Przegląd
W tym artykule omówiono dwa różne dostępne podejścia do usuwania zduplikowanych wierszy z tabel SQL, co często staje się trudne w miarę wzrostu danych, jeśli nie zostanie to zrobione na czas.
Obecność zduplikowanych wierszy jest częstym problemem, z którym od czasu do czasu borykają się programiści i testerzy SQL, jednak te zduplikowane wiersze należą do wielu różnych kategorii, które omówimy w tym artykule.
Ten artykuł koncentruje się na konkretnym scenariuszu, w którym dane wstawione do tabeli bazy danych prowadzą do wprowadzenia zduplikowanych rekordów, a następnie przyjrzymy się bliżej metodom usuwania duplikatów i ostatecznie usuwamy duplikaty za pomocą tych metod.
Przygotowywanie przykładowych danych
Zanim zaczniemy badać różne dostępne opcje usuwania duplikatów, warto w tym miejscu skonfigurować przykładową bazę danych, która pomoże nam zrozumieć sytuacje, w których zduplikowane dane trafiają do systemu, oraz metody, które należy zastosować, aby je wyeliminować .
Skonfiguruj przykładową bazę danych (UniversityV2)
Zacznij od stworzenia bardzo prostej bazy danych, która składa się tylko z Studenta tabela na początku.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Wypełnij tabelę uczniów
Dodajmy tylko dwa rekordy do tabeli Student:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Sprawdzanie danych
Zobacz tabelę, która w tej chwili zawiera dwa różne rekordy:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
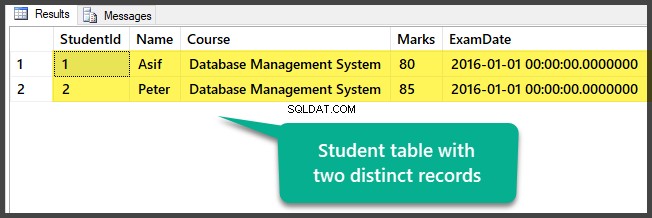
Pomyślnie przygotowałeś przykładowe dane, konfigurując bazę danych z jedną tabelą i dwoma różnymi (różnymi) rekordami.
Omówimy teraz kilka potencjalnych scenariuszy, w których duplikaty zostały wprowadzone i usunięte, począwszy od prostych do nieco złożonych sytuacji.
Przypadek 01:Dodawanie i usuwanie duplikatów
Teraz wprowadzimy zduplikowane wiersze w tabeli Student.
Warunki
W takim przypadku mówi się, że tabela zawiera zduplikowane rekordy, jeśli imię i nazwisko ucznia , Kurs , Znaki i Data Egzaminu pokrywają się w więcej niż jednym rekordzie, nawet jeśli identyfikator ucznia jest inny.
Tak więc zakładamy, że dwóch uczniów nie może mieć tego samego nazwiska, kursu, ocen i daty egzaminu.
Dodawanie zduplikowanych danych dla ucznia Asif
Celowo wstawmy zduplikowany rekord dla Student:Asif do Studenta tabela w następujący sposób:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Wyświetl zduplikowane dane uczniów
Wyświetl Studenta tabela, aby zobaczyć zduplikowane rekordy:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
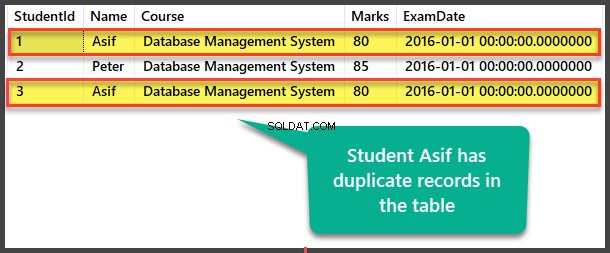
Znajdowanie duplikatów metodą samoodniesienia
A jeśli w tej tabeli są tysiące rekordów, to przeglądanie tabeli nie będzie zbyt pomocne.
W metodzie odwoływania się do siebie bierzemy dwa odniesienia do tej samej tabeli i łączymy je za pomocą mapowania kolumna po kolumnie, z wyjątkiem identyfikatora, który jest mniejszy lub większy od drugiego.
Przyjrzyjmy się metodzie odwoływania się do siebie, aby znaleźć duplikaty, które wyglądają tak:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
Wynik powyższego skryptu pokazuje nam tylko zduplikowane rekordy:

Znajdowanie duplikatów metodą samoodniesienia-2
Innym sposobem na znalezienie duplikatów przy użyciu odniesień do siebie jest użycie INNER JOIN w następujący sposób:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Usuwanie duplikatów metodą samoodniesienia
Duplikaty możemy usunąć za pomocą tej samej metody, której używaliśmy do wyszukiwania duplikatów, z wyjątkiem użycia DELETE zgodnie z jego składnią w następujący sposób:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Sprawdzanie danych po usunięciu duplikatów
Pozwól nam szybko sprawdzić rekordy po usunięciu duplikatów:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
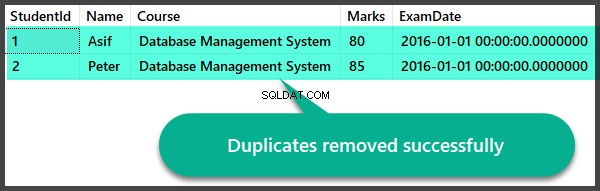
Tworzenie duplikatów Wyświetl i usuń zapisaną procedurę
Teraz, gdy wiemy, że nasze skrypty mogą z powodzeniem znajdować i usuwać zduplikowane wiersze w SQL, lepiej jest przekształcić je w widok i procedurę składowaną, aby ułatwić korzystanie:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
Dodawanie i przeglądanie wielu zduplikowanych rekordów
Dodajmy teraz cztery kolejne rekordy do Studenta tabela i wszystkie rekordy są duplikatami w taki sposób, że mają tę samą nazwę, kurs, oceny i datę egzaminu:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
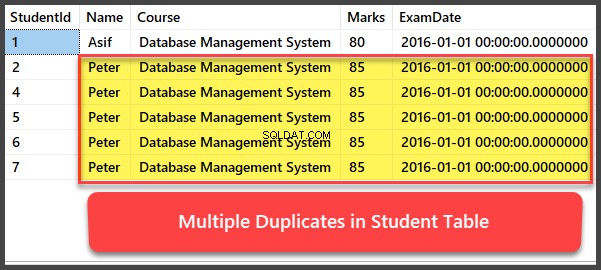
Usuwanie duplikatów za pomocą procedury UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
Sprawdzanie danych po usunięciu wielu duplikatów
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
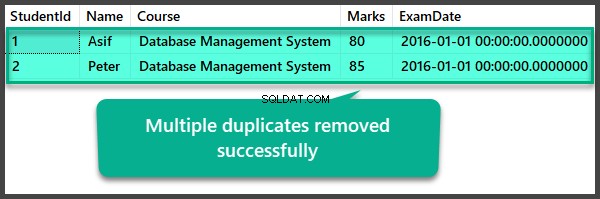
Przypadek 02:dodawanie i usuwanie duplikatów z tymi samymi identyfikatorami
Do tej pory zidentyfikowaliśmy zduplikowane rekordy o różnych identyfikatorach, ale co, jeśli identyfikatory są takie same.
Na przykład pomyśl o scenariuszu, w którym tabela została niedawno zaimportowana z pliku tekstowego lub pliku Excel, który nie ma klucza podstawowego.
Warunki
W tym przypadku mówi się, że tabela zawiera zduplikowane rekordy, jeśli wszystkie wartości kolumn są dokładnie takie same, w tym niektóre kolumny ID i brakuje klucza podstawowego, co ułatwiło wprowadzenie zduplikowanych rekordów.
