Replikacja odgrywa kluczową rolę w utrzymaniu wysokiej dostępności. Serwery mogą ulec awarii, system operacyjny lub oprogramowanie bazy danych może wymagać aktualizacji. Oznacza to zmianę ról serwera i przeniesienie łączy replikacji przy jednoczesnym zachowaniu spójności danych we wszystkich bazach danych. Konieczne będą zmiany topologii i istnieją różne sposoby ich wykonania.
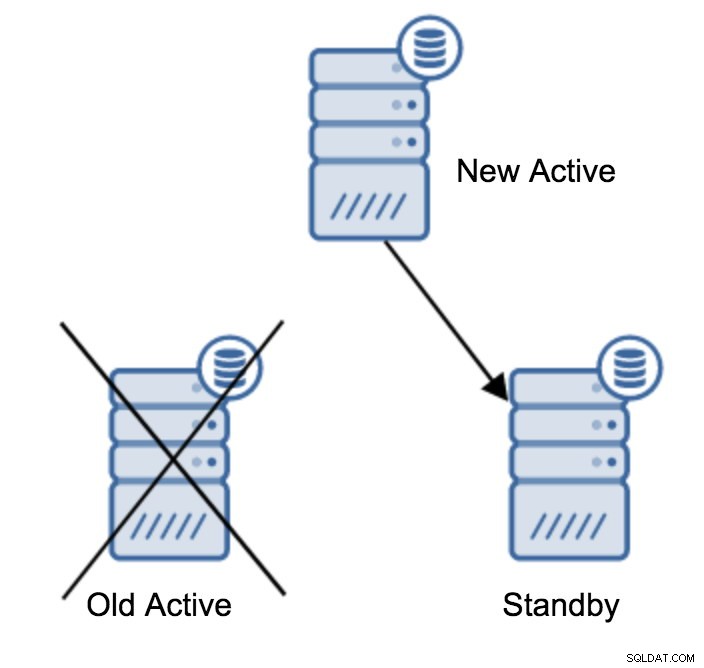
Promowanie serwera w trybie gotowości
Prawdopodobnie jest to najczęstsza operacja, którą będziesz musiał wykonać. Istnieje wiele przyczyn — na przykład konserwacja bazy danych na serwerze głównym, która wpłynęłaby na obciążenie w niedopuszczalny sposób. Może być planowany przestój spowodowany niektórymi operacjami sprzętowymi. Awaria serwera głównego, która uniemożliwia dostęp do aplikacji. To wszystko są powody, aby wykonać przełączanie awaryjne, niezależnie od tego, czy jest planowane, czy nie. We wszystkich przypadkach będziesz musiał promować jeden z serwerów rezerwowych, aby stał się nowym serwerem głównym.
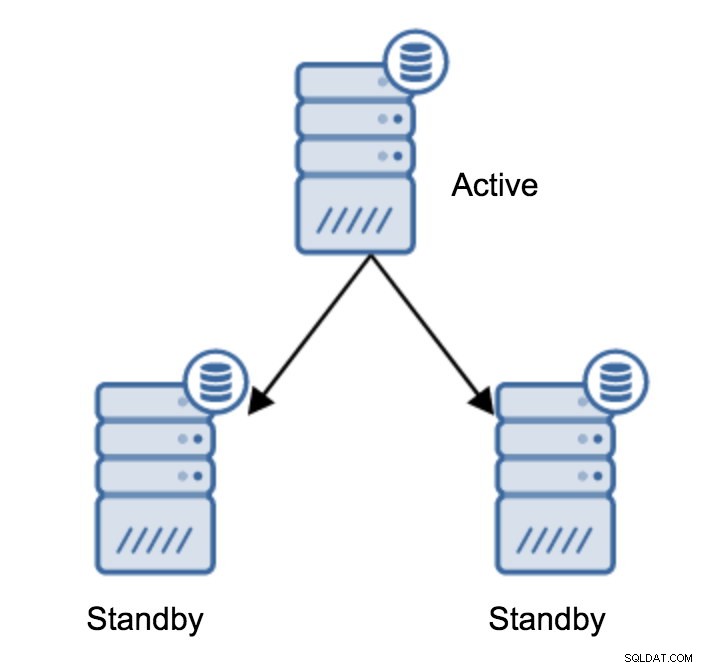
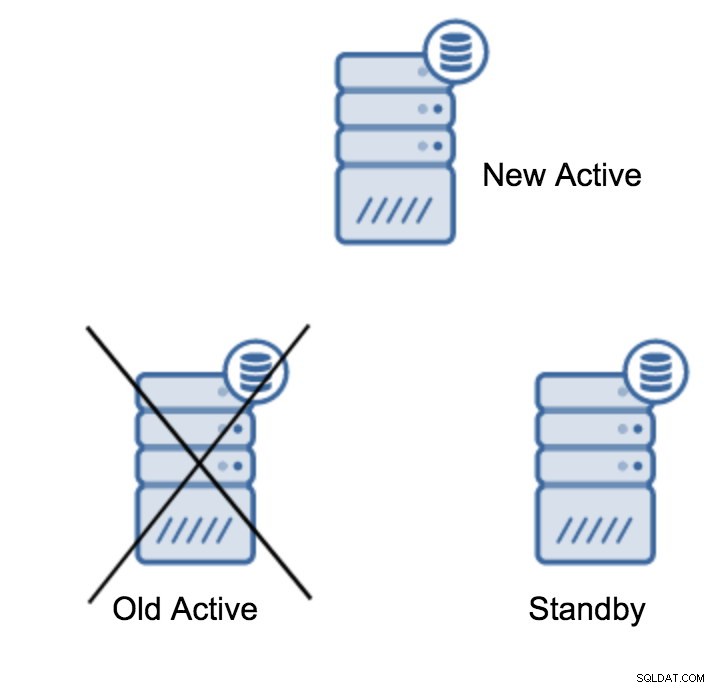
Aby promować serwer rezerwowy, musisz uruchomić:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
