lname}
Oznacza to, że Twój interfejs API oczekuje zmiennej lname , w ścieżce punktu końcowego adresu URL, której używa do znalezienia pojedynczej person . Zmodyfikowanie kodu Pythona SQLite z góry w tym celu wyglądałoby mniej więcej tak:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Powyższy fragment kodu wykonuje następujące czynności:
-
Wiersz 1 ustawia
lnamezmienna na'Farrell'. Pochodziłoby to ze ścieżki punktu końcowego adresu URL interfejsu API REST. -
Wiersz 2 używa formatowania napisów w Pythonie do tworzenia napisów SQL i ich wykonywania.
Aby wszystko było proste, powyższy kod ustawia lname zmienna na stałą, ale tak naprawdę pochodziłaby ze ścieżki punktu końcowego adresu URL interfejsu API i może być dowolną wartością podaną przez użytkownika. Kod SQL wygenerowany przez formatowanie ciągu wygląda tak:
SELECT * FROM person WHERE lname = 'Farrell'
Kiedy ten kod SQL jest wykonywany przez bazę danych, przeszukuje person tabela dla rekordu, w którym nazwisko jest równe 'Farrell' . To jest zamierzone, ale każdy program, który akceptuje dane wprowadzane przez użytkownika, jest również otwarty dla złośliwych użytkowników. W powyższym programie, gdzie lname zmienna jest ustawiana na podstawie danych wprowadzonych przez użytkownika, co otwiera program na tzw. atak wstrzyknięcia SQL. To jest pieszczotliwie nazywane Little Bobby Tables:
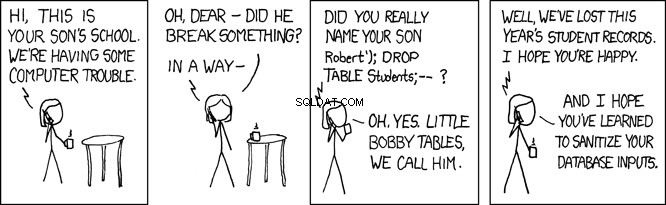
Na przykład wyobraź sobie złośliwego użytkownika o nazwie REST API w ten sposób:
GET /api/people/Farrell');DROP TABLE person;
Powyższe żądanie REST API ustawia lname zmienna na 'Farrell');DROP TABLE person;' , który w powyższym kodzie wygeneruje tę instrukcję SQL:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Powyższa instrukcja SQL jest poprawna i po wykonaniu przez bazę danych znajdzie jeden rekord, w którym lname pasuje do 'Farrell' . Następnie znajdzie znak ogranicznika instrukcji SQL ; i pójdzie prosto i porzuci cały stół. To zasadniczo zniszczyłoby twoją aplikację.
Możesz chronić swój program, oczyszczając wszystkie dane, które otrzymujesz od użytkowników aplikacji. Oczyszczanie danych w tym kontekście oznacza, że program sprawdza dane dostarczone przez użytkownika i upewnia się, że nie zawierają one niczego niebezpiecznego dla programu. Może to być trudne do wykonania we właściwy sposób i musiałoby być zrobione wszędzie tam, gdzie dane użytkownika wchodzą w interakcję z bazą danych.
Jest inny sposób, który jest znacznie prostszy:użyj SQLAlchemy. Oczyści dane użytkownika przed utworzeniem instrukcji SQL. To kolejna duża zaleta i powód, aby używać SQLAlchemy podczas pracy z bazami danych.
Modelowanie danych za pomocą SQLAlchemy
SQLAlchemy to duży projekt i zapewnia wiele funkcji do pracy z bazami danych przy użyciu Pythona. Jedną z rzeczy, które zapewnia, jest ORM, czyli Object Relational Mapper, i to jest to, czego będziesz używać do tworzenia i pracy z person tabela bazy danych. Pozwala to zmapować wiersz pól z tabeli bazy danych na obiekt Pythona.
Programowanie zorientowane obiektowo umożliwia łączenie danych wraz z zachowaniem, funkcjami, które operują na tych danych. Tworząc klasy SQLAlchemy, możesz połączyć pola z wierszy tabeli bazy danych z zachowaniem, umożliwiając interakcję z danymi. Oto definicja klasy SQLAlchemy dla danych w person tabela bazy danych:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Klasa Person dziedziczy z db.Model , do którego dojdziesz, gdy zaczniesz budować kod programu. Na razie oznacza to, że dziedziczysz po klasie bazowej o nazwie Model , zapewniając atrybuty i funkcje wspólne dla wszystkich klas z niego wywodzących się.
