To dość powszechny problem.
Zwykłe B-Tree indeksy nie są dobre dla zapytań takich jak to:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Indeks jest dobry do wyszukiwania wartości w podanych granicach, na przykład:
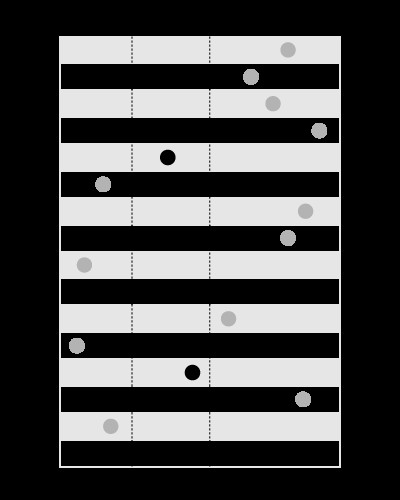
, ale nie do wyszukiwania granic zawierających podaną wartość, tak jak to:
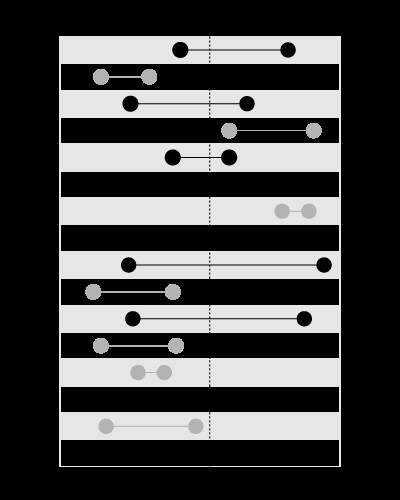
Ten artykuł na moim blogu bardziej szczegółowo wyjaśnia problem:
(model zagnieżdżonych zbiorów zajmuje się podobnym typem predykatu).
Indeks można utworzyć time , w ten sposób intervals będzie wiodący w łączeniu, czas z przedziału będzie używany wewnątrz zagnieżdżonych pętli. Będzie to wymagało sortowania według time .
Możesz utworzyć indeks przestrzenny w intervals (dostępne w MySQL używając MyISAM przechowywania), który zawierałby start i end w jednej kolumnie geometrii. W ten sposób measures może prowadzić w łączeniu i nie będzie potrzebne sortowanie.
Indeksy przestrzenne są jednak wolniejsze, więc będzie to skuteczne tylko wtedy, gdy masz niewiele miar, ale wiele interwałów.
Ponieważ masz niewiele interwałów, ale wiele miar, po prostu upewnij się, że masz indeks na measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Aktualizacja:
Oto przykładowy skrypt do przetestowania:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
To zapytanie:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
używa NESTED LOOPS i zwraca w 1.7 sekund.
To zapytanie:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
używa MERGE JOIN i musiałem to zatrzymać po 5 minut.
Aktualizacja 2:
Najprawdopodobniej będziesz musiał zmusić silnik do używania prawidłowej kolejności tabel w łączeniu, używając podpowiedzi takiej jak ta:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle Optymalizator nie jest wystarczająco sprytny, aby zobaczyć, że interwały się nie przecinają. Dlatego najprawdopodobniej użyje measures jako wiodący stół (co byłoby mądrą decyzją, gdyby przedziały się przecinały).
Aktualizacja 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
To zapytanie dzieli oś czasu na zakresy i używa HASH JOIN aby połączyć miary i znaczniki czasu z wartościami zakresu, z dokładnym filtrowaniem później.
Zobacz ten artykuł na moim blogu, aby uzyskać bardziej szczegółowe wyjaśnienia, jak to działa: