W pierwszej części tego bloga wspomnieliśmy o kilku ważnych koncepcjach związanych z dobrym środowiskiem replikacji PostgreSQL. Zobaczmy teraz, jak połączyć wszystkie te rzeczy razem w prosty sposób za pomocą ClusterControl. W tym celu założymy, że masz zainstalowany ClusterControl, ale jeśli nie, możesz przejść na oficjalną stronę lub zapoznać się z oficjalną dokumentacją, aby go zainstalować.
Wdrażanie replikacji strumieniowej PostgreSQL
Aby przeprowadzić wdrożenie klastra PostgreSQL z ClusterControl, wybierz opcję Wdróż i postępuj zgodnie z wyświetlanymi instrukcjami.
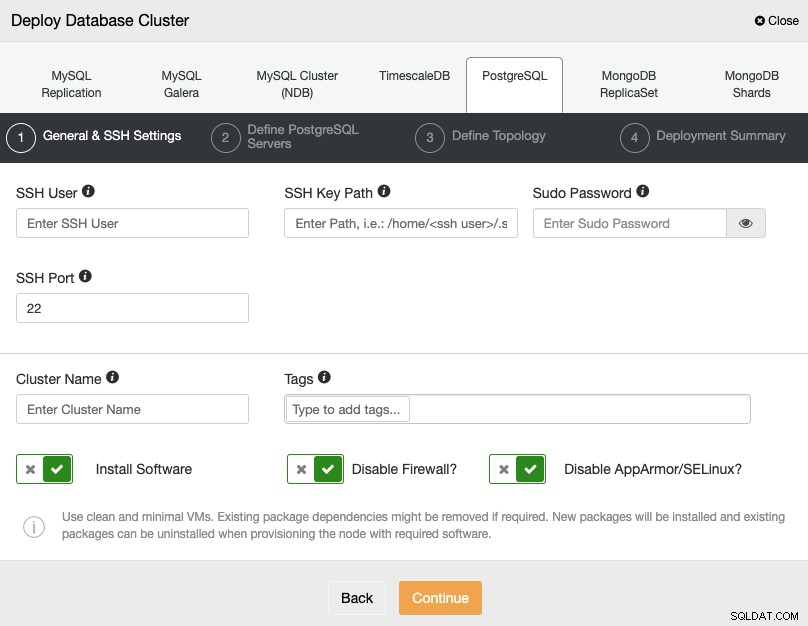
Wybierając PostgreSQL, musisz określić Użytkownika, Klucz lub Hasło oraz Port do łączenia się przez SSH z Twoimi serwerami. Możesz również dodać nazwę dla nowego klastra i określić, czy chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
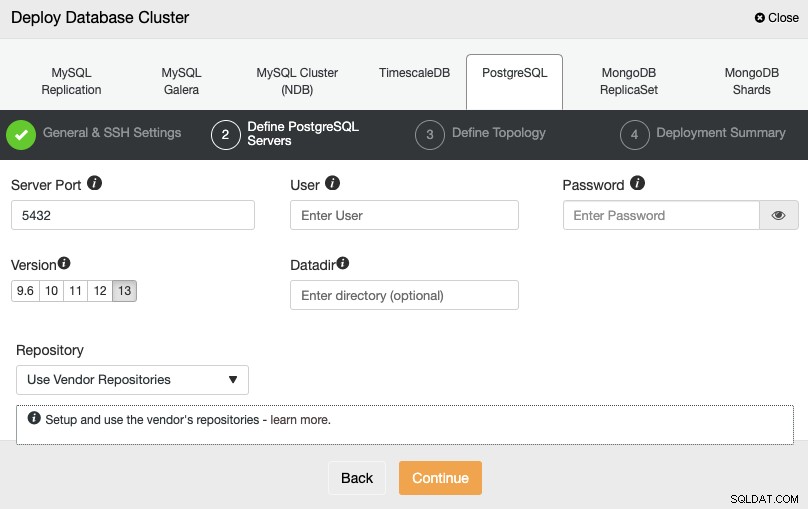
Po skonfigurowaniu informacji dostępu SSH należy zdefiniować poświadczenia bazy danych , wersja i katalog danych (opcjonalnie). Możesz także określić, którego repozytorium chcesz użyć.
W następnym kroku musisz dodać swoje serwery do klastra, który zamierzasz utworzyć przy użyciu adresu IP lub nazwy hosta.
