Zarządzanie instalacją PostgreSQL obejmuje inspekcję i kontrolę szerokiego zakresu aspektów w stosie oprogramowania/infrastruktury, na którym działa PostgreSQL. To musi obejmować:
- Dostrajanie aplikacji pod kątem użycia/transakcji/połączeń bazy danych
- Kod bazy danych (zapytania, funkcje)
- System baz danych (wydajność, HA, kopie zapasowe)
- Sprzęt/infrastruktura (dyski, procesor/pamięć)
Rdzeń PostgreSQL zapewnia warstwę bazy danych, na której ufamy przechowywaniu, przetwarzaniu i obsłudze naszych danych. Zapewnia również całą technologię pozwalającą na posiadanie naprawdę nowoczesnego, wydajnego, niezawodnego i bezpiecznego systemu. Jednak często ta technologia nie jest dostępna jako gotowy do użycia, wyrafinowany produkt klasy business/enterprise w podstawowej dystrybucji PostgreSQL. Zamiast tego istnieje wiele produktów/rozwiązań stworzonych przez społeczność PostgreSQL lub oferty komercyjne, które spełniają te potrzeby. Rozwiązania te pojawiają się jako przyjazne dla użytkownika udoskonalenia podstawowych technologii lub rozszerzenia podstawowych technologii, a nawet jako integracja między komponentami PostgreSQL i innymi komponentami systemu. W naszym poprzednim blogu zatytułowanym Dziesięć wskazówek, jak przejść do produkcji z PostgreSQL, przyjrzeliśmy się niektórym z tych narzędzi, które mogą pomóc w zarządzaniu instalacją PostgreSQL w środowisku produkcyjnym. W tym blogu bardziej szczegółowo przyjrzymy się aspektom, które należy uwzględnić podczas zarządzania instalacją PostgreSQL w środowisku produkcyjnym oraz najczęściej używanym do tego celu narzędziom. Omówimy następujące tematy:
- Wdrożenie
- Zarządzanie
- Skalowanie
- Monitorowanie
Wdrożenie
W dawnych czasach ludzie pobierali i kompilowali PostgreSQL ręcznie, a następnie konfigurowali parametry wykonawcze i kontrolę dostępu użytkowników. Wciąż istnieją przypadki, w których może to być potrzebne, ale wraz z dojrzewaniem systemów i rozwojem, pojawiła się potrzeba bardziej znormalizowanych sposobów wdrażania i zarządzania Postgresql. Większość systemów operacyjnych zapewnia pakiety do instalacji, wdrażania i zarządzania klastrami PostgreSQL. Debian ustandaryzował własny układ systemu obsługujący wiele wersji Postgresql i wiele klastrów na wersję jednocześnie. Pakiet debian postgresql-common zapewnia potrzebne narzędzia. Na przykład, aby utworzyć nowy klaster (o nazwie i18n_cluster) dla PostgreSQL w wersji 10 w Debianie, możemy to zrobić za pomocą następujących poleceń:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsNastępnie odśwież systemd:
$ sudo systemctl daemon-reloadi wreszcie uruchom i korzystaj z nowego klastra:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(zauważ, że Debian obsługuje różne klastry, używając różnych portów 5432, 5433 itd.)
W miarę wzrostu zapotrzebowania na bardziej zautomatyzowane i masowe wdrożenia, coraz więcej instalacji korzysta z narzędzi do automatyzacji, takich jak Ansible, Chef i Puppet. Poza automatyzacją i powtarzalnością wdrożeń, narzędzia do automatyzacji są świetne, ponieważ są dobrym sposobem na udokumentowanie wdrożenia i konfiguracji klastra. Z drugiej strony automatyzacja ewoluowała i sama w sobie stała się dużą dziedziną, wymagając wykwalifikowanych ludzi do pisania, zarządzania i uruchamiania automatycznych skryptów. Więcej informacji na temat udostępniania PostgreSQL można znaleźć w tym blogu:Zostań DBA PostgreSQL:Udostępnianie i wdrażanie.