Utwórz tabelę kursów bez klucza podstawowego
Aby odtworzyć scenariusz, w którym zduplikowane rekordy przy braku klucza podstawowego trafiają do tabeli, utwórzmy najpierw nowy Kurs tabela bez klucza podstawowego w bazie danych Uniwersytetu2 w następujący sposób:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Wypełnij tabelę kursów
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Sprawdzanie danych
Wyświetl Kurs tabela:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
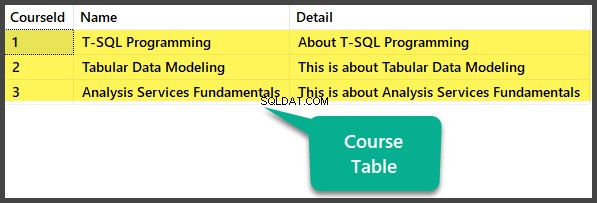
Dodawanie zduplikowanych danych w tabeli kursów
Teraz wstaw duplikaty do Kursu tabela:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Wyświetl zduplikowane dane kursu
Wybierz wszystkie kolumny, aby wyświetlić tabelę:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

Znajdowanie duplikatów metodą agregacji
Dokładne duplikaty możemy znaleźć za pomocą metody agregacji, grupując wszystkie kolumny z sumą większą niż jedna po wybraniu wszystkich kolumn wraz z policzeniem wszystkich wierszy za pomocą funkcji agregacji count(*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Można to zastosować w następujący sposób:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
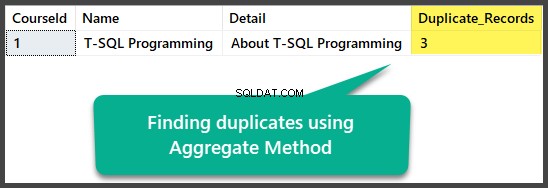
Usuwanie duplikatów metodą agregacji
Usuńmy duplikaty za pomocą metody agregacji w następujący sposób:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Sprawdzanie danych
UŻYJ Uniwersytet V2
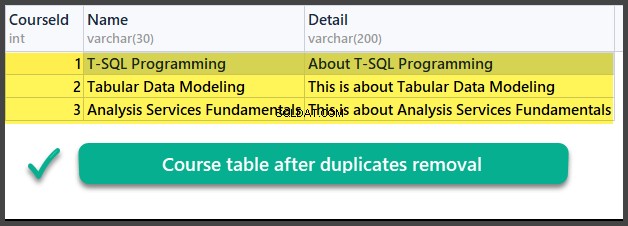
Tak więc z powodzeniem nauczyliśmy się, jak usuwać duplikaty z tabeli bazy danych za pomocą dwóch różnych metod opartych na dwóch różnych scenariuszach.
Rzeczy do zrobienia
Możesz teraz łatwo zidentyfikować i zwolnić tabelę bazy danych ze zduplikowanej wartości.
1. Spróbuj utworzyć UspRemoveDuplicatesByAggregate procedura składowana oparta na metodzie wspomnianej powyżej i usuń duplikaty poprzez wywołanie procedury składowanej
2. Spróbuj zmodyfikować procedurę składowaną utworzoną powyżej (UspRemoveDuplicatesByAggregates) i zaimplementuj wskazówki dotyczące czyszczenia wymienione w tym artykule.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Czy możesz być pewien, że UspRemoveDuplicatesByAggregate procedura składowana może być wykonywana tyle razy, ile to możliwe, nawet po usunięciu duplikatów, aby pokazać, że procedura pozostaje spójna?
4. Proszę zapoznać się z moim poprzednim artykułem Skok, aby rozpocząć tworzenie baz danych sterowane testami (TDDD) – część 1 i spróbuj wstawić duplikaty do tabel bazy danych SQLDevBlog, a następnie spróbuj usunąć duplikaty przy użyciu obu metod wymienionych w tej wskazówce.
5. Spróbuj utworzyć kolejną przykładową bazę danych EmployeesSample odnosząc się do mojego poprzedniego artykułu Sztuka izolowania zależności i danych w testowaniu jednostek bazy danych i wstawiaj duplikaty do tabel i spróbuj je usunąć, korzystając z obu metod, których nauczyłeś się z tej wskazówki.
Przydatne narzędzie:
dbForge Data Compare for SQL Server – potężne narzędzie do porównywania danych SQL zdolne do pracy z dużymi danymi.