Pozostałe definicje to atrybuty na poziomie klasy zdefiniowane w następujący sposób:
-
__tablename__ = 'person'łączy definicję klasy zpersontabela bazy danych. -
person_id = db.Column(db.Integer, primary_key=True)tworzy kolumnę bazy danych zawierającą liczbę całkowitą pełniącą rolę klucza podstawowego dla tabeli. To również informuje bazę danych, żeperson_idbędzie automatycznie zwiększającą się wartością typu Integer. -
lname = db.Column(db.String)tworzy pole nazwiska, kolumnę bazy danych zawierającą wartość ciągu. -
fname = db.Column(db.String)tworzy pole imienia, kolumnę bazy danych zawierającą wartość ciągu. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)tworzy pole znacznika czasu, kolumnę bazy danych zawierającą wartość daty/czasu.default=datetime.utcnowparametr domyślnie ustawia wartość znacznika czasu na bieżącąutcnowwartość podczas tworzenia rekordu.onupdate=datetime.utcnowparametr aktualizuje znacznik czasu z bieżącymutcnowwartość, gdy rekord jest aktualizowany.
Uwaga:znaczniki czasu UTC
Być może zastanawiasz się, dlaczego znacznik czasu w powyższej klasie ma wartość domyślną i jest aktualizowany przez datetime.utcnow() metoda, która zwraca czas UTC lub uniwersalny czas koordynowany. Jest to sposób na standaryzację źródła sygnatury czasowej.
Źródłem lub czasem zerowym jest linia biegnąca na północ i południe od północnego do południowego bieguna Ziemi przez Wielką Brytanię. Jest to zerowa strefa czasowa, od której wszystkie inne strefy czasowe są przesunięte. Używając tego jako źródła czasu zerowego, Twoje znaczniki czasu są przesunięte względem tego standardowego punktu odniesienia.
Jeśli Twoja aplikacja jest dostępna z różnych stref czasowych, masz możliwość wykonania obliczeń daty/czasu. Wszystko czego potrzebujesz to znacznik czasu UTC i docelowa strefa czasowa.
Gdybyś miał użyć lokalnych stref czasowych jako źródła sygnatury czasowej, nie mógłbyś wykonać obliczeń daty/godziny bez informacji o lokalnych strefach czasowych przesuniętych od czasu zerowego. Bez informacji o źródle sygnatury czasowej nie można w ogóle porównywać daty/godziny ani wykonywać obliczeń.
Praca ze znacznikami czasu opartymi na UTC to dobry standard do naśladowania. Oto witryna z zestawem narzędzi do pracy i lepszego ich zrozumienia.
Dokąd zmierzasz z tą person definicja klasy? Ostatecznym celem jest możliwość uruchomienia zapytania przy użyciu SQLAlchemy i odzyskanie listy wystąpień Person klasa. Jako przykład spójrzmy na poprzednią instrukcję SQL:
SELECT * FROM people ORDER BY lname;
Pokaż ten sam mały przykładowy program z powyższego, ale teraz używający SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Ignorując na razie linię 1, chcesz tylko person rekordy posortowane w porządku rosnącym według lname pole. Co otrzymasz z instrukcji SQLAlchemy Person.query.order_by(Person.lname).all() to lista person obiekty dla wszystkich rekordów w person tabeli bazy danych w tej kolejności. W powyższym programie people zmienna zawiera listę person obiekty.
Program iteruje po people zmienna, biorąc każdą person kolejno i wydrukowanie imienia i nazwiska osoby z bazy danych. Zauważ, że program nie musi używać indeksów, aby uzyskać fname lub lname wartości:używa atrybutów zdefiniowanych w Person obiekt.
Używanie SQLAlchemy pozwala myśleć w kategoriach obiektów z zachowaniem, a nie surowego SQL . Staje się to jeszcze bardziej korzystne, gdy tabele bazy danych stają się większe, a interakcje bardziej złożone.
Serializowanie/deserializowanie modelowanych danych
Praca z danymi modelowanymi za pomocą SQLAlchemy w programach jest bardzo wygodna. Jest to szczególnie wygodne w programach manipulujących danymi, na przykład wykonujących obliczenia lub wykorzystujących je do tworzenia prezentacji na ekranie. Twoja aplikacja jest interfejsem API REST zasadniczo zapewniającym operacje CRUD na danych i jako taka nie wykonuje wielu manipulacji danymi.
