Pracując w branży IT prawdopodobnie nie raz słyszeliśmy słowo „failover”, ale może ono również rodzić pytania typu:Czym tak naprawdę jest failover? Do czego możemy go wykorzystać? Czy to ważne, żeby go mieć? Jak możemy to zrobić?
Choć mogą wydawać się dość podstawowe pytania, ważne jest, aby wziąć je pod uwagę w każdym środowisku bazy danych. I najczęściej nie bierzemy pod uwagę podstaw...
Na początek spójrzmy na kilka podstawowych koncepcji.
Co to jest przełączanie awaryjne?
Przełączanie awaryjne to zdolność systemu do dalszego działania, nawet jeśli wystąpi jakaś awaria. Sugeruje to, że funkcje systemu są przejmowane przez komponenty drugorzędne, jeśli główne komponenty ulegną awarii.
W przypadku PostgreSQL istnieją różne narzędzia, które pozwalają na zaimplementowanie odpornego na awarie klastra bazy danych. Jednym z mechanizmów redundancji dostępnych natywnie w PostgreSQL jest replikacja. A nowością w PostgreSQL 10 jest implementacja replikacji logicznej.
Co to jest replikacja?
Jest to proces kopiowania i aktualizowania danych w jednym lub kilku węzłach bazy danych. Wykorzystuje koncepcję węzła głównego, który odbiera modyfikacje, oraz węzłów podrzędnych, w których są one replikowane.
Mamy kilka sposobów kategoryzacji replikacji:
- Replikacja synchroniczna:nie ma utraty danych, nawet jeśli nasz węzeł główny zostanie utracony, ale zatwierdzenia w urządzeniu głównym muszą czekać na potwierdzenie od urządzenia podrzędnego, co może wpłynąć na wydajność.
- Replikacja asynchroniczna:Istnieje możliwość utraty danych w przypadku utraty naszego węzła głównego. Jeśli replika z jakiegoś powodu nie zostanie zaktualizowana w momencie incydentu, informacje, które nie zostały skopiowane, mogą zostać utracone.
- Replikacja fizyczna:bloki dysku są kopiowane.
- Replikacja logiczna:przesyłanie strumieniowe zmian danych.
- Podrzędne urządzenia w trybie ciepłej gotowości:nie obsługują połączeń.
- Hot Standby Slave:Obsługuje połączenia tylko do odczytu, przydatne w przypadku raportów lub zapytań.
Do czego służy przełączanie awaryjne?
Istnieje kilka możliwych zastosowań przełączania awaryjnego. Zobaczmy kilka przykładów.
Migracja
Jeśli chcemy przeprowadzić migrację z jednego centrum danych do drugiego, minimalizując przestoje, możemy skorzystać z funkcji przełączania awaryjnego.
Załóżmy, że nasz master znajduje się w centrum danych A i chcemy przenieść nasze systemy do centrum danych B.
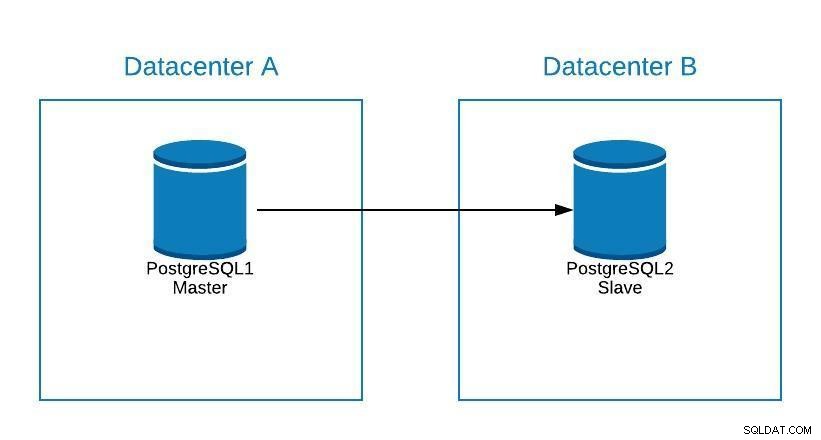 Schemat migracji 1
Schemat migracji 1 Możemy utworzyć replikę w centrum danych B. Po zsynchronizowaniu musimy zatrzymać nasz system, wypromować naszą replikę do nowego systemu głównego i przełączenia awaryjnego, zanim skierujemy nasz system do nowego systemu głównego w centrum danych B.
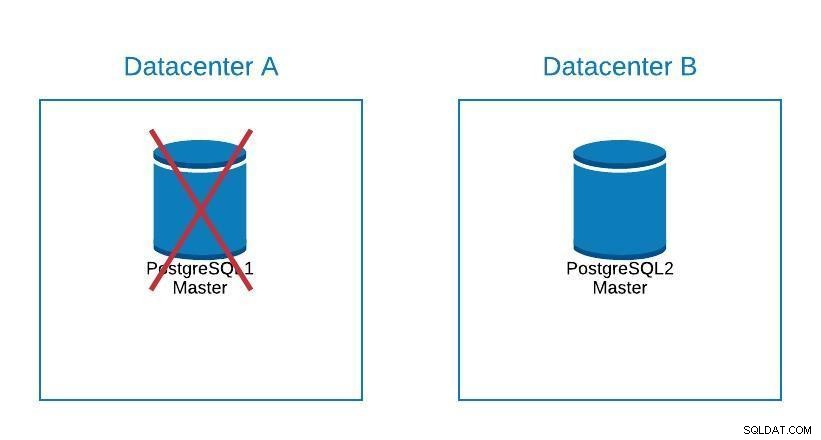 Schemat migracji 2
Schemat migracji 2 Przełączanie awaryjne dotyczy nie tylko bazy danych, ale także aplikacji. Skąd wiedzą, z którą bazą danych mają się połączyć? Na pewno nie chcemy modyfikować naszej aplikacji, ponieważ wydłuży to tylko nasz czas przestoju. Możemy więc skonfigurować load balancer tak, aby po wyłączeniu naszego mastera automatycznie wskazywał następny promowany serwer.
Inną opcją jest użycie DNS. Promując replikę główną w nowym centrum danych, bezpośrednio modyfikujemy adres IP nazwy hosta, która wskazuje na mastera. W ten sposób unikamy konieczności modyfikowania naszej aplikacji i chociaż nie można tego zrobić automatycznie, jest to alternatywa, jeśli nie chcemy wdrażać load balancera.
Posiadanie jednej instancji modułu równoważenia obciążenia nie jest wspaniałe, ponieważ może stać się pojedynczym punktem awarii. W związku z tym można również zaimplementować przełączanie awaryjne dla modułu równoważenia obciążenia za pomocą usługi, takiej jak keepalived. W ten sposób, jeśli mamy problem z naszym głównym systemem równoważenia obciążenia, keepalived jest odpowiedzialny za migrację adresu IP do naszego dodatkowego systemu równoważenia obciążenia, a wszystko nadal działa przejrzyście.
