PostgreSQL to jedna z najbardziej zaawansowanych baz danych open source na świecie z wieloma wspaniałymi funkcjami. Jednym z nich jest replikacja strumieniowa (replikacja fizyczna), która została wprowadzona w PostgreSQL 9.0. Opiera się na rekordach XLOG, które są przesyłane na serwer docelowy i tam stosowane. Jest jednak oparty na klastrach i nie możemy wykonać replikacji pojedynczej bazy danych lub pojedynczego obiektu (replikacja selektywna). Przez lata byliśmy zależni od zewnętrznych narzędzi, takich jak Slony, Bucardo, BDR, itp. do selektywnej lub częściowej replikacji, ponieważ nie było żadnej funkcji na poziomie rdzenia aż do PostgreSQL 9.6. Jednak PostgreSQL 10 wymyślił funkcję o nazwie Logiczna replikacja, dzięki której możemy wykonać replikację na poziomie bazy danych/obiektu.
Replikacja logiczna replikuje zmiany obiektów na podstawie ich tożsamości replikacji, która zwykle jest kluczem podstawowym. Różni się od replikacji fizycznej, w której replikacja opiera się na blokach i replikacji bajt po bajcie. Replikacja logiczna nie wymaga dokładnej kopii binarnej po stronie serwera docelowego, a w przeciwieństwie do replikacji fizycznej mamy możliwość pisania na serwerze docelowym. Ta funkcja pochodzi z modułu pglogical.
W tym poście na blogu omówimy:
- Jak to działa — architektura
- Funkcje
- Przypadki użycia – kiedy jest to przydatne
- Ograniczenia
- Jak to osiągnąć
Jak to działa — architektura replikacji logicznej
Logiczna replikacja implementuje koncepcję publikowania i subskrybowania (publikacja i subskrypcja). Poniżej znajduje się diagram architektury wyższego poziomu przedstawiający, jak to działa.
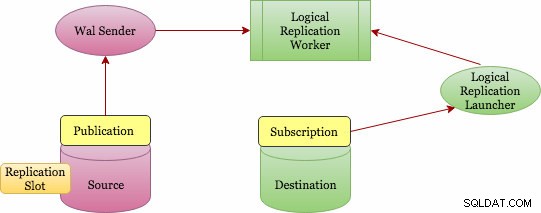
Podstawowa architektura replikacji logicznej
Publikację można zdefiniować na serwerze głównym, a węzeł, w którym jest zdefiniowana, jest określany jako „wydawca”. Publikacja to zbiór zmian z pojedynczej tabeli lub grupy tabel. Odbywa się to na poziomie bazy danych, a każda publikacja istnieje w jednej bazie danych. Do jednej publikacji można dodać wiele tabel, a tabela może znajdować się w wielu publikacjach. Powinieneś dodawać obiekty bezpośrednio do publikacji, chyba że wybierzesz opcję „WSZYSTKIE TABLICE”, która wymaga uprawnień superużytkownika.
Możesz ograniczyć zmiany obiektów (WSTAW, AKTUALIZUJ i USUŃ), które mają być replikowane. Domyślnie replikowane są wszystkie typy operacji. Musisz mieć skonfigurowaną tożsamość replikacji dla obiektu, który chcesz dodać do publikacji. Ma to na celu replikację operacji UPDATE i DELETE. Tożsamość replikacji może być kluczem podstawowym lub unikalnym indeksem. Jeśli tabela nie ma klucza podstawowego ani unikalnego indeksu, można ją ustawić na replikę tożsamości „pełną”, w której wszystkie kolumny są traktowane jako klucz (cały wiersz staje się kluczem).
Publikację można utworzyć za pomocą opcji UTWÓRZ PUBLIKACJĘ. Niektóre praktyczne polecenia opisano w sekcji „Jak to osiągnąć”.
Subskrypcję można zdefiniować na serwerze docelowym, a węzeł, na którym jest zdefiniowana, jest określany jako „subskrybent”. Połączenie do źródłowej bazy danych jest zdefiniowane w abonamencie. Węzeł subskrybenta jest taki sam, jak każda inna samodzielna baza danych Postgres i możesz go również użyć jako publikacji do dalszych subskrypcji.
Subskrypcja jest dodawana za pomocą CREATE SUBSCRIPTION i może być zatrzymana/wznowiona w dowolnym momencie za pomocą polecenia ALTER SUBSCRIPTION i usunięta za pomocą DROP SUBSCRIPTION.
Po utworzeniu subskrypcji replikacja logiczna kopiuje migawkę danych w bazie danych wydawcy. Po wykonaniu tej czynności czeka na zmiany delta i wysyła je do węzła subskrypcji, gdy tylko się pojawią.
Jak jednak zbierane są zmiany? Kto wysyła je do celu? A kto stosuje je u celu? Replikacja logiczna jest również oparta na tej samej architekturze, co replikacja fizyczna. Jest realizowany przez procesy „walsender” i „apply”. Ponieważ opiera się na dekodowaniu WAL, kto rozpoczyna dekodowanie? Proces walsendera jest odpowiedzialny za rozpoczęcie logicznego dekodowania WAL i ładowanie standardowej wtyczki dekodowania logicznego (pgoutput). Wtyczka przekształca zmiany odczytane z WAL na protokół replikacji logicznej i filtruje dane zgodnie ze specyfikacją publikacji. Dane są następnie w sposób ciągły przesyłane za pomocą protokołu replikacji strumieniowej do procesu roboczego aplikacji, który mapuje dane do lokalnych tabel i stosuje poszczególne zmiany w miarę ich odbierania, we właściwej kolejności transakcyjnej.