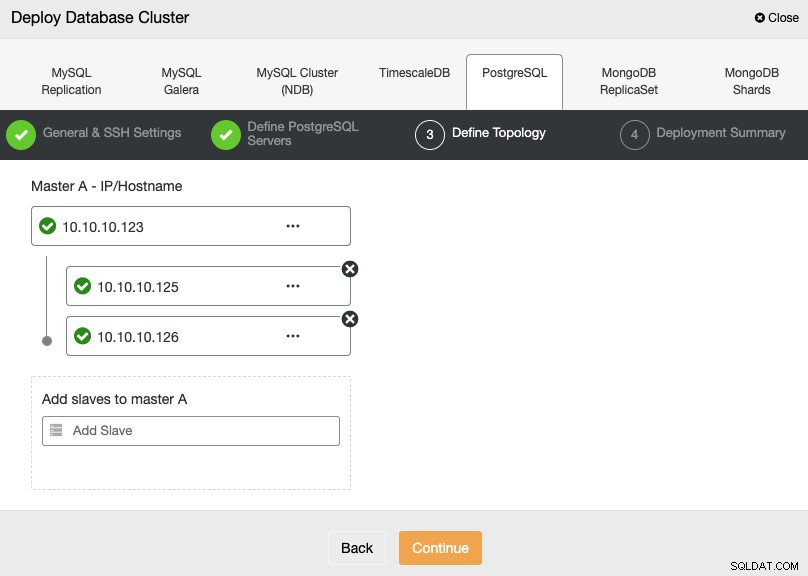
W ostatnim kroku możesz wybrać, czy twoja replikacja będzie synchroniczna, czy Asynchronicznie, a następnie po prostu naciśnij Wdróż.
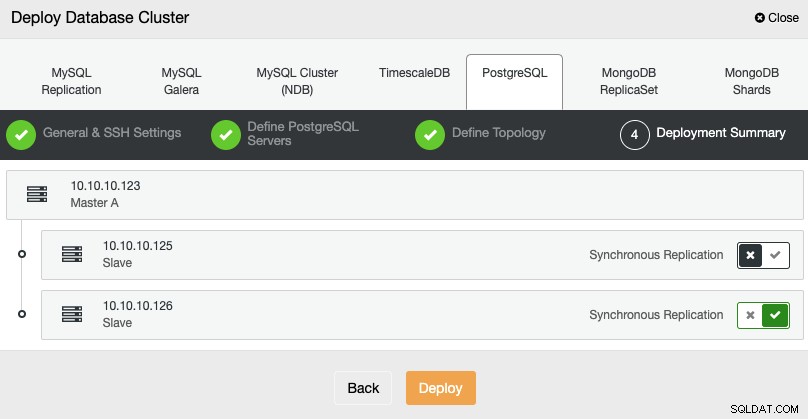
Po zakończeniu zadania możesz zobaczyć swój nowy klaster PostgreSQL w główny ekran ClusterControl.

Teraz masz już utworzony klaster, możesz wykonać na nim kilka zadań, jak dodanie modułu równoważenia obciążenia (HAProxy), puli połączeń (PgBouncer) lub nowego niewolnika replikacji synchronicznej lub asynchronicznej.
Dodawanie synchronicznych i asynchronicznych niewolników replikacji
Przejdź do ClusterControl -> Cluster Actions -> Add Replication Slave.
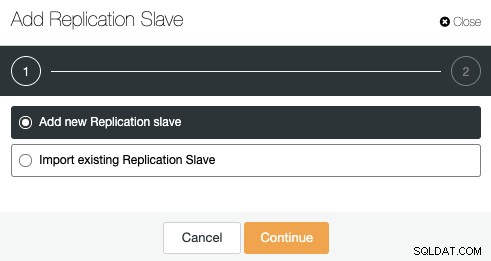
Możesz dodać nowe urządzenie podrzędne replikacji, a nawet zaimportować istniejące. Wybierzmy pierwszą opcję i kontynuuj.
