Kontynuuję serię artykułów na temat podstaw EXPLAIN w PostgreSQL, która jest krótką recenzją Understanding EXPLAIN autorstwa Guillaume Lelarge.
Aby lepiej zrozumieć problem, gorąco polecam przejrzenie oryginalnego „Understanding EXPLAIN” Guillaume Lelarge i przeczytaj mój pierwszy i drugi artykuł.
ZAMÓW PRZEZ
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Najpierw wykonujesz skanowanie sekwencyjne (Seq Scan) tabeli foo, a następnie wykonujesz sortowanie (Sort). Znak -> komendy EXPLAIN wskazuje hierarchię kroków (węzeł). Im wcześniej krok zostanie wykonany, tym większe ma wcięcie.
Klucz sortowania jest warunkiem sortowania.
Metoda sortowania:scalanie zewnętrzne Dysk podczas sortowania używany jest plik tymczasowy na dysku o pojemności 4592 kB.
Sprawdź za pomocą opcji BUFORÓW:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
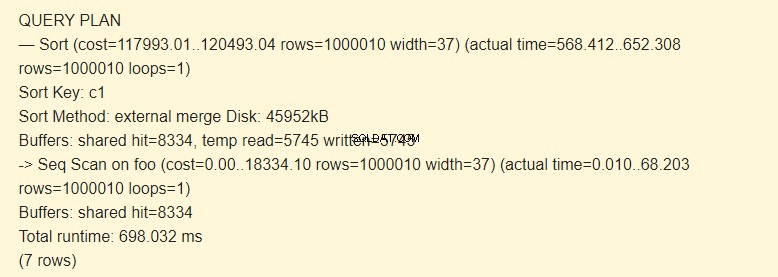
Rzeczywiście, linia temp read=5745 write=5745 oznacza, że 45960Kb (5745 bloków po 8Kb każdy) zostało zapisanych i odczytanych w pliku tymczasowym. Operacje z 8334 blokami zostały wykonane w pamięci podręcznej.
Operacje na systemie plików są wolniejsze niż operacje w pamięci RAM.
Spróbujmy zwiększyć pojemność pamięci work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Metoda sortowania:quicksort Pamięć:102702kB – całe sortowanie zostało wykonane w pamięci RAM.
Indeks wygląda następująco:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Pozostało nam tylko skanowanie indeksów, co znacząco wpłynęło na szybkość zapytania.
LIMIT
Usuń wcześniej utworzony indeks:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Zgodnie z oczekiwaniami używane są sekwencyjne skanowanie i filtrowanie.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan odczytuje wiersze tabeli i porównuje je (Filtr) z warunkiem. Gdy tylko 10 rekordów spełni warunek, skanowanie zostanie zakończone. W naszym przypadku, aby uzyskać 10 wierszy wyników, musieliśmy odczytać tylko 3063 rekordów, a nie całą tabelę. 3053 wierszy o tej liczbie zostało odrzuconych (wiersze usunięte przez filtr).
To samo dzieje się ze skanowaniem indeksu.
DOŁĄCZ
Utwórz nową tabelę i wygeneruj dla niej statystyki:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
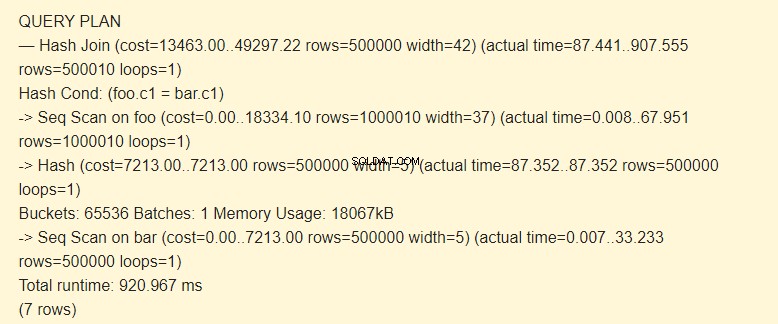
Zapytanie dla dwóch tabel wygląda następująco:
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Najpierw skan sekwencyjny (Seq Scan) odczytuje tabelę słupków. Dla każdego wiersza obliczany jest skrót (Hash).
Następnie skanuje tabelę foo i dla każdego wiersza obliczany jest hash, który jest porównywany (Hash Join) z hashem tabeli słupkowej według warunku Hash Cond. Jeśli pasują, wyprowadzany jest łańcuch wynikowy.
18067kB pamięci jest używane do przechowywania skrótów dla paska.
Dodaj indeks:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash nie jest już używany. Scalanie łączenia i skanowania indeksów na indeksach obu tabel znacznie poprawia wydajność.
LEWY DOŁĄCZ:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
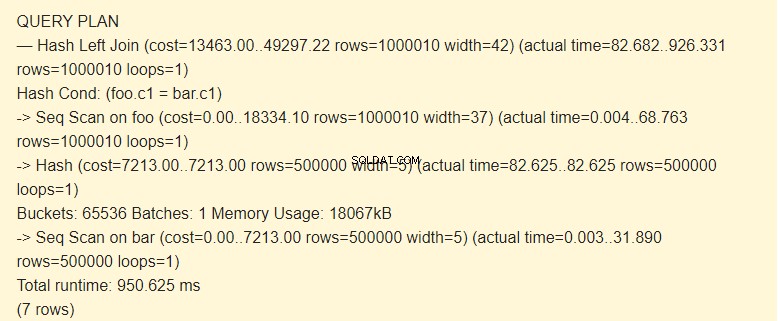
Skanowanie sekwencji?
Zobaczmy, jaki wynik uzyskamy, jeśli wyłączymy Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Według harmonogramu używanie indeksów jest bardziej kosztowne niż używanie skrótów. Jest to możliwe przy odpowiednio dużej ilości przydzielonej pamięci. Czy pamiętasz, jak zwiększaliśmy work_mem?
Jeśli jednak nie masz wystarczającej ilości pamięci, harmonogram będzie zachowywał się inaczej:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Jeśli wyłączymy skanowanie indeksu, jaki wynik zostanie wyświetlony WYJAŚNIJ?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
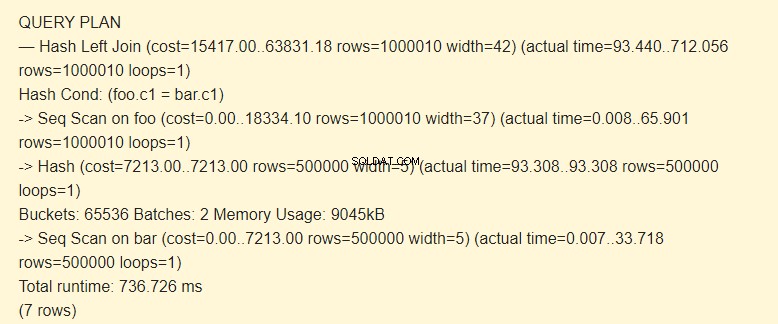
Partie:2 ma zwiększony koszt. Cały hasz nie mieścił się w pamięci; musieliśmy podzielić go na dwie paczki po 9045kB.
Dziękuję za przeczytanie moich artykułów! Mam nadzieję, że były przydatne. Jeśli masz jakieś uwagi lub uwagi, daj mi znać.