Kubernetes został przedstawiony we wcześniejszym artykule „Pierwsze kroki z Kubernetes w Amazon Web Services (AWS)”. Kubernetes został również omówiony w innym artykule, „Korzystanie z Kubernetes (K8s) na IBM Bluemix”. Kubernetes można zainstalować na gołym metalu na prawie każdym systemie operacyjnym, w tym Fedorze, CentOS, Ubuntu i CoreOS, w celach programistycznych.
Problem
Instalacja Kubernetes na gołym metalu obejmuje uruchomienie kilku poleceń w celu skonfigurowania węzła głównego, węzłów roboczych, sieci pod itp.
Rozwiązanie
Kubernetes 1.4 wprowadza nowe narzędzie o nazwie kubeadm do ładowania klastra Kubernetes. kubeadm ładuje klaster Kubernetes za pomocą dwóch poleceń. Po zainstalowaniu platformy Docker, kubectl i kubelet węzeł główny można uruchomić za pomocą kubeadm init i węzły robocze dodane za pomocą dołączenia kubeadm .
W tym artykule użyjemy następującej procedury, aby zainstalować i załadować klaster Kubernetes, a następnie przetestować klaster:
- Uruchom trzy nowe instancje Ubuntu na Amazon EC2.
- We wszystkich instancjach Ubuntu zainstaluj Docker, kubeadm, kubectl i kubelet.
- Z jednej z instancji Ubuntu zainicjuj Master klastra Kubernetes za pomocą następującego polecenia:
kubeadm init
- Zastosuj politykę sieci Calico Pod kubeadm/calico.yaml .
- Dołącz do dwóch pozostałych instancji (węzłów) Ubuntu z masterem za pomocą kubeadm join --token=
- Na masterze trzy węzły są wyświetlane za pomocą „kubectl get nodes”.
- Uruchom aplikację na master:
kubectl -s https://localhost:8080 run nginx --image=nginx --replicas=3 --port=80
- Wymień pody:
kubectl get pods -o wide
- Odinstaluj klaster Kubernetes.
kubeadm reset
Ten artykuł ma następujące sekcje:
- Ustawianie środowiska
- Instalowanie platformy Docker, kubeadm, kubectl i kubelet na każdym hoście
- Inicjowanie Mistrza
- Instalacja sieci Calico Pod
- Dołączanie węzłów do klastra
- Instalowanie przykładowej aplikacji
- Odinstalowywanie klastra
- Ograniczenia
- Dalsze zmiany w kubeadm
- Wniosek
Ustawianie środowiska
kubeadm narzędzie wymaga następujących maszyn z systemem Ubuntu 16.04+, HypriotOS v1.0.1+ lub CentOS 7 działającym na nich.
- Jedna maszyna dla węzła głównego
- Jeden lub więcej komputerów dla węzłów roboczych
Na każdym komputerze wymagany jest co najmniej 1 GB pamięci RAM. Wykorzystaliśmy trzy maszyny Ubuntu działające na Amazon EC2 do uruchomienia klastra z jednym węzłem głównym i dwoma węzłami roboczymi. Trzy maszyny z Ubuntu są pokazane na rysunku 1.
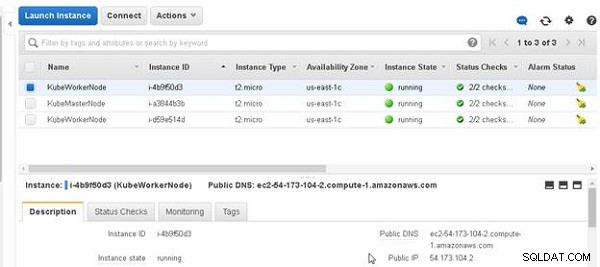
Rysunek 1: Maszyny Ubuntu
Instalowanie platformy Docker, kubeadm, kubectl i kubelet na każdym hoście
W tej sekcji zainstalujemy Docker, kubelet, kubectl i kubeadm na każdej z trzech maszyn. Zainstalowane komponenty są omówione w Tabeli 1.
