Routing transakcji wiosennych
Najpierw utworzymy DataSourceType Java Enum, który definiuje nasze opcje routingu transakcji:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
Aby skierować transakcje odczytu i zapisu do węzła podstawowego i transakcje tylko do odczytu do węzła repliki, możemy zdefiniować ReadWriteDataSource który łączy się z węzłem podstawowym i ReadOnlyDataSource które łączą się z węzłem repliki.
Trasowanie transakcji do odczytu i zapisu oraz tylko do odczytu jest realizowane przez Spring AbstractRoutingDataSource abstrakcji, która jest implementowana przez TransactionRoutingDatasource , jak ilustruje poniższy diagram:
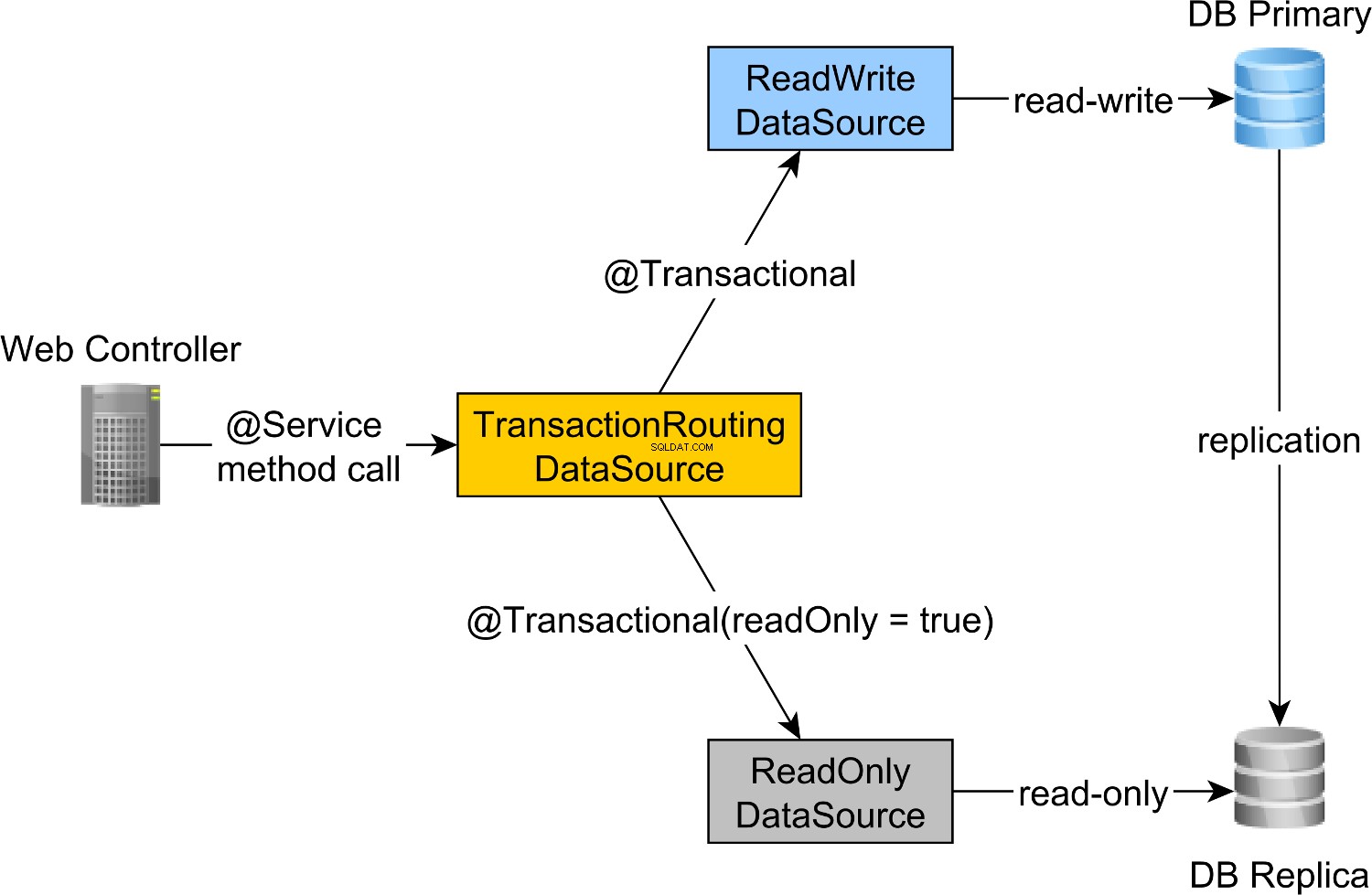
TransactionRoutingDataSource jest bardzo łatwy do wdrożenia i wygląda następująco:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
Zasadniczo sprawdzamy Spring TransactionSynchronizationManager klasa, która przechowuje bieżący kontekst transakcyjny, aby sprawdzić, czy aktualnie uruchomiona transakcja Spring jest tylko do odczytu, czy nie.
determineCurrentLookupKey metoda zwraca wartość dyskryminatora, która zostanie użyta do wyboru JDBC do odczytu-zapisu lub tylko do odczytu DataSource .