Konserwacja
Jeśli musimy wykonać jakąkolwiek konserwację na naszym głównym serwerze bazy danych postgreSQL, możemy promować nasz serwer podrzędny, wykonać zadanie i zrekonstruować urządzenie podrzędne na naszym starym serwerze głównym.
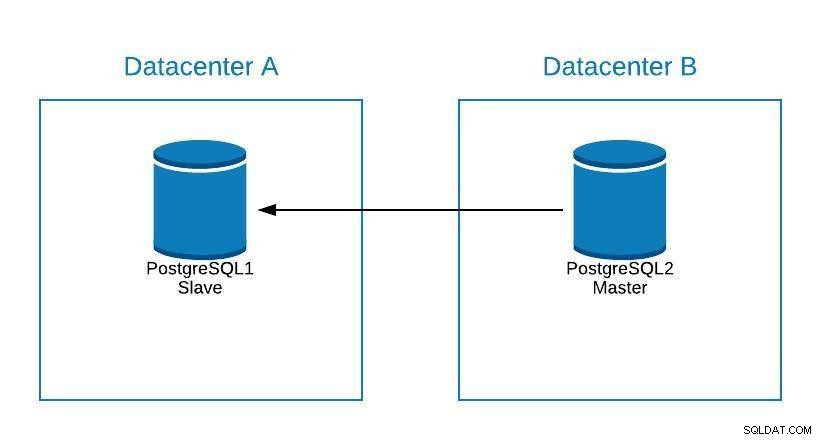 Schemat konserwacji 1
Schemat konserwacji 1 Następnie możemy ponownie promować starego mistrza i powtórzyć proces rekonstrukcji niewolnika, wracając do stanu początkowego.
Schemat konserwacji 2 W ten sposób moglibyśmy pracować na naszym serwerze bez narażania się na ryzyko braku połączenia lub utraty informacji podczas wykonywania prac konserwacyjnych.
Aktualizacja
Chociaż PostgreSQL 11 nie jest jeszcze dostępny, byłoby technicznie możliwe uaktualnienie z PostgreSQL w wersji 10 przy użyciu replikacji logicznej, tak jak można to zrobić z innymi silnikami.
Kroki byłyby takie same, jak przy migracji do nowego centrum danych (patrz sekcja Migracja), z tą różnicą, że nasze urządzenie podrzędne byłoby w PostgreSQL 11.
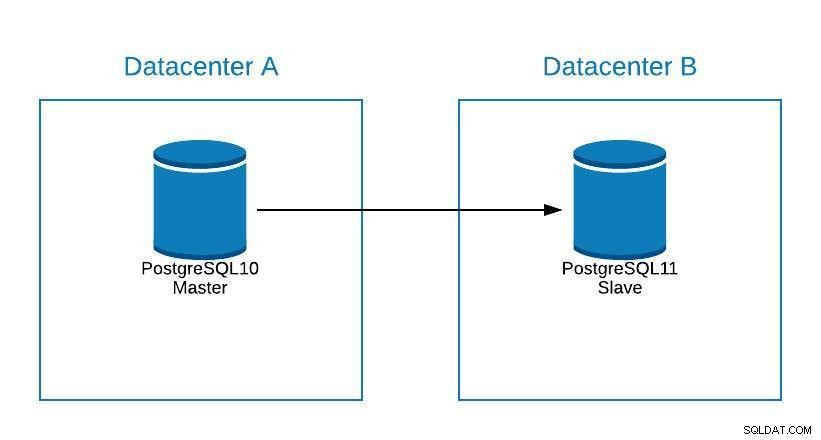 Schemat aktualizacji 1
Schemat aktualizacji 1 Problemy
Najważniejszą funkcją przełączania awaryjnego jest zminimalizowanie przestojów lub uniknięcie utraty informacji w przypadku problemów z naszą główną bazą danych.
Jeśli z jakiegoś powodu stracimy naszą bazę danych master, możemy wykonać przełączanie awaryjne, promując nasz slave na master i utrzymać działanie naszych systemów.
Aby to zrobić, PostgreSQL nie udostępnia nam żadnego zautomatyzowanego rozwiązania. Możemy to zrobić ręcznie lub zautomatyzować za pomocą skryptu lub zewnętrznego narzędzia.
Aby awansować naszego niewolnika na pana:
-
Uruchom pg_ctl promować
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Utwórz plik trigger_file, który musimy dodać w recovery.conf w naszym katalogu danych.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Aby wdrożyć strategię przełączania awaryjnego, musimy ją zaplanować i dokładnie przetestować w różnych scenariuszach awarii. Ponieważ awarie mogą się zdarzyć na różne sposoby, rozwiązanie powinno idealnie działać w większości typowych scenariuszy. Jeśli szukamy sposobu na zautomatyzowanie tego, możemy zapoznać się z ofertą ClusterControl.
ClusterControl dla przełączania awaryjnego PostgreSQL
ClusterControl ma wiele funkcji związanych z replikacją PostgreSQL i automatycznym przełączaniem awaryjnym.
Dodaj urządzenie podrzędne
Jeśli chcemy dodać urządzenie podrzędne w innym centrum danych, jako awaryjne lub w celu migracji systemów, możemy przejść do Akcji klastra i wybrać Dodaj urządzenie podrzędne replikacji.
