Wejście do produkcji to bardzo ważne zadanie, które należy wcześniej dokładnie przemyśleć i zaplanować. Niektóre niezbyt dobre decyzje można później łatwo skorygować, ale inne nie. Dlatego zawsze lepiej jest poświęcić ten dodatkowy czas na czytanie oficjalnych dokumentów, książek i badań przeprowadzonych przez innych wcześnie, niż później żałować. Dotyczy to większości wdrożeń systemów komputerowych, a PostgreSQL nie jest wyjątkiem.
Wstępne planowanie systemu
Niektóre decyzje muszą zostać podjęte wcześnie, zanim system zostanie uruchomiony. DBA PostgreSQL musi odpowiedzieć na szereg pytań:Czy baza danych będzie działać na gołym metalu, maszynach wirtualnych, a nawet w kontenerach? Będzie działać w siedzibie organizacji czy w chmurze? Który system operacyjny będzie używany? Czy pamięć ma być typu wirujących dysków czy dysków SSD? Dla każdego scenariusza lub decyzji są plusy i minusy, a ostateczne wezwanie zostanie wykonane we współpracy z interesariuszami zgodnie z wymaganiami organizacji. Tradycyjnie ludzie uruchamiali PostgreSQL na gołym metalu, ale w ostatnich latach zmieniło się to dramatycznie, ponieważ coraz więcej dostawców usług chmurowych oferuje PostgreSQL jako opcję standardową, co jest oznaką szerokiego przyjęcia i rosnącej popularności PostgreSQL. Niezależnie od konkretnego rozwiązania administrator musi zapewnić bezpieczeństwo danych, co oznacza, że baza danych będzie w stanie przetrwać awarie, a to jest kryterium numer jeden przy podejmowaniu decyzji dotyczących sprzętu i pamięci masowej. To prowadzi nas do pierwszej wskazówki!
Wskazówka 1
Bez względu na to, co reklamuje kontroler dysku, producent dysku lub dostawca pamięci masowej w chmurze, należy zawsze upewnić się, że pamięć nie kłamie o fsync. Gdy fsync zwróci OK, dane powinny być bezpieczne na nośniku bez względu na to, co stanie się później (awaria, awaria zasilania itp.). Jednym z fajnych narzędzi, które pomoże Ci przetestować niezawodność pamięci podręcznej zapisu zwrotnego Twoich dysków, jest diskchecker.pl.
Po prostu przeczytaj notatki:https://brad.livejournal.com/2116715.html i wykonaj test.
Użyj jednej maszyny do nasłuchiwania zdarzeń i rzeczywistej maszyny do testowania. Powinieneś zobaczyć:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0na końcu raportu o testowanej maszynie.
Druga troska po niezawodności powinna dotyczyć wydajności. Decyzje dotyczące systemu (procesor, pamięć) były kiedyś o wiele ważniejsze, ponieważ później trudno było je zmienić. Ale w dzisiejszych czasach, w erze chmury, możemy być bardziej elastyczni, jeśli chodzi o systemy, na których działa baza danych. To samo dotyczy pamięci masowej, zwłaszcza we wczesnym okresie życia systemu i gdy rozmiary są nadal małe. Kiedy baza danych przekroczy rozmiar TB, staje się coraz trudniej zmienić podstawowe parametry przechowywania bez konieczności całkowitego kopiowania bazy danych - lub, co gorsza, wykonywania pg_dump, pg_restore. Druga wskazówka dotyczy wydajności systemu.
Wskazówka 2
Podobnie jak zawsze testując obietnice producentów dotyczące niezawodności, to samo powinieneś zrobić z wydajnością sprzętu. Bonnie++ to najpopularniejszy test wydajności pamięci masowej dla systemów uniksopodobnych. W przypadku ogólnych testów systemu (procesor, pamięć, a także pamięć masowa) nic nie jest bardziej reprezentatywne niż wydajność bazy danych. Tak więc podstawowym testem wydajności w nowym systemie byłoby uruchomienie pgbench, oficjalnego pakietu testowego PostgreSQL opartego na TCP-B.
Rozpoczęcie pracy z pgbench jest dość łatwe, wystarczy:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Zawsze powinieneś skonsultować się z pgbench po każdej ważnej zmianie, którą chcesz ocenić i porównać wyniki.
Wdrażanie, automatyzacja i monitorowanie systemu
Po uruchomieniu bardzo ważne jest, aby główne komponenty systemu były udokumentowane i odtwarzalne, aby mieć zautomatyzowane procedury tworzenia usług i powtarzających się zadań, a także mieć narzędzia do ciągłego monitorowania.
Wskazówka 3
Jednym z przydatnych sposobów na rozpoczęcie korzystania z PostgreSQL ze wszystkimi jego zaawansowanymi funkcjami dla przedsiębiorstw jest ClusterControl firmy Manynines. Można mieć klaster PostgreSQL klasy korporacyjnej, naciskając kilka kliknięć. ClusterControl zapewnia wszystkie te usługi i wiele innych. Konfiguracja ClusterControl jest dość łatwa, wystarczy postępować zgodnie z instrukcjami zawartymi w oficjalnej dokumentacji. Po przygotowaniu systemów (zazwyczaj jeden do uruchamiania CC, a drugi do PostgreSQL w przypadku podstawowej konfiguracji) i skonfigurowaniu SSH, musisz wprowadzić podstawowe parametry (adresy IP, numery portów itp.), a jeśli wszystko pójdzie dobrze, powinieneś zobacz wynik podobny do następującego:
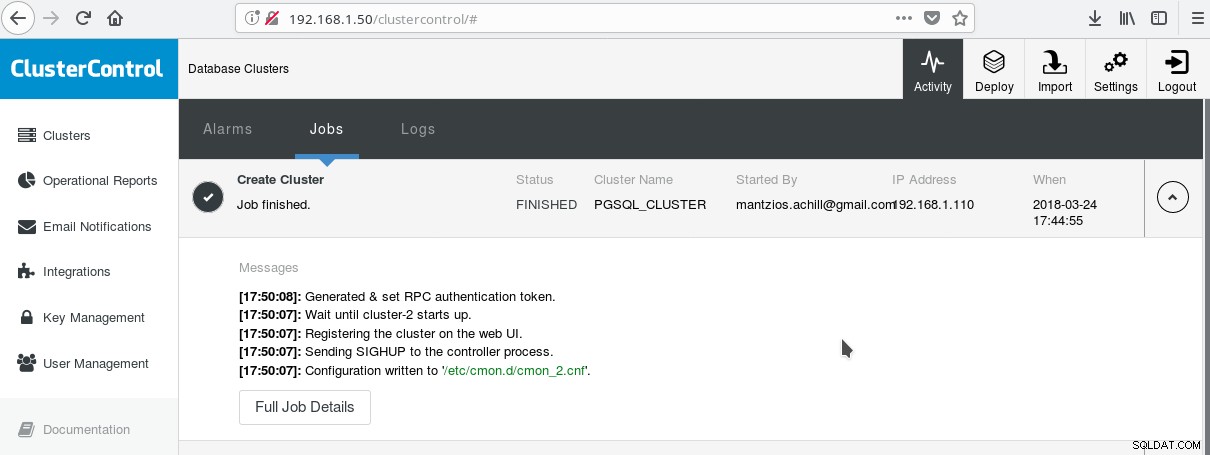
A na głównym ekranie klastrów:
Możesz zalogować się do swojego głównego serwera i zacząć tworzyć swój schemat! Oczywiście możesz użyć jako podstawy utworzonego właśnie klastra, aby dalej rozbudowywać swoją infrastrukturę (topologię). Ogólnie dobrym pomysłem jest posiadanie stabilnego układu systemu plików serwera i ostatecznej konfiguracji na serwerze PostgreSQL i bazach danych użytkowników/aplikacji, zanim zaczniesz tworzyć klony i rezerwy (slave) na podstawie właśnie utworzonego nowego serwera.