Wiosenna konfiguracja JDBC DataSource do odczytu i zapisu oraz tylko do odczytu
DataSource konfiguracja wygląda następująco:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
/META-INF/jdbc-postgresql-replication.properties plik zasobów zapewnia konfigurację dla JDBC do odczytu i zapisu oraz tylko do odczytu DataSource komponenty:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
jdbc.url.primary właściwość definiuje adres URL węzła podstawowego, podczas gdy jdbc.url.replica definiuje adres URL węzła repliki.
readWriteDataSource Komponent Spring definiuje JDBC do odczytu i zapisu DataSource podczas gdy readOnlyDataSource komponent definiuje JDBC tylko do odczytu DataSource .
Zwróć uwagę, że zarówno źródła danych do odczytu i zapisu, jak i tylko do odczytu używają HikariCP do łączenia połączeń.
actualDataSource działa jako fasada dla źródeł danych do odczytu i zapisu oraz tylko do odczytu i jest zaimplementowany przy użyciu TransactionRoutingDataSource narzędzie.
readWriteDataSource jest zarejestrowany przy użyciu DataSourceType.READ_WRITE klucz i readOnlyDataSource za pomocą DataSourceType.READ_ONLY klawisz.
Tak więc, podczas wykonywania odczytu i zapisu @Transactional metoda, readWriteDataSource będzie używany podczas wykonywania @Transactional(readOnly = true) metoda, readOnlyDataSource zostanie użyty zamiast tego.
Zauważ, że additionalProperties metoda definiuje hibernate.connection.provider_disables_autocommit Właściwość Hibernate, którą dodałem do Hibernate, aby odroczyć przejęcie bazy danych dla transakcji RESOURCE_LOCAL JPA.
Nie tylko, że hibernate.connection.provider_disables_autocommit pozwala lepiej wykorzystać połączenia z bazą danych, ale jest to jedyny sposób, w jaki możemy sprawić, by ten przykład działał, ponieważ bez tej konfiguracji połączenie jest nawiązywane przed wywołaniem determineCurrentLookupKey metoda TransactionRoutingDataSource .
Pozostałe komponenty Spring potrzebne do zbudowania JPA EntityManagerFactory są zdefiniowane przez AbstractJPAConfiguration klasa podstawowa.
Zasadniczo actualDataSource jest dodatkowo opakowany przez DataSource-Proxy i dostarczony do JPA EntityManagerFactory . Możesz sprawdzić kod źródłowy na GitHub, aby uzyskać więcej informacji.
Czas testowania
Aby sprawdzić, czy routing transakcji działa, włączymy dziennik zapytań PostgreSQL, ustawiając następujące właściwości w pliku postgresql.conf plik konfiguracyjny:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
log_min_duration_statement ustawienie właściwości służy do rejestrowania wszystkich instrukcji PostgreSQL, podczas gdy druga dodaje nazwę bazy danych do dziennika SQL.
Tak więc, podczas wywoływania newPost i findAllPostsByTitle metody, takie jak:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
Widzimy, że PostgreSQL rejestruje następujące komunikaty:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
Instrukcje dziennika przy użyciu high_performance_java_persistence prefiks został wykonany na węźle podstawowym, podczas gdy te używające high_performance_java_persistence_replica w węźle repliki.
Tak więc wszystko działa jak czar!
Cały kod źródłowy można znaleźć w moim repozytorium High-Performance Java Persistence GitHub, więc możesz go również wypróbować.
Wniosek
Musisz upewnić się, że ustawiłeś odpowiedni rozmiar dla swoich pul połączeń, ponieważ może to mieć ogromne znaczenie. W tym celu polecam korzystanie z Flexy Pool.
Musisz być bardzo sumienny i upewnić się, że wszystkie transakcje tylko do odczytu zostały odpowiednio oznaczone. To niezwykłe, że tylko 10% Twoich transakcji jest tylko do odczytu. Czy to możliwe, że masz taką aplikację, która najczęściej zapisuje lub używasz transakcji zapisu, w których wydajesz tylko zapytania?
Do przetwarzania wsadowego zdecydowanie potrzebujesz transakcji odczytu i zapisu, więc upewnij się, że włączyłeś przetwarzanie wsadowe JDBC, tak jak poniżej:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
Do grupowania możesz również użyć oddzielnego DataSource który używa innej puli połączeń, która łączy się z węzłem podstawowym.
Upewnij się tylko, że całkowity rozmiar połączenia wszystkich pul połączeń jest mniejszy niż liczba połączeń, z którymi skonfigurowano PostgreSQL.
Każde zadanie wsadowe musi korzystać z dedykowanej transakcji, więc upewnij się, że używasz rozsądnego rozmiaru partii.
Co więcej, chcesz trzymać blokady i jak najszybciej kończyć transakcje. Jeśli procesor wsadowy używa współbieżnych procesów roboczych, upewnij się, że wielkość powiązanej puli połączeń jest równa liczbie procesów roboczych, aby nie czekali, aż inni zwolnią połączenia.