Część, którą zawsze uważałem za mylącą, to koszt uruchomienia w porównaniu z całkowitym kosztem. Google to za każdym razem, gdy o tym zapominam, co mnie tu sprowadza, co nie wyjaśnia różnicy, dlatego piszę tę odpowiedź. Oto, czego dowiedziałem się z EXPLAIN Postgresa dokumentację wyjaśnioną tak, jak ją rozumiem.
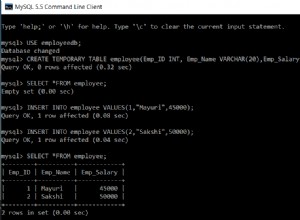
Oto przykład z aplikacji zarządzającej forum:
EXPLAIN SELECT * FROM post LIMIT 50;
Limit (cost=0.00..3.39 rows=50 width=422)
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
Oto graficzne wyjaśnienie od PgAdmin:

(Gdy używasz PgAdmin, możesz skierować kursor myszy na komponent, aby odczytać szczegóły kosztów).
Koszt jest reprezentowany jako krotka, np. koszt LIMIT to cost=0.00..3.39 i koszt sekwencyjnego skanowania post to cost=0.00..15629.12 . Pierwsza liczba w krotce to koszt uruchomienia a druga liczba to całkowity koszt . Ponieważ użyłem EXPLAIN a nie EXPLAIN ANALYZE , te koszty są szacunkami, a nie rzeczywistymi środkami.
- Koszt uruchomienia to trudna koncepcja. Reprezentuje nie tylko czas przed uruchomieniem tego komponentu . Reprezentuje czas między rozpoczęciem wykonywania komponentu (odczytywanie danych) a momentem, w którym komponent wyprowadza swój pierwszy wiersz .
- Całkowity koszt to całkowity czas wykonania komponentu, od momentu rozpoczęcia odczytu danych do zakończenia zapisywania danych wyjściowych.
Jako komplikacja, koszty każdego węzła „nadrzędnego” obejmują koszty jego węzłów podrzędnych. W reprezentacji tekstowej drzewo jest reprezentowane przez wcięcie, np. LIMIT jest węzłem nadrzędnym i Seq Scan jest jego dzieckiem. W reprezentacji PgAdmin strzałki wskazują od dziecka do rodzica — kierunek przepływu danych — co może być sprzeczne z intuicją, jeśli znasz teorię grafów.
Dokumentacja mówi, że koszty obejmują wszystkie węzły podrzędne, ale zauważ, że całkowity koszt rodzica 3.39 jest znacznie mniejszy niż całkowity koszt jego dziecka 15629.12 . Całkowity koszt nie jest uwzględniony, ponieważ komponent taki jak LIMIT nie musi przetwarzać całego swojego wejścia. Zobacz EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2; przykład w Postgresie EXPLAIN dokumentacja.
W powyższym przykładzie czas uruchamiania wynosi zero dla obu składników, ponieważ żaden składnik nie musi wykonywać żadnego przetwarzania przed rozpoczęciem zapisywania wierszy:skanowanie sekwencyjne odczytuje pierwszy wiersz tabeli i emituje go. LIMIT odczytuje swój pierwszy wiersz, a następnie go emituje.
Kiedy składnik musiałby wykonać dużo przetwarzania, zanim będzie mógł zacząć wyprowadzać jakiekolwiek wiersze? Istnieje wiele możliwych powodów, ale spójrzmy na jeden jasny przykład. Oto to samo zapytanie co wcześniej, ale teraz zawiera ORDER BY klauzula:
EXPLAIN SELECT * FROM post ORDER BY body LIMIT 50;
Limit (cost=23283.24..23283.37 rows=50 width=422)
-> Sort (cost=23283.24..23859.27 rows=230412 width=422)
Sort Key: body
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
I graficznie:
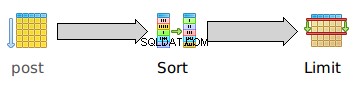
Po raz kolejny sekwencyjne skanowanie post nie ma kosztu początkowego:natychmiast rozpoczyna wyprowadzanie wierszy. Ale ten rodzaj ma znaczny koszt początkowy 23283.24 ponieważ musi posortować całą tabelę, zanim wygeneruje nawet pojedynczy wiersz . Całkowity koszt sortowania 23859.27 jest tylko nieznacznie wyższy niż koszt uruchomienia, co odzwierciedla fakt, że po posortowaniu całego zestawu danych posortowane dane mogą być emitowane bardzo szybko.
Zwróć uwagę, że czas uruchamiania LIMIT 23283.24 jest dokładnie równy czasowi uruchomienia danego rodzaju. Nie dzieje się tak, ponieważ LIMIT sam w sobie ma wysoki czas uruchamiania. Sam w sobie ma zerowy czas uruchamiania, ale EXPLAIN zlicza wszystkie koszty dziecka dla każdego rodzica, więc LIMIT czas uruchamiania obejmuje sumę czasów uruchamiania jego elementów potomnych.
Takie zestawienie kosztów może utrudnić zrozumienie kosztu wykonania każdego pojedynczego komponentu. Na przykład nasz LIMIT ma zerowy czas uruchamiania, ale na pierwszy rzut oka nie jest to oczywiste. Z tego powodu kilka innych osób połączyło się z explain.depesz.com, narzędziem stworzonym przez Huberta Lubaczewskiego (aka depesz), które pomaga zrozumieć EXPLAIN poprzez — między innymi — odjęcie kosztów dziecka od kosztów rodziców. W krótkim wpisie na blogu o swoim narzędziu wspomina o innych zawiłościach.