Interfejs API REST działa z danymi JSON i tutaj możesz napotkać problem z modelem SQLAlchemy. Ponieważ dane zwracane przez SQLAlchemy są instancjami klas Pythona, Connexion nie może serializować tych instancji klas do danych w formacie JSON. Pamiętaj z części 1, że Connexion jest narzędziem, którego używałeś do projektowania i konfigurowania interfejsu API REST przy użyciu pliku YAML oraz łączenia z nim metod Pythona.
W tym kontekście serializacja oznacza konwersję obiektów Pythona, które mogą zawierać inne obiekty Pythona i złożone typy danych, na prostsze struktury danych, które można przetworzyć na typy danych JSON, które wymieniono tutaj:
string: typ ciągunumber: liczby obsługiwane przez Pythona (liczby całkowite, zmiennoprzecinkowe, długie)object: obiekt JSON, który jest mniej więcej odpowiednikiem słownika Pythonaarray: mniej więcej odpowiednik listy Pythonaboolean: reprezentowane w JSON jakotruelubfalse, ale w Pythonie jakoTruelubFalsenull: zasadniczoNonew Pythonie
Jako przykład, Twoja Person klasa zawiera znacznik czasu, którym jest Python DateTime . W JSON nie ma definicji daty/godziny, więc znacznik czasu musi zostać przekonwertowany na ciąg, aby istniał w strukturze JSON.
Twoja Person Klasa jest wystarczająco prosta, więc pobranie z niej atrybutów danych i ręczne utworzenie słownika do powrotu z naszych punktów końcowych adresu URL REST nie byłoby trudne. W bardziej złożonej aplikacji z wieloma większymi modelami SQLAlchemy tak nie byłoby. Lepszym rozwiązaniem jest użycie modułu o nazwie Marshmallow, który wykona tę pracę za Ciebie.
Marshmallow pomaga stworzyć PersonSchema klasa, która jest jak SQLAlchemy Person klasa, którą stworzyliśmy. Tutaj jednak, zamiast mapować tabele bazy danych i nazwy pól na klasę i jej atrybuty, PersonSchema class definiuje, w jaki sposób atrybuty klasy zostaną przekonwertowane na formaty przyjazne dla JSON. Oto definicja klasy Marshmallow dla danych w naszej person tabela:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Klasa PersonSchema dziedziczy z ma.ModelSchema , do którego dojdziesz, gdy zaczniesz budować kod programu. Na razie oznacza to PersonSchema dziedziczy z klasy bazowej Marshmallow o nazwie ModelSchema , zapewniając atrybuty i funkcje wspólne dla wszystkich klas z niego wywodzących się.
Reszta definicji jest następująca:
-
class Metadefiniuje klasę o nazwieMetaw twojej klasie.ModelSchemaklasy, którąPersonSchemaklasa dziedziczy po wyglądach tej wewnętrznejMetai używa jej do znalezienia modelu SQLAlchemyPersonidb.session. W ten sposób Marshmallow znajduje atrybuty wPersonklasę i typ tych atrybutów, aby wiedział, jak je serializować/deserializować. -
modelmówi klasie, jakiego modelu SQLAlchemy użyć do serializacji/deserializacji danych do iz. -
db.sessionmówi klasie, jakiej sesji bazy danych użyć do introspekcji i określenia typów danych atrybutów.
Dokąd zmierzasz z tą definicją klasy? Chcesz mieć możliwość serializacji wystąpienia person klasy do danych JSON oraz do deserializacji danych JSON i utworzenia Person instancje klas z niego.
Utwórz zainicjowaną bazę danych
SQLAlchemy obsługuje wiele interakcji specyficznych dla poszczególnych baz danych i pozwala skoncentrować się na modelach danych oraz na tym, jak z nich korzystać.
Teraz, gdy zamierzasz utworzyć bazę danych, jak wspomniano wcześniej, użyjesz SQLite. Robisz to z kilku powodów. Jest dostarczany z Pythonem i nie musi być instalowany jako oddzielny moduł. Zapisuje wszystkie informacje z bazy danych w jednym pliku, dzięki czemu jest łatwy w konfiguracji i obsłudze.
Zainstalowanie oddzielnego serwera bazy danych, takiego jak MySQL lub PostgreSQL, działałoby dobrze, ale wymagałoby zainstalowania tych systemów i uruchomienia ich, co wykracza poza zakres tego artykułu.
Ponieważ SQLAlchemy obsługuje bazę danych, pod wieloma względami tak naprawdę nie ma znaczenia, jaka jest baza danych.