Układ, parametry i ustawienia PostgreSQL
W fazie inicjalizacji klastra najważniejszą decyzją jest to, czy używać sum kontrolnych danych na stronach danych, czy nie. Jeśli zależy Ci na maksymalnym bezpieczeństwie Twoich cennych (przyszłych) danych, to nadszedł czas, aby to zrobić. Jeśli jest szansa, że możesz chcieć tej funkcji w przyszłości i nie zrobisz tego na tym etapie, nie będziesz mógł jej później zmienić (bez pg_dump/pg_restore). Oto kolejna wskazówka:
Wskazówka 4
Aby włączyć sumy kontrolne danych, uruchom initdb w następujący sposób:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Zauważ, że powinno to zostać zrobione w czasie końcówki 3, którą opisaliśmy powyżej. Jeśli utworzyłeś już klaster za pomocą ClusterControl, będziesz musiał ponownie uruchomić pg_createcluster ręcznie, ponieważ w chwili pisania tego tekstu nie ma możliwości poinformowania systemu lub CC o włączeniu tej opcji.
Kolejnym bardzo ważnym krokiem przed wejściem do produkcji jest zaplanowanie układu systemu plików serwera. Większość nowoczesnych dystrybucji Linuksa (przynajmniej te oparte na debianie) montuje wszystko na /, ale w PostgreSQL zwykle tego nie chcesz. Korzystne jest umieszczenie przestrzeni tabel na osobnych woluminach, aby jeden wolumin był przeznaczony na pliki WAL, a drugi na dziennik pg. Ale najważniejsze jest przeniesienie WAL na własny dysk. To prowadzi nas do następnej wskazówki.
Wskazówka 5
Z PostgreSQL 10 w Debian Stretch, możesz przenieść swój WAL na nowy dysk za pomocą następujących poleceń (przypuśćmy, że nowy dysk ma nazwę /dev/sdb ):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlNiezwykle ważne jest prawidłowe skonfigurowanie ustawień regionalnych i kodowania baz danych. Przeocz to w fazie createdb, a będziesz tego bardzo żałować, ponieważ Twoja aplikacja/baza danych przenosi się na terytoria i18n, l10n. Następna wskazówka pokazuje, jak to zrobić.
Wskazówka 6
Powinieneś przeczytać oficjalną dokumentację i zdecydować o ustawieniach COLLATE i CTYPE (createdb --locale=) (odpowiedzialnych za porządek sortowania i klasyfikację znaków), a także ustawieniach zestawu znaków (createdb --encoding=). Określenie UTF8 jako kodowania umożliwi Twojej bazie danych przechowywanie tekstu w wielu językach.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentWysoka dostępność PostgreSQL
Od czasu PostgreSQL 9.0, kiedy replikacja strumieniowa stała się standardową funkcją, możliwe stało się posiadanie jednego lub więcej hot standbys tylko do odczytu, umożliwiając w ten sposób kierowanie ruchu tylko do odczytu do dowolnego z dostępnych urządzeń podrzędnych. Istnieją nowe plany replikacji z wieloma wzorcami, ale w momencie pisania tego tekstu (10.3) możliwe jest posiadanie tylko jednego wzorca do odczytu i zapisu, przynajmniej w oficjalnym produkcie open source. Na następną wskazówkę, która dotyczy dokładnie tego.
Wskazówka 7
Użyjemy naszego ClusterControl PGSQL_CLUSTER utworzonego w Tip 3. Najpierw tworzymy drugą maszynę, która będzie działać jako nasz slave tylko do odczytu (hot standby w terminologii PostgreSQL). Następnie klikamy Add Replication slave i wybieramy naszego mastera i nowego slave'a. Po zakończeniu zadania powinieneś zobaczyć następujący wynik:
Klaster powinien teraz wyglądać tak:
Zwróć uwagę na zieloną ikonę „zaznaczenia” na etykiecie „NIEwolnicy” obok „MASTER”. Możesz sprawdzić, czy replikacja strumieniowa działa, tworząc obiekt bazy danych (baza danych, tabela itp.) lub wstawiając kilka wierszy do tabeli na urządzeniu głównym i zobaczyć zmianę w trybie gotowości.