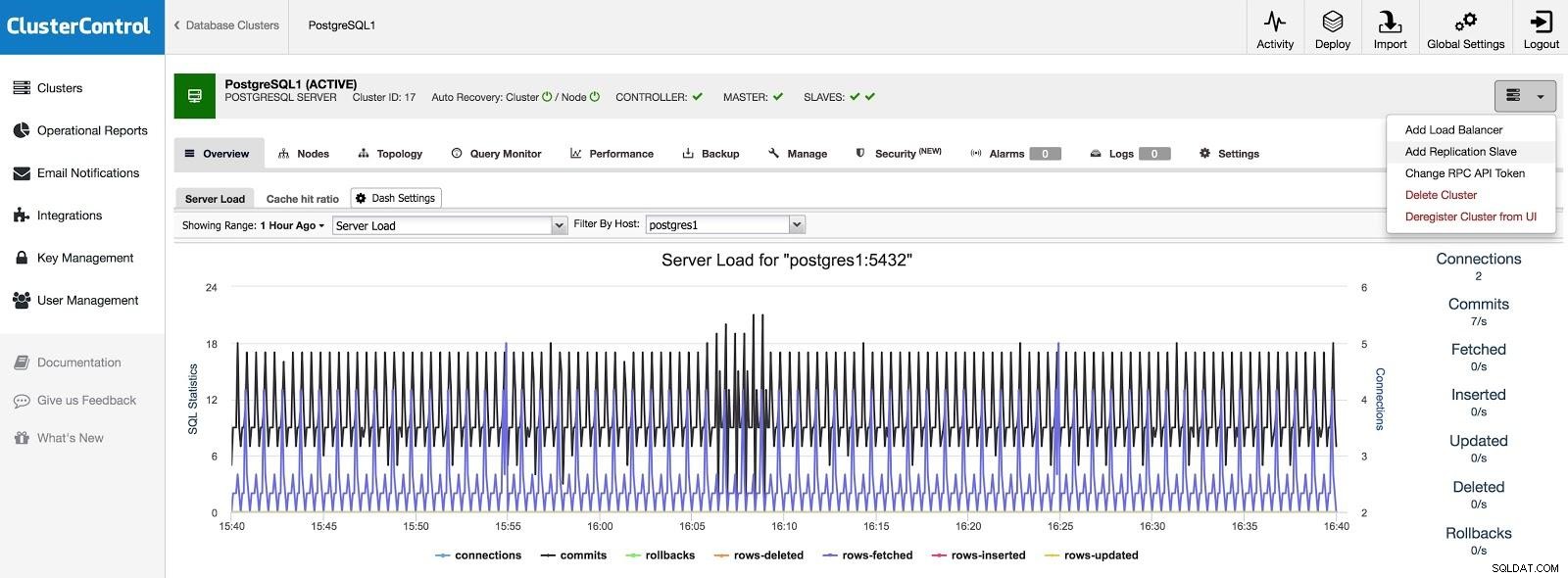 ClusterControl Dodaj moduł podrzędny 1
ClusterControl Dodaj moduł podrzędny 1 Będziemy musieli wprowadzić podstawowe dane, takie jak IP lub nazwa hosta, katalog danych (opcjonalnie), synchroniczny lub asynchroniczny slave. Powinniśmy uruchomić naszego niewolnika po kilku sekundach.
W przypadku korzystania z innego centrum danych zalecamy utworzenie asynchronicznego urządzenia podrzędnego, ponieważ w przeciwnym razie opóźnienie może znacznie wpłynąć na wydajność.
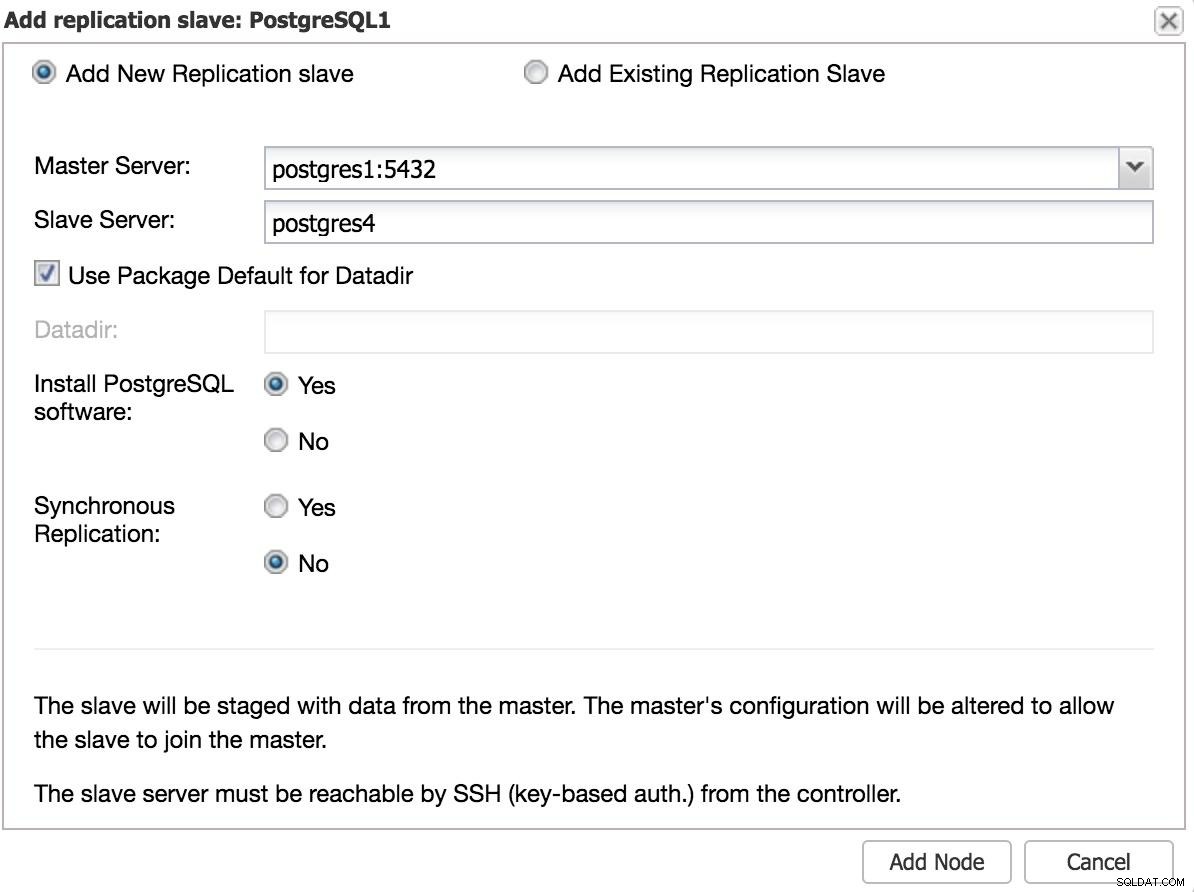 ClusterControl Dodaj moduł podrzędny 2
ClusterControl Dodaj moduł podrzędny 2 Ręczne przełączanie awaryjne
Dzięki ClusterControl przełączanie awaryjne można wykonać ręcznie lub automatycznie.
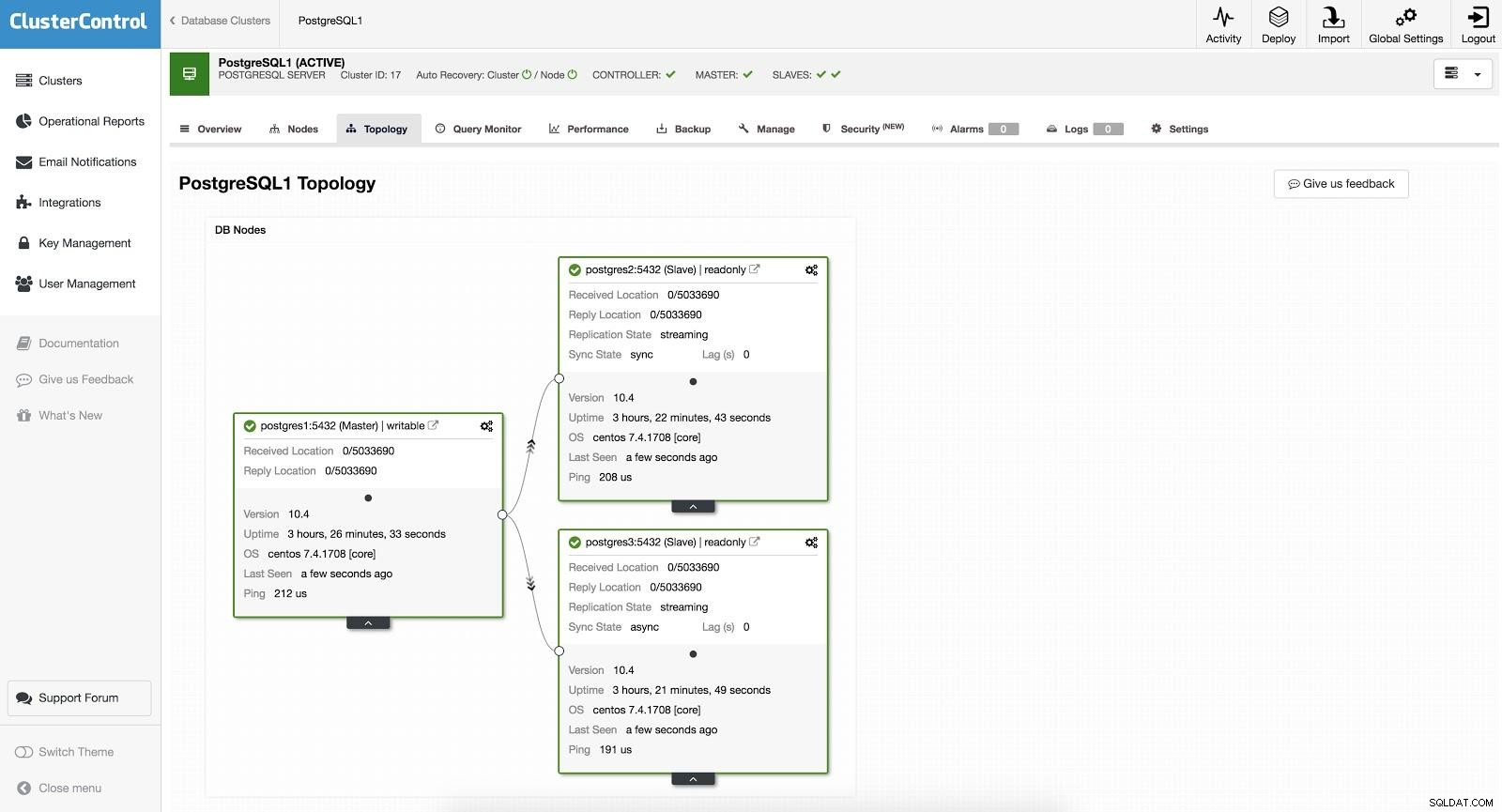 ClusterControl Failover 1
ClusterControl Failover 1 Aby wykonać ręczne przełączanie awaryjne, przejdź do ClusterControl -> Select Cluster -> Nodes, a w węźle akcji jednego z naszych urządzeń podrzędnych wybierz „Promote Slave”. W ten sposób po kilku sekundach nasz niewolnik staje się panem, a to, co było wcześniej naszym panem, staje się niewolnikiem.
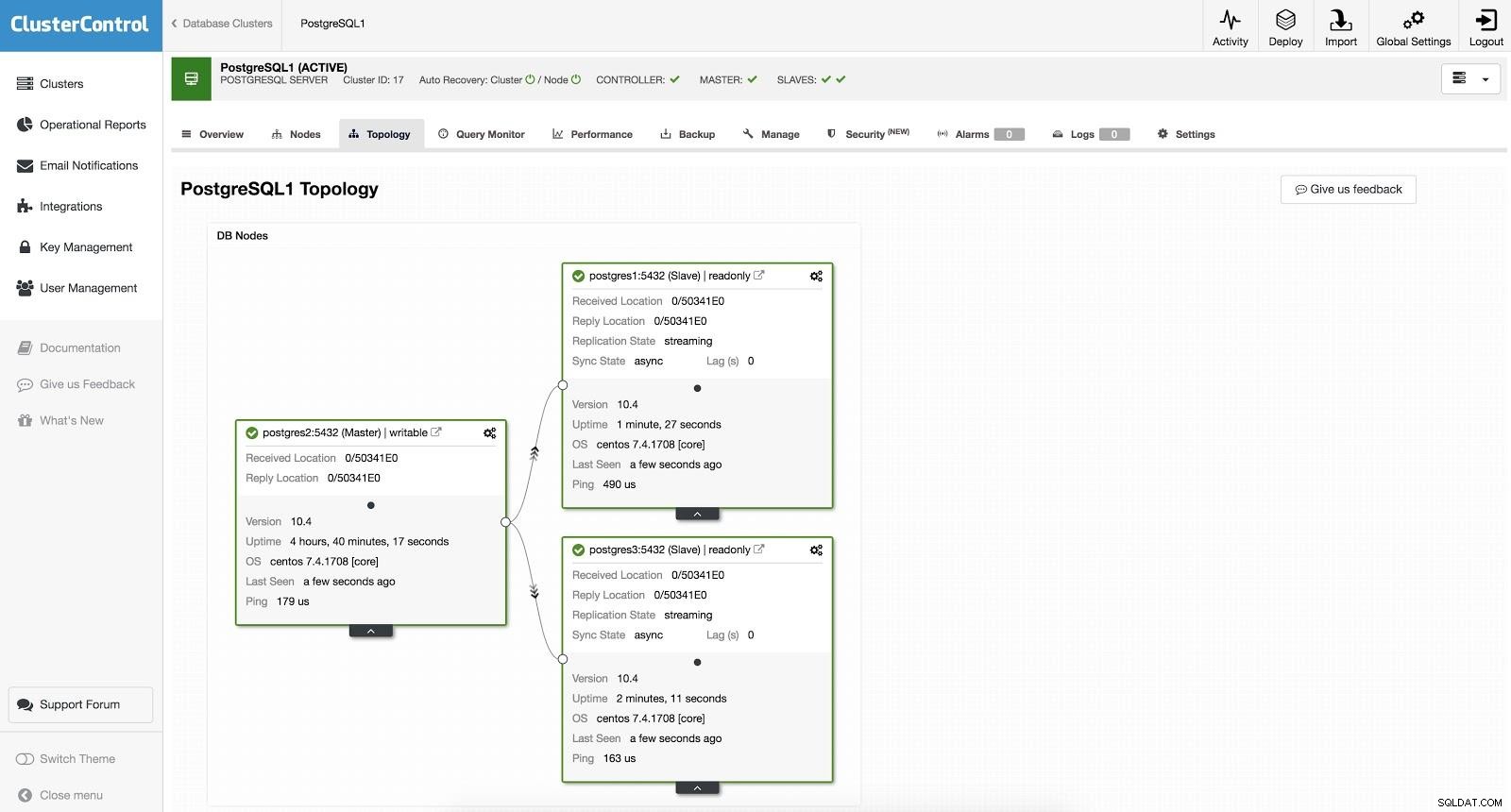 ClusterControl Failover 2
ClusterControl Failover 2 Powyższe jest przydatne w zadaniach migracji, konserwacji i aktualizacji, które widzieliśmy wcześniej.
Automatyczne przełączanie awaryjne
W przypadku automatycznego przełączania awaryjnego, ClusterControl wykrywa awarie w urządzeniu nadrzędnym i promuje urządzenie podrzędne z najbardziej aktualnymi danymi jako nowe urządzenie nadrzędne. Działa również na pozostałych urządzeniach podrzędnych, aby były replikowane z nowego urządzenia głównego.
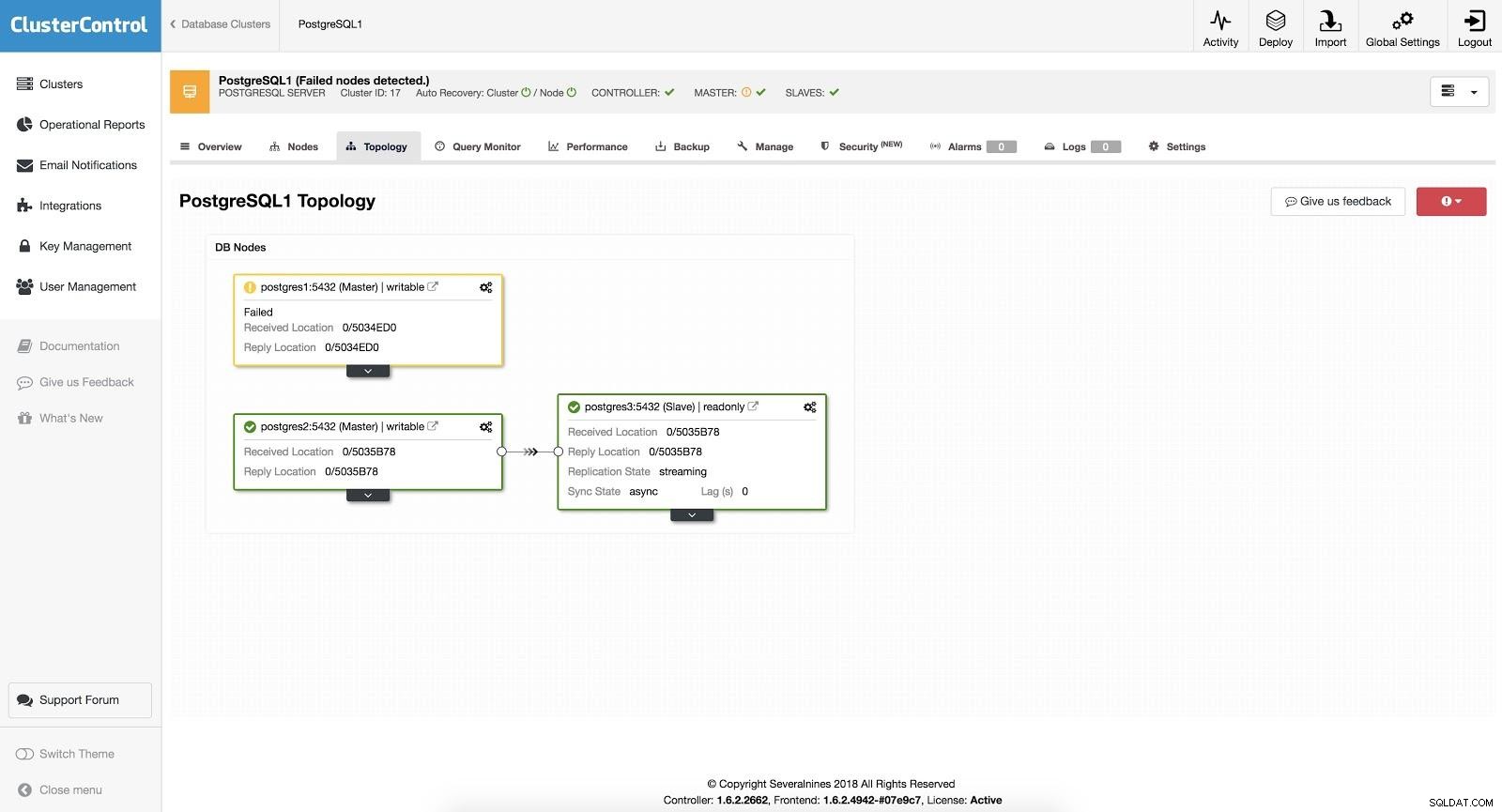 ClusterControl Failover 3
ClusterControl Failover 3 Mając WŁĄCZONĄ opcję „Autoodzyskiwanie”, nasz ClusterControl wykona automatyczne przełączanie awaryjne, a także powiadomi nas o problemie. W ten sposób nasze systemy mogą odzyskać sprawność w ciągu kilku sekund i bez naszej interwencji.
Cluster Control oferuje nam możliwość skonfigurowania białej/czarnej listy, aby określić, w jaki sposób chcemy, aby nasze serwery były brane pod uwagę (lub nie) przy podejmowaniu decyzji o wyborze głównego kandydata.
Spośród dostępnych zgodnie z powyższą konfiguracją, ClusterControl wybierze najbardziej zaawansowany slave, wykorzystując do tego celu pg_current_xlog_location (PostgreSQL 9+) lub pg_current_wal_lsn (PostgreSQL 10+) w zależności od wersji naszej bazy danych.
ClusterControl wykonuje również kilka kontroli procesu przełączania awaryjnego, aby uniknąć niektórych typowych błędów. Jednym z przykładów jest to, że jeśli uda nam się odzyskać naszego starego, uszkodzonego mastera, NIE zostanie on automatycznie ponownie wprowadzony do klastra, ani jako master, ani jako slave. Musimy to zrobić ręcznie. Pozwoli to uniknąć możliwości utraty danych lub niespójności w przypadku, gdy nasz slave (którego promowaliśmy) był opóźniony w momencie awarii. Możemy również chcieć szczegółowo przeanalizować problem, ale dodając go do naszego klastra, prawdopodobnie stracimy informacje diagnostyczne.