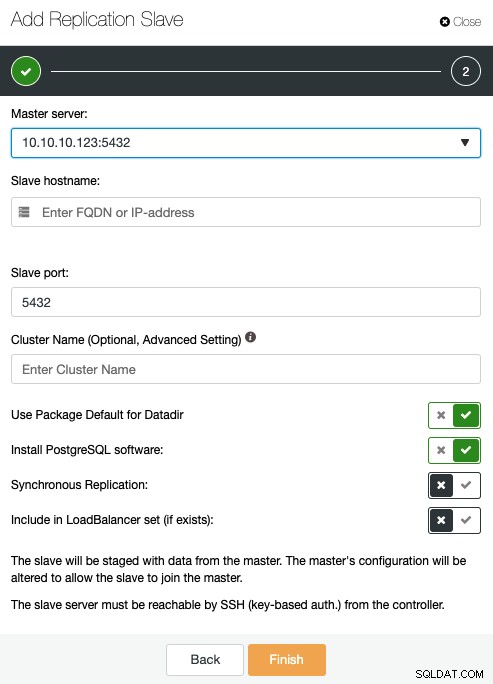
W tym miejscu należy określić serwer główny, adres IP lub nazwę hosta nowe urządzenie podrzędne replikacji, port i, jeśli chcesz, ClusterControl, zainstaluj oprogramowanie lub dołącz ten węzeł do istniejącego modułu równoważenia obciążenia. Możesz także skonfigurować replikację tak, aby była synchroniczna lub asynchroniczna.
Teraz masz już swój klaster PostgreSQL z odpowiednimi replikami, zobaczmy, jak poprawić wydajność przez dodanie puli połączeń.
Wdrożenie PgBouncera
Przejdź do ClusterControl -> Wybierz Klaster PostgreSQL -> Akcje klastra -> Dodaj Load Balancer -> PgBouncer. Tutaj możesz wdrożyć nowy węzeł PgBouncer, który zostanie wdrożony w wybranym węźle bazy danych, a nawet zaimportować istniejący PgBouncer.
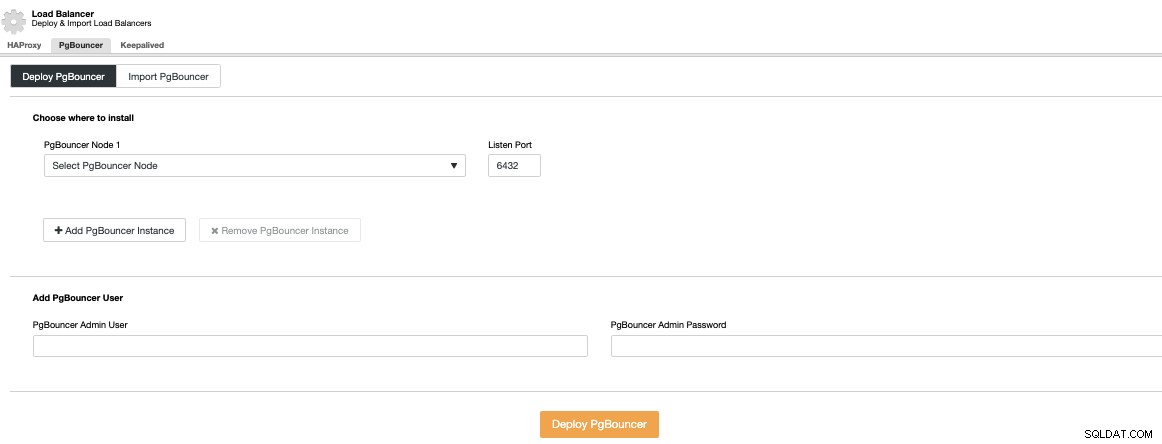
Musisz podać adres IP lub nazwę hosta, port nasłuchiwania i Poświadczenia PgBouncera. Po naciśnięciu przycisku Wdróż PgBouncer, ClusterControl uzyska dostęp do węzła, zainstaluje i skonfiguruje wszystko bez ręcznej interwencji.
Możesz monitorować postęp w sekcji Aktywność ClusterControl. Po zakończeniu musisz utworzyć nową pulę. W tym celu przejdź do ClusterControl -> Wybierz klaster PostgreSQL -> Węzły -> węzeł PgBouncer.
