Ten blog rozpoczyna wiele serii dokumentujących moją podróż do testowania PostgreSQL w chmurze.
Pierwsza część zawiera przegląd narzędzi do testów porównawczych i rozpoczyna zabawę z Amazon Aurora PostgreSQL.
Wybieranie dostawców usług chmurowych PostgreSQL
Jakiś czas temu natknąłem się na procedurę benchmarka AWS dla Aurory i pomyślałem, że byłoby naprawdę fajnie, gdybym mógł wziąć ten test i uruchomić go na innych dostawcach hostingu w chmurze. Trzeba przyznać Amazonowi, że spośród trzech najbardziej znanych dostawców usług obliczeniowych — AWS, Google i Microsoft — AWS jest jedynym głównym wkładem w rozwój PostgreSQL i pierwszym, który oferuje zarządzaną usługę PostgreSQL (od listopada 2013 r.).
Chociaż zarządzane usługi PostgreSQL są również dostępne u wielu dostawców hostingu PostgreSQL, chciałem skupić się na wspomnianych trzech dostawcach przetwarzania w chmurze, ponieważ ich środowiska są miejscem, w którym wiele organizacji poszukujących zalet przetwarzania w chmurze decyduje się na uruchamianie swoich aplikacji, pod warunkiem, że mają niezbędną wiedzę na temat zarządzania PostgreSQL. Mocno wierzę, że w dzisiejszym środowisku IT organizacje pracujące z krytycznymi obciążeniami w chmurze odniosłyby znaczne korzyści z usług wyspecjalizowanego dostawcy usług PostgreSQL, który może pomóc im poruszać się po złożonym świecie GUCS i niezliczonych prezentacjach SlideShare.
Wybieranie odpowiedniego narzędzia analizy porównawczej
Benchmarking PostgreSQL dość często pojawia się na listach dyskusyjnych dotyczących wydajności, a jak podkreślano niezliczoną ilość razy, testy nie mają na celu walidacji konfiguracji dla rzeczywistej aplikacji. Jednak wybór odpowiedniego narzędzia i parametrów wzorcowych jest ważny w celu uzyskania znaczących wyników. Oczekiwałbym, że każdy dostawca usług w chmurze zapewni procedury do analizy porównawczej swoich usług, zwłaszcza gdy pierwsze doświadczenie w chmurze może nie zacząć się we właściwy sposób. Dobrą wiadomością jest to, że dwóch z trzech graczy biorących udział w tym teście uwzględniło testy w swojej dokumentacji. Przewodnik AWS Benchmark Procedure for Aurora jest łatwy do znalezienia i jest dostępny bezpośrednio na stronie Amazon Aurora Resources. Google nie zapewnia przewodnika dotyczącego PostgreSQL, jednak dokumentacja Compute Engine zawiera przewodnik testowania obciążenia dla SQL Server w oparciu o HammerDB.
Poniżej znajduje się podsumowanie narzędzi porównawczych opartych na ich referencjach, na które warto zwrócić uwagę:
- Wspomniany powyżej Benchmark AWS jest oparty na pgbench i sysbench.
- Wspomniany wcześniej HammerDB został omówiony w niedawnym poście na liście pgsql-hackerów.
- Testy TPC-C oparte na oltpbench, jak wspomniano w tej innej dyskusji z hakerami pgsql.
- benchmarksql to kolejny test TPC-C, który został użyty do sprawdzenia zmian w podziałach stron B-Tree.
- pg_ycsb to nowy dzieciak w mieście, ulepszający pgbench i już używany przez niektórych hakerów PostgreSQL.
- pgbench-tools, jak sama nazwa wskazuje, jest oparty na pgbench i chociaż nie otrzymał żadnych aktualizacji od 2016 roku, jest produktem Grega Smitha, autora książek o wysokiej wydajności PostgreSQL.
- Test porównawczy zamówień przyłączenia to test porównawczy, który przetestuje optymalizator zapytań.
- pgreplay, na który natknąłem się podczas czytania bloga Command Prompt, jest tak blisko, jak to tylko możliwe, do testowania scenariusza z prawdziwego życia.
Inną kwestią, na którą należy zwrócić uwagę, jest to, że PostgreSQL nie jest jeszcze dobrze dostosowany do standardu benchmarku TPC-H i jak wspomniano powyżej, wszystkie narzędzia (z wyjątkiem pgreplay) muszą być uruchamiane w trybie TPC-C (domyślnie jest to pgbench).
