Korzystanie z replikacji baz danych PostgreSQL może być przydatne nie tylko do zapewnienia środowiska o wysokiej dostępności i odporności na błędy, ale także do poprawy wydajności systemu poprzez równoważenie ruchu między węzłami rezerwowymi. W tej pierwszej części dwuczęściowego bloga zobaczymy niektóre koncepcje związane z replikacją PostgreSQL.
Metody replikacji w PostgreSQL
Istnieją różne metody replikacji danych w PostgreSQL, ale tutaj skupimy się na dwóch głównych metodach:replikacji strumieniowej i replikacji logicznej.
Replikacja strumieniowa
Replikacja strumieniowa PostgreSQL, najpopularniejsza replikacja PostgreSQL, to fizyczna replikacja, która replikuje zmiany na poziomie bajt po bajcie, tworząc identyczną kopię bazy danych na innym serwerze. Opiera się na metodzie wysyłki dziennika. Rekordy WAL są przenoszone bezpośrednio z jednego serwera bazy danych na inny w celu zastosowania. Można powiedzieć, że jest to rodzaj ciągłego PITR.
Ten transfer WAL jest wykonywany na dwa różne sposoby:przesyłając jeden plik (segment WAL) na raz (przesyłanie dziennika opartego na plikach) oraz przesyłając rekordy WAL (plik WAL składa się z rekordy WAL) w locie (przesyłanie dzienników na podstawie rekordów), między serwerem głównym a jednym lub więcej niż na serwerach rezerwowych, bez czekania na wypełnienie pliku WAL.
W praktyce proces zwany odbiornikiem WAL, działający na serwerze rezerwowym, połączy się z serwerem głównym za pomocą połączenia TCP/IP. Na serwerze głównym istnieje inny proces o nazwie WAL sender, który odpowiada za wysyłanie rejestrów WAL do serwera rezerwowego w miarę ich występowania.
Podstawową replikację strumieniową można przedstawić w następujący sposób:
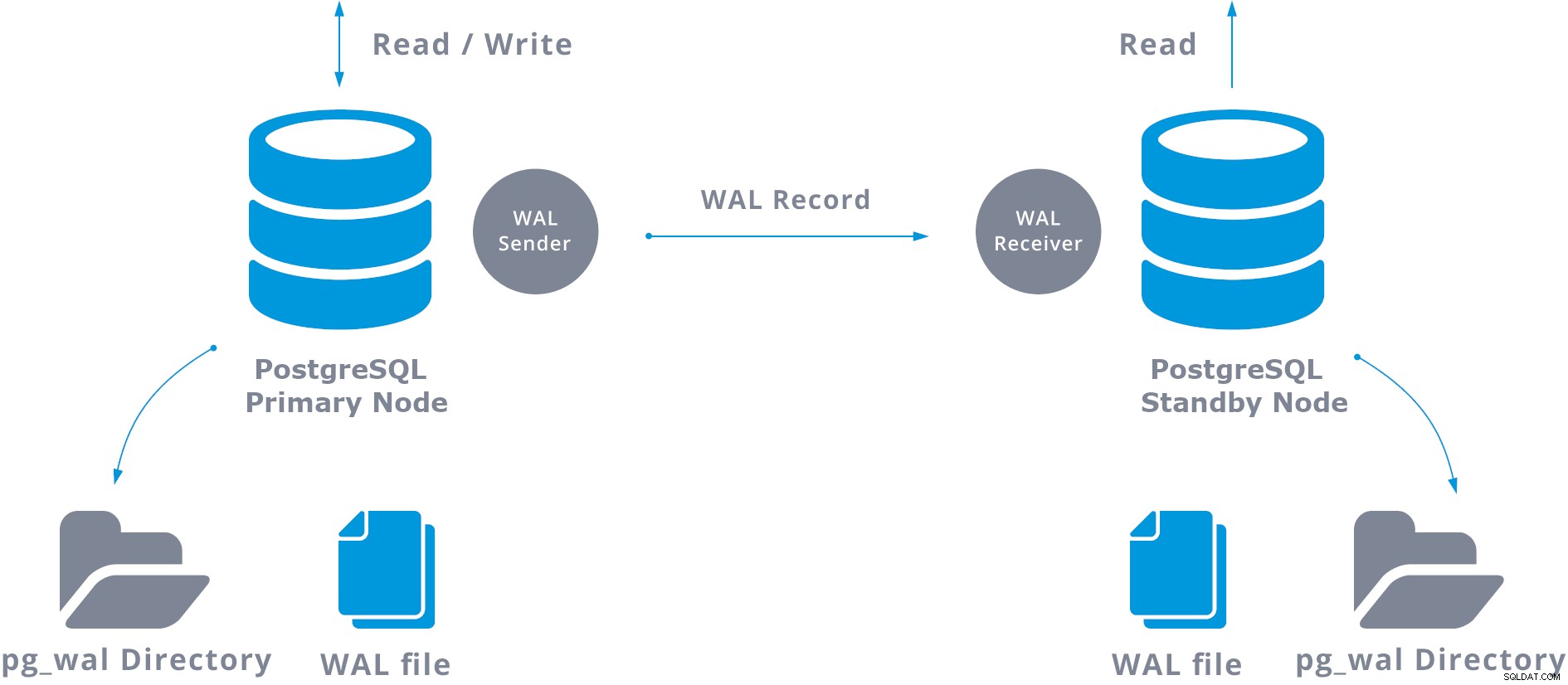
Podczas konfigurowania replikacji strumieniowej można włączyć archiwizację WAL. Nie jest to obowiązkowe, ale jest niezwykle ważne w przypadku niezawodnej konfiguracji replikacji, ponieważ konieczne jest unikanie odtwarzania przez serwer główny starych plików WAL, które nie zostały jeszcze zastosowane na serwerze rezerwowym. W takim przypadku konieczne będzie odtworzenie repliki od zera.
Replikacja logiczna
Replikacja logiczna PostgreSQL to metoda replikacji obiektów danych i ich zmian w oparciu o ich tożsamość replikacji (zwykle klucz podstawowy). Opiera się na trybie publikowania i subskrybowania, w którym jeden lub więcej subskrybentów subskrybuje jedną lub więcej publikacji w węźle wydawcy.
Publikacja to zbiór zmian wygenerowany z tabeli lub grupy tabel. Węzeł, w którym zdefiniowana jest publikacja, jest określany jako wydawca. Subskrypcja jest następną stroną replikacji logicznej. Węzeł, w którym zdefiniowana jest subskrypcja, określany jest mianem subskrybenta i określa on połączenie z inną bazą danych oraz zbiorem publikacji (jedną lub więcej), które chce subskrybować. Subskrybenci pobierają dane z publikacji, które subskrybują.
Replikacja logiczna ma architekturę podobną do fizycznej replikacji strumieniowej. Jest realizowany przez procesy „walsender” i „apply”. Proces walsendera rozpoczyna logiczne dekodowanie WAL i ładuje standardową wtyczkę dekodowania logicznego. Wtyczka przekształca zmiany odczytane z WAL na protokół replikacji logicznej i filtruje dane zgodnie ze specyfikacją publikacji. Dane są następnie w sposób ciągły przesyłane za pomocą protokołu replikacji strumieniowej do procesu roboczego aplikacji, który mapuje dane do lokalnych tabel i stosuje poszczególne zmiany w miarę ich odbierania, w prawidłowej kolejności transakcyjnej.
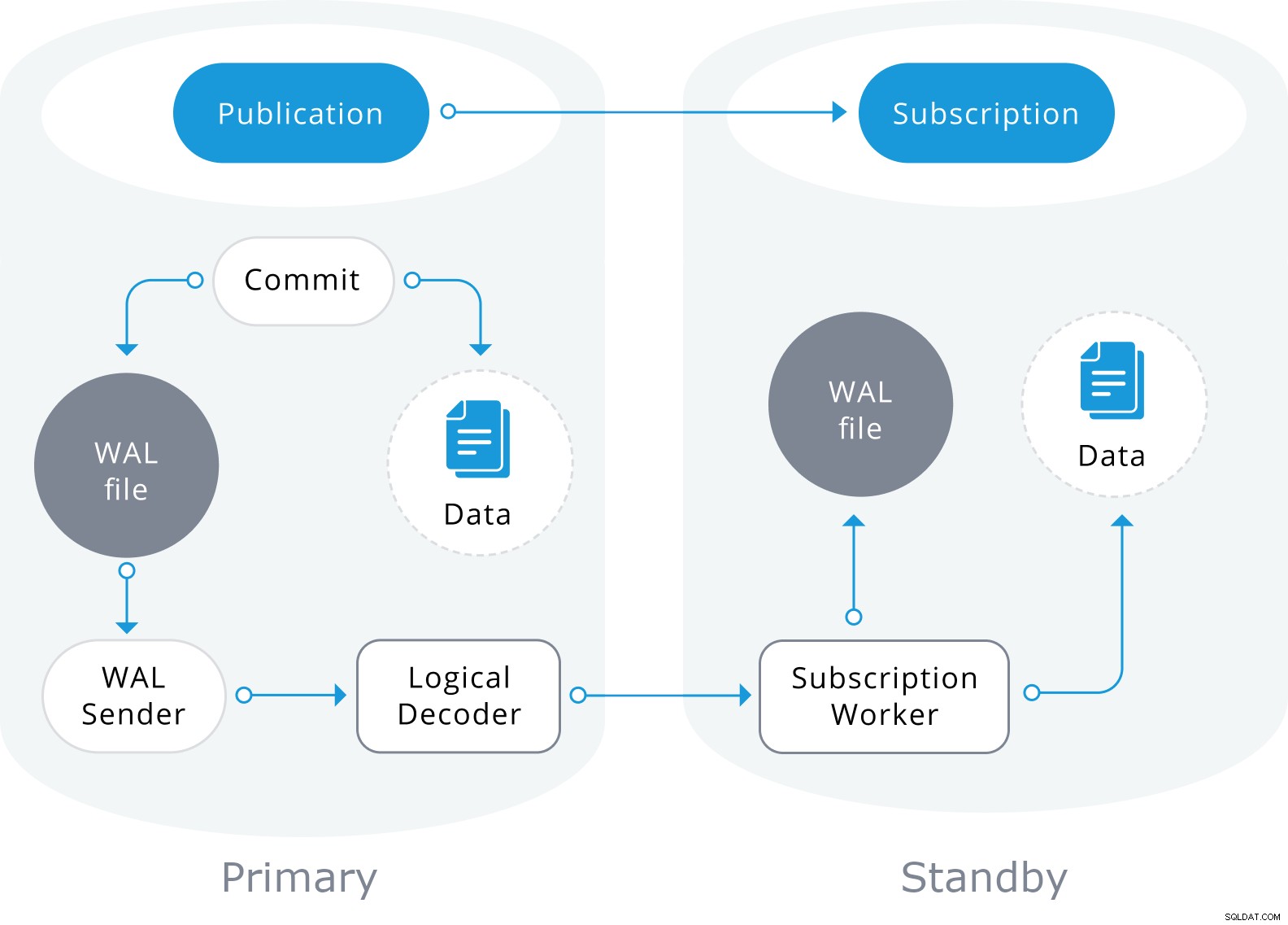
Replikacja logiczna rozpoczyna się od wykonania migawki danych w bazie danych wydawcy i kopiowanie tego do subskrybenta. Początkowe dane w istniejących subskrybowanych tabelach są zapisywane i kopiowane w równoległym wystąpieniu specjalnego rodzaju procesu stosowania. Ten proces utworzy własne tymczasowe gniazdo replikacji i skopiuje istniejące dane. Po skopiowaniu istniejących danych pracownik przechodzi w tryb synchronizacji, który zapewnia, że tabela zostanie przywrócona do stanu zsynchronizowanego z głównym procesem wprowadzania, przesyłając strumieniowo wszelkie zmiany, które zaszły podczas początkowego kopiowania danych, przy użyciu standardowej replikacji logicznej. Po zakończeniu synchronizacji kontrola nad replikacją tabeli jest przekazywana z powrotem do głównego procesu wprowadzania, w którym replikacja jest kontynuowana normalnie. Zmiany w wydawcy są wysyłane do subskrybenta w czasie rzeczywistym.
Tryby replikacji w PostgreSQL
Replikacja w PostgreSQL może być synchroniczna lub asynchroniczna.
Replikacja asynchroniczna
Jest to tryb domyślny. Tutaj jest możliwe, aby niektóre transakcje zostały zatwierdzone w węźle podstawowym, które nie zostały jeszcze zreplikowane na serwer rezerwowy. Oznacza to, że istnieje możliwość potencjalnej utraty danych. To opóźnienie w procesie zatwierdzania powinno być bardzo małe, jeśli serwer rezerwowy jest wystarczająco wydajny, aby nadążyć za obciążeniem. Jeśli to małe ryzyko utraty danych jest nie do zaakceptowania w firmie, możesz zamiast tego użyć replikacji synchronicznej.
Synchroniczna replikacja
Każde zatwierdzenie transakcji zapisu będzie czekać na potwierdzenie, że zatwierdzenie zostało zapisane w dzienniku zapisu z wyprzedzeniem na dysku zarówno serwera podstawowego, jak i rezerwowego. Ta metoda minimalizuje możliwość utraty danych. Aby doszło do utraty danych, konieczne byłoby jednoczesne uszkodzenie głównego i rezerwowego.
Wada tej metody jest taka sama dla wszystkich metod synchronicznych, ponieważ przy tej metodzie zwiększa się czas odpowiedzi dla każdej transakcji zapisu. Wynika to z konieczności oczekiwania na wszystkie potwierdzenia, że transakcja została zatwierdzona. Na szczęście nie będzie to miało wpływu na transakcje tylko do odczytu, ale; tylko transakcje zapisu.
Wysoka dostępność replikacji PostgreSQL
Wysoka dostępność jest wymogiem dla wielu systemów, bez względu na używaną technologię, i istnieją różne podejścia do osiągnięcia tego celu przy użyciu różnych narzędzi.
Równoważenie obciążenia
Systemy równoważenia obciążenia to narzędzia, których można użyć do zarządzania ruchem z aplikacji, aby jak najlepiej wykorzystać architekturę bazy danych. Jest to nie tylko przydatne do równoważenia obciążenia naszych baz danych, ale także pomaga przekierowywać aplikacje do dostępnych/zdrowych węzłów, a nawet określać porty o różnych rolach.
HAProxy to moduł równoważenia obciążenia, który rozdziela ruch z jednego źródła do jednego lub więcej miejsc docelowych i może zdefiniować określone reguły i/lub protokoły dla tego zadania. Jeśli którykolwiek z miejsc docelowych przestanie odpowiadać, zostaje oznaczony jako offline, a ruch jest przesyłany do pozostałych dostępnych miejsc docelowych. Posiadanie tylko jednego węzła Load Balancer wygeneruje pojedynczy punkt awarii, więc aby tego uniknąć, należy wdrożyć co najmniej dwa węzły HAProxy i skonfigurować między nimi Keepalived.
Keepalived to usługa, która pozwala nam skonfigurować wirtualny adres IP w ramach aktywnej/pasywnej grupy serwerów. Ten wirtualny adres IP jest przypisany do aktywnego serwera. Jeśli ten serwer ulegnie awarii, adres IP zostanie automatycznie przeniesiony do „dodatkowego” serwera pasywnego, umożliwiając mu dalszą pracę z tym samym adresem IP w sposób przejrzysty dla systemów.
Poprawa wydajności replikacji PostgreSQL
Wydajność jest zawsze ważna w każdym systemie. Będziesz musiał dobrze wykorzystać dostępne zasoby, aby zapewnić jak najkrótszy czas reakcji. Istnieją różne sposoby, aby to zrobić. Każde połączenie z bazą danych zużywa zasoby, więc jednym ze sposobów na poprawę wydajności bazy danych PostgreSQL jest posiadanie dobrego puli połączeń między aplikacją a serwerami baz danych.
Zbiorniki połączeń
Zestawienie połączeń to metoda tworzenia puli połączeń i ponownego ich wykorzystywania, unikając ciągłego otwierania nowych połączeń do bazy danych, co znacznie zwiększy wydajność Twoich aplikacji. PgBouncer to popularny puler połączeń zaprojektowany dla PostgreSQL.
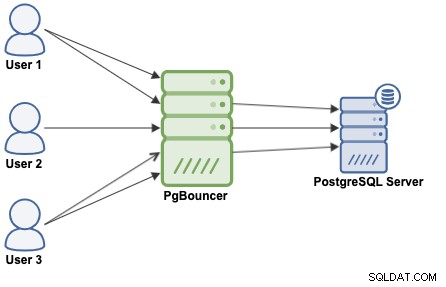
PgBouncer działa jako serwer PostgreSQL, więc wystarczy mieć dostęp do bazy danych używając informacji PgBouncer (adres IP/nazwa hosta i port), a PgBouncer utworzy połączenie z serwerem PostgreSQL lub użyje go ponownie, jeśli istnieje.
Kiedy PgBouncer odbiera połączenie, przeprowadza uwierzytelnianie, które zależy od metody określonej w pliku konfiguracyjnym. PgBouncer obsługuje wszystkie mechanizmy uwierzytelniania obsługiwane przez serwer PostgreSQL. Następnie PgBouncer sprawdza połączenie z pamięcią podręczną z tą samą kombinacją nazwy użytkownika i bazy danych. Jeśli zostanie znalezione połączenie buforowane, zwraca połączenie do klienta, jeśli nie, tworzy nowe połączenie. W zależności od konfiguracji PgBouncer i liczby aktywnych połączeń, może się zdarzyć, że nowe połączenie zostanie umieszczone w kolejce do momentu utworzenia lub nawet przerwania.
Dzięki tym wszystkim wspomnianym koncepcjom, w drugiej części tego bloga zobaczymy, jak można je połączyć, aby uzyskać dobre środowisko replikacji w PostgreSQL.



