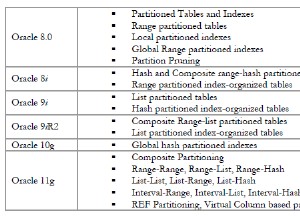
To nie jest problem z MERGE jako takim. Raczej problem leży w twojej aplikacji. Rozważ tę procedurę składowaną:
create or replace procedure upsert_t23
( p_id in t23.id%type
, p_name in t23.name%type )
is
cursor c is
select null
from t23
where id = p_id;
dummy varchar2(1);
begin
open c;
fetch c into dummy;
if c%notfound then
insert into t23
values (p_id, p_name);
else
update t23
set name = p_name
where id = p_id;
end if;
end;
Jest to więc odpowiednik MERGE w PL/SQL na T23. Co się stanie, jeśli dwie sesje wywołają to jednocześnie?
SSN1> exec upsert_t23(100, 'FOX IN SOCKS')
SSN2> exec upsert_t23(100, 'MR KNOX')
SSN1 dostaje się tam jako pierwszy, nie znajduje pasującego rekordu i wstawia rekord. SSN2 dociera tam na drugim miejscu, ale przed zatwierdzeniem SSN1 nie znajduje żadnego rekordu, wstawia rekord i zawiesza się ponieważ SSN1 ma blokadę na unikalnym węźle indeksu na 100. Gdy SSN1 zatwierdzi SSN2 rzuci naruszenie DUP_VAL_ON_INDEX.
Instrukcja MERGE działa dokładnie w ten sam sposób. Obie sesje będą sprawdzać on (t23.id = 100) , nie znajdź go i przejdź do gałęzi INSERT. Pierwsza sesja zakończy się sukcesem, a druga rzuci ORA-00001.
Jednym ze sposobów poradzenia sobie z tym jest wprowadzenie pesymistycznego blokowania. Na początku procedury UPSERT_T23 blokujemy tabelę:
...
lock table t23 in row shared mode nowait;
open c;
...
Teraz przybywa SSN1, chwyta zamek i postępuje jak poprzednio. Kiedy SSN2 nadejdzie, nie może uzyskać blokady, więc natychmiast ulega awarii. Co jest frustrujące dla drugiego użytkownika, ale przynajmniej nie zawiesza się, a ponadto wie, że ktoś inny pracuje nad tym samym rekordem.
Nie ma składni INSERT, która jest odpowiednikiem SELECT ... FOR UPDATE, ponieważ nie ma nic do wybrania. I tak też nie ma takiej składni dla MERGE. To, co musisz zrobić, to dołączyć instrukcję LOCK TABLE do jednostki programu, która wydaje MERGE. To, czy jest to możliwe, zależy od używanego frameworka.