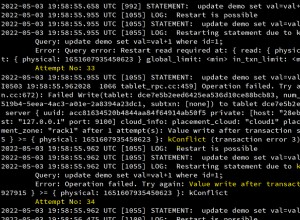
W obciążonym środowisku baz danych z większymi bazami danych często występuje potrzeba replikacji danych w czasie rzeczywistym. Aplikacje często wymagają replikacji danych produkcyjnych w czasie rzeczywistym do zdalnych lokalizacji w celu analizy i innych krytycznych potrzeb operacyjnych.
Administratorzy baz danych muszą również zapewnić ciągłą replikację danych do zdalnych lokalizacji w celu spełnienia różnych wymagań. Jednak te wymagania mogą nie zawsze polegać na zreplikowaniu całej bazy danych; może również zaistnieć potrzeba replikowania tylko podzbioru danych (takich jak tabela lub zestaw tabel lub dane z wielu tabel przy użyciu SQL do analiz, raportowania itp.)
W tym blogu skupimy się na tym, jak replikować tabele do zdalnych baz danych w czasie rzeczywistym.
Co to jest replikacja na poziomie tabeli?
Replikacja na poziomie tabeli to mechanizm replikacji danych określonej tabeli lub zestawu tabel z jednej bazy danych (źródłowej) do innej bazy danych (docelowej) hostowanej zdalnie w środowisku rozproszonym. Replikacja na poziomie tabeli zapewnia ciągłą dystrybucję danych w tabeli i zachowanie spójności w replikowanych (docelowych) witrynach.
Dlaczego warto korzystać z replikacji na poziomie tabeli?
Replikacja na poziomie tabeli jest niezbędna w większych, złożonych, wysoce rozproszonych środowiskach. Z mojego doświadczenia wynika, że zawsze istniała potrzeba zreplikowania zestawu tabel z produkcyjnej bazy danych do hurtowni danych do celów raportowania. Dane muszą być stale replikowane, aby zapewnić, że raporty zawierają najnowsze dane. W środowiskach krytycznych nie można tolerować nieaktualności danych, dlatego zmiany danych zachodzące na produkcji muszą zostać natychmiast zreplikowane do lokalizacji docelowej. Może to być prawdziwym wyzwaniem dla DBA, który musi prognozować różne czynniki, aby zapewnić wydajną i płynną replikację tabeli.
Przyjrzyjmy się niektórym wymaganiom, które rozwiązuje replikacja na poziomie tabeli:
- Raporty mogą być uruchamiane w bazie danych w środowisku innym niż produkcyjne, takim jak hurtownie danych
- Rozproszone środowisko bazy danych z rozproszonymi aplikacjami wyodrębniającymi dane z wielu lokalizacji. W przypadku rozproszonych aplikacji internetowych lub mobilnych kopia tych samych danych powinna być dostępna w wielu lokalizacjach, aby zaspokoić różne potrzeby aplikacji, dla których replikacja na poziomie tabeli może być dobrym rozwiązaniem
- Aplikacje płacowe wymagające, aby dane z różnych baz danych znajdujących się w różnych geograficznie rozproszonych centrach danych lub instancjach w chmurze były dostępne w scentralizowanej bazie danych
Różne czynniki wpływające na replikację na poziomie tabeli — na co zwrócić uwagę
Jak wspomnieliśmy powyżej, administratorzy baz danych muszą brać pod uwagę różne komponenty i czynniki czasu rzeczywistego, aby zaprojektować i wdrożyć skuteczny system replikacji na poziomie tabeli.
Struktura tabeli
Rodzaj dostosowanej tabeli danych ma duży wpływ na wydajność replikacji. Jeśli tabela mieści kolumnę BYTEA z danymi binarnymi o większym rozmiarze, wydajność replikacji może być zagrożona. Wpływ replikacji na sieć, procesor i dysk należy dokładnie ocenić.
Rozmiar danych
Jeśli migrowana tabela jest zbyt duża, początkowa migracja danych wymagałaby zasobów i czasu, administratorzy baz danych muszą upewnić się, że nie ma to wpływu na produkcyjną bazę danych.
Zasoby infrastrukturalne
Infrastruktura musi posiadać odpowiednie zasoby, aby można było zbudować niezawodny i stabilnie działający system replikacji. Jakie elementy infrastruktury należy wziąć pod uwagę?
Procesory
Replikacja danych w dużym stopniu opiera się na procesorach. Podczas replikacji z produkcji procesory nie mogą się wyczerpać, co może wpłynąć na wydajność produkcji.
Sieć
Ma to kluczowe znaczenie dla wydajności replikacji. Opóźnienie sieci między źródłowymi i docelowymi bazami danych należy ocenić za pomocą testów warunków skrajnych, aby upewnić się, że przepustowość jest wystarczająca do szybszej replikacji. Ponadto ta sama sieć może zostać wykorzystana przez inne procesy lub aplikacje. Dlatego planowanie wydajności należy wykonać tutaj.