Na potrzeby tego bloga pomyślałem, że procedura porównawcza AWS dla Aurora to dobry początek, ponieważ wyznacza standardy dla dostawców chmury i opiera się na powszechnie używanych narzędziach.
Ponadto korzystałem z najnowszej dostępnej w tym czasie wersji PostgreSQL. Wybierając dostawcę chmury, należy wziąć pod uwagę częstotliwość aktualizacji, zwłaszcza gdy ważne funkcje wprowadzone przez nowe wersje mogą wpłynąć na wydajność (co ma miejsce w przypadku wersji 10 i 11 w porównaniu z 9). W chwili pisania tego tekstu mamy:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS dla PostgreSQL 10.6
- Google Cloud SQL dla PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
...a zwycięzcą jest tutaj AWS, który oferuje najnowszą wersję (chociaż nie jest to najnowsza, która w chwili pisania tego tekstu to 11.2).
Konfigurowanie środowiska porównawczego
Zdecydowałem się ograniczyć testy do średnich obciążeń z kilku powodów:Po pierwsze, dostępne zasoby w chmurze nie są identyczne u różnych dostawców. W przewodniku specyfikacje AWS dla instancji bazy danych to 64 vCPU / 488 GiB RAM / 25 Gigabit Network, podczas gdy maksymalna pamięć RAM Google dla dowolnego rozmiaru instancji (wybór musi być ustawiony na „custom” w Kalkulatorze Google) to 208 GiB, a Business Critical Gen5 firmy Microsoft z 32 vCPU ma tylko 163 GiB). Po drugie, inicjalizacja pgbench zwiększa rozmiar bazy danych do 160GiB, co w przypadku instancji z 488 GiB pamięci RAM prawdopodobnie będzie przechowywane w pamięci.
Poza tym pozostawiłem konfigurację PostgreSQL nietkniętą. Powodem trzymania się domyślnych ustawień dostawcy chmury jest to, że po wyjęciu z pudełka, w przypadku standardowego testu porównawczego, oczekuje się, że zarządzana usługa będzie działać dość dobrze. Pamiętaj, że społeczność PostgreSQL przeprowadza testy pgbench w ramach procesu zarządzania wydaniami. Dodatkowo przewodnik AWS nie wspomina o żadnych zmianach w domyślnej konfiguracji PostgreSQL.
Jak wyjaśniono w przewodniku, AWS zastosował dwie łatki do pgbench. Ponieważ łatka dla liczby klientów nie działała poprawnie w wersji 10.6 PostgreSQL i nie chciałem inwestować czasu w jej naprawę, liczba klientów została ograniczona do maksymalnie 1000.
Przewodnik określa wymaganie, aby instancja klienta miała włączoną rozszerzoną sieć — dla tego typu instancji jest to wartość domyślna:
[example@sqldat.com ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[example@sqldat.com ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Uruchamianie testu porównawczego na Amazon Aurora PostgreSQL
Podczas samego biegu postanowiłem zrobić jeszcze jedno odstępstwo od przewodnika:zamiast prowadzenia testu przez 1 godzinę, ustaw limit czasu na 10 minut, co jest ogólnie akceptowane jako dobra wartość.
Bieg nr 1
Szczegóły
- Ten test wykorzystuje specyfikacje AWS zarówno dla rozmiarów instancji klienta, jak i bazy danych.
- Maszyna kliencka:instancja EC2 zoptymalizowana pod kątem pamięci na żądanie:
- procesor wirtualny:32 (16 rdzeni x 2 wątki/rdzeń)
- RAM:244 GiB
- Pamięć:zoptymalizowana przez EBS
- Sieć:10 Gigabit
- Klaster DB:db.r4.16xlarge
- procesor wirtualny:64
- ECU (pojemność procesora):195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM:488 GiB
- Pamięć:zoptymalizowana przez EBS (dedykowana pojemność dla I/O)
- Sieć:maksymalna przepustowość 14 000 Mb/s w sieci 25 Gps
- Maszyna kliencka:instancja EC2 zoptymalizowana pod kątem pamięci na żądanie:
- Konfiguracja bazy danych obejmowała jedną replikę.
- Przechowywanie bazy danych nie było zaszyfrowane.
Wykonywanie testów i wyników
- Postępuj zgodnie z instrukcjami w przewodniku, aby zainstalować pgbench i sysbench.