Zamierzasz utworzyć nowy program narzędziowy o nazwie build_database.py aby utworzyć i zainicjować SQLite people.db plik bazy danych zawierający Twoją person tabela bazy danych. Po drodze utworzysz dwa moduły Pythona, config.py i models.py , który będzie używany przez build_database.py i zmodyfikowany server.py z części 1.
Oto, gdzie możesz znaleźć kod źródłowy modułów, które zamierzasz utworzyć, które są przedstawione tutaj:
-
config.pypobiera niezbędne moduły zaimportowane do programu i skonfigurowane. Obejmuje to Flask, Connexion, SQLAlchemy i Marshmallow. Ponieważ będzie używany zarówno przezbuild_database.pyiserver.py, niektóre części konfiguracji będą dotyczyć tylkoserver.pyaplikacji. -
models.pyto moduł, w którym utworzyszpersonSQLAlchemy iPersonSchemaDefinicje klas Marshmallow opisane powyżej. Ten moduł jest zależny odconfig.pydla niektórych obiektów tam utworzonych i skonfigurowanych.
Moduł konfiguracyjny
config.py moduł, jak sama nazwa wskazuje, jest miejscem, w którym tworzone i inicjowane są wszystkie informacje konfiguracyjne. Będziemy używać tego modułu zarówno dla naszego build_database.py plik programu i wkrótce zostanie zaktualizowany server.py plik z części 1. artykułu. Oznacza to, że skonfigurujemy tutaj Flask, Connexion, SQLAlchemy i Marshmallow.
Mimo że build_database.py program nie korzysta z Flask, Connexion ani Marshmallow, używa SQLAlchemy do tworzenia naszego połączenia z bazą danych SQLite. Oto kod dla config.py moduł:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Oto, co robi powyższy kod:
-
Linie 2–4 zaimportuj Connexion tak jak w pliku
server.pyprogram z części 1. Importuje równieżSQLAlchemyzflask_sqlalchemymoduł. Daje to dostęp do bazy danych programu. Na koniec importujeMarshmallowzflask_marshamllowmoduł. -
Linia 6 tworzy zmienną
basedirwskazując na katalog, w którym działa program. -
Linia 9 używa
basedirzmienna, aby utworzyć instancję aplikacji Connexion i nadać jej ścieżkę doswagger.ymlplik. -
Linia 12 tworzy zmienną
app, czyli instancja Flask zainicjowana przez Connexion. -
Linie 15 używa
appzmienna do konfiguracji wartości używanych przez SQLAlchemy. Najpierw ustawiaSQLALCHEMY_ECHOnaTrue. Powoduje to, że SQLAlchemy wyświetla na konsoli polecenia SQL, które wykonuje. Jest to bardzo przydatne do debugowania problemów podczas tworzenia programów bazodanowych. Ustaw to naFalsedla środowisk produkcyjnych. -
Linia 16 ustawia
SQLALCHEMY_DATABASE_URIdosqlite:////' + os.path.join(basedir, 'people.db'). To mówi SQLAlchemy, aby używał SQLite jako bazy danych i pliku o nazwiepeople.dbw bieżącym katalogu jako plik bazy danych. Różne silniki baz danych, takie jak MySQL i PostgreSQL, będą miały różneSQLALCHEMY_DATABASE_URIciągi do ich konfiguracji. -
Linia 17 ustawia
SQLALCHEMY_TRACK_MODIFICATIONSnaFalse, wyłączając system zdarzeń SQLAlchemy, który jest domyślnie włączony. System zdarzeń generuje zdarzenia przydatne w programach sterowanych zdarzeniami, ale powoduje znaczne obciążenie. Ponieważ nie tworzysz programu sterowanego zdarzeniami, wyłącz tę funkcję. -
Linia 19 tworzy
dbzmienna przez wywołanieSQLAlchemy(app). To inicjuje SQLAlchemy przez przekazanieappinformacje o konfiguracji właśnie ustawione.dbzmienna jest importowana dobuild_database.pyprogram, aby dać mu dostęp do SQLAlchemy i bazy danych. Będzie służył temu samemu celowi wserver.pyprogram ipeople.pymoduł. -
Linia 23 tworzy
mazmienna, wywołującMarshmallow(app). To inicjuje Marshmallow i umożliwia introspekcję składników SQLAlchemy dołączonych do aplikacji. Dlatego Marshmallow jest inicjowany po SQLAlchemy.
