Indeks pomocniczy może potencjalnie pomóc uniknąć konieczności jawnego sortowania w planie zapytania podczas optymalizacji zapytań T-SQL dotyczących funkcji okna. Przez indeks pomocniczy Mam na myśli jedną z elementami partycjonowania i porządkowania okna jako klucz indeksu, a resztę kolumn, które pojawiają się w zapytaniu jako kolumny zawierające indeks. Często nazywam taki wzorzec indeksowania POC indeks jako akronim dla partycjonowania , zamawianie, i przykrycie . Oczywiście, jeśli element partycjonujący lub porządkujący nie pojawia się w funkcji okna, pomijasz tę część w definicji indeksu.
Ale co z zapytaniami obejmującymi wiele funkcji okien z różnymi potrzebami porządkowania? Podobnie, co jeśli inne elementy w zapytaniu oprócz funkcji okna również wymagają uporządkowania danych wejściowych zgodnie z kolejnością w planie, np. klauzula prezentacji ORDER BY? Może to spowodować, że różne części planu będą musiały przetworzyć dane wejściowe w różnej kolejności.
W takich okolicznościach zazwyczaj akceptujesz jawne sortowanie jako nieuniknione w planie. Może się okazać, że układ składni wyrażeń w zapytaniu może wpływać na ile wyraźne operatory sortowania, które dostajesz w planie. Postępując zgodnie z kilkoma podstawowymi wskazówkami, możesz czasami zmniejszyć liczbę jawnych operatorów sortowania, co oczywiście może mieć duży wpływ na wydajność zapytania.
Środowisko dla wersji demonstracyjnych
W moich przykładach użyję przykładowej bazy danych PerformanceV5. Tutaj możesz pobrać kod źródłowy, aby utworzyć i wypełnić tę bazę danych.
Wszystkie przykłady uruchomiłem na SQL Server 2019 Developer, gdzie dostępny jest tryb wsadowy w rowstore.
W tym artykule chcę skupić się na wskazówkach dotyczących potencjału obliczania funkcji okna w planie do polegania na uporządkowanych danych wejściowych bez konieczności dodatkowej jawnej czynności sortowania w planie. Ma to znaczenie, gdy optymalizator używa szeregowego lub równoległego traktowania funkcji okna w trybie wierszowym oraz gdy używa szeregowego operatora Window Aggregate w trybie wsadowym.
SQL Server nie obsługuje obecnie wydajnej kombinacji równoległych danych wejściowych z zachowaniem kolejności przed równoległym operatorem Window Aggregate w trybie wsadowym. Tak więc, aby użyć równoległego operatora Window Aggregate działającego w trybie wsadowym, optymalizator musi wprowadzić pośredniczący równoległy operator sortowania działający w trybie wsadowym, nawet jeśli dane wejściowe są już zamówione w przedsprzedaży.
Dla uproszczenia możesz zapobiec równoległości we wszystkich przykładach pokazanych w tym artykule. Aby to osiągnąć bez konieczności dodawania wskazówki do wszystkich zapytań i bez ustawiania opcji konfiguracji dla całego serwera, można ustawić opcję konfiguracji w zakresie bazy danych MAXDOP do 1 , jak tak:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Pamiętaj, aby ustawić go z powrotem na 0 po zakończeniu testowania przykładów w tym artykule. Przypomnę na koniec.
Alternatywnie można zapobiec równoległości na poziomie sesji za pomocą nieudokumentowanego DBCC OPTIMIZER_WHATIF polecenie, jak na przykład:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Aby zresetować opcję, gdy skończysz, wywołaj ją ponownie z wartością 0 jako liczbą procesorów.
Kiedy skończysz wypróbowywać wszystkie przykłady w tym artykule z wyłączonym paralelizmem, zalecam włączenie paralelizmu i ponowne wypróbowanie wszystkich przykładów, aby zobaczyć, jakie zmiany.
Wskazówki 1 i 2
Zanim zacznę od wskazówek, spójrzmy najpierw na prosty przykład z funkcją okna zaprojektowaną tak, aby korzystać z supp class="border indent shadow orting index.
Rozważ następujące zapytanie, które będę nazywać Zapytanie 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Nie przejmuj się tym, że przykład jest wymyślony. Nie ma żadnego sensownego powodu biznesowego, aby obliczyć bieżącą sumę identyfikatorów zamówień — ta tabela ma przyzwoity rozmiar z 1 MM wierszy, a chciałem pokazać prosty przykład ze wspólną funkcją okna, taką jak ta, która stosuje obliczanie bieżącej sumy.