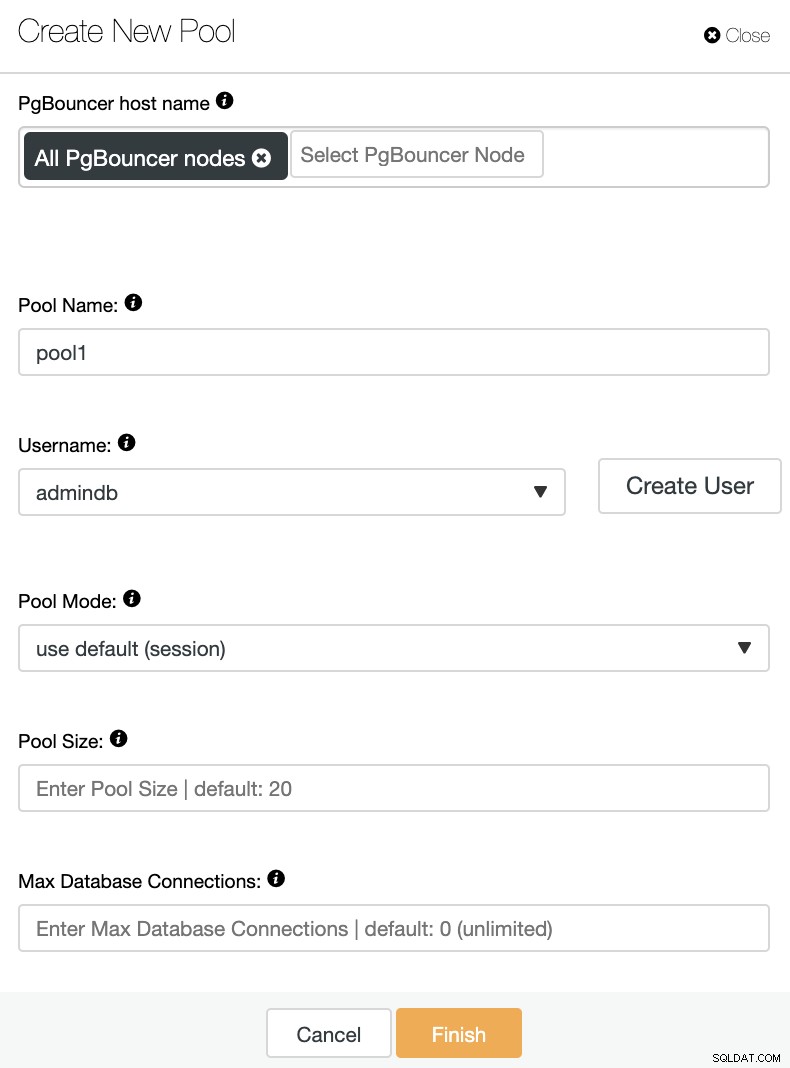
Musisz dodać następujące informacje:
-
Nazwa hosta PgBouncer:Wybierz hosty węzłów, aby utworzyć pulę połączeń.
-
Nazwa puli:Nazwy puli i bazy danych muszą być takie same.
-
Nazwa użytkownika:wybierz użytkownika z węzła podstawowego PostgreSQL lub utwórz nowego.
-
Tryb puli:może to być:łączenie sesji (domyślnie), transakcji lub wyciągów.
-
Rozmiar puli:Maksymalny rozmiar pul dla tej bazy danych. Domyślna wartość to 20.
-
Maksymalna liczba połączeń z bazą danych:Skonfiguruj maksimum dla całej bazy danych. Domyślna wartość to 0, co oznacza nieograniczoną liczbę.
Teraz powinieneś być w stanie zobaczyć Pulę w sekcji Węzeł.