| Komponent | Opis |
| Dokowane | Środowisko wykonawcze kontenera. Zalecana jest wersja 1.11.2, a v1.10.3 i v1.12.1 również są w porządku. Wymagane na wszystkich komputerach w klastrze. |
| kubelet | Podstawowy składnik Kubernetes, który działa na wszystkich komputerach w klastrze. Uruchamia kontenery i kapsuły. Wymagane na wszystkich komputerach w klastrze. |
| kubectl | Narzędzie wiersza poleceń do zarządzania klastrem. Wymagane tylko w węźle głównym, ale przydatne, jeśli jest zainstalowane na wszystkich węzłach. |
| kubeadm | Narzędzie do ładowania klastra. Wymagane na wszystkich komputerach w klastrze. |
Tabela 1: Komponenty do zainstalowania
Uzyskaj publiczny adres IP każdej z trzech maszyn i zaloguj się do każdego z nich przez SSH:
ssh -i "docker.pem" example@sqldat.com ssh -i "docker.pem" example@sqldat.com ssh -i "docker.pem" example@sqldat.com
Polecenia instalacji plików binarnych muszą być uruchamiane jako root; dlatego ustaw użytkownika jako root.
sudo su -
Uruchom następujące polecenia na każdym z komputerów:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF > /etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF
Pierwsze polecenie pobiera wymagane pakiety dla Kubernetes, jak pokazano na rysunku 2.
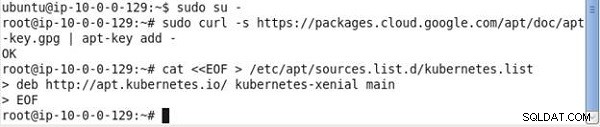
Rysunek 2: Pobieranie pakietów dla Kubernetes
Polecenie 2 pobiera listy pakietów z repozytoriów i aktualizuje je najnowszymi wersjami pakietów.
apt-get update
Dane wyjściowe pokazano na rysunku 3.
Rysunek 3: Aktualizowanie pakietów repozytoriów
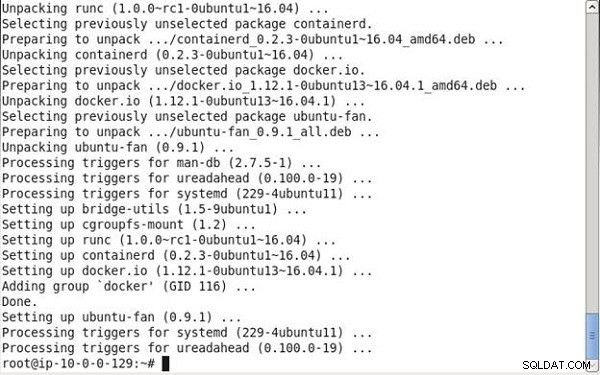
Następnie zainstaluj Docker:
# Install docker if you don't have it already. apt-get install -y docker.io
Docker zostanie zainstalowany, jak pokazano w wyniku polecenia na rysunku 4.
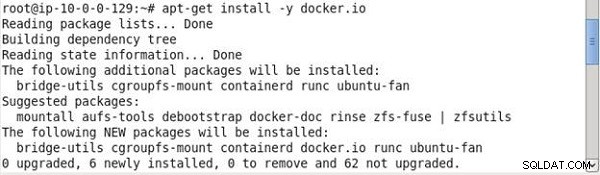
Rysunek 4: Instalowanie Dockera
Następnie zainstaluj kubelet (główny składnik Kubernetes), kubeadm (narzędzie do ładowania początkowego), kubectl (narzędzie do zarządzania klastrami) i kubernetes-cni (wtyczka sieciowa):
apt-get install -y kubelet kubeadm kubectl kubernetes-cni
Dane wyjściowe z poprzednich poleceń pokazano na rysunku 5.