Zarządzanie
Zarządzanie systemem działającym obejmuje zadania takie jak:planowanie kopii zapasowych i monitorowanie ich stanu, odtwarzanie po awarii, zarządzanie konfiguracją, zarządzanie wysoką dostępnością oraz automatyczna obsługa przełączania awaryjnego. Tworzenie kopii zapasowej klastra Postgresql można wykonać na różne sposoby. Narzędzia niskiego poziomu:
- tradycyjny pg_dump (logiczna kopia zapasowa)
- kopie zapasowe na poziomie systemu plików (fizyczna kopia zapasowa)
- pg_basebackup (fizyczna kopia zapasowa)
Lub wyższy poziom:
- Barman
- PgBackRest
Każdy z tych sposobów obejmuje różne przypadki użycia i scenariusze odzyskiwania oraz różni się złożonością. Backup PostgreSQL jest ściśle powiązany z pojęciami PITR, archiwizacji i replikacji WAL. Przez lata procedura wykonywania, testowania i wreszcie (z kciukiem kciuki!) korzystania z kopii zapasowych za pomocą PostgreSQL ewoluowała i stała się złożonym zadaniem. Dobry przegląd rozwiązań do tworzenia kopii zapasowych dla PostgreSQL można znaleźć w tym blogu:Najlepsze narzędzia do tworzenia kopii zapasowych dla PostgreSQL.
Jeśli chodzi o wysoką dostępność i automatyczne przełączanie awaryjne, absolutne minimum, jakie musi mieć instalacja, aby to wdrożyć, to:
- Pracująca podstawa
- Gotowy tryb gotowości akceptujący WAL przesyłany strumieniowo z podstawowego
- W przypadku niepowodzenia prawyborów, metoda informująca pierwotną, że nie jest już pierwotną (czasami nazywana STONITH)
- Mechanizm pulsu do sprawdzania łączności między dwoma serwerami i kondycji serwera podstawowego
- Metoda wykonania przełączenia awaryjnego (np. przez promowanie pg_ctl lub plik wyzwalający)
- Zautomatyzowana procedura odtwarzania starego systemu podstawowego jako nowego rezerwowego:Po wykryciu zakłócenia lub awarii na serwerze głównym rezerwowy musi być promowany jako nowy główny. Stary podstawowy nie jest już ważny ani użyteczny. Dlatego system musi mieć sposób na obsługę tego stanu między przełączeniem awaryjnym a ponownym utworzeniem starego serwera podstawowego jako nowego rezerwowego. Ten stan jest nazywany stanem zdegenerowanym, a PostgreSQL zapewnia narzędzie o nazwie pg_rewind, które przyspiesza proces przywracania starego podstawowego z powrotem do stanu umożliwiającego synchronizację z nowego podstawowego.
- Metoda dokonywania przełączeń na żądanie/planowanych
Szeroko stosowanym narzędziem, które obsługuje wszystkie powyższe, jest Repmgr. Opiszemy minimalną konfigurację, która pozwoli na udane przełączenie. Zaczynamy od działającego podstawowego PostgreSQL 10.4 działającego na FreeBSD 11.1, ręcznie zbudowanego i zainstalowanego, a repmgr 4.0 również ręcznie zbudowanego i zainstalowanego dla tej wersji (10.4). Użyjemy dwóch hostów o nazwach fbsd (192.168.1.80) i fbsdclone (192.168.1.81) z identycznymi wersjami PostgreSQL i repmgr. Na podstawowym (początkowo fbsd , 192.168.1.80) upewniamy się, że ustawione są następujące parametry PostgreSQL:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Następnie tworzymy użytkownika repmgr (jako superużytkownik) i bazę danych:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgri skonfiguruj kontrolę dostępu opartą na hoście w pg_hba.conf, umieszczając następujące wiersze na górze:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustUpewniamy się, że ustawiliśmy logowanie bez hasła dla użytkownika repmgr we wszystkich węzłach klastra, w naszym przypadku fbsd i fbsdclone, ustawiając autoryzowane_klucze w .ssh, a następnie udostępniając .ssh. Następnie tworzymy repmrg.conf na stronie głównej jako:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Następnie rejestrujemy podstawowy:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredI sprawdź stan klastra:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Teraz pracujemy w trybie gotowości, ustawiając repmgr.conf w następujący sposób:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Upewniamy się również, że katalog danych określony w wierszu powyżej istnieje, jest pusty i ma odpowiednie uprawnienia:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataTeraz musimy sklonować do naszego nowego trybu gotowości:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"I uruchom tryb gotowości:
example@sqldat.com:~ % pg_ctl -D data startW tym momencie replikacja powinna działać zgodnie z oczekiwaniami, sprawdź to, odpytując pg_stat_replication (fbsd) i pg_stat_wal_receiver (fbsdclone). Następnym krokiem jest zarejestrowanie gotowości:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerTeraz możemy uzyskać status klastra w trybie gotowości lub podstawowej i zweryfikować, czy tryb gotowości jest zarejestrowany:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Załóżmy teraz, że chcemy wykonać zaplanowane ręczne przełączenie w celu np. wykonać pewne prace administracyjne na węźle fbsd. W węźle gotowości uruchamiamy następujące polecenie:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyPrzełączenie zostało pomyślnie wykonane! Zobaczmy, co daje pokaz klastra:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Dwa serwery zamieniły się rolami! Repmgr zapewnia demona repmgrd, który zapewnia monitorowanie, automatyczne przełączanie awaryjne, a także powiadomienia/alerty. Łącząc repmgrd z pgbouncer, możliwe jest zaimplementowanie automatycznej aktualizacji informacji o połączeniu z bazą danych, zapewniając w ten sposób odgrodzenie uszkodzonego podstawowego węzła (zapobiegając jakiemukolwiek wykorzystaniu uszkodzonego węzła przez aplikację) oraz zapewniając minimalny czas przestoju aplikacji. W bardziej złożonych schematach innym pomysłem jest połączenie Keepalived z HAProxy na szczycie pgbouncer i repmgr, aby osiągnąć:
- równoważenie obciążenia (skalowanie)
- wysoka dostępność
Należy zauważyć, że ClusterControl zarządza również przełączaniem awaryjnym konfiguracji replikacji PostgreSQL oraz integruje HAProxy i VirtualIP, aby automatycznie przekierowywać połączenia klientów do działającego mastera. Więcej informacji można znaleźć w tym dokumencie na temat automatyzacji PostgreSQL.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentSkalowanie
Od PostgreSQL 10 (i 11) nadal nie ma możliwości uzyskania replikacji z wieloma wzorcami, przynajmniej nie z rdzenia PostgreSQL. Oznacza to, że tylko działanie select (tylko do odczytu) może być skalowane w górę. Skalowanie w PostgreSQL jest osiągane przez dodanie większej liczby hot standby, co zapewnia więcej zasobów dla działań tylko do odczytu. Dzięki repmgr łatwo jest dodać nowy tryb gotowości, jak widzieliśmy wcześniej za pomocą klonu gotowości i rejestr gotowości polecenia. Dodane (lub usunięte) stany gotowości muszą zostać podane do konfiguracji modułu równoważenia obciążenia. HAProxy, jak wspomniano powyżej w temacie dotyczącym zarządzania, jest popularnym systemem równoważenia obciążenia dla PostgreSQL. Zwykle jest połączony z Keepalived, który zapewnia wirtualny adres IP za pośrednictwem VRRP. Dobry przegląd używania HAProxy i Keepalived razem z PostgreSQL można znaleźć w tym artykule:Równoważenie obciążenia PostgreSQL przy użyciu HAProxy i Keepalived.
Monitorowanie
Omówienie tego, co monitorować w PostgreSQL można znaleźć w tym artykule:Kluczowe rzeczy do monitorowania w PostgreSQL - Analiza obciążenia. Istnieje wiele narzędzi, które umożliwiają monitorowanie systemu i postgresql za pomocą wtyczek. Niektóre narzędzia obejmują obszar prezentacji graficznego wykresu wartości historycznych (munin), inne narzędzia obejmują obszar monitorowania danych na żywo i alarmowania na żywo (nagios), a niektóre narzędzia obejmują oba obszary (zabbix). Listę takich narzędzi dla PostgreSQL można znaleźć tutaj:https://wiki.postgresql.org/wiki/Monitoring. Popularnym narzędziem do monitorowania offline (opartego na plikach dziennika) jest pgBadger. pgBadger to skrypt Perla, który działa poprzez parsowanie dziennika PostgreSQL (który zwykle obejmuje aktywność jednego dnia), wydobywanie informacji, obliczanie statystyk i wreszcie tworzenie fantazyjnej strony html prezentującej wyniki. pgBadger nie ogranicza ustawienia log_line_prefix, może dostosować się do już istniejącego formatu. Na przykład, jeśli ustawiłeś w swoim postgresql.conf coś takiego:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'następnie polecenie pgbadger, aby przeanalizować plik dziennika i wygenerować wyniki, może wyglądać tak:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger dostarcza raporty dla:
- Przegląd statystyk (głównie ruch SQL)
- Połączenia (na sekundę, na bazę danych/użytkownika/host)
- Sesje (liczba, czasy sesji, na bazę danych/użytkownika/host/aplikację)
- Punkty kontrolne (bufory, pliki wal, aktywność)
- Użycie plików tymczasowych
- Odkurzanie/analiza aktywności (na tabelę, krotki/strony usunięte)
- Zamki
- Zapytania (według typu/bazy danych/użytkownika/hosta/aplikacji, czas trwania według użytkownika)
- Najpopularniejsze (zapytania:najwolniejsze, czasochłonne, częstsze, znormalizowane najwolniejsze)
- Zdarzenia (błędy, ostrzeżenia, ofiary śmiertelne itp.)
Ekran pokazujący sesje wygląda tak:
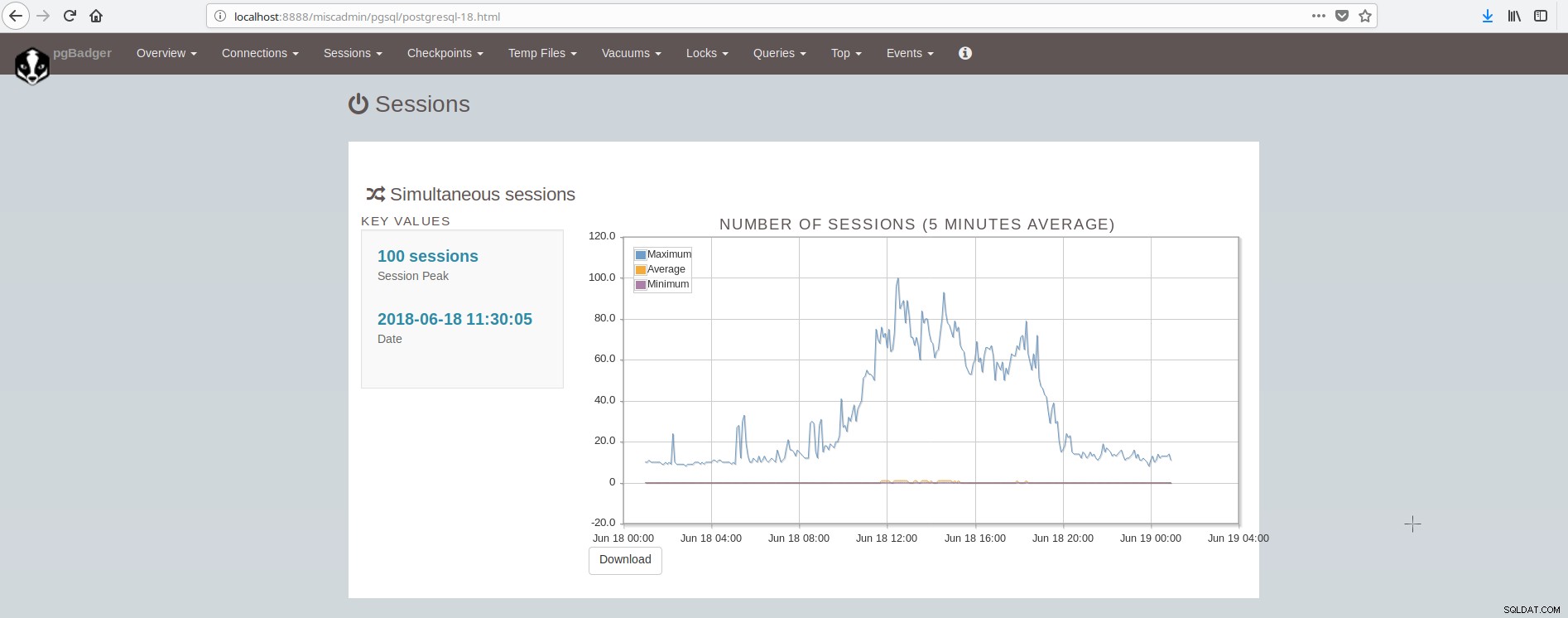
Jak możemy wnioskować, przeciętna instalacja PostgreSQL musi integrować i dbać o wiele narzędzi, aby mieć nowoczesną, niezawodną i szybką infrastrukturę, a jest to dość skomplikowane do osiągnięcia, chyba że istnieją duże zespoły zaangażowane w postgresql i administrację systemem. Świetnym pakietem, który wykonuje wszystkie powyższe i więcej, jest ClusterControl.