Pamięć
Musi być dostępna wystarczająca ilość dostępnej pamięci, aby zapewnić buforowanie wystarczającej ilości danych w celu szybszej replikacji.
Aktualizacje tabeli źródłowej
Jeśli zmiany danych w tabeli źródłowej są duże, system replikacji musi mieć możliwość jak najszybszego zsynchronizowania zmian ze zdalnymi lokacjami. Replikacja zakończy się wysyłaniem dużej liczby żądań synchronizacji do docelowej bazy danych, co może wymagać dużej ilości zasobów.
Rodzaj infrastruktury (centra danych lub chmura) może również wpływać na wydajność replikacji i może stanowić wyzwanie. Wyzwaniem może być również wdrożenie monitoringu. Jeśli występuje opóźnienie i brakuje niektórych danych w docelowej bazie danych, monitorowanie może być trudne i nie może być synchroniczne
Jak zaimplementować replikację tabel
Replikacja na poziomie tabeli w PostgreSQL może być zaimplementowana przy użyciu różnych zewnętrznych narzędzi (komercyjnych lub open-source), które są dostępne na rynku, lub przy użyciu niestandardowych strumieni danych.
Przyjrzyjmy się niektórym z tych narzędzi, ich funkcjom i możliwościom...
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentSłony
Slony to jedno z najpopularniejszych narzędzi używanych do asynchronicznej replikacji poszczególnych tabel lub tabel w czasie rzeczywistym z jednej bazy danych PostgreSQL do innej. Jest to narzędzie oparte na Perlu, które wykonuje replikację opartą na wyzwalaczu zmian danych tabeli (lub zestawu tabel) z bazy danych w jednej witrynie do drugiej. Jest dość niezawodny i ma wieloletnią historię rozwoju. Choć wysoce niezawodne, będąc narzędziem opartym na wyzwalaczach, zarządzanie konfiguracjami replikacji może stać się skomplikowane.
Przyjrzyjmy się niektórym możliwościom Slony...
Zalety używania Slony
- Obsługuje metodologię replikacji typu master-slave lub wiele jednostek podrzędnych, co pomaga zwiększyć skalowalność odczytu poziomego. Innymi słowy, niewolników nie można zapisywać
- Konfiguracja wielu urządzeń podrzędnych na jednym urządzeniu głównym jest możliwa, a także obsługuje metodologię replikacji kaskadowej
- Obsługuje mechanizmy przełączania i przełączania awaryjnego
- Duża liczba tabel może być replikowana równolegle w grupach
- Możemy replikować między różnymi głównymi wersjami instancji PostgreSQL, co czyni Slony świetną opcją do aktualizacji baz danych
- Prosty w instalacji
Wady używania Slony
- Nie obsługuje replikacji DDL
- Niektóre zmiany schematu mogą przerwać replikację
- Zdarzenia replikacji są rejestrowane w bazie danych w tabelach dzienników specyficznych dla Slony, co może stanowić obciążenie dla konserwacji.
- Jeśli ma zostać zreplikowana ogromna liczba tabel z dużymi zestawami danych, wydajność i konserwacja mogą stanowić poważne wyzwania
- Ponieważ replikacja oparta na wyzwalaczu może mieć wpływ na wydajność
Bucardo
Bucardo to kolejny system replikacji oparty na perlu typu open source dla PostgreSQL, który obsługuje asynchroniczną replikację określonych danych tabeli między dwiema lub większą liczbą instancji PostgreSQL. Tym, co odróżnia Bucardo od Slony, jest to, że obsługuje również replikację z wieloma wzorcami.
Przyjrzyjmy się różnym typom mechanizmów replikacji, które bucardo pomaga zaimplementować...
- Replikacja z wieloma wzorcami:Tabele mogą być replikowane w obu kierunkach między dwiema lub większą liczbą instancji PostgreSQL, a dane transakcyjne będą synchronizowane dwukierunkowo
- Master-slave:dane z tabel w master zostaną asynchronicznie zreplikowane do slave, a slave będzie dostępne do operacji odczytu
- Pełny tryb kopiowania (Master-slave):Bucardo -/replikuj wszystkie dane z węzła master do węzła podrzędnego, usuwając wszystkie dane z węzła podrzędnego
Zalety korzystania z Bucardo
- Prosty w instalacji
- Obsługuje tryby replikacji multi-master, master-slave i pełnej kopii
- Może być używany do aktualizacji baz danych
- Replikację można wykonać między różnymi wersjami PostgreSQL
Wady korzystania z Bucardo
- Będąc replikacją opartą na wyzwalaczu, wydajność może być wyzwaniem
- Zmiany schematu, takie jak DDL, mogą przerwać replikację
- Replikowanie dużej liczby tabel może stanowić obciążenie dla konserwacji
- Zasoby infrastruktury muszą być zoptymalizowane pod kątem dobrej wydajności replikacji, w przeciwnym razie nie można osiągnąć spójności.
Replikacja logiczna PostgreSQL
Replikacja logiczna to rewolucyjna wbudowana funkcja PostgreSQL, która pomaga replikować poszczególne tabele za pośrednictwem rekordów WAL. Będąc replikacją opartą na WAL (podobną do replikacji strumieniowej), logika pg wyróżnia się w porównaniu z innymi narzędziami do replikacji tabel. Replikacja danych za pośrednictwem rekordów WAL jest zawsze najbardziej niezawodnym i wydajnym sposobem replikacji danych w sieci. Prawie wszystkie narzędzia na rynku zapewniają replikację opartą na wyzwalaczu, z wyjątkiem replikacji logicznej.
Zalety korzystania z replikacji logicznej PostgreSQL
- Najlepsza opcja, gdy chcesz zreplikować pojedynczą tabelę lub zestaw tabel
- Jest to dobra opcja, jeśli wymagana jest migracja określonych tabel z różnych baz danych do jednej bazy danych (takiej jak hurtownie danych lub bazy danych raportowania) w celach raportowania lub analizy
- Bez kłopotów z wyzwalaczami
Wady korzystania z logicznej replikacji PostgreSQL
- Niewłaściwe zarządzanie plikami WAL / plikami archiwum WAL może stanowić wyzwanie dla replikacji logicznej
- Nie możemy replikować tabel bez kluczy podstawowych lub unikalnych
- DDL i TRUNCATE nie są replikowane
- Opóźnienie replikacji może wzrosnąć, jeśli warstwy WAL zostaną usunięte. Oznacza to, że replikacja i zarządzanie WAL muszą się wzajemnie uzupełniać, aby zapewnić, że replikacja się nie zepsuje
- Dużych obiektów nie można replikować
Oto kilka dodatkowych zasobów, które pomogą Ci lepiej zrozumieć replikację logiczną PostgreSQL i różnice między nią a replikacją strumieniową.
Opakowania danych zagranicznych
Chociaż zewnętrzne opakowania danych w rzeczywistości nie replikują danych, chciałem podkreślić tę funkcję PostgreSQL, ponieważ może ona pomóc administratorom baz danych osiągnąć coś podobnego do replikacji bez faktycznej replikacji danych. Oznacza to, że dane nie są replikowane ze źródła do celu, a aplikacje mogą mieć do nich dostęp z docelowej bazy danych. Docelowa baza danych ma jedynie strukturę tabeli z łączem zawierającym szczegóły dotyczące hosta i bazy danych tabeli źródłowej, a gdy aplikacja wysyła zapytanie do tabeli docelowej, dane są przeciągane ze źródłowej bazy danych do docelowej bazy danych, podobnie jak w przypadku Łącza bazy danych. Jeśli FDW mogą pomóc, możesz całkowicie uniknąć narzutu związanego z replikacją danych w sieci. Wiele razy mamy do czynienia z sytuacją, w której raporty mogą być wykonywane na zdalnej docelowej bazie danych bez konieczności fizycznej obecności danych.
FDW są świetną opcją w następujących sytuacjach -
- Jeśli w źródłowej bazie danych znajdują się małe i statyczne tabele, nie warto replikować danych
- Może być naprawdę korzystne, jeśli masz naprawdę duże tabele w źródłowej bazie danych i uruchamiasz zapytania agregujące w docelowej bazie danych.
Zalety korzystania z zewnętrznych opakowań danych
- Można całkowicie uniknąć replikacji danych, co pozwala zaoszczędzić czas i zasoby
- Prosty do wdrożenia
- Przeciągane dane są zawsze najnowsze
- Brak kosztów utrzymania
Wady korzystania z zewnętrznych opakowań danych
- Zmiany strukturalne w tabeli źródłowej mogą wpłynąć na funkcjonalność aplikacji w docelowej bazie danych
- W dużym stopniu polega na sieci i może mieć znaczne obciążenie sieci w zależności od rodzaju uruchamianych raportów
- Oczekuje się narzutu na wydajność, gdy zapytania są wykonywane kilka razy, za każdym razem, gdy wykonywane jest zapytanie, dane muszą być pobierane przez sieć ze źródłowej bazy danych, a także mogą powodować obciążenie wydajnością źródłowej bazy danych
- Każde obciążenie źródła może wpłynąć na wydajność aplikacji w docelowej bazie danych
Wniosek
- Replikowanie tabel może służyć różnym krytycznym celom biznesowym
- Może obsługiwać rozproszone zapytania równoległe w środowiskach rozproszonych
- Implementacja synchroniczna jest prawie niemożliwa
- Infrastruktura musi być odpowiednio przystosowana, co wiąże się z kosztami
- Doskonała opcja do zbudowania zintegrowanej scentralizowanej bazy danych do celów raportowania i analizy