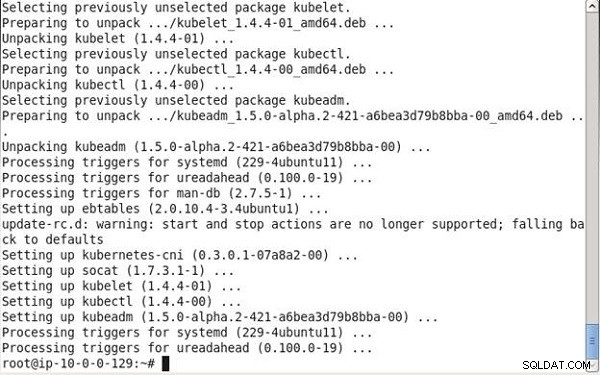
Rysunek 5: Instalowanie programów kubelet, kubeadm, kubectln i kubernetes-cni
Inicjowanie Master
Następnie zainicjuj master, na którym działa baza danych etcd i serwer API. Kubelet uruchamia Pody do uruchamiania tych komponentów. Uruchom następujące polecenie, które automatycznie wykryje adresy IP:
kubeadm init
Jak pokazano w danych wyjściowych polecenia, najpierw uruchamiane są niektóre kontrole przed lotem w celu sprawdzenia stanu systemu. Następnie generowany jest token główny/tokeny, który ma być używany jako klucz wzajemnego uwierzytelniania dla węzłów roboczych, które chcą dołączyć do klastra. Następnie generowany jest klucz i certyfikat urzędu certyfikacji z podpisem własnym, aby zapewnić tożsamości każdemu z węzłów w klastrze w celu komunikacji z klientami. Klucz i certyfikat serwera API są tworzone dla serwera API w celu komunikacji z klientami. util/kubeconfig tworzony jest plik kubelet, aby połączyć się z serwerem API i innym util/kubeconfig tworzony jest plik dla administracji. Następnie tworzona jest konfiguracja klienta API. Dane wyjściowe z kubeadm init polecenie jest pokazane na rysunku 6.
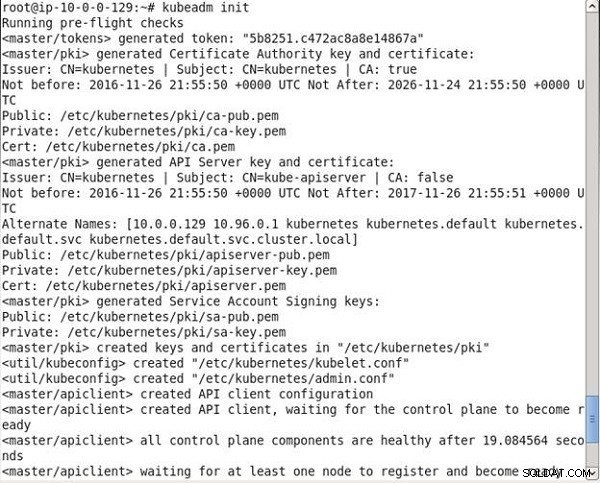
Rysunek 6: Uruchamiam init Kubeadm
Wszystkie komponenty płaszczyzny sterowania są gotowe. Pierwszy węzeł jest gotowy i wykonywane jest wdrożenie testowe. Tworzone są również niezbędne składniki dodatkowe, kube-discovery, kube-proxy i kube-dns, jak pokazano w wynikach polecenia na rysunku 7. Master Kubernetes zostaje pomyślnie zainicjowany. Generowane jest polecenie o następującej składni; musi być uruchamiany na maszynach (węzłach), które mają dołączyć do klastra.
kubeadm join -token=<token> <IP Address of the master node>
Poprzednie polecenie musi zostać skopiowane i zachowane do późniejszego użycia w węzłach roboczych.