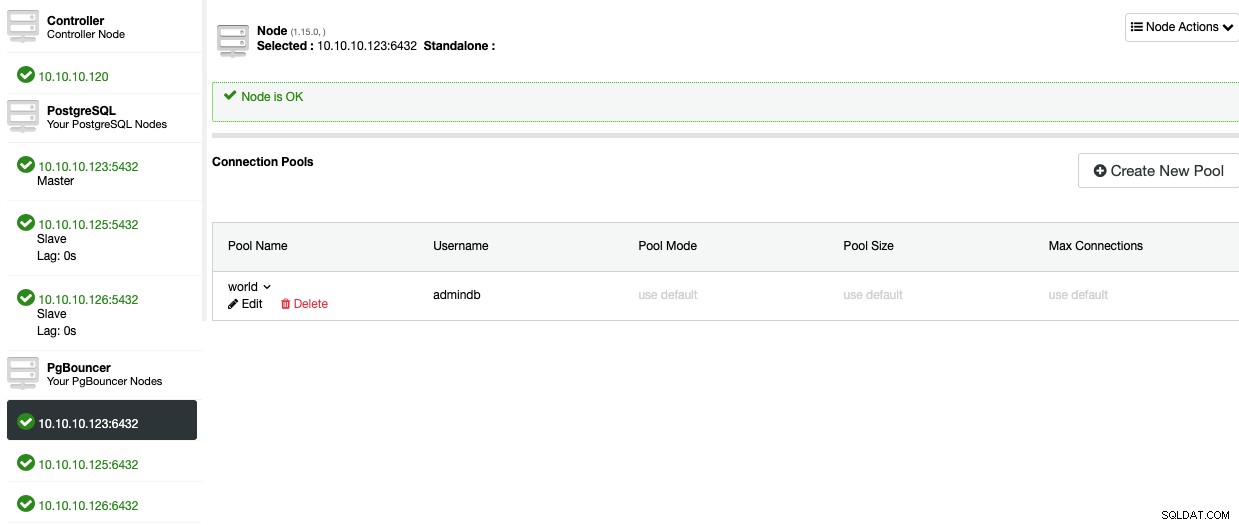
Aby dodać wysoką dostępność do bazy danych PostgreSQL, zobaczmy, jak wdrożyć system równoważenia obciążenia.
Wdrażanie systemu równoważenia obciążenia
Aby przeprowadzić wdrożenie systemu równoważenia obciążenia, wybierz opcję Dodaj system równoważenia obciążenia w menu Akcje klastra i uzupełnij wymagane informacje.
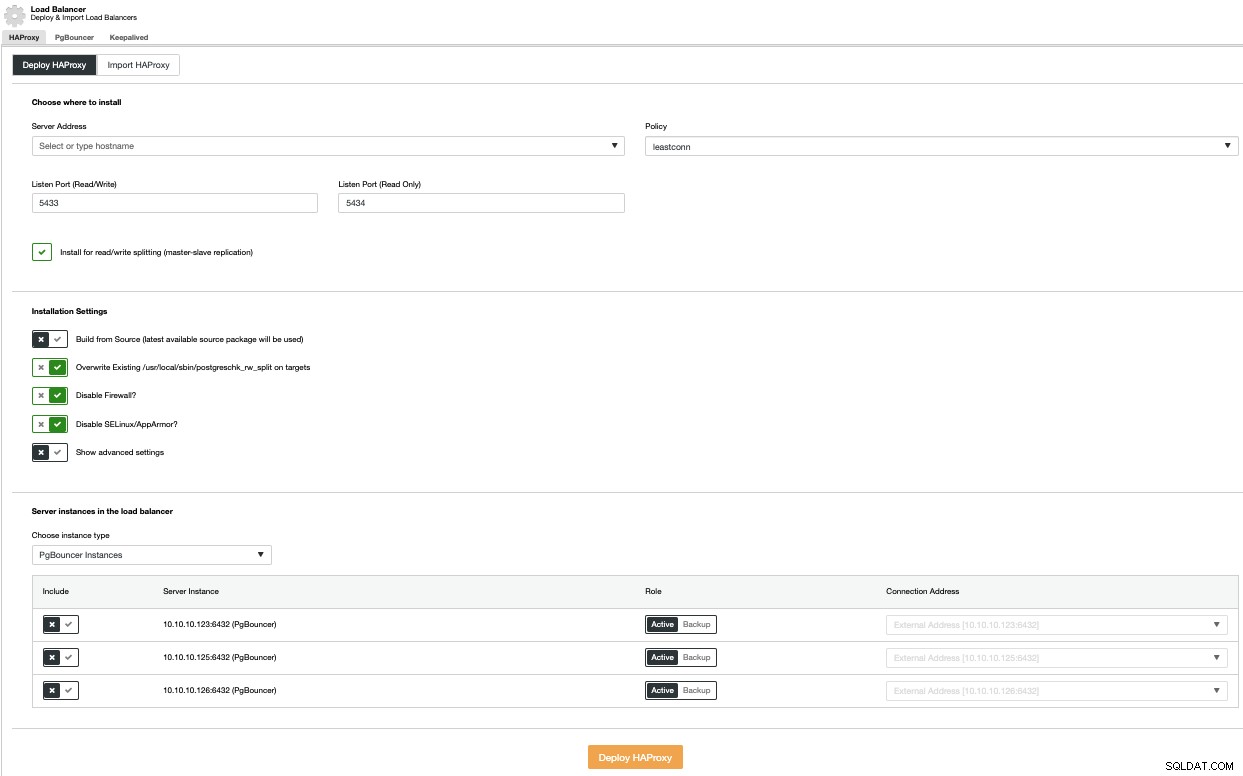
Musisz dodać adres IP lub nazwę hosta, port, zasady i węzły zamierzasz użyć. Jeśli używasz PgBouncera, możesz go wybrać w polu kombi typu instancji.