Zgodnie ze schematem indeksowania POC, tworzysz następujący indeks do obsługi zapytania:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Plan dla tego zapytania pokazano na rysunku 1.
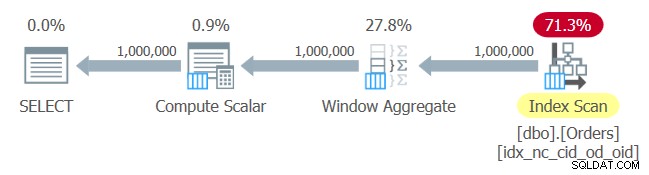 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Tutaj nie ma niespodzianek. Plan stosuje skanowanie kolejności indeksów właśnie utworzonego indeksu, dostarczając dane uporządkowane operatorowi Window Aggregate, bez potrzeby jawnego sortowania.
Następnie rozważmy następujące zapytanie, które obejmuje wiele funkcji okna o różnych potrzebach porządkowania, a także klauzulę prezentacji ORDER BY:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Będę nazywał to zapytanie Zapytanie 2. Plan dla tego zapytania pokazano na rysunku 2.
 Rysunek 2:Plan dla zapytania 2
Rysunek 2:Plan dla zapytania 2
Zauważ, że w planie są cztery operatory sortowania.
Jeśli przeanalizujesz różne funkcje okien i potrzeby w zakresie porządkowania prezentacji, odkryjesz, że istnieją trzy różne potrzeby w zakresie porządkowania:
- cusid, orderdate, orderid
- identyfikator zamówienia
- identyfikator klienta, identyfikator zamówienia
Biorąc pod uwagę, że jeden z nich (pierwszy na powyższej liście) może być obsługiwany przez utworzony wcześniej indeks, można by oczekiwać, że w planie pojawią się tylko dwa rodzaje. Dlaczego więc plan ma cztery rodzaje? Wygląda na to, że SQL Server nie próbuje być zbyt wyrafinowany, zmieniając kolejność przetwarzania funkcji w planie, aby zminimalizować sortowanie. Przetwarza funkcje w planie w kolejności, w jakiej pojawiają się w zapytaniu. Tak jest przynajmniej w przypadku pierwszego wystąpienia każdej odrębnej potrzeby porządkowania, ale omówię to wkrótce.
Możesz usunąć potrzebę niektórych rodzajów planu, stosując następujące dwie proste praktyki:
Wskazówka 1:Jeśli masz indeks obsługujący niektóre funkcje okna w zapytaniu, określ je najpierw.
Wskazówka 2:Jeśli zapytanie obejmuje funkcje okien z taką samą potrzebą porządkowania jak porządkowanie prezentacji w zapytaniu, określ te funkcje na końcu.
Postępując zgodnie z tymi wskazówkami, zmieniasz kolejność wyglądu funkcji okna w zapytaniu w następujący sposób:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Będę nazywał to zapytanie Zapytanie 3. Plan dla tego zapytania pokazano na rysunku 3.
 Rysunek 3:Plan dla zapytania 3
Rysunek 3:Plan dla zapytania 3
Jak widać, plan ma teraz tylko dwa rodzaje.
Wskazówka 3
SQL Server nie próbuje być zbyt wyrafinowany w zmienianiu kolejności przetwarzania funkcji okna w celu zminimalizowania sortowania w planie. Jest jednak w stanie dokonać pewnej prostej rearanżacji. Skanuje funkcje okna w oparciu o kolejność wyglądu w zapytaniu i za każdym razem, gdy wykryje nową, odrębną potrzebę uporządkowania, wyszukuje dodatkowe funkcje okna o tej samej potrzebie uporządkowania, a jeśli je znajdzie, grupuje je razem z pierwszym wystąpieniem. W niektórych przypadkach może nawet użyć tego samego operatora do obliczenia wielu funkcji okna.
Rozważ następujące zapytanie jako przykład:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Będę nazywał to zapytanie Query 4. Plan dla tego zapytania pokazano na rysunku 4.
 Rysunek 4:Plan dla zapytania 4
Rysunek 4:Plan dla zapytania 4
Funkcje okien o tych samych potrzebach porządkowania nie są grupowane w zapytaniu. Jednak w planie są jeszcze tylko dwa rodzaje. Dzieje się tak, ponieważ to, co liczy się jako kolejność przetwarzania w planie, to pierwsze wystąpienie każdej odrębnej potrzeby zamówienia. To prowadzi mnie do trzeciej wskazówki.