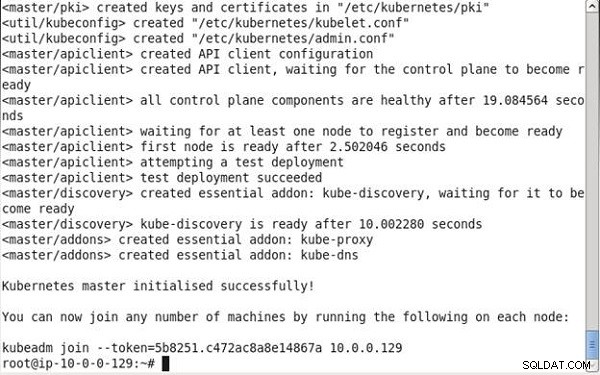
Rysunek 7: Zainicjowano master Kubernetes
Domyślnie węzły główne nie podlegają zaplanowaniu i są tworzone przy użyciu „dedykowane” tainty. Węzeł główny można zaplanować za pomocą następującego polecenia:
kubectl taint nodes --all dedicated-
kubeadm polecenie obsługuje kilka innych opcji (patrz Tabela 2), których nie musieliśmy używać, ale mogą być użyte do zastąpienia domyślnego polecenia.
| Parametr polecenia | Opis | Domyślny |
| --pomiń kontrole przed lotem | Pomija kontrole przed lotem | Przeprowadzane są kontrole przed lotem |
| --użyj-wersji-kubernetes | Ustawia używaną wersję Kubernetes | v1.5.1 |
| --adresy-api-advertise | Kubeadm init polecenie automatycznie wykrywa i używa adresu IP domyślnego interfejsu sieciowego i używa go do generowania certyfikatów dla serwera API. Ten parametr konfiguracyjny może być użyty do zastąpienia wartości domyślnej jednym lub większą liczbą adresów IP, na których serwer API ma zostać zweryfikowany. | Automatyczne wykrywanie |
| --api-external-dns-names | Ten parametr konfiguracyjny może być użyty do zastąpienia domyślnego interfejsu sieciowego jedną lub większą liczbą nazw hostów, na których serwer API ma zostać zweryfikowany. Tylko jeden z adresów IP lub zewnętrznych nazw DNS musi być użyty. | |
| --dostawca-chmury | Określa dostawcę chmury. Menedżer chmury obsługuje „aws”, „azure”, „cloudstack”, „gce”, „mesos”, „openstack”, „ovirt”, „rackspace” i „vsphere”. Konfigurację dostawcy chmury można znaleźć w pliku /etc/kubernetes/cloud-config. Korzystanie z dostawcy chmury ma również tę zaletę, że używa trwałych woluminów i równoważenia obciążenia. | Brak automatycznego wykrywania dostawcy chmury |
| --pod-cidr-sieci | Przydziela zakresy sieci (CIDR) do każdego węzła i jest przydatne w przypadku niektórych rozwiązań sieciowych, w tym dostawców flanelowych i chmurowych. | |
| --service-cidr | Zastępuje podsieć używaną przez Kubernetes do przypisywania adresów IP do podów. /etc/systemd/system/kubelet.service.d/10-kubeadm.conf również musi zostać zmodyfikowany. | 10.96.0.0/12 |
| --service-dns-domain | Zastępuje sufiks nazwy DNS do przypisywania usług z nazwami DNS; ma format | cluster.local |
| --token | Określa token, który ma być używany do wzajemnego uwierzytelniania między urządzeniem głównym a węzłami dołączającymi do klastra. | Automatycznie generowane |
Tabela 2: Opcje poleceń Kubeadm
Instalowanie sieci Calico Pod
Aby pody mogły komunikować się ze sobą, musi być zainstalowany dodatek sieciowy podów. Calico zapewnia konfigurację instalacji hostowaną przez kubeadm w postaci ConfigMap pod adresem https://docs.projectcalico.org/master/getting-started/kubernetes/installation/hosted/kubeadm/calico.yaml, którego użyjemy w tej sekcji, aby zainstalować sieć Pod. Uruchom następujące polecenie na węźle głównym, aby zainstalować sieć Pod:
kubectl apply -f https://docs.projectcalico.org/master/getting-started/ kubernetes/installation/hosted/kubeadm/calico.yaml
Alternatywnie pobierz plik calico.yaml i skopiuj do węzła głównego:
scp -i "docker.pem" calico.yaml example@sqldat.com:~
Następnie uruchom następujące polecenie:
kubectl apply -f calico.yaml
Calico i pojedynczy klaster etcd zostaną zainstalowane, jak pokazano na rysunku 8.