Aby uniknąć pojedynczego punktu awarii, należy wdrożyć co najmniej dwa węzły HAProxy i użyć funkcji Keepalived, która pozwala na użycie wirtualnego adresu IP w aplikacji, który jest przypisany do aktywnego węzła HAProxy. Jeśli ten węzeł ulegnie awarii, wirtualny adres IP zostanie przeniesiony do pomocniczego systemu równoważenia obciążenia, dzięki czemu Twoja aplikacja będzie mogła nadal działać normalnie.
Utrzymywane wdrażanie
Aby przeprowadzić wdrożenie z podtrzymaniem, wybierz opcję Dodaj równoważenie obciążenia w menu Akcje klastra, a następnie przejdź do zakładki Zachowaj aktywność.
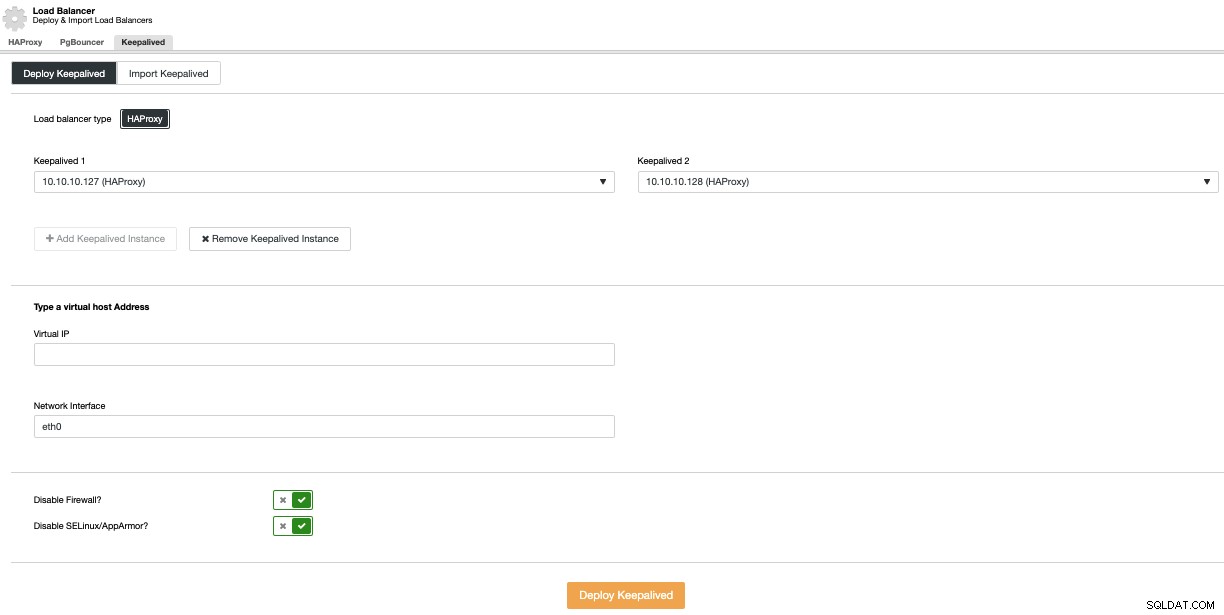
Tutaj wybierz węzły HAProxy i określ wirtualny adres IP, który będzie być używany do uzyskania dostępu do bazy danych (lub puli połączeń).
