Krótkie podsumowanie
- Wydajność metody podzapytań zależy od dystrybucji danych.
- Wydajność agregacji warunkowej nie zależy od dystrybucji danych.
Metoda podzapytań może być szybsza lub wolniejsza niż agregacja warunkowa, zależy to od dystrybucji danych.
Oczywiście, jeśli tabela ma odpowiedni indeks, to podzapytania prawdopodobnie na tym skorzystają, ponieważ indeks umożliwiłby przeskanowanie tylko odpowiedniej części tabeli zamiast pełnego skanu. Posiadanie odpowiedniego indeksu raczej nie przyniesie znaczących korzyści metodzie warunkowej agregacji, ponieważ i tak będzie ona skanować cały indeks. Jedyną korzyścią byłoby, gdyby indeks był węższy niż tabela i silnik musiałby wczytać mniej stron do pamięci.
Wiedząc o tym, możesz zdecydować, którą metodę wybrać.
Pierwszy test
Zrobiłem większy stół testowy, z rzędami 5M. Na stole nie było żadnych indeksów. Zmierzyłem statystyki IO i CPU za pomocą SQL Sentry Plan Explorer. Do tych testów użyłem 64-bitowego programu SQL Server 2014 SP1-CU7 (12.0.4459.0) Express.
Rzeczywiście, Twoje oryginalne zapytania zachowywały się tak, jak opisałeś, tj. podzapytania były szybsze, mimo że odczyty były 3 razy wyższe.
Po kilku próbach na tabeli bez indeksu przepisałem twoją agregację warunkową i dodałem zmienne do przechowywania wartości DATEADD wyrażenia.
Całkowity czas znacznie się skrócił.
Potem zastąpiłem SUM z COUNT i znów stało się trochę szybsze.
W końcu agregacja warunkowa stała się prawie tak szybka jak podzapytania.
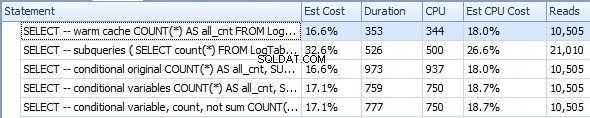
Ogrzej pamięć podręczną (procesor=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Podzapytania (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Pierwotna agregacja warunkowa (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregacja warunkowa ze zmiennymi (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregacja warunkowa ze zmiennymi i COUNT zamiast SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Na podstawie tych wyników przypuszczam, że CASE wywołano DATEADD dla każdego wiersza, natomiast WHERE był na tyle sprytny, by raz to obliczyć. Plus COUNT jest odrobinę bardziej wydajny niż SUM .
Ostatecznie agregacja warunkowa jest tylko nieznacznie wolniejsza niż podzapytania (1062 vs 1031), być może dlatego, że WHERE jest nieco bardziej wydajny niż CASE w sobie, a poza tym WHERE odfiltrowuje sporo wierszy, więc COUNT musi przetwarzać mniej wierszy.
W praktyce skorzystałbym z agregacji warunkowej, ponieważ uważam, że ważniejsza jest liczba odczytów. Jeśli Twoja tabela jest mała, aby zmieścić się i pozostać w puli buforów, każde zapytanie będzie szybkie dla użytkownika końcowego. Ale jeśli tabela jest większa niż dostępna pamięć, spodziewam się, że odczyt z dysku znacznie spowolni podzapytania.
Drugi test
Z drugiej strony ważne jest również odfiltrowywanie wierszy tak wcześnie, jak to możliwe.
Oto niewielka odmiana testu, która to pokazuje. Tutaj ustawiłem próg na GETDATE() + 100 lat, aby upewnić się, że żadne wiersze nie spełniają kryteriów filtrowania.
Ogrzej pamięć podręczną (procesor=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Podzapytania (procesor=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Pierwotna agregacja warunkowa (procesor=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregacja warunkowa ze zmiennymi (procesor=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregacja warunkowa ze zmiennymi i COUNT zamiast SUM (procesor=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
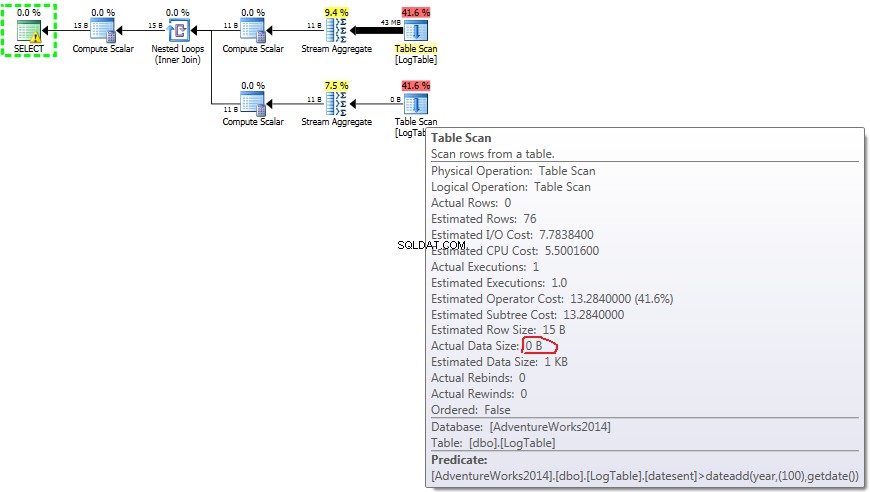
Poniżej znajduje się plan z podzapytaniami. Widać, że 0 wierszy trafiło do agregacji strumienia w drugim podzapytaniu, wszystkie zostały odfiltrowane na etapie skanowania tabeli.
