Warstwa proxy może być bardzo przydatna w zwiększaniu dostępności warstwy bazy danych. Może zmniejszyć ilość kodu po stronie aplikacji, aby obsłużyć awarie bazy danych i zmiany topologii replikacji. W tym poście na blogu omówimy, jak skonfigurować HAProxy do pracy z PostgreSQL.
Po pierwsze - HAProxy współpracuje z bazami danych jako serwer proxy warstwy sieciowej. Nie ma zrozumienia podstawowej, czasami złożonej topologii. Wszystko, co robi HAProxy, to wysyłanie pakietów w sposób okrężny do zdefiniowanych backendów. Nie sprawdza pakietów ani nie rozumie protokołu, w którym aplikacje komunikują się z PostgreSQL. W rezultacie HAProxy nie ma możliwości zaimplementowania podziału odczytu/zapisu na jednym porcie – wymagałoby to parsowania zapytań. Dopóki Twoja aplikacja może rozdzielać odczyty od zapisów i wysyłać je do różnych adresów IP lub portów, możesz zaimplementować podział R/W za pomocą dwóch zaplecza. Zobaczmy, jak można to zrobić.
Konfiguracja HAProxy
Poniżej znajdziesz przykład dwóch backendów PostgreSQL skonfigurowanych w HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkJak widać, używają portów 3307 do zapisu i 3308 do odczytu. W tej konfiguracji są trzy serwery - jedna aktywna i dwie rezerwowe. Co ważne, tcp-check służy do śledzenia kondycji węzłów. HAProxy połączy się z portem 9201 i oczekuje, że otrzyma zwrócony ciąg znaków. Zdrowi członkowie backendu zwrócą oczekiwaną zawartość, a ci, którzy nie zwrócą ciągu, zostaną oznaczeni jako niedostępni.
Konfiguracja Xinetd
Ponieważ HAProxy sprawdza port 9201, coś musi na nim nasłuchiwać. Możemy użyć xinetd, aby tam nasłuchiwać i uruchamiać dla nas kilka skryptów. Przykładowa konfiguracja takiej usługi może wyglądać następująco:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Upewnij się, że dodałeś linię:
postgreschk 9201/tcpdo /etc/services.
Xinetd uruchamia skrypt postgreschk, którego zawartość jest taka jak poniżej:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Logika skryptu wygląda następująco. Istnieją dwa zapytania, które są używane do wykrywania stanu węzła.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Pierwsze sprawdza, czy PostgreSQL jest w trakcie odzyskiwania - będzie „fałsz” dla aktywnego serwera i „prawda” dla serwerów rezerwowych. Drugi sprawdza, czy PostgreSQL jest w trybie tylko do odczytu. Aktywny serwer zwróci „wyłączony”, a serwery rezerwowe wrócą „włączony”. Na podstawie wyników skrypt wywołuje funkcję return_ok() z odpowiednim parametrem („master” lub „slave”, w zależności od tego, co zostało wykryte). Jeśli zapytania się nie powiodą, zostanie wykonana funkcja ‘return_fail’.
Funkcja Return_ok zwraca ciąg znaków na podstawie przekazanego do niej argumentu. Jeśli host jest aktywnym serwerem, skrypt zwróci komunikat „Uruchomiony jest serwer PostgreSQL”. Jeśli jest w trybie gotowości, zwrócony ciąg będzie następujący:„Uruchomiony serwer PostgreSQL”. Jeśli stan nie jest jasny, zwróci:„PostgreSQL działa”. Tutaj kończy się pętla. HAProxy sprawdza stan, łącząc się z xinetd. Ten ostatni uruchamia skrypt, który następnie zwraca ciąg, który analizuje HAProxy.
Jak być może pamiętasz, HAProxy oczekuje następujących ciągów:
tcp-check expect string master\ is\ runningdla backendu zapisu i
tcp-check expect string is\ running.dla zaplecza tylko do odczytu. To sprawia, że serwer aktywny jest jedynym hostem dostępnym w backendzie zapisu, podczas gdy w backendzie odczytu, można używać zarówno serwerów aktywnych, jak i rezerwowych.
PostgreSQL i HAProxy w ClusterControl
Powyższa konfiguracja nie jest skomplikowana, ale jej skonfigurowanie zajmuje trochę czasu. ClusterControl może być użyty do ustawienia tego wszystkiego za Ciebie.