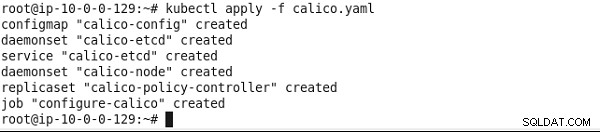
Rysunek 8: Instalowanie zasad Calico
Następnie wypisz wszystkie pody we wszystkich przestrzeniach nazw Kubernetes.
kubectl get pods --all-namespaces
kube-dns Pod musi być uruchomiony, jak pokazano na rysunku 9.
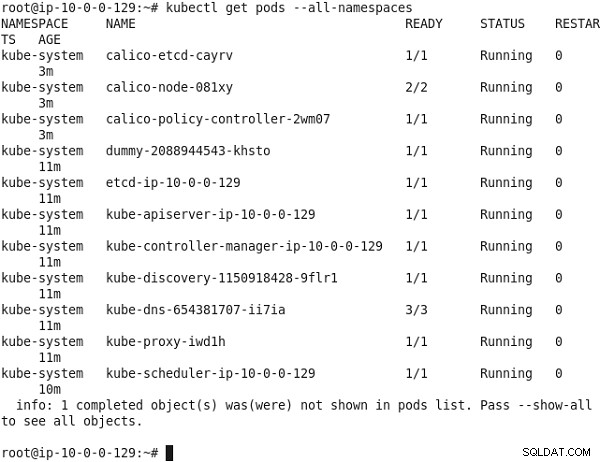
Rysunek 9: Wyświetlanie podów we wszystkich przestrzeniach nazw
Dołączanie węzłów do klastra
W tej sekcji dołączymy węzły robocze do klastra za pomocą dołączenia kubeadm polecenie, które ma następującą składnię:
kubeadm join --token=<token> <master-ip>
Opcjonalnie dołączenie kubeadm polecenie można uruchomić z --skip-preflight-checks opcja pominięcia wstępnej weryfikacji.
Dołączenie kubeadm polecenie używa dostarczonego tokena do komunikacji z serwerem API i uzyskania certyfikatu głównego urzędu certyfikacji oraz tworzy parę kluczy lokalnych. Następnie żądanie podpisania certyfikatu (CSR) jest wysyłane do serwera API w celu podpisania, a lokalny kubelet jest konfigurowany do łączenia się z serwerem API.
Uruchom dołączenie kubeadm polecenie skopiowane z wyjścia kubeadm init na każdym z komputerów Ubuntu, które mają dołączyć do klastra.
Najpierw zaloguj się przez SSH do instancji/instancji Ubuntu:
ssh -i "docker.pem" example@sqldat.com
i
ssh -i "docker.pem" example@sqldat.com
Następnie uruchom dołączenie kubeadm Komenda. Najpierw przeprowadzane są pewne kontrole przed lotem. Podany token został zweryfikowany. Następnie używane jest wykrywanie węzłów. Tworzony jest klient odnajdywania informacji o klastrze i żądane są informacje z serwera interfejsu API. Odbierany jest obiekt informacji o klastrze, a podpis jest weryfikowany przy użyciu podanego tokena. Stwierdzono, że sygnatura i zawartość informacji o klastrze są prawidłowe, a wykrywanie węzła zostało zakończone. Następnie wykonywane jest ładowanie węzła, w którym do nawiązania połączenia wykorzystywane są punkty końcowe API https://10.0.0.129:6443. Następnie żądanie podpisania certyfikatu (csr) jest wykonywane przy użyciu klienta API w celu uzyskania unikalnego certyfikatu dla węzła. Po odebraniu podpisanego certyfikatu z serwera API generowany jest plik konfiguracyjny kubelet. Komunikat „Dołączanie węzła zakończone” na rysunku 10 wskazuje, że węzeł dołączył do klastra.