Wskazówka 3:Postępuj zgodnie ze wskazówkami 1 i 2 przy pierwszym wystąpieniu każdej odrębnej potrzeby zamówienia. Kolejne wystąpienia tej samej potrzeby porządkowej, nawet jeśli nie sąsiadują, są identyfikowane i grupowane razem z pierwszym.
Wskazówki 4 i 5
Załóżmy, że chcesz w wyniku zwrócić kolumny wynikające z obliczeń w oknie w określonej kolejności od lewej do prawej. Ale co, jeśli kolejność nie jest taka sama jak kolejność, która zminimalizuje sortowanie w planie?
Załóżmy na przykład, że chcesz uzyskać taki sam wynik, jak w zapytaniu 2 pod względem kolejności kolumn od lewej do prawej w danych wyjściowych (kolejność kolumn:inne kolumny, sum2, sum1, sum3), ale wolisz taki sam plan jak ten, który otrzymałeś dla zapytania 3 (kolejność kolumn:inne kolumny, sum1, sum3, sum2), który ma dwa sortowania zamiast czterech.
Jest to całkowicie wykonalne, jeśli znasz czwartą wskazówkę.
Wskazówka 4:Powyższe zalecenia dotyczą kolejności wyglądu funkcji okna w kodzie, nawet jeśli w nazwanym wyrażeniu tabelowym, takim jak CTE lub widok, i nawet jeśli zewnętrzne zapytanie zwraca kolumny w innej kolejności niż w nazwane wyrażenie tabeli. W związku z tym, jeśli musisz zwrócić kolumny w określonej kolejności w danych wyjściowych i różni się ona od optymalnej kolejności pod względem minimalizowania sortowań w planie, postępuj zgodnie ze wskazówkami dotyczącymi kolejności wyświetlania w nazwanym wyrażeniu tabeli i zwróć kolumny w zewnętrznym zapytaniu w żądanej kolejności wyników.
Poniższe zapytanie, które będę nazywać Zapytanie 5, ilustruje tę technikę:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Plan dla tego zapytania pokazano na rysunku 5.
 Rysunek 5:Plan dla zapytania 5
Rysunek 5:Plan dla zapytania 5
Nadal otrzymujesz tylko dwa sortowania w planie, mimo że kolejność kolumn na wyjściu to:inne kolumny, sum2, sum1, sum3, jak w zapytaniu 2.
Jedynym zastrzeżeniem dotyczącym tej sztuczki z nazwanym wyrażeniem tabeli jest to, że jeśli do kolumn w wyrażeniu tabeli nie odwołuje się zapytanie zewnętrzne, są one wykluczone z planu i dlatego nie są liczone.
Rozważ następujące zapytanie, które będę nazywać Zapytanie 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; W tym przypadku do wszystkich kolumn wyrażeń tabelowych odwołuje się zapytanie zewnętrzne, więc optymalizacja odbywa się na podstawie pierwszego odrębnego wystąpienia każdej potrzeby porządkowania w wyrażeniu tabelowym:
- max1:identyfikator klienta, data zamówienia, identyfikator zamówienia
- max3:id zamówienia
- max2:identyfikator klienta, identyfikator zamówienia
Daje to plan z tylko dwoma rodzajami, jak pokazano na rysunku 6.
 Rysunek 6:Plan dla zapytania 6
Rysunek 6:Plan dla zapytania 6
Teraz zmień tylko zewnętrzne zapytanie, usuwając referencje do max2, max1, max3, avg2, avg1 i avg3, w ten sposób:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Będę nazywał to zapytanie Zapytanie 7. Obliczenia max1, max3, max2, avg1, avg3 i avg2 w wyrażeniu tabelowym nie mają związku z zapytaniem zewnętrznym, więc są wykluczone. Pozostałe obliczenia dotyczące funkcji okna w wyrażeniu tabelowym, które są istotne dla zapytania zewnętrznego, to obliczenia sum2, sum1 i sum3. Niestety nie pojawiają się one w wyrażeniu tabelowym w optymalnej kolejności pod względem minimalizowania sortowań. Jak widać w planie dla tego zapytania, jak pokazano na rysunku 7, istnieją cztery rodzaje.