Modele
Module
models.py moduł jest tworzony w celu zapewnienia person i PersonSchema klasy dokładnie tak, jak opisano w powyższych sekcjach dotyczących modelowania i serializacji danych. Oto kod tego modułu:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Oto, co robi powyższy kod:
-
Wiersz 1 importuje
datetimeobiekt zdatetimemoduł dostarczany z Pythonem. Daje to możliwość utworzenia znacznika czasu wPersonklasa. -
Wiersz 2 importuje
dbimazmienne instancji zdefiniowane wconfig.pymoduł. Daje to modułowi dostęp do atrybutów i metod SQLAlchemy dołączonych dodbzmiennej oraz atrybuty i metody Marshmallow dołączone domazmienna. -
Linie 4–9 zdefiniuj
personklasy, jak omówiono w sekcji modelowania danych powyżej, ale teraz wiesz, gdzie znajduje siędb.Modelże klasa dziedziczy po źródłach. To dajePersonklasy SQLAlchemy, takie jak połączenie z bazą danych i dostęp do jej tabel. -
Linie 11-14 zdefiniuj
PersonSchemaklasy, jak omówiono w sekcji serializacji danych powyżej. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodule.dbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonklasa. After it is instantiated, you call thedb.session.add(p)funkcjonować. This uses the database connection instancedbto access thesessionobiekt. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobiekt. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Uwaga: At Line 22, no data has been added to the database. Everything is being saved within the session obiekt. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py plik. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname wartość.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Opis |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people stół. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelist. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Uwaga: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person Baza danych. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person obiekt. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} Sekcja. This section of the UI gets a single person from the database and looks like this:
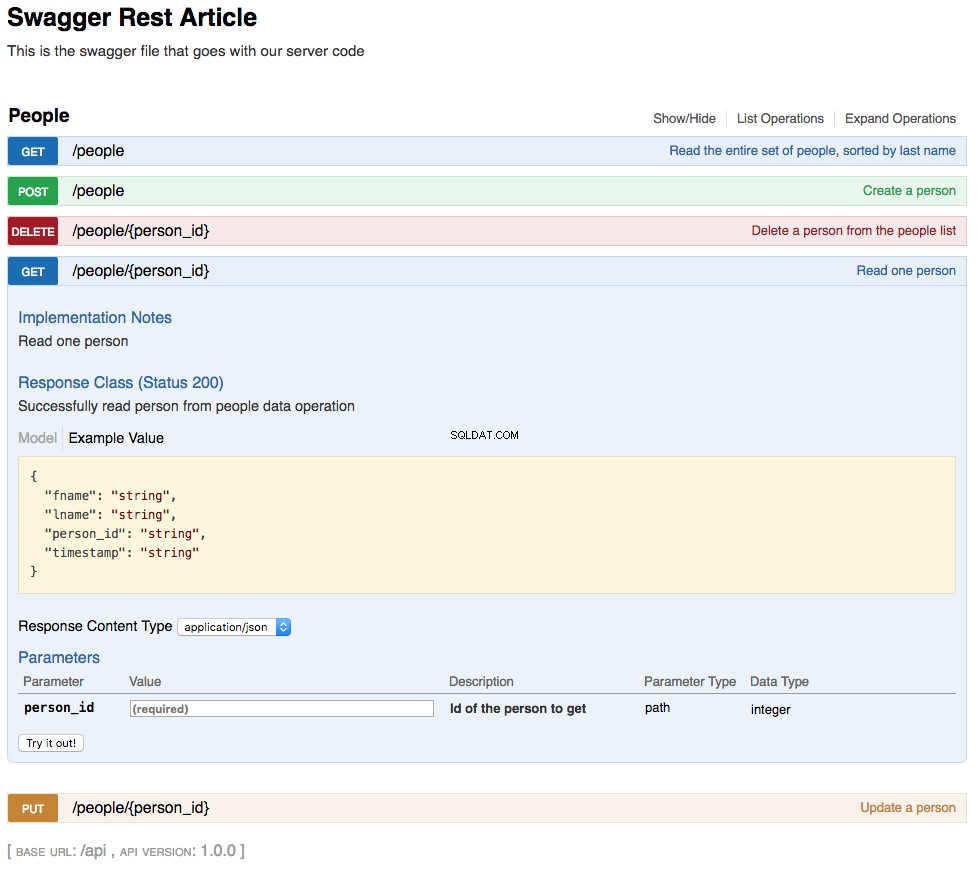
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Wniosek
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.