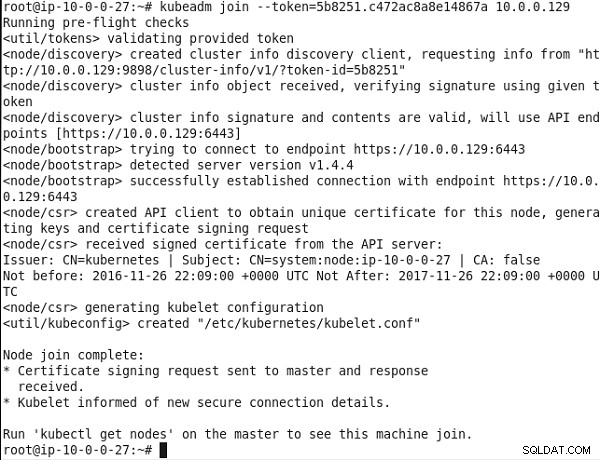
Rysunek 10: Dołączanie węzła do klastra
Podobnie uruchom to samo polecenie na innym komputerze z systemem Ubuntu. Drugi węzeł również dołącza do klastra, jak pokazano na rysunku 11.
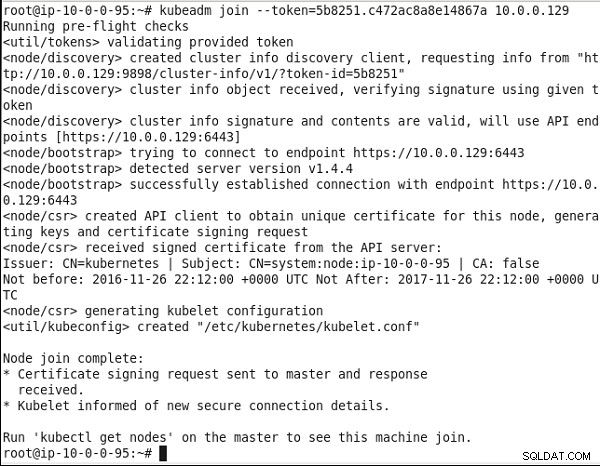
Rysunek 11: Dołączanie drugiego węzła do klastra
Na węźle głównym uruchom następujące polecenie, aby wyświetlić listę węzłów:
kubectl get nodes
Węzeł główny i dwa węzły robocze powinny zostać wyświetlone, jak pokazano na rysunku 12.

Rysunek 12: Wyświetlanie listy węzłów klastra Kubernetes
Instalowanie przykładowej aplikacji
Następnie przetestujemy klaster. Uruchom następujące polecenie, aby uruchomić nginx oparty na klastrze Pod składający się z trzech replik:
kubectl -s https://localhost:8080 run nginx --image=nginx --replicas=3 --port=80
Wymień wdrożenia:
kubectl get deployments
Wymień pody obejmujące cały klaster:
kubectl get pods -o wide
Ujawnij wdrożenie jako usługę typu LoadBalancer :
kubectl expose deployment nginx --port=80 --type=LoadBalancer
Wymień usługi:
kubectl get services
Dane wyjściowe z poprzednich poleceń wskazują nginx zostało utworzone wdrożenie, a trzy pody działają w dwóch węzłach roboczych w klastrze. Zostanie również utworzona usługa o nazwie „nginx”, jak pokazano na rysunku 13.
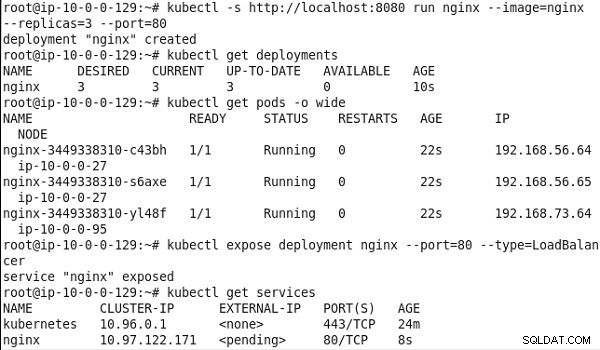
Rysunek 13: Uruchamianie klastra nginx Pod
Skopiuj adres IP klastra usługi. Uruchom polecenie curl, aby wywołać usługę:
curl 10.0.0.99
Znacznik HTML z usługi otrzymuje dane wyjściowe, jak pokazano na rysunku 14.