server promotedUruchomienie tego polecenia jest łatwe, ale najpierw upewnij się, że nie utracisz danych. Jeśli mówimy o scenariuszu „awarii głównego serwera”, możesz nie mieć zbyt wielu opcji. Jeśli jest to planowana konserwacja, to można się do niej przygotować. Należy zatrzymać ruch na serwerze podstawowym, a następnie sprawdzić, czy serwer rezerwowy odebrał i zastosował wszystkie dane. Można to zrobić na serwerze rezerwowym, używając zapytania jak poniżej:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Gdy wszystko będzie dobrze, możesz zatrzymać stary serwer główny i promować serwer rezerwowy.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentZwalnianie serwera rezerwowego z nowego serwera głównego
Możesz mieć więcej niż jeden serwer rezerwowy, który jest podporządkowany serwerowi głównemu. W końcu serwery rezerwowe są przydatne do odciążania ruchu tylko do odczytu. Po awansowaniu serwera rezerwowego na nowy serwer główny należy coś zrobić z pozostałymi serwerami rezerwowymi, które są nadal połączone (lub próbują się połączyć) ze starym serwerem głównym. Niestety nie można po prostu zmienić pliku recovery.conf i połączyć go z nowym serwerem głównym. Aby je połączyć, musisz je najpierw odbudować. Istnieją dwie metody, które możesz wypróbować tutaj:standardowa podstawowa kopia zapasowa lub pg_rewind.