W tej chwili powinieneś mieć następującą topologię:
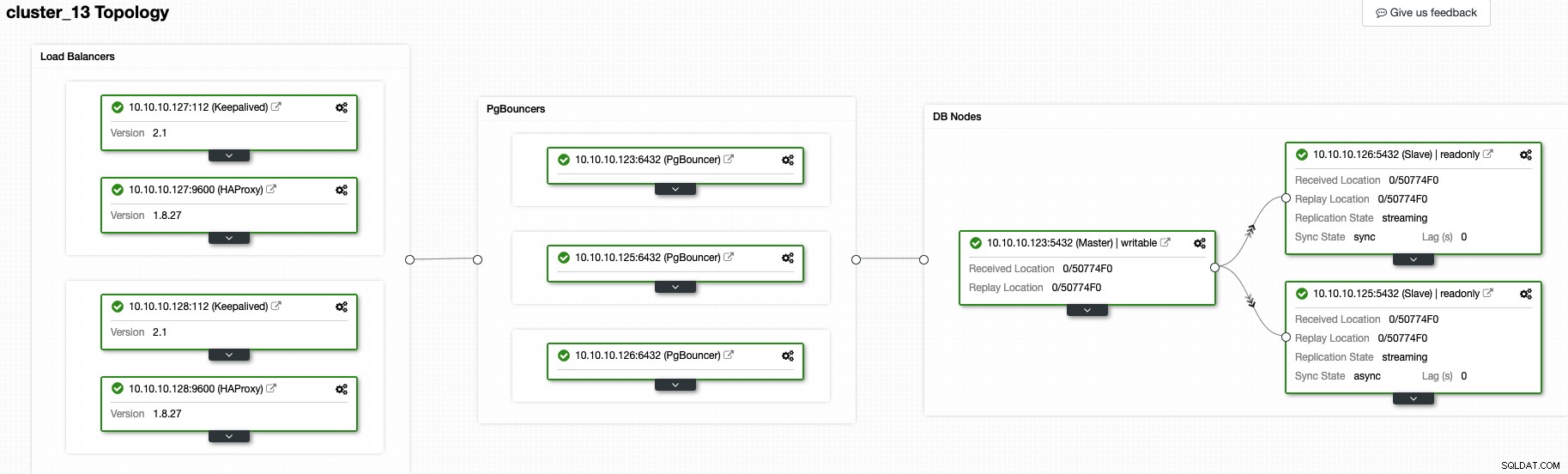
A to oznacza:HAProxy + Keepalived -> PgBouncer -> Węzły bazy danych PostgreSQL , to jest dobra topologia dla twojego klastra PostgreSQL.
Funkcja automatycznego odzyskiwania ClusterControl
W przypadku awarii, ClusterControl przeniesie najbardziej zaawansowany węzeł gotowości do stanu podstawowego, a także powiadomi Cię o problemie. Replikacja z nowego serwera głównego jest również błędna w stosunku do reszty węzła rezerwowego.
Domyślnie HAProxy jest skonfigurowane z dwoma różnymi portami:do odczytu-zapisu i tylko do odczytu. Na porcie do odczytu i zapisu masz węzeł podstawowej bazy danych (lub PgBouncer) w trybie online, a pozostałe węzły w trybie offline, a na porcie tylko do odczytu masz w trybie online zarówno węzły podstawowe, jak i rezerwowe.
Gdy HAProxy wykryje, że jeden z twoich węzłów jest niedostępny, automatycznie oznacza go jako offline i nie bierze pod uwagę przy wysyłaniu do niego ruchu. Wykrywanie odbywa się za pomocą skryptów sprawdzania kondycji, które są konfigurowane przez ClusterControl w czasie wdrażania. Sprawdzają one, czy instancje działają, czy są w trakcie odzyskiwania, czy są tylko do odczytu.
Gdy ClusterControl promuje węzeł rezerwowy, HAProxy oznacza stary podstawowy jako offline dla obu portów i umieszcza promowany węzeł online w porcie do odczytu i zapisu.
Jeśli twój aktywny HAProxy, któremu przypisany jest wirtualny adres IP, z którym łączą się twoje systemy, ulegnie awarii, Keepalived automatycznie migruje ten adres IP do pasywnego HAProxy. Oznacza to, że Twoje systemy będą mogły dalej normalnie funkcjonować.
Wnioski
Jak widać, posiadanie dobrej topologii PostgreSQL jest łatwe, jeśli używasz ClusterControl i jeśli postępujesz zgodnie z podstawowymi zasadami najlepszych praktyk dotyczących replikacji PostgreSQL. Oczywiście najlepsze środowisko zależy od obciążenia, sprzętu, aplikacji itp., ale możesz użyć go jako przykładu i przenieść elementy według potrzeb.