 Rysunek 7:Plan dla zapytania 7
Rysunek 7:Plan dla zapytania 7
Jeśli myślisz, że jest mało prawdopodobne, że w zapytaniu wewnętrznym pojawią się kolumny, do których nie odniesiesz się w zapytaniu zewnętrznym, pomyśl o widokach. Za każdym razem, gdy wysyłasz zapytanie do widoku, możesz być zainteresowany innym podzbiorem kolumn. Mając to na uwadze, piąta wskazówka może pomóc w zmniejszeniu sortowań w planie.
Wskazówka 5:W wewnętrznym zapytaniu nazwanego wyrażenia tabelowego, takiego jak CTE lub widok, zgrupuj razem wszystkie funkcje okna o tych samych potrzebach porządkowania i postępuj zgodnie ze wskazówkami 1 i 2 w kolejności grup funkcji.
Poniższy kod implementuje widok oparty na tej rekomendacji:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Teraz zapytaj widok żądający tylko okienkowych kolumn wyników sum2, sum1 i sum3, w tej kolejności:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Będę nazywał to zapytanie Zapytanie 8. Otrzymasz plan pokazany na rysunku 8 z tylko dwoma rodzajami.
 Rysunek 8:Plan dla zapytania 8
Rysunek 8:Plan dla zapytania 8
Wskazówka 6
Kiedy masz zapytanie z wieloma funkcjami okna z wieloma różnymi potrzebami porządkowania, powszechnie wiadomo, że możesz obsługiwać tylko jedną z nich za pomocą wstępnie uporządkowanych danych za pośrednictwem indeksu. Dzieje się tak nawet wtedy, gdy wszystkie funkcje okna mają odpowiednie indeksy pomocnicze.
Pokażę to. Przypomnij sobie wcześniej, kiedy utworzyłeś indeks idx_nc_cid_od_oid, który może obsługiwać funkcje okna wymagające danych uporządkowanych według custid, orderdate, orderid, takich jak następujące wyrażenie:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Załóżmy, że oprócz tej funkcji okna potrzebujesz również następującej funkcji okna w tym samym zapytaniu:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Ta funkcja okna skorzystałaby z następującego indeksu:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
Poniższe zapytanie, które będę nazywać Zapytanie 9, wywołuje obie funkcje okna:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Plan dla tego zapytania pokazano na rysunku 9.
 Rysunek 9:Plan dla zapytania 9
Rysunek 9:Plan dla zapytania 9
Na moim komputerze otrzymuję następujące statystyki czasu dla tego zapytania, a wyniki są odrzucane w SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Jak wyjaśniono wcześniej, SQL Server skanuje okna wyrażeń w kolejności pojawiania się w zapytaniu i liczby, które może obsłużyć jako pierwsze za pomocą uporządkowanego skanowania indeksu idx_nc_cid_od_oid. Ale potem dodaje operator Sort do planu, aby uporządkować dane, tak jak potrzebuje druga funkcja okna. Oznacza to, że plan ma skalowanie N log N. Nie bierze pod uwagę używania indeksu idx_nc_cid_oid do obsługi drugiej funkcji okna. Prawdopodobnie myślisz, że to niemożliwe, ale spróbuj myśleć nieco nieszablonowo. Czy nie możesz obliczyć każdej z funkcji okna na podstawie odpowiedniej kolejności indeksów, a następnie połączyć wyniki? Teoretycznie można iw zależności od rozmiaru danych, dostępności indeksowania i innych dostępnych zasobów wersja sprzężenia może czasami działać lepiej. SQL Server nie bierze pod uwagę takiego podejścia, ale z pewnością możesz je wdrożyć, samodzielnie pisząc sprzężenie, na przykład:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Będę nazywał to zapytanie Zapytanie 10. Plan dla tego zapytania pokazano na rysunku 10.
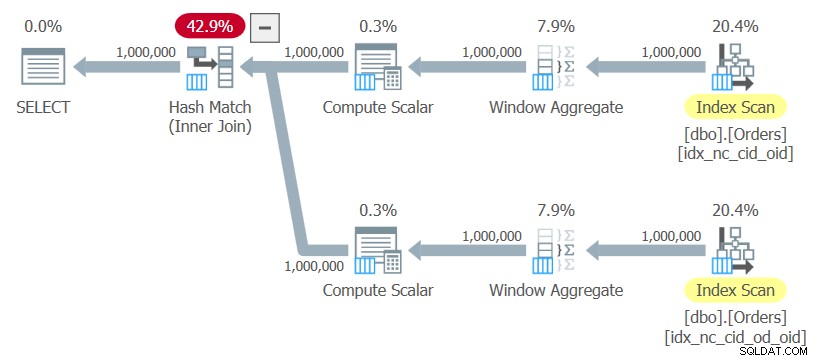 Rysunek 10:Plan dla zapytania 10
Rysunek 10:Plan dla zapytania 10
Plan używa uporządkowanych skanów dwóch indeksów bez żadnego jawnego sortowania, oblicza funkcje okna i używa sprzężenia mieszającego, aby połączyć wyniki. Ten plan skaluje się liniowo w porównaniu do poprzedniego, który ma skalowanie N log N.