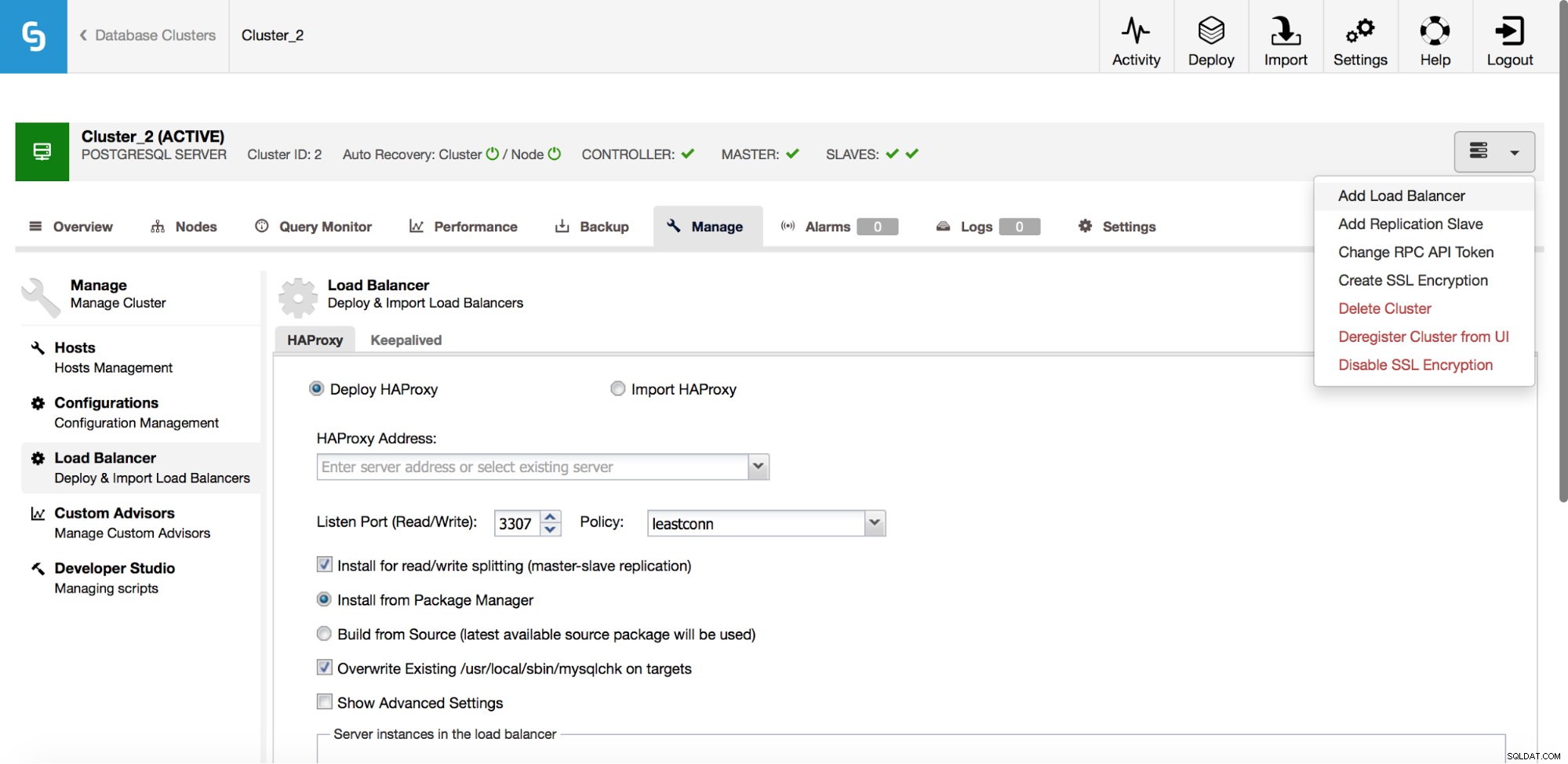
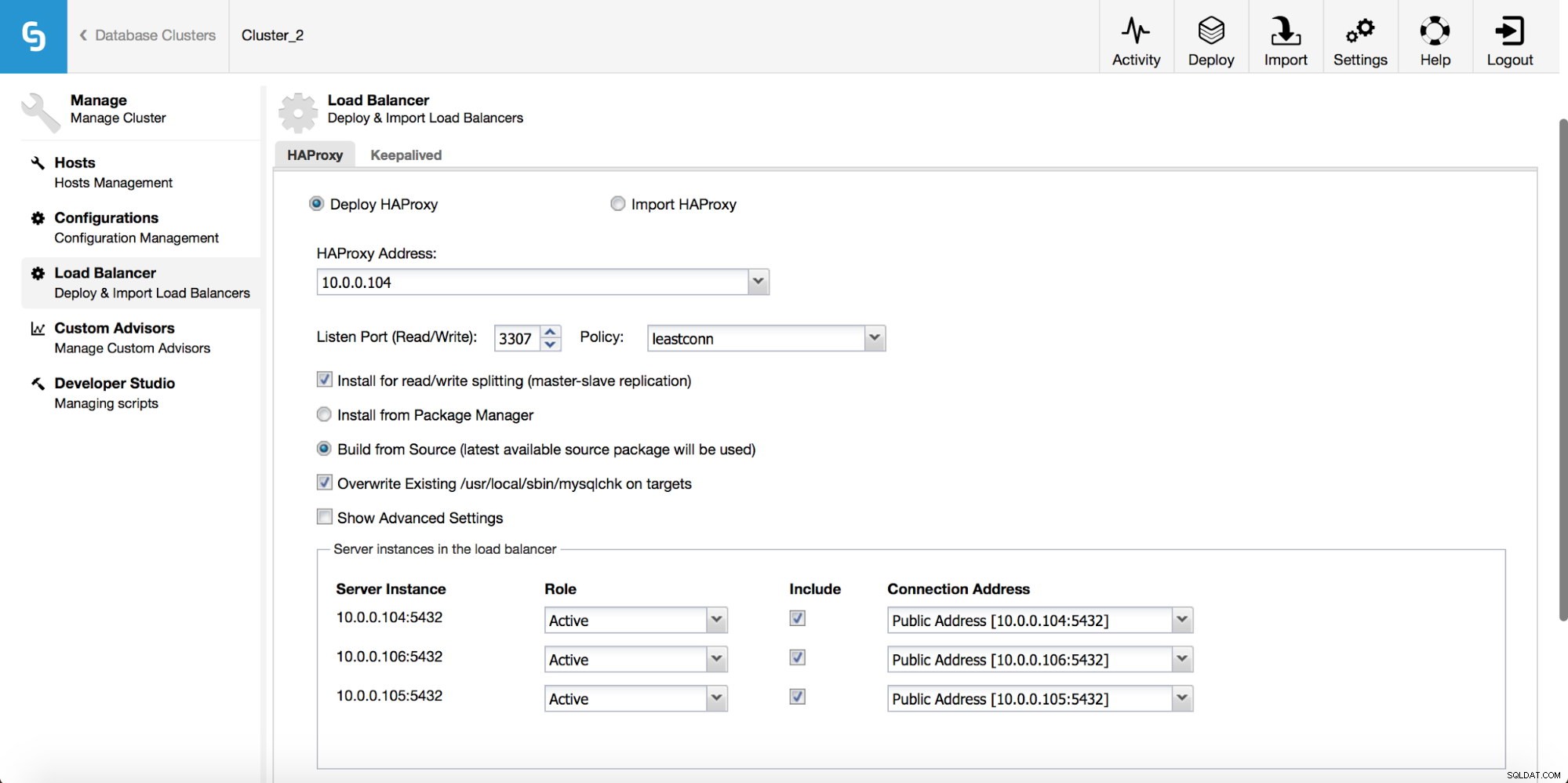
W menu rozwijanym zadania klastra masz możliwość dodania modułu równoważenia obciążenia. Następnie pojawia się opcja wdrożenia HAProxy. Musisz wpisać, gdzie chcesz go zainstalować i podjąć pewne decyzje:z repozytoriów, które skonfigurowałeś na hoście lub z najnowszej wersji, skompilowanej z kodu źródłowego. Musisz także skonfigurować węzły w klastrze, które chcesz dodać do HAProxy.