Rejestruje wszystkie te kroki w plikach dziennika podczas konfigurowania. W dalszej części wpisu możemy zobaczyć komunikaty w sekcji „Jak to osiągnąć”.
Funkcje replikacji logicznej
- Replikacja logiczna replikuje obiekty danych na podstawie ich tożsamości replikacji (zazwyczaj
- klucz podstawowy lub unikalny indeks).
- Do zapisów można używać serwera docelowego. Możesz mieć różne indeksy i definicje bezpieczeństwa.
- Replikacja logiczna obsługuje wiele wersji. W przeciwieństwie do replikacji strumieniowej, replikację logiczną można ustawić między różnymi wersjami PostgreSQL (> 9.4)
- Replikacja logiczna wykonuje filtrowanie oparte na zdarzeniach
- W porównaniu, replikacja logiczna ma mniejsze wzmocnienie zapisu niż replikacja strumieniowa
- Publikacje mogą mieć kilka subskrypcji
- Replikacja logiczna zapewnia elastyczność przechowywania poprzez replikowanie mniejszych zestawów (nawet partycjonowanych tabel)
- Minimalne obciążenie serwera w porównaniu z rozwiązaniami opartymi na wyzwalaczach
- Pozwala na równoległe przesyłanie strumieniowe między wydawcami
- Replikacja logiczna może być używana do migracji i aktualizacji
- Transformację danych można przeprowadzić podczas konfiguracji.
Przypadki użycia — kiedy replikacja logiczna jest przydatna?
Bardzo ważne jest, aby wiedzieć, kiedy używać replikacji logicznej. W przeciwnym razie nie odniesiesz większych korzyści, jeśli Twój przypadek użycia nie będzie pasował. Oto kilka przypadków użycia, w których należy użyć replikacji logicznej:
- Jeśli chcesz skonsolidować wiele baz danych w jedną bazę danych do celów analitycznych.
- Jeśli Twoim wymaganiem jest replikacja danych między różnymi głównymi wersjami PostgreSQL.
- Jeśli chcesz wysyłać zmiany przyrostowe w pojedynczej bazie danych lub podzbiorze bazy danych do innych baz danych.
- Jeśli dajesz dostęp do zreplikowanych danych różnym grupom użytkowników.
- Jeśli dzielisz podzbiór bazy danych między wieloma bazami danych.
Ograniczenia replikacji logicznej
Logiczna replikacja ma pewne ograniczenia, nad którymi społeczność nieustannie pracuje, aby przezwyciężyć:
- Tabele muszą mieć taką samą pełną kwalifikowaną nazwę między publikacją a subskrypcją.
- Tabele muszą mieć klucz podstawowy lub klucz unikalny
- Wzajemna (dwukierunkowa) replikacja nie jest obsługiwana
- Nie replikuje schematu/DDL
- Nie replikuje sekwencji
- Nie replikuje OBCIĄŻAJ
- Nie replikuje dużych obiektów
- Subskrypcje mogą mieć więcej kolumn lub inną kolejność kolumn, ale typy i nazwy kolumn muszą być zgodne między publikacją a subskrypcją.
- Uprawnienia superużytkownika do dodawania wszystkich tabel
- Nie możesz przesyłać strumieniowo do tego samego hosta (subskrypcja zostanie zablokowana).
Jak osiągnąć replikację logiczną
Oto kroki do osiągnięcia podstawowej replikacji logicznej. O bardziej złożonych scenariuszach możemy omówić później.
-
Zainicjuj dwie różne instancje publikacji i subskrypcji i rozpocznij.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parametry, które należy zmienić przed uruchomieniem instancji (zarówno dla instancji publikacji, jak i subskrypcji).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedInne parametry mogą być ustawione jako domyślne dla podstawowej konfiguracji.
-
Zmień plik pg_hba.conf, aby umożliwić replikację. Pamiętaj, że te wartości są zależne od Twojego środowiska, jednak jest to tylko podstawowy przykład (zarówno dla instancji publikacji, jak i subskrypcji).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Utwórz kilka tabel testowych, aby zreplikować i wstawić niektóre dane do instancji publikacji.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Utwórz strukturę tabel w instancji subskrypcji, ponieważ replikacja logiczna nie replikuje struktury.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Utwórz publikację na instancji publikacji (port 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Utwórz subskrypcję na instancji subskrypcji (port 5556) do publikacji utworzonej w kroku 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msZ dziennika:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedJak widać w komunikacie NOTICE, utworzono szczelinę replikacji, która zapewnia, że czyszczenie WAL nie powinno zostać wykonane, dopóki początkowe zmiany migawki lub delta nie zostaną przesłane do docelowej bazy danych. Następnie nadawca WAL rozpoczął dekodowanie zmian, a zastosowanie replikacji logicznej zadziałało, gdy uruchomiono zarówno pub, jak i sub. Następnie rozpoczyna synchronizację tabeli.
-
Zweryfikuj dane w instancji subskrypcji.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#Jak widzisz, dane zostały zreplikowane przez początkowy zrzut.
-
Sprawdź zmiany delta.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Oto kroki podstawowej konfiguracji replikacji logicznej.