W moim poprzednim artykule zaczęliśmy opisywać podstawy polecenia EXPLAIN i analizowaliśmy, co dzieje się w PostgreSQL podczas wykonywania zapytania.
Zamierzam kontynuować pisanie o podstawach EXPLAIN w PostgreSQL. Informacje te są krótkim przeglądem Understanding EXPLAIN autorstwa Guillaume'a Lelarge'a. Gorąco polecam przeczytanie oryginału, ponieważ niektóre informacje zostały pominięte.
Pamięć podręczna
Co dzieje się na poziomie fizycznym podczas wykonywania naszego zapytania? Rozwiążmy to. Wdrożyłem mój serwer na Ubuntu 13.10 i używałem pamięci podręcznych na poziomie systemu operacyjnego.
Zatrzymuję PostgreSQL, wprowadzam zmiany w systemie plików, czyszczę pamięć podręczną i uruchamiam PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Po wyczyszczeniu pamięci podręcznej uruchom zapytanie z opcją BUFORÓW
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Czytamy tabelę blokami. Pamięć podręczna jest pusta. Aby odczytać całą tabelę z dysku, musieliśmy uzyskać dostęp do 8334 bloków.
Bufory:współdzielony odczyt to liczba bloków, które PostgreSQL odczytuje z dysku.
Uruchom poprzednie zapytanie
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Bufory:wspólne trafienie to liczba bloków pobranych z pamięci podręcznej PostgreSQL.
Z każdym zapytaniem PostgreSQL pobiera coraz więcej danych z pamięci podręcznej, tym samym wypełniając własną pamięć podręczną.
Operacje odczytu pamięci podręcznej są szybsze niż operacje odczytu dysku. Możesz zobaczyć ten trend, śledząc wartość całkowitego czasu działania.
Rozmiar pamięci podręcznej jest zdefiniowany przez stałą shared_buffers w pliku postgresql.conf.
GDZIE
Dodaj warunek do zapytania
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
W tabeli nie ma indeksów. Podczas wykonywania zapytania każdy rekord tabeli jest skanowany sekwencyjnie (Skanowanie sekwencyjne) i porównywany z warunkiem c1> 500. Jeśli warunek jest spełniony, rekord jest dodawany do wyniku. W przeciwnym razie jest odrzucany. Filtr wskazuje to zachowanie, a także wzrost wartości kosztów.
Szacowana liczba wierszy maleje.
W oryginalnym artykule wyjaśniono, dlaczego koszt przyjmuje tę wartość i jak obliczana jest szacunkowa liczba wierszy.
Czas stworzyć indeksy.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Szacowana liczba wierszy uległa zmianie. A co z indeksem?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Filtrowanych jest tylko 510 wierszy powyżej 1 miliona. PostgreSQL musiał przeczytać ponad 99,9% tabeli.
Wymusimy użycie indeksu, wyłączając Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

W Index Scan i Index Cond zamiast opcji Filter używany jest indeks foo_c1_idx.
Wybierając całą tabelę, użycie indeksu zwiększy koszt i czas wykonania zapytania.
Włącz skanowanie sekwencyjne:
SET enable_seqscan TO on;
Zmodyfikuj zapytanie:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
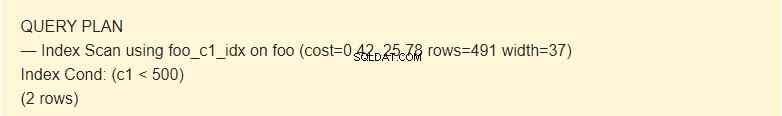
Tutaj planista używa indeksu.
Teraz skomplikujmy wartość, dodając pole tekstowe.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Jak widać, indeks foo_c1_idx jest używany dla c1 <500. Aby wykonać c2 ~~ ‘abcd%’::text, użyj filtra.
Należy zauważyć, że na wyjściu wyników używany jest format POSIX operatora LIKE. Jeśli w warunku jest tylko pole tekstowe:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Zastosowano skanowanie sekwencyjne.
Zbuduj indeks według c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Indeks nie jest stosowany, ponieważ moja baza danych dla pól testowych używa kodowania UTF-8.
Podczas budowania indeksu konieczne jest określenie klasy operatora text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Świetny! Udało się!
Skanowanie indeksu map bitowych wykorzystuje indeks foo_c2_idx1 do określenia potrzebnych nam rekordów. Następnie PostgreSQL przechodzi do tabeli (Skanowanie sterty bitmapy), aby upewnić się, że te rekordy rzeczywiście istnieją. To zachowanie odnosi się do wersjonowania PostgreSQL.
Jeśli wybierzesz tylko pole, na którym zbudowany jest indeks, zamiast całego wiersza:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Skanowanie tylko indeksu zostanie wykonane szybciej niż skanowanie indeksu, ponieważ nie jest konieczne odczytywanie wiersza tabeli:szerokość=4.
Wniosek
- Seq Scan odczytuje całą tabelę
- Skanowanie indeksu używa indeksu dla instrukcji WHERE i odczytuje tabelę podczas wybierania wierszy
- Skanowanie indeksu mapy bitowej wykorzystuje funkcję Skanowanie indeksu i kontrolę wyboru w tabeli. Skuteczny w przypadku dużej liczby rzędów.
- Skanowanie tylko indeksu jest najszybszym blokiem, który odczytuje tylko indeks.
Dalsza lektura:
Optymalizacja zapytań w PostgreSQL. WYJAŚNIJ podstawy – część 3