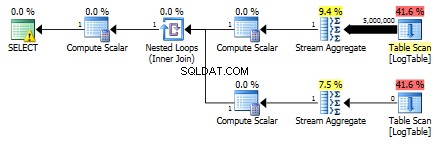
W rezultacie podzapytania są ponownie szybsze.
Trzeci test
Tutaj zmieniłem kryteria filtrowania poprzedniego testu:wszystkie > zostały zastąpione przez < . W rezultacie warunkowe COUNT policzył wszystkie wiersze zamiast żadnego. Niespodzianka niespodzianka! Warunkowe zapytanie agregujące zajęło tyle samo 750 ms, podczas gdy podzapytania zmieniły się w 813 zamiast 500.

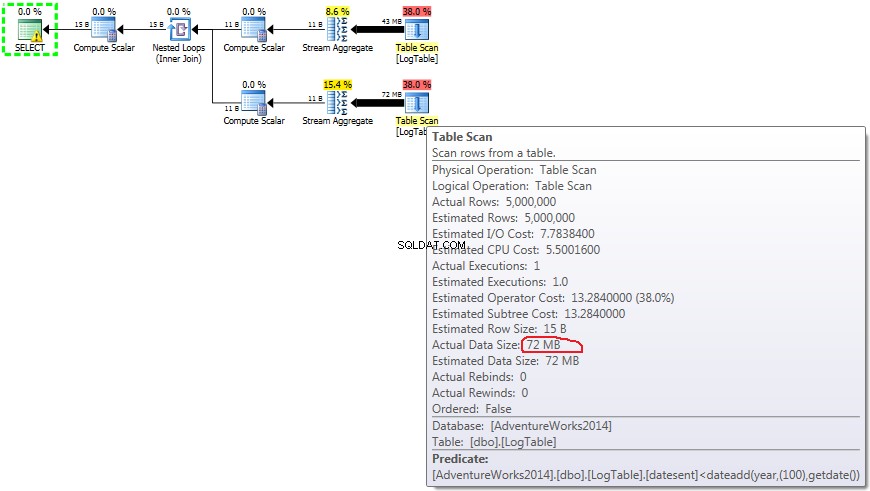
Oto plan podzapytań:
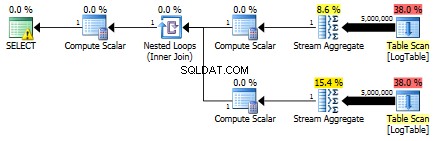
Czy możesz podać przykład, w którym agregacja warunkowa znacznie przewyższa rozwiązanie podzapytania?
Oto jest. Wykonanie metody podzapytań zależy od dystrybucji danych. Wykonanie agregacji warunkowej nie zależy od dystrybucji danych.
Metoda podzapytań może być szybsza lub wolniejsza niż agregacja warunkowa, zależy to od dystrybucji danych.
Wiedząc o tym, możesz zdecydować, którą metodę wybrać.
Szczegóły bonusu
Jeśli najedziesz myszą na Table Scan operatora możesz zobaczyć Actual Data Size w różnych wariantach.
- Proste
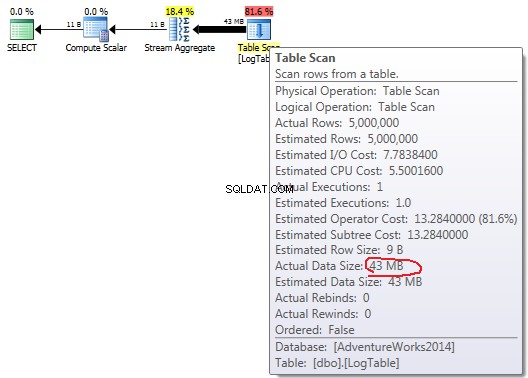
COUNT(*):
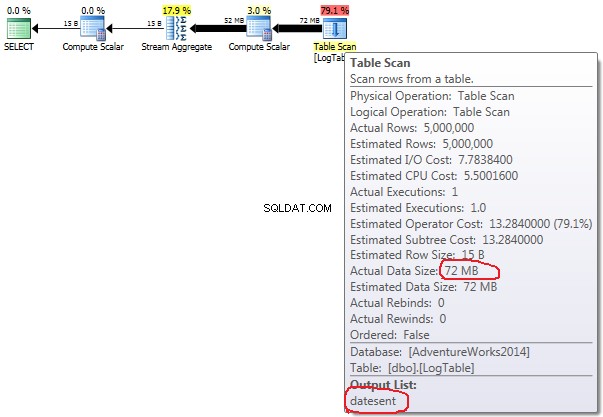
- Agregacja warunkowa:
- Podzapytanie w teście 2:
- Podzapytanie w teście 3:
Teraz staje się jasne, że różnica w wydajności jest prawdopodobnie spowodowana różnicą w ilości danych przepływających przez plan.
W przypadku prostego COUNT(*) nie ma Output list (nie są potrzebne żadne wartości kolumn), a rozmiar danych jest najmniejszy (43 MB).
W przypadku agregacji warunkowej ilość ta nie zmienia się między testami 2 i 3, zawsze wynosi 72 MB. Output list ma jedną kolumnę datesent .
W przypadku podzapytań ta kwota robi zmienić w zależności od dystrybucji danych.