Programista Oracle, który często używa w kodzie wyrażeń regularnych, prędzej czy później może stawić czoła zjawisku, które jest rzeczywiście mistyczne. Długotrwałe poszukiwanie źródła problemu może prowadzić do utraty wagi, apetytu i wywołać różnego rodzaju zaburzenia psychosomatyczne – temu wszystkiemu można zapobiec za pomocą funkcji regexp_replace. Może mieć do 6 argumentów:
REGEXP_REPLACE (
- ciąg_źródłowy,
- szablon,
- substitution_string,
- pozycja początkowa wyszukiwania dopasowania z szablonem (domyślnie 1),
- pozycja wystąpienia szablonu w ciągu źródłowym (domyślnie 0 równa się wszystkim wystąpieniom),
- modyfikator (na razie jest to ciemny koń)
)
Zwraca zmodyfikowany ciąg_źródłowy, w którym wszystkie wystąpienia szablonu są zastępowane wartością przekazaną w parametrze substituting_string. Często używana jest skrócona wersja funkcji, w której określone są pierwsze 3 argumenty, co wystarcza do rozwiązania wielu problemów. Zrobię to samo. Załóżmy, że musimy zamaskować wszystkie znaki ciągu za pomocą gwiazdek w ciągu „MASK:małe litery”. Aby określić zakres małych liter, wzorzec „[a-z]” powinien pasować.
wybierz regexp_replace('MASK:małe litery', '[a-z]', '*') jako wynik z podwójnego Oczekiwanie
+------------------+| WYNIK |+------------------+| MASKA:***** **** |+------------------+
Rzeczywistość
+------------------+| WYNIK |+------------------+| *A**:***** **** |+------------------+
Jeśli to wydarzenie nie zostało odtworzone w Twojej bazie danych, to jak dotąd masz szczęście. Ale częściej zaczynasz kopać w kodzie, konwertować ciągi znaków z jednego zestawu znaków na inny i ostatecznie pojawia się rozpacz.
Definiowanie problemu
Nasuwa się pytanie – co jest takiego specjalnego w literze „A”, że nie została ona zastąpiona, ponieważ pozostałe wielkie litery również nie miały zostać zastąpione. Może istnieją inne poprawne litery oprócz tej. Konieczne jest przejrzenie całego alfabetu wielkich liter.
wybierz regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') jako alfabet z podwójnego+-------------------------- --+| ALFABET |+-----------------------------+| A************************* |+---------------------- ------+ Jednak
Jeśli szósty argument funkcji nie jest wyraźnie określony, na przykład 'i' oznacza rozróżnianie wielkości liter lub 'c' oznacza rozróżnianie wielkości liter podczas porównywania ciągu źródłowego z szablonem, wyrażenie regularne używa domyślnie parametru NLS_SORT sesji/bazy danych. Na przykład:
Ten parametr określa metodę sortowania w ORDER BY. Jeśli mówimy o sortowaniu prostych pojedynczych znaków, to każdemu z nich odpowiada pewna liczba binarna (kod NLSSORT), a sortowanie faktycznie odbywa się według wartości tych liczb.
Aby to zilustrować, weźmy kilka pierwszych i ostatnich znaków alfabetu, zarówno małych, jak i wielkich, i umieśćmy je w warunkowo nieuporządkowanym zestawie tabel i nazwijmy go ABC. Następnie posortujmy ten zestaw według pola SYMBOL i wyświetlmy jego kod NLSSORT w formacie HEX obok każdego symbolu.
z ABC jako ( wybierz column_value jako symbol z table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b', 'c', 'x', 'y', 'z')))wybierz symbol, nlssort(symbol) nls_code_hexfrom ABCporządek według symbolu
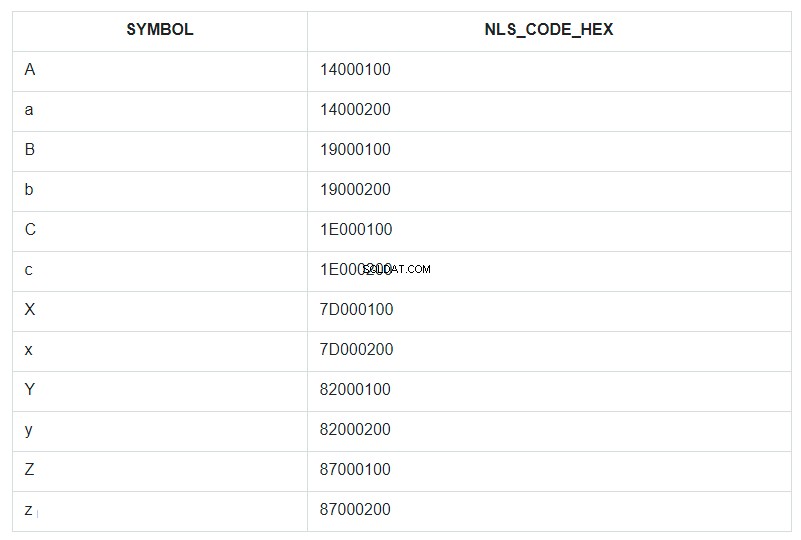
W zapytaniu ORDER BY jest określone dla pola SYMBOL, ale w rzeczywistości w bazie danych sortowanie przebiegało według wartości z pola NLS_CODE_HEX.
Teraz wróć do zakresu z szablonu i spójrz na tabelę – co jest w pionie między symbolem „a” (kod 14000200) a „z” (kod 87000200)? Wszystko poza wielką literą „A”. To wszystko, co zostało zastąpione gwiazdką. Kod 14000100 litery „A” nie jest zawarty w zakresie zastępczym od 14000200 do 87000200.
Wyleczenie
Wyraźnie określ modyfikator wielkości liter
wybierz regexp_replace('MASK:małe litery', '[a-z]', '*', 1, 0, 'c') z dual+----------------- -+| WYNIK |+------------------+| MASKA:***** **** |+------------------+ Niektóre źródła podają, że modyfikator „c” jest ustawiony domyślnie, ale właśnie widzieliśmy, że to nie do końca prawda. A jeśli ktoś tego nie widział, to parametr NLS_SORT jego sesji/bazy danych jest najprawdopodobniej ustawiony na BINARY i sortowanie odbywa się zgodnie z rzeczywistymi kodami znaków. Rzeczywiście, jeśli zmienisz parametr sesji, problem zostanie rozwiązany.
ALTER SESSION SET NLS_SORT=BINARY;wybierz regexp_replace('MASK:małe litery', '[a-z]', '*') jako wynik z podwójnego+---------------- --+| WYNIK |+------------------+| MASKA:***** **** |+------------------+ Testy zostały przeprowadzone w Oracle 12c.
Możesz zostawić swoje komentarze i uważać.