Po wdrożeniu instancji HAProxy możesz uzyskać dostęp do niektórych statystyk w zakładce „Węzły”:
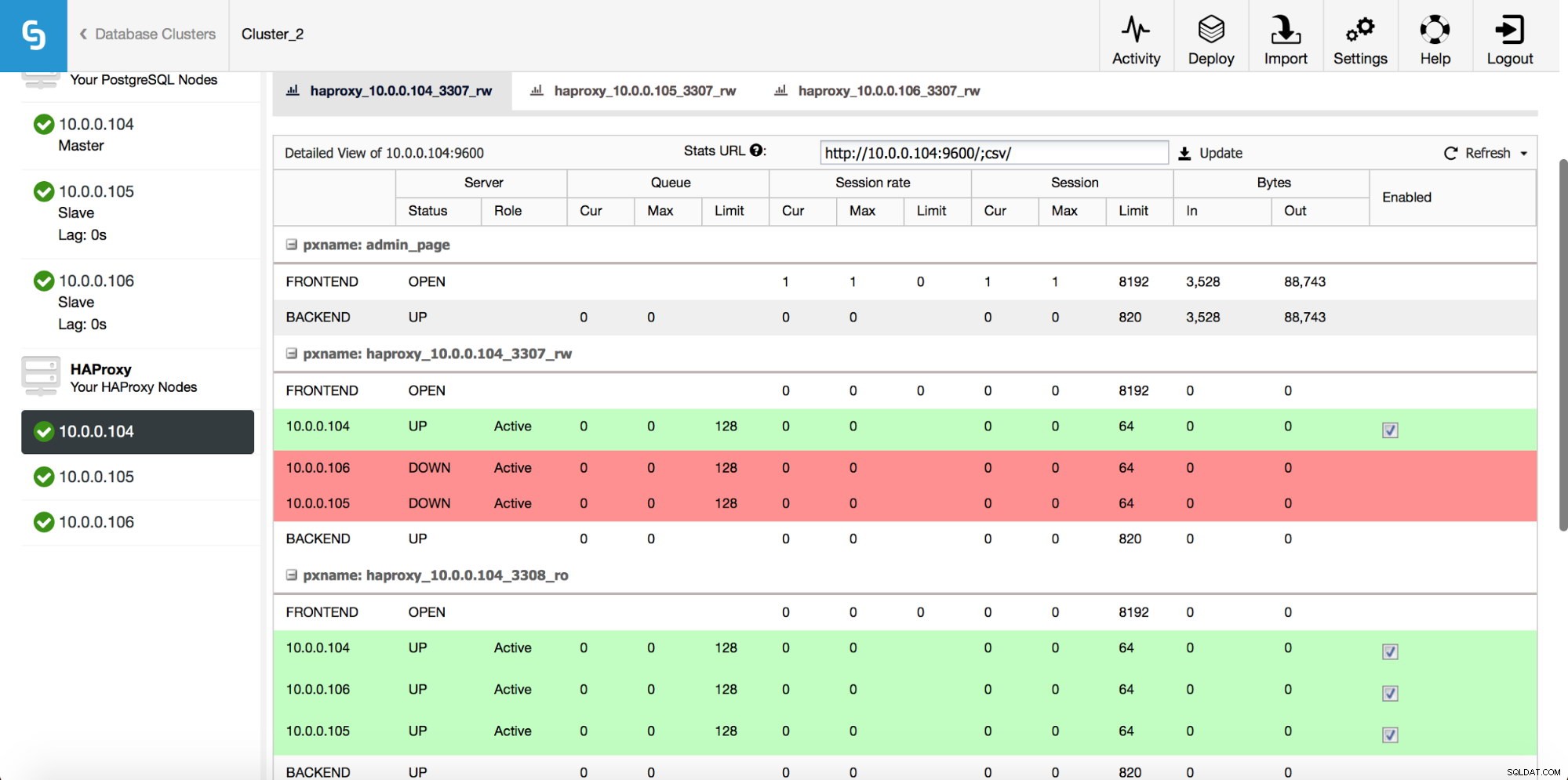
Jak widać, dla backendu R/W tylko jeden host (serwer aktywny) jest oznaczony jako włączony. W przypadku zaplecza tylko do odczytu wszystkie węzły działają.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentUtrzymane
HAProxy będzie znajdować się między aplikacjami a instancjami baz danych, więc będzie odgrywać główną rolę. Niestety może również stać się pojedynczym punktem awarii, jeśli się nie powiedzie, nie będzie trasy do baz danych. Aby uniknąć takiej sytuacji, można wdrożyć wiele instancji HAProxy. Ale wtedy pojawia się pytanie - jak zdecydować, z którym hostem proxy się połączyć. Jeśli wdrożyłeś HAProxy z ClusterControl, wystarczy uruchomić kolejne zadanie „Dodaj Load Balancer”, tym razem wdrażając Keepalived.