Ponadto, jeśli przełączanie awaryjne nie powiedzie się, nie są podejmowane żadne dalsze próby, wymagana jest ręczna interwencja w celu przeanalizowania problemu i wykonania odpowiednich działań. Ma to na celu uniknięcie sytuacji, w której ClusterControl, jako menedżer wysokiej dostępności, próbuje promować kolejne urządzenie podrzędne i następne. Może wystąpić problem i nie chcemy pogarszać sytuacji, próbując wielu przełączeń awaryjnych.
Systemy równoważenia obciążenia
Jak wspomnieliśmy wcześniej, system równoważenia obciążenia jest ważnym narzędziem do rozważenia podczas przełączania awaryjnego, zwłaszcza jeśli chcemy użyć automatycznego przełączania awaryjnego w naszej topologii bazy danych.
Aby przełączanie awaryjne było transparentne zarówno dla użytkownika, jak i aplikacji, potrzebujemy komponentu pośredniego, ponieważ nie wystarczy awansować mastera na slave. W tym celu możemy użyć HAProxy + Keepalived.
Co to jest HAProxy?
HAProxy to moduł równoważenia obciążenia, który dystrybuuje ruch z jednego źródła do jednego lub więcej miejsc docelowych i może zdefiniować określone reguły i/lub protokoły dla tego zadania. Jeśli którykolwiek z miejsc docelowych przestanie odpowiadać, zostaje oznaczony jako offline, a ruch jest przesyłany do pozostałych dostępnych miejsc docelowych. Zapobiega to wysyłaniu ruchu do niedostępnego miejsca docelowego i zapobiega utracie tego ruchu, kierując go do prawidłowego miejsca docelowego.
Co to jest Keepalive?
Keepalived umożliwia konfigurację wirtualnego adresu IP w ramach aktywnej/pasywnej grupy serwerów. Ten wirtualny adres IP jest przypisany do aktywnego „podstawowego” serwera. Jeśli ten serwer ulegnie awarii, adres IP zostanie automatycznie przeniesiony na serwer „dodatkowy”, który okazał się pasywny, co pozwala mu kontynuować pracę z tym samym adresem IP w przejrzysty sposób dla naszych systemów.
Aby zaimplementować to rozwiązanie za pomocą ClusterControl, zaczęliśmy tak, jakbyśmy mieli dodać urządzenie podrzędne. Przejdź do Cluster Actions i wybierz Add Load Balancer (zobacz ClusterControl Add Slave 1 image).
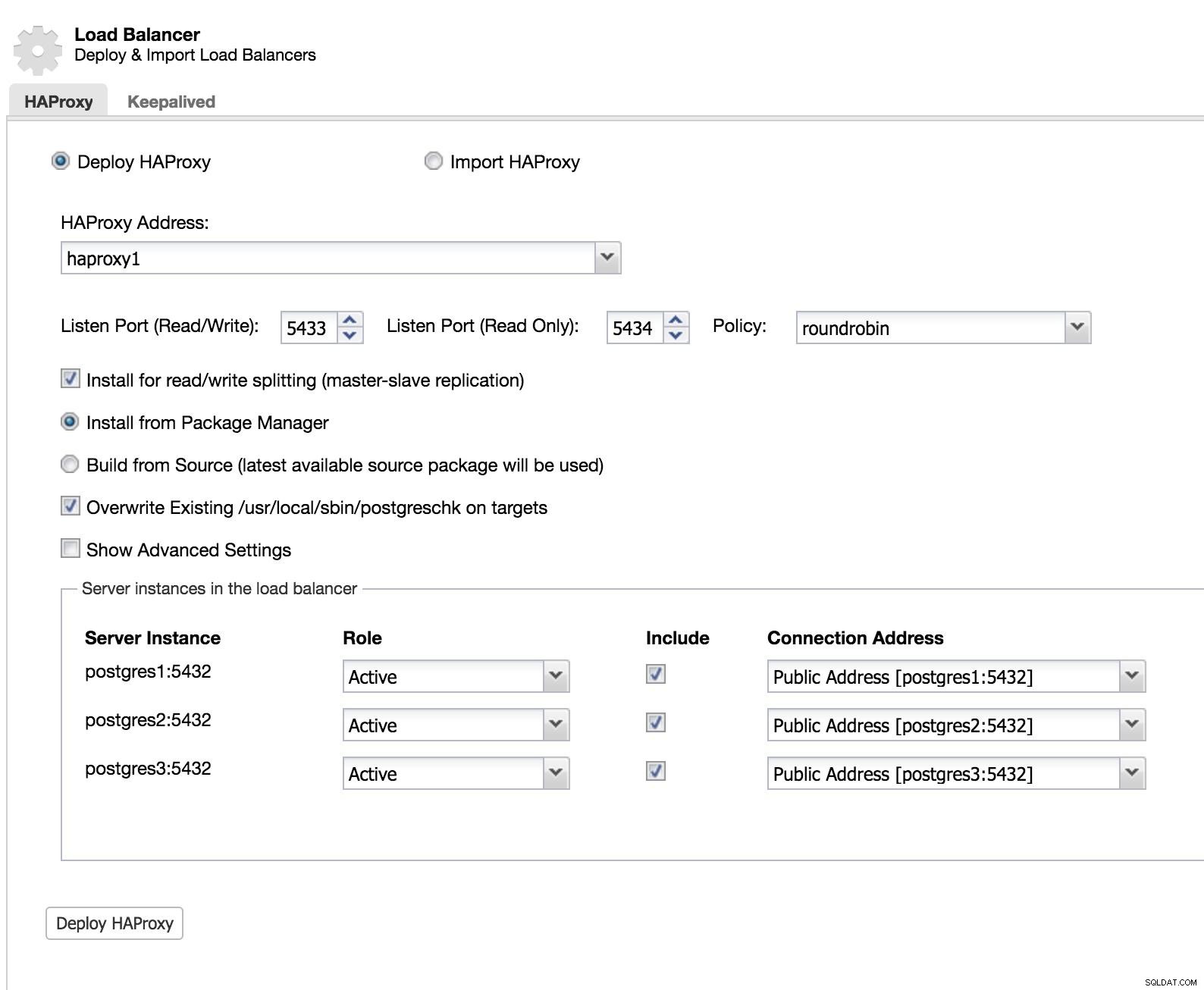 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Dodajemy informacje o naszym nowym systemie równoważenia obciążenia oraz o tym, jak chcemy, aby się zachowywał (Polityka).
W przypadku chęci zaimplementowania przełączania awaryjnego dla naszego load balancera, musimy skonfigurować co najmniej dwie instancje.
Następnie możemy skonfigurować Keepalived (Wybierz klaster -> Zarządzaj -> Load Balancer -> Keepalived).
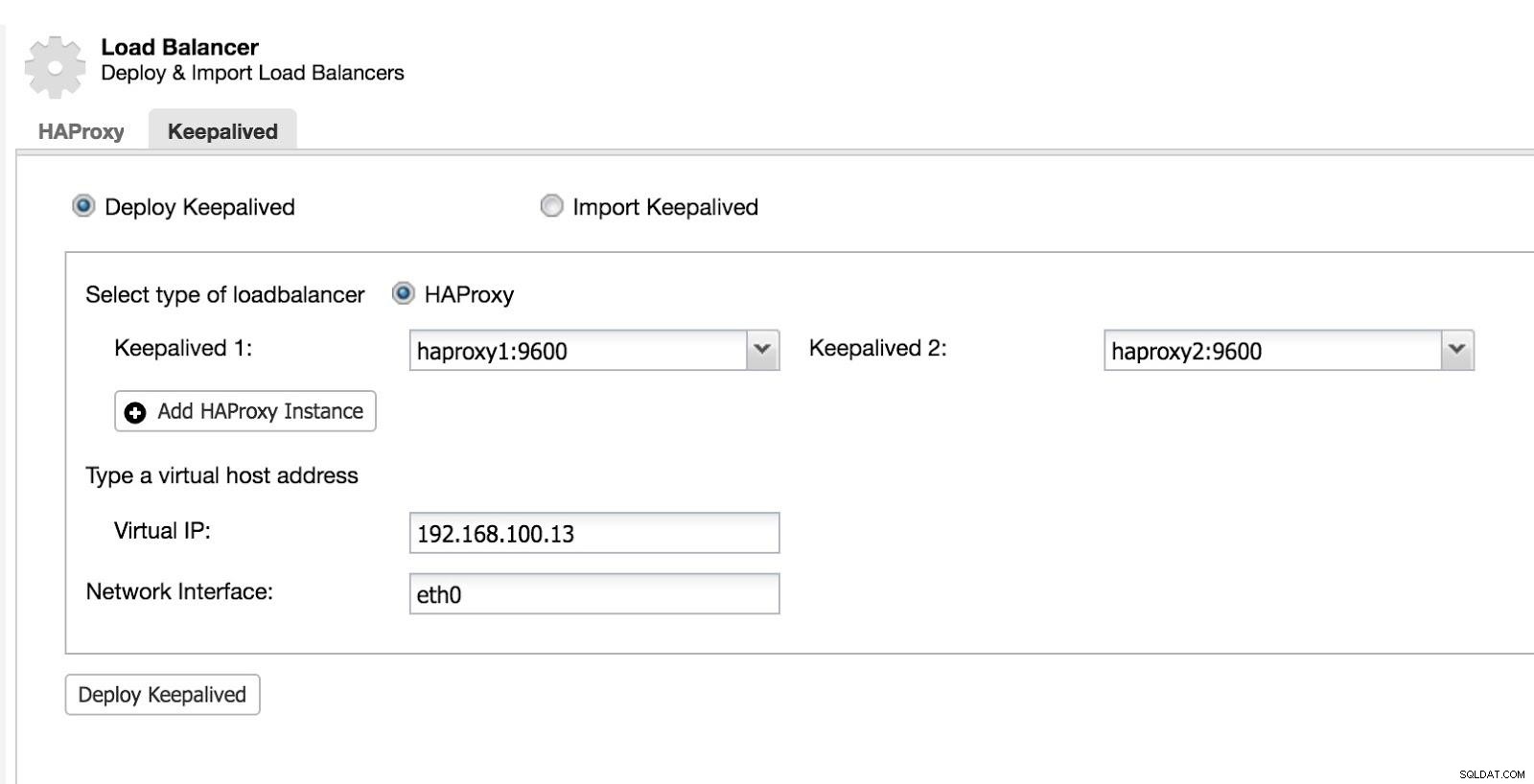 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Następnie mamy następującą topologię:
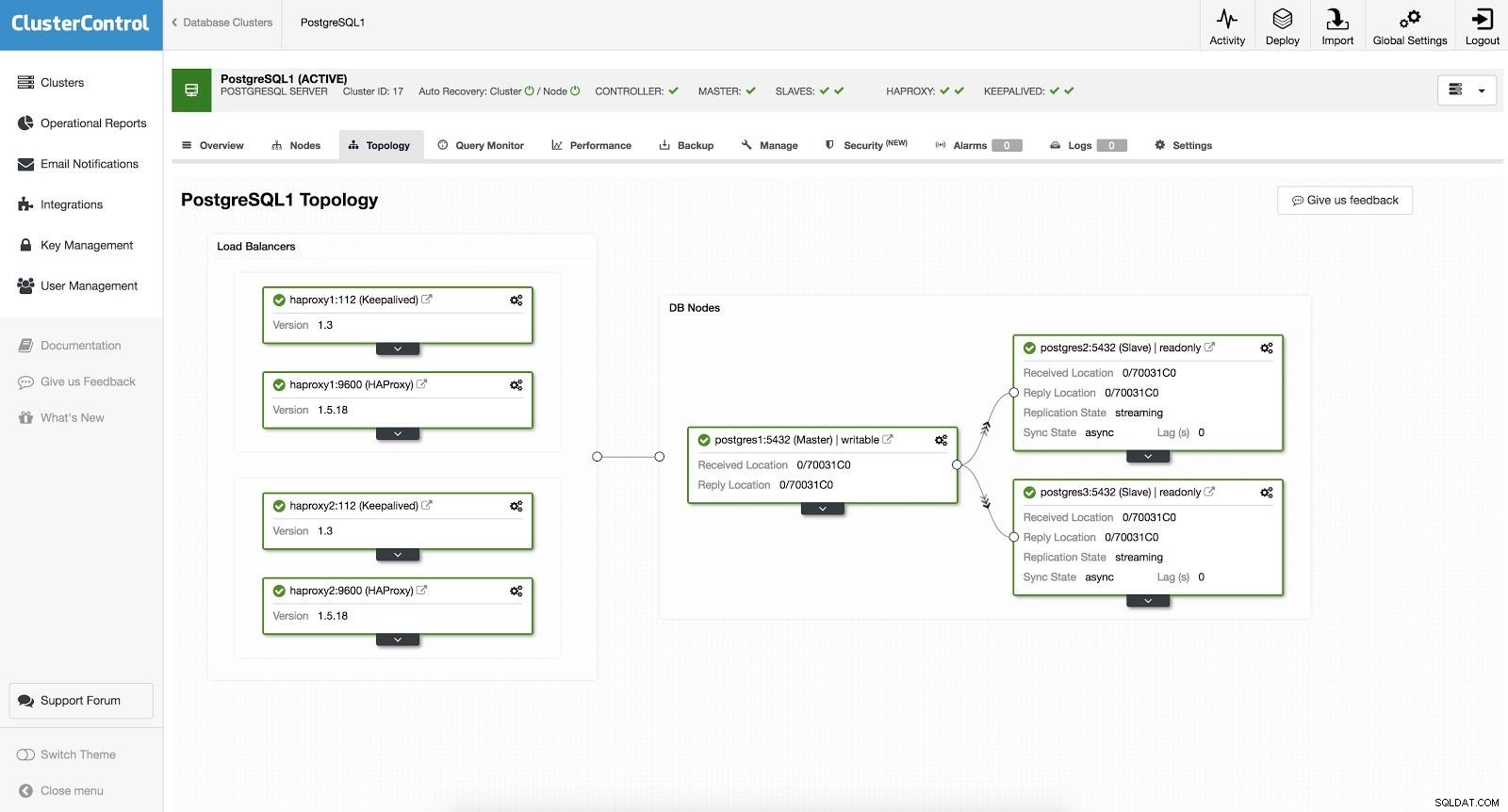 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy jest skonfigurowany z dwoma różnymi portami, jednym do odczytu-zapisu i jednym tylko do odczytu.
W naszym porcie do odczytu i zapisu nasz serwer główny jest w trybie online, a reszta naszych węzłów jest w trybie offline. W porcie tylko do odczytu mamy zarówno urządzenie nadrzędne, jak i podrzędne w trybie online. W ten sposób możemy zrównoważyć ruch odczytu między naszymi węzłami. Podczas pisania zostanie użyty port do odczytu i zapisu, który będzie wskazywał na mastera.
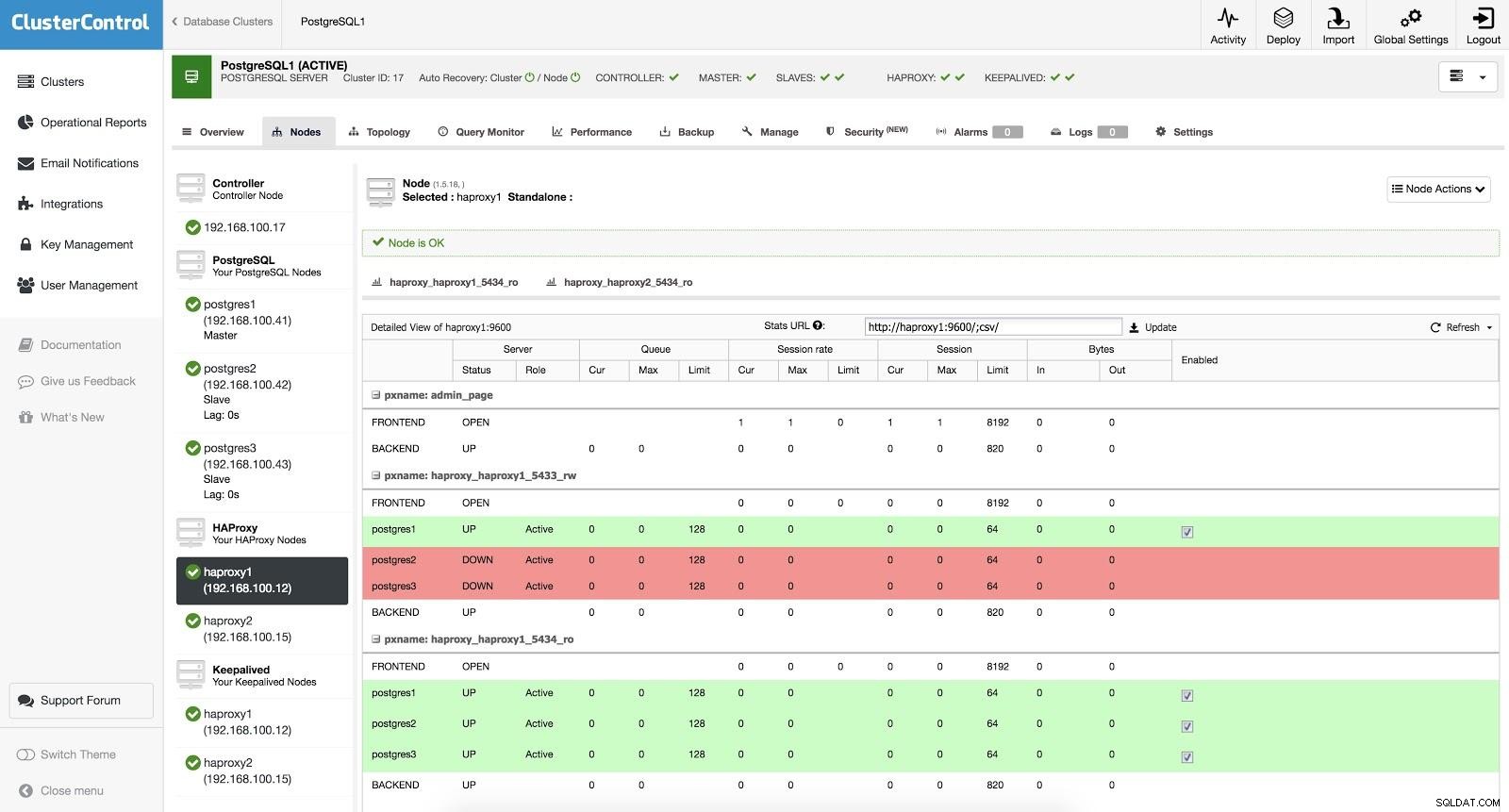 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Gdy HAProxy wykryje, że jeden z naszych węzłów, główny lub podrzędny, jest niedostępny, automatycznie oznacza go jako offline. HAProxy nie będzie do niego wysyłać żadnego ruchu. To sprawdzenie jest wykonywane przez skrypty sprawdzania kondycji, które są konfigurowane przez ClusterControl w czasie wdrażania. Sprawdzają one, czy instancje działają, czy są w trakcie odzyskiwania, czy są tylko do odczytu.
Kiedy ClusterControl promuje slave'a do mastera, nasz HAProxy oznacza stary master jako offline (dla obu portów) i umieszcza promowany węzeł w trybie online (w porcie do odczytu i zapisu). W ten sposób nasze systemy nadal działają normalnie.
Jeśli nasz aktywny HAProxy (który ma przypisany wirtualny adres IP, z którym łączą się nasze systemy) ulegnie awarii, Keepalived automatycznie migruje ten adres IP do naszego pasywnego HAProxy. Oznacza to, że nasze systemy mogą wtedy normalnie funkcjonować.
Wniosek
Jak widzieliśmy, przełączanie awaryjne jest podstawową częścią każdej produkcyjnej bazy danych. Może być przydatny podczas wykonywania typowych zadań konserwacyjnych lub migracji. Mamy nadzieję, że ten blog był przydatny jako wprowadzenie do tematu, dzięki czemu możesz kontynuować badania i tworzyć własne strategie przełączania awaryjnego.