- Edytuj ~/.bashrc, aby ustawić zmienne środowiskowe dla połączenia z bazą danych i wymagane ścieżki do bibliotek PostgreSQL:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Zainicjuj bazę danych:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Zweryfikuj rozmiar bazy danych:
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Użyj następującego zapytania, aby sprawdzić, czy odstęp czasu między punktami kontrolnymi jest ustawiony tak, aby punkty kontrolne były wymuszone podczas 10-minutowego przebiegu:
Wynik:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Uruchom obciążenie odczytu/zapisu:
Wyjście[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Przygotuj test sysbench:
Dane wyjściowe:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Uruchom test sysbench:
Dane wyjściowe:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Zebrane dane
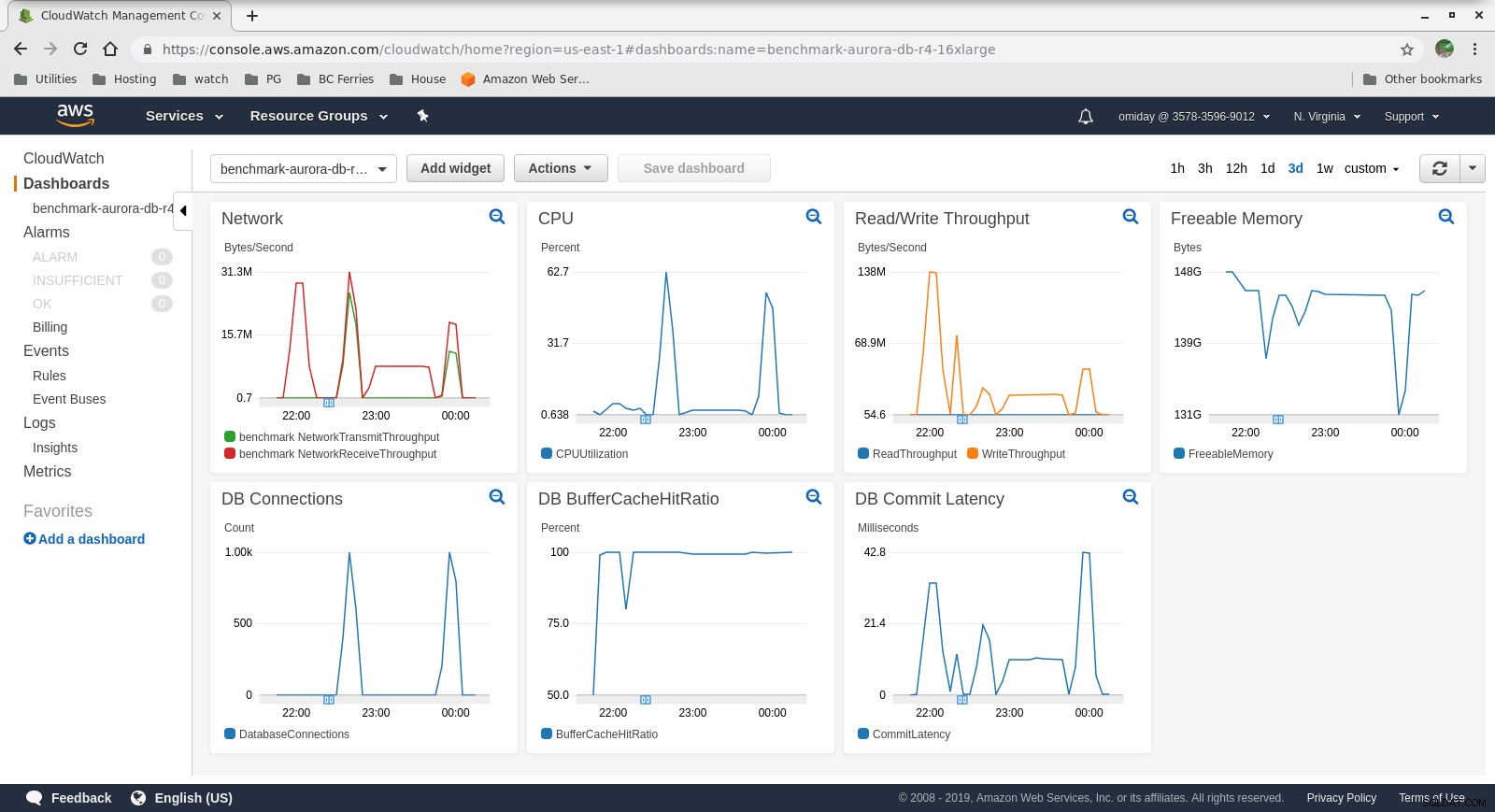 Wskaźniki Cloudwatch
Wskaźniki Cloudwatch 