Nie będziemy wchodzić w szczegóły, jak wykonać kopię zapasową bazy — omówiliśmy to w naszym poprzednim poście na blogu, który skupiał się na robieniu kopii zapasowych i przywracaniu ich w PostgreSQL. Jeśli używasz ClusterControl, możesz również użyć go do utworzenia podstawowej kopii zapasowej:
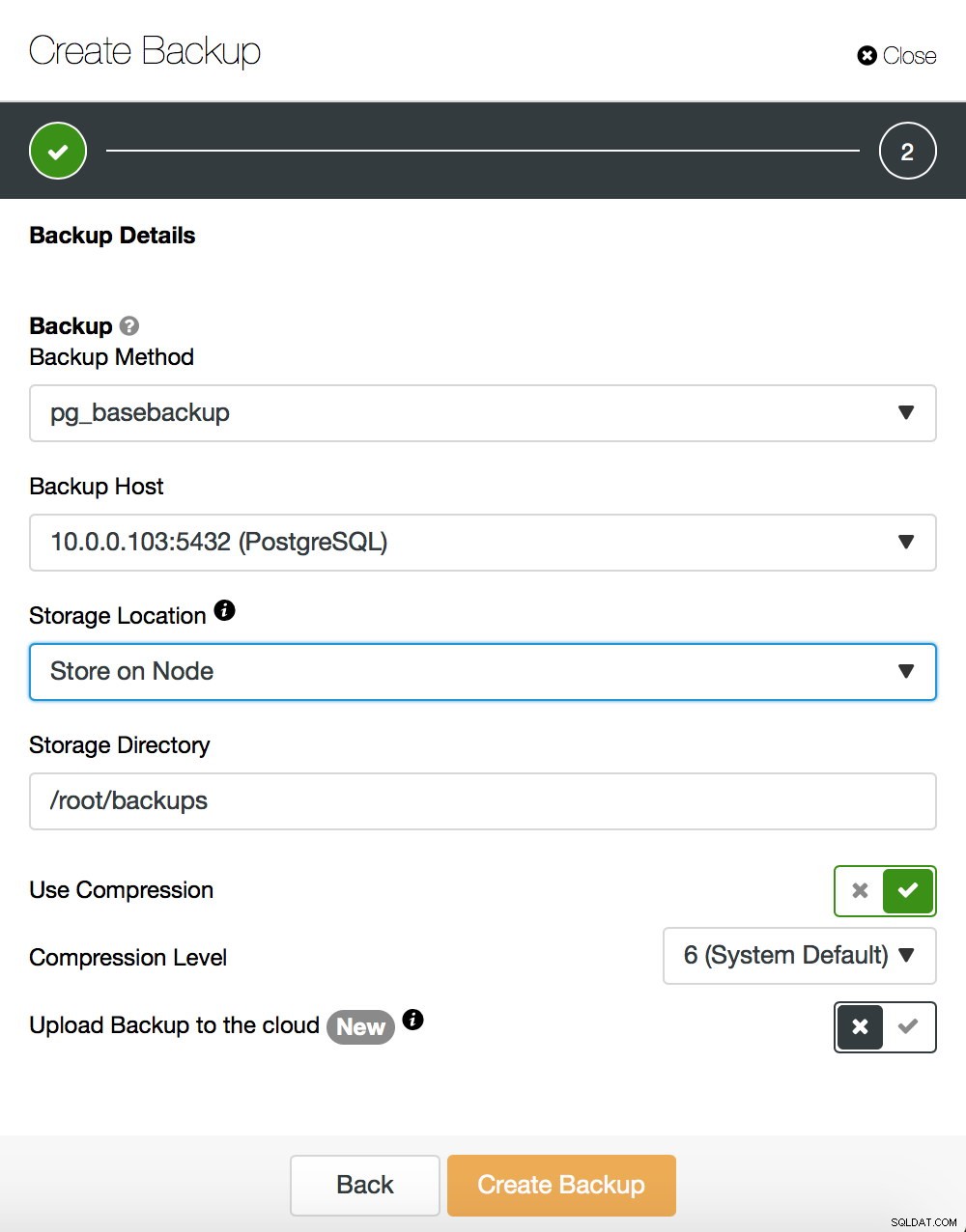
Z drugiej strony powiedzmy kilka słów o pg_rewind. Główna różnica między obiema metodami polega na tym, że podstawowa kopia zapasowa tworzy pełną kopię zestawu danych. Jeśli mówimy o małych zestawach danych, może to być w porządku, ale w przypadku zestawów danych o rozmiarze setek gigabajtów (lub nawet większych) może to szybko stać się problemem. W końcu chcesz, aby serwery rezerwowe były szybko gotowe do pracy — aby odciążyć serwer aktywny i mieć inny rezerwowy, na który można by było przełączać się awaryjnie, gdyby zaistniała taka potrzeba. Pg_rewind działa inaczej - kopiuje tylko te bloki, które zostały zmodyfikowane. Zamiast kopiować wszystko, kopiuje tylko zmiany, znacznie przyspieszając proces. Załóżmy, że twój nowy master ma IP 10.0.0.103. W ten sposób możesz wykonać pg_rewind. Pamiętaj, że musisz zatrzymać serwer docelowy - PostgreSQL nie może tam działać.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Spowoduje to pracę na sucho , testując proces, ale nie wprowadzając żadnych zmian. Jeśli wszystko jest w porządku, wystarczy, że uruchomisz go ponownie, tym razem bez parametru „--dry-run”. Po zakończeniu ostatnim pozostałym krokiem będzie utworzenie pliku recovery.conf, który wskaże nowy master. Może to wyglądać tak:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Teraz jesteś gotowy do uruchomienia serwera rezerwowego, który wykona replikację z nowego aktywnego serwera.
Replikacja łańcuchowa
Istnieje wiele powodów, dla których warto zbudować replikację łańcuchową, chociaż zwykle robi się to w celu zmniejszenia obciążenia serwera podstawowego. Udostępnianie WAL serwerom w stanie gotowości wiąże się z pewnym obciążeniem. Nie jest to duży problem, jeśli masz jeden lub dwa serwery w trybie gotowości, ale jeśli mówimy o dużej liczbie serwerów w trybie gotowości, może to stać się problemem. Na przykład, możemy zminimalizować liczbę serwerów rezerwowych replikujących się bezpośrednio z aktywnych, tworząc topologię jak poniżej:
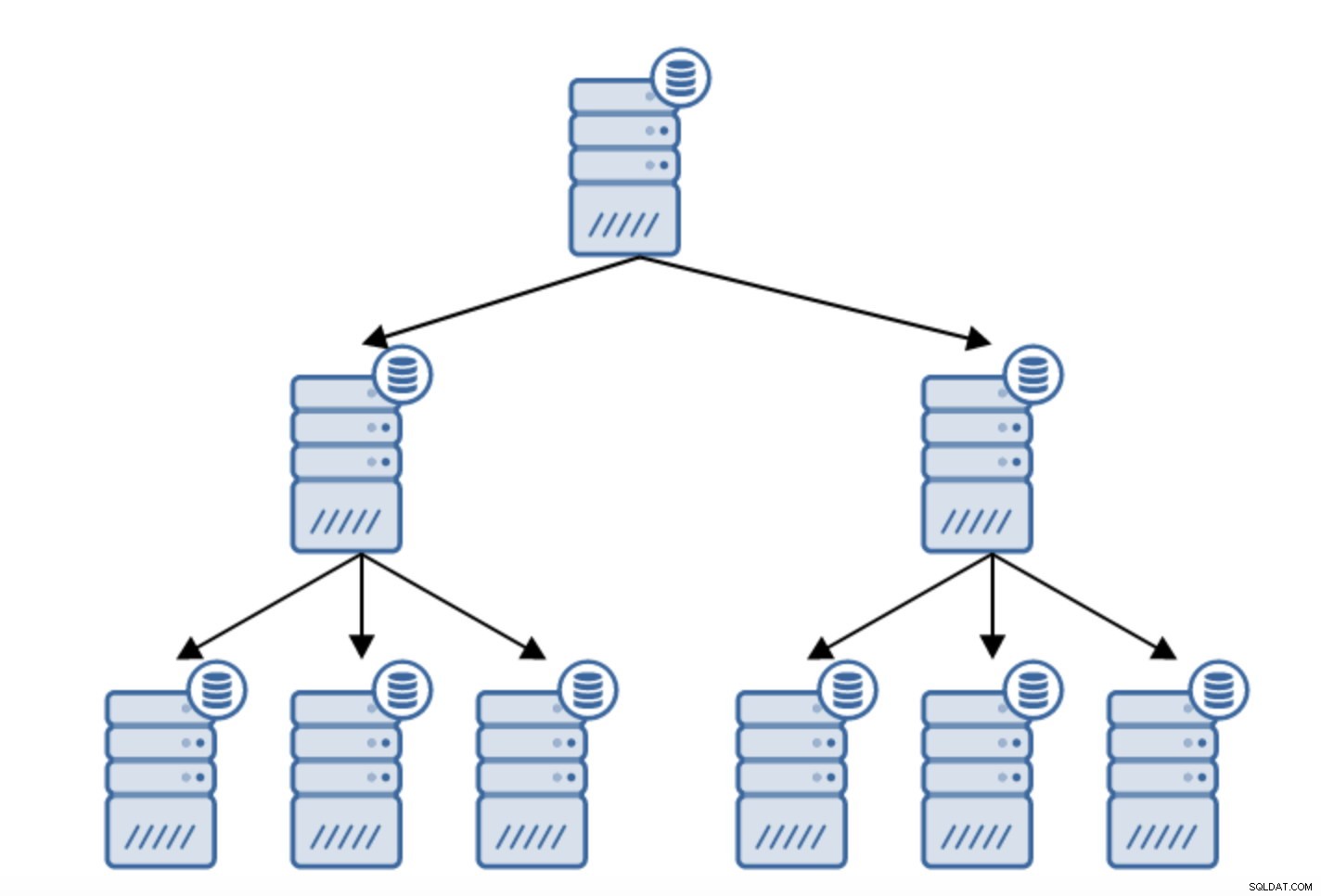
Przejście z topologii dwóch serwerów rezerwowych do replikacji łańcuchowej jest dość proste.
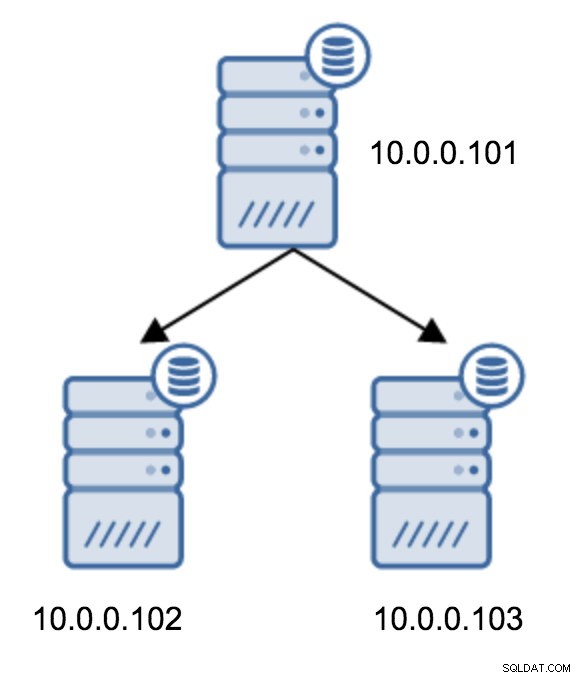
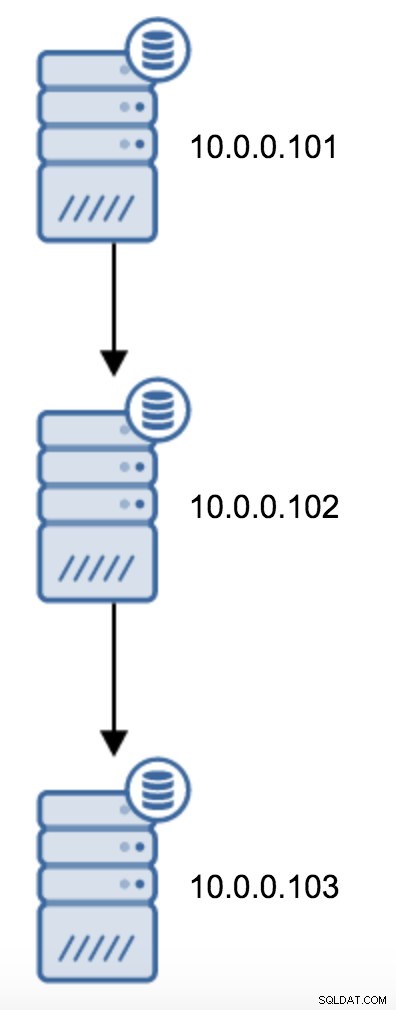
Będziesz musiał zmodyfikować plik recovery.conf w 10.0.0.103, skierować go na 10.0.0.102, a następnie ponownie uruchomić PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Po ponownym uruchomieniu 10.0.0.103 powinien zacząć stosować aktualizacje WAL.
Oto kilka typowych przypadków zmian topologii. Jednym z tematów, który nie został omówiony, ale który nadal jest ważny, jest wpływ tych zmian na aplikacje. Opowiemy o tym w osobnym poście, a także o tym, jak sprawić, by te zmiany topologii były przezroczyste dla aplikacji.