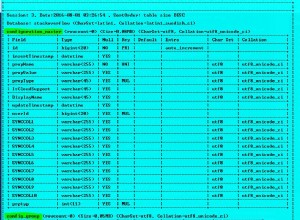
w 10g/11g możesz użyć do tego klauzuli modelowej.
SQL> with emps as (select rownum id, name, start_date,
2 end_date, trunc(end_date)-trunc(start_date) date_range
3 from table1)
4 select name, the_date
5 from emps
6 model partition by(id as key)
7 dimension by(0 as f)
8 measures(name, start_date, cast(null as date) the_date, date_range)
9 rules (the_date [for f from 0 to date_range[0] increment 1] = start_date[0] + cv(f),
10 name[any] = name[0]);
NAME THE_DATE
----------- ----------
DAVID SMITH 01-01-2001
DAVID SMITH 01-02-2001
DAVID SMITH 01-03-2001
DAVID SMITH 01-04-2001
DAVID SMITH 01-05-2001
DAVID SMITH 01-06-2001
JOHN SMITH 02-07-2012
JOHN SMITH 02-08-2012
JOHN SMITH 02-09-2012
9 rows selected.
tj. Twoje zapytanie podstawowe:
select rownum id, name, start_date,
end_date, trunc(end_date)-trunc(start_date) date_range
from table1
po prostu definiuje daty + zakres (użyłem identyfikatora rownum, ale jeśli masz PK, możesz go użyć zamiast tego.
partycja dzieli nasze obliczenia na ID (unikalny wiersz):
6 model partition by(id as key)
środki:
8 measures(name, start_date, cast(null as date) the_date, date_range)
definiuje atrybuty, które będziemy wyprowadzać/obliczać. w tym przypadku pracujemy z nazwą i datą_początkową plus zakresem wierszy do wygenerowania. dodatkowo zdefiniowałem kolumnę the_date który będzie zawierał obliczoną datę (tzn. chcemy obliczyć data_początkowa + n, gdzie n wynosi od 0 do zakresu).
zasady określają JAK mamy zamiar wypełnić nasze kolumny:
9 rules (the_date [for f from 0 to date_range[0] increment 1] = start_date[0] + cv(f),
10 name[any] = name[0]);
więc z
the_date [for f from 0 to date_range[0] increment 1]
mówimy, że wygenerujemy liczbę wierszy, które zawiera zakres_dat+1 (tj. łącznie 6 dat). wartość f można się do nich odwoływać poprzez cv (wartość bieżąca).
więc w wierszu 1 dla Dawida mielibyśmy the_date [0] = start_date+0 a następnie w wierszu 2 mielibyśmy the_date [1] = start_date+1 . całą drogę do start_date+5 (tj. end_date )
p.s.dla połączenia przez, musisz zrobić coś takiego:
select
A.EMPLOYEE_NAME,
A.START_DATE+(b.r-1) AS INDIVIDUAL_DAY,
TO_CHAR(A.START_DATE,'MM/DD/YYYY') START_DATE,
TO_CHAR(A.END_DATE,'MM/DD/YYYY') END_DATE
FROM table1 A
cross join (select rownum r
from (select max(end_date-start_date) d from table1)
connect by level-1 <= d) b
where A.START_DATE+(b.r-1) <= A.END_DATE
order by 1, 2;
tj. odizoluj połączenie według podzapytania, a następnie odfiltruj wiersze, w których indywidualny_dzień> data_końcowa.
ale nie polecam tego podejścia. jego wydajność będzie gorsza w porównaniu z podejściem modelowym (zwłaszcza jeśli zakresy staną się duże).