Obecność trybu gotowości tylko do odczytu umożliwia nam równoważenie obciążenia dla klientów wykonujących zapytania tylko do odczytu między dwoma dostępnymi serwerami, głównym i podrzędnym. To prowadzi nas do wskazówki 8.
Wskazówka 8
Możesz włączyć równoważenie obciążenia między dwoma serwerami za pomocą HAProxy. Z ClusterControl jest to dość łatwe do zrobienia. Kliknij Zarządzaj-> Load Balancer. Po wybraniu serwera HAProxy, ClusterControl zainstaluje wszystko za Ciebie:xinetd we wszystkich określonych instancjach i HAProxy na wyznaczonym serwerze HAProxy. Po pomyślnym zakończeniu zadania powinieneś zobaczyć:
Zwróć uwagę na zielony haczyk HAPROXY obok NIEWOLNICY. Teraz możesz przetestować działanie HAProxy:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Wskazówka 9
Oprócz konfigurowania HA i równoważenia obciążenia, zawsze korzystne jest posiadanie pewnego rodzaju puli połączeń przed serwerem PostgreSQL. Pgpool i Pgbouncer to dwa projekty wywodzące się ze społeczności PostgreSQL. Wiele serwerów aplikacji dla przedsiębiorstw udostępnia również własne pule. Pgbouncer jest bardzo popularny ze względu na swoją prostotę, szybkość i funkcję „transaction pooling”, dzięki której połączenie z serwerem jest uwalniane po zakończeniu transakcji, dzięki czemu można go ponownie wykorzystać do kolejnych transakcji, które mogą pochodzić z tej samej lub innej sesji . Ustawienie puli transakcji przerywa niektóre funkcje puli sesji, ale generalnie konwersja do konfiguracji gotowej do „pulowania transakcji” jest łatwa, a wady nie są tak ważne w ogólnym przypadku. Typową konfiguracją jest skonfigurowanie puli serwera aplikacji z półtrwałymi połączeniami:raczej większa pula połączeń na użytkownika lub na aplikację (która łączy się z pgbouncer) z długimi limitami czasu bezczynności. W ten sposób czas połączenia z aplikacji jest minimalny, podczas gdy pgbouncer pomoże utrzymać jak najmniej połączeń z serwerem.
Jedną z rzeczy, która najprawdopodobniej będzie niepokojąca po uruchomieniu PostgreSQL, jest zrozumienie i naprawa powolnych zapytań. Narzędzia do monitorowania, o których wspomnieliśmy w poprzednim blogu, takie jak pg_stat_statements, a także ekrany narzędzi, takich jak ClusterControl, pomogą Ci zidentyfikować i ewentualnie zasugerować pomysły na naprawę powolnych zapytań. Jednak po zidentyfikowaniu powolnego zapytania będziesz musiał uruchomić EXPLAIN lub EXPLAIN ANALYZE, aby dokładnie zobaczyć koszty i czasy związane z planem zapytania. Następna wskazówka dotyczy bardzo przydatnego narzędzia, aby to zrobić.
Wskazówka 10
Musisz uruchomić analizę WYJAŚNIJ ANALIZĘ w swojej bazie danych, a następnie skopiować wyniki i wkleić je do narzędzia online do analizy wyjaśnień depesz i kliknąć prześlij. Następnie zobaczysz trzy zakładki:HTML, TEKST i STATYSTYKI. HTML zawiera koszt, czas i liczbę pętli dla każdego węzła w planie. Karta STATYSTYKI pokazuje statystyki według typu węzła. Powinieneś obserwować kolumnę „% zapytania”, aby wiedzieć, na czym dokładnie cierpi Twoje zapytanie.
Gdy zaznajomisz się z PostgreSQL, sam znajdziesz o wiele więcej wskazówek!