Otrzymuję następujące statystyki czasu dla tego zapytania na moim komputerze (ponownie z wynikami odrzuconymi w SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
Podsumowując, oto nasza szósta wskazówka.
Wskazówka 6:jeśli masz wiele funkcji okien z wieloma różnymi potrzebami porządkowania i jesteś w stanie obsłużyć je wszystkie za pomocą indeksów, wypróbuj wersję sprzężenia i porównaj jej wydajność z zapytaniem bez sprzężenia.
Oczyszczanie
Jeśli wyłączyłeś równoległość, ustawiając opcję konfiguracji w zakresie bazy danych MAXDOP na 1, włącz ponownie równoległość, ustawiając ją na 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Jeśli użyto nieudokumentowanej opcji sesji DBCC OPTIMIZER_WHATIF z opcją procesorów ustawioną na 1, włącz ponownie równoległość, ustawiając ją na 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Jeśli chcesz, możesz ponownie spróbować wszystkich przykładów z włączoną równoległością.
Użyj następującego kodu, aby wyczyścić nowo utworzone indeksy:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
Oraz następujący kod do usunięcia widoku:
DROP VIEW IF EXISTS dbo.MyView;
Postępuj zgodnie ze wskazówkami, aby zminimalizować liczbę sortowań
Funkcje okien muszą przetworzyć zamówione dane wejściowe. Indeksowanie może pomóc w wyeliminowaniu sortowania w planie, ale zwykle tylko dla jednej wyraźnej potrzeby porządkowania. Zapytania z wieloma potrzebami związanymi z zamawianiem zazwyczaj obejmują pewne rodzaje planów. Jednak postępując zgodnie z pewnymi wskazówkami, możesz zminimalizować liczbę potrzebnych sortowań. Oto podsumowanie wskazówek, o których wspomniałem w tym artykule:
- Wskazówka 1: Jeśli masz indeks obsługujący niektóre funkcje okna w zapytaniu, określ je najpierw.
- Wskazówka 2: Jeśli zapytanie obejmuje funkcje okna z taką samą potrzebą porządkowania, jak porządkowanie prezentacji w zapytaniu, określ te funkcje jako ostatnie.
- Wskazówka 3: Pamiętaj, aby zastosować się do wskazówek 1 i 2 przy pierwszym wystąpieniu każdej odrębnej potrzeby zamówienia. Kolejne wystąpienia tej samej potrzeby porządkowej, nawet jeśli nie sąsiadują ze sobą, są identyfikowane i grupowane razem z pierwszym.
- Wskazówka 4: Powyższe zalecenia dotyczą kolejności wyglądu funkcji okna w kodzie, nawet jeśli w nazwanym wyrażeniu tabelowym, takim jak CTE lub widok, i nawet jeśli zewnętrzne zapytanie zwraca kolumny w innej kolejności niż w nazwanym wyrażeniu tabelowym. W związku z tym, jeśli musisz zwrócić kolumny w określonej kolejności w danych wyjściowych i różni się ona od optymalnej kolejności pod względem minimalizowania sortowań w planie, postępuj zgodnie ze wskazówkami dotyczącymi kolejności wyświetlania w nazwanym wyrażeniu tabeli i zwróć kolumny w zewnętrznym zapytaniu w żądanej kolejności danych wyjściowych.
- Wskazówka 5: W wewnętrznym zapytaniu nazwanego wyrażenia tabelowego, takiego jak CTE lub widok, zgrupuj razem wszystkie funkcje okna o tych samych potrzebach porządkowania i postępuj zgodnie ze wskazówkami 1 i 2 w kolejności grup funkcji.
- Wskazówka 6: Jeśli masz wiele funkcji okna z wieloma różnymi potrzebami porządkowania i jesteś w stanie obsłużyć je wszystkie za pomocą indeksów, wypróbuj wersję sprzężenia i porównaj jej wydajność z zapytaniem bez sprzężenia.