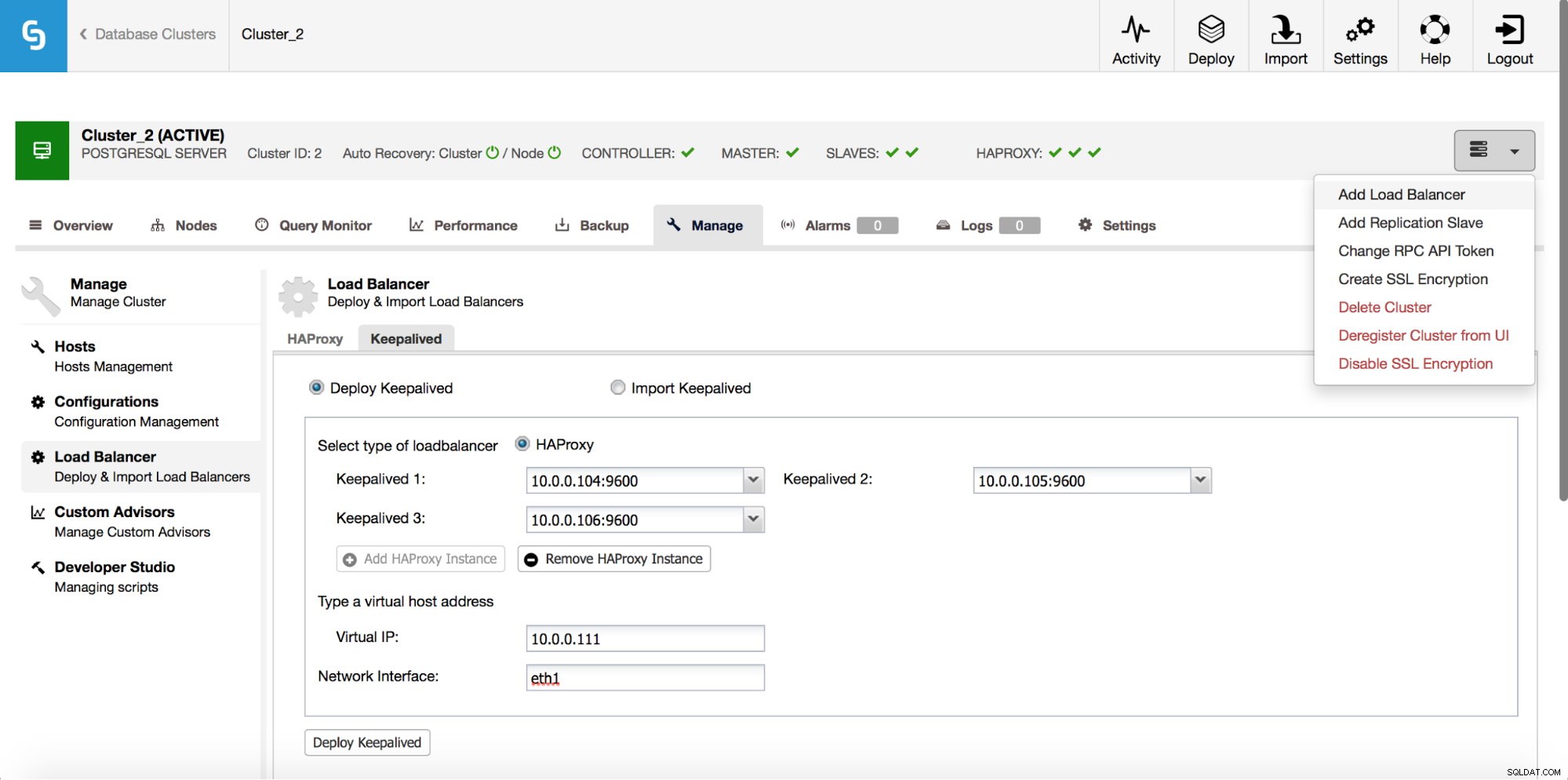
Jak widać na powyższym zrzucie ekranu, możesz wybrać do trzech hostów HAProxy, a Keepalived zostanie na nich wdrożony, monitorując ich stan. Do jednego z nich zostanie przypisany wirtualny adres IP (VIP). Twoja aplikacja powinna używać tego adresu VIP do łączenia się z bazą danych. Jeśli „aktywny” HAProxy stanie się niedostępny, VIP zostanie przeniesiony na innego hosta.
Jak widzieliśmy, wdrożenie pełnego stosu wysokiej dostępności dla PostgreSQL jest dość łatwe. Spróbuj i daj nam znać, jeśli masz jakieś uwagi.