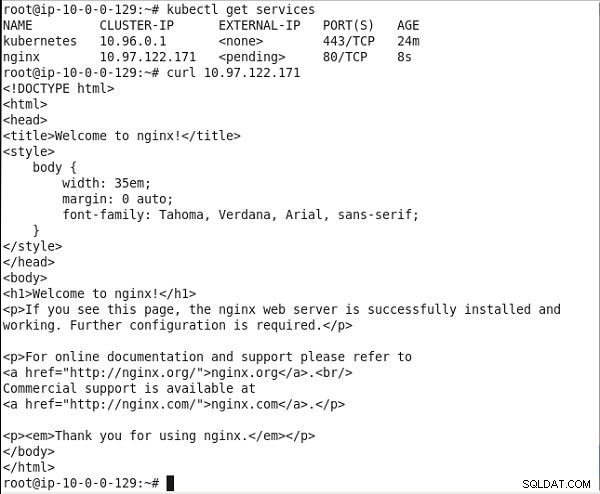
Rysunek 14: Wywoływanie usługi nginx
Odinstalowywanie klastra
Aby odinstalować klaster zainstalowany przez kubeadm, uruchom następujące polecenie:
kubeadm reset
Klaster zostanie odinstalowany, jak pokazano na rysunku 15.
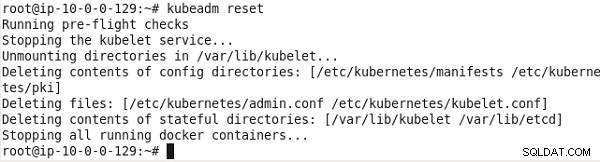
Rysunek 15: Odinstalowywanie/resetowanie klastra Kubernetes
Ograniczenia
Kubeadm ma kilka ograniczeń i jest zalecany tylko do użytku programistycznego. Ograniczenia kubeadm są następujące;
- Obsługiwane jest tylko kilka systemów operacyjnych:Ubuntu 16.04+, CentOS 7, HypriotOS v1.0.1+.
- Nie nadaje się do użytku produkcyjnego.
- Integracja dostawców chmury jest eksperymentalna.
- Utworzony zostanie klaster z tylko jednym masterem i jedną bazą danych etcd. Wysoka dostępność nie jest obsługiwana, co oznacza, że master jest pojedynczym punktem awarii (SPOF).
- Funkcjonalność HostPort i HostIP nie są obsługiwane.
- Niektóre inne znane problemy, gdy kubeadm jest używany z RHEL/CentOS 7 i VirtualBox.
Dalsze zmiany w kubeadm
Kubeadm jest w wersji alfa w Kubernetes v 1.5 i jest w wersji beta od Kubernetes 1.6. Drobne poprawki i ulepszenia są nadal wprowadzane w kubeadm z każdą nową wersją Kubernetes:
- W Kubernetes 1.7 modyfikacje wewnętrznych zasobów klastra zainstalowane za pomocą kubeadm są nadpisywane podczas aktualizacji z wersji 1.6 do wersji 1.7.
- W Kubernetes 1.8 domyślny token Bootstrap utworzony za pomocą kubeadm init staje się nieważny i jest usuwany po 24 godzinach od utworzenia, aby ograniczyć ujawnienie cennego poświadczenia. Dołączenie kubeadm polecenie deleguje ładowanie TLS do iteslf kubelet zamiast ponownego zaimplementowania procesu. Program startowy KubeConfig plik jest zapisywany w /etc/kubernetes/bootstrap-kubelet-conf z dołączaniem kubeadm .
Wniosek
W tym artykule wykorzystaliśmy funkcję narzędzia kubeadm dostępną od wersji Kubernetes 1.4, aby załadować klaster Kubernetes. Najpierw instalowane są wymagane pliki binarne dla platformy Docker, kubectl, kubelet i kubeadm. Następnie kubeadm init Polecenie służy do inicjowania węzła głównego w klastrze. Wreszcie, dołączenie kubeadm Polecenie służy do łączenia węzłów roboczych z klastrem. Przykładowy nginx aplikacja jest uruchamiana w celu przetestowania klastra.