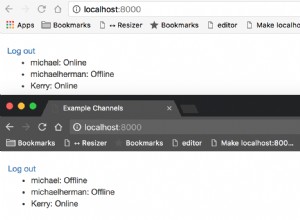
Najpierw musisz zdefiniować myślnik jako printjoin w swoim lekserze.
sprawdź to z
select IXV_ATTRIBUTE, IXV_VALUE from CTXSYS.CTX_INDEX_VALUES where IXV_CLASS = 'LEXER';
IXV_ATTRIBUTE IXV_VALUE
-----------------------------------------
PRINTJOINS _$%&-
NUMJOIN .
NUMGROUP .
WHITESPACE ,=
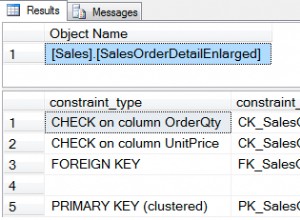
Następnie możesz (po ponownym utworzeniu indeksu za pomocą tego leksera) sprawdzić, czy tokeny są zgodne z oczekiwaniami:(Twoja tabela będzie się różnić w zależności od nazwy indeksu; sprawdź wszystkie tabele, np. „DR$%$I”)
select TOKEN_TEXT from DR$TEXTIDX_IDX$I where TOKEN_TEXT like '%-XYZ99';
TOKEN_TEXT
----------------------------------------------------------------
AN-XYZ99
BAR-XYZ99
FO-XYZ99
Teraz możesz zapytać o ciąg wyszukiwania.
Najwyraźniej musisz zmienić myślnik jako BAR-XYZ99 znajdzie wiersze z BAR nie zawierające XYZ99; chociaż dokumentacja hyphen with no space
jest nieco inny.
SELECT SCORE(1),txt
FROM textidx
WHERE CONTAINS(txt, 'BAR-XYZ99',1) > 0;
SCORE(1) TXT
---------- ------------------------------------------------------------------------------------
4 unbekannt Stadt Text: FO-XYZ99 << foobar Straße 31.12.2017 Datum Host 20160101 bar
Z jakiegoś powodu (jestem na 11.2.0.2.0) uciekanie za pomocą nawiasów klamrowych nie działa (zwraca brak dopasowania), ale użycie odwrotnego ukośnika jest w porządku.
SELECT SCORE(1),txt
FROM textidx
WHERE CONTAINS(txt, 'BAR\-XYZ99',1) > 0;
SCORE(1) TXT
---------- ------------------------------------------------------------------------------------
4 unbekannt Stadt Text: BAR-XYZ99 << foobar Straße 31.12.2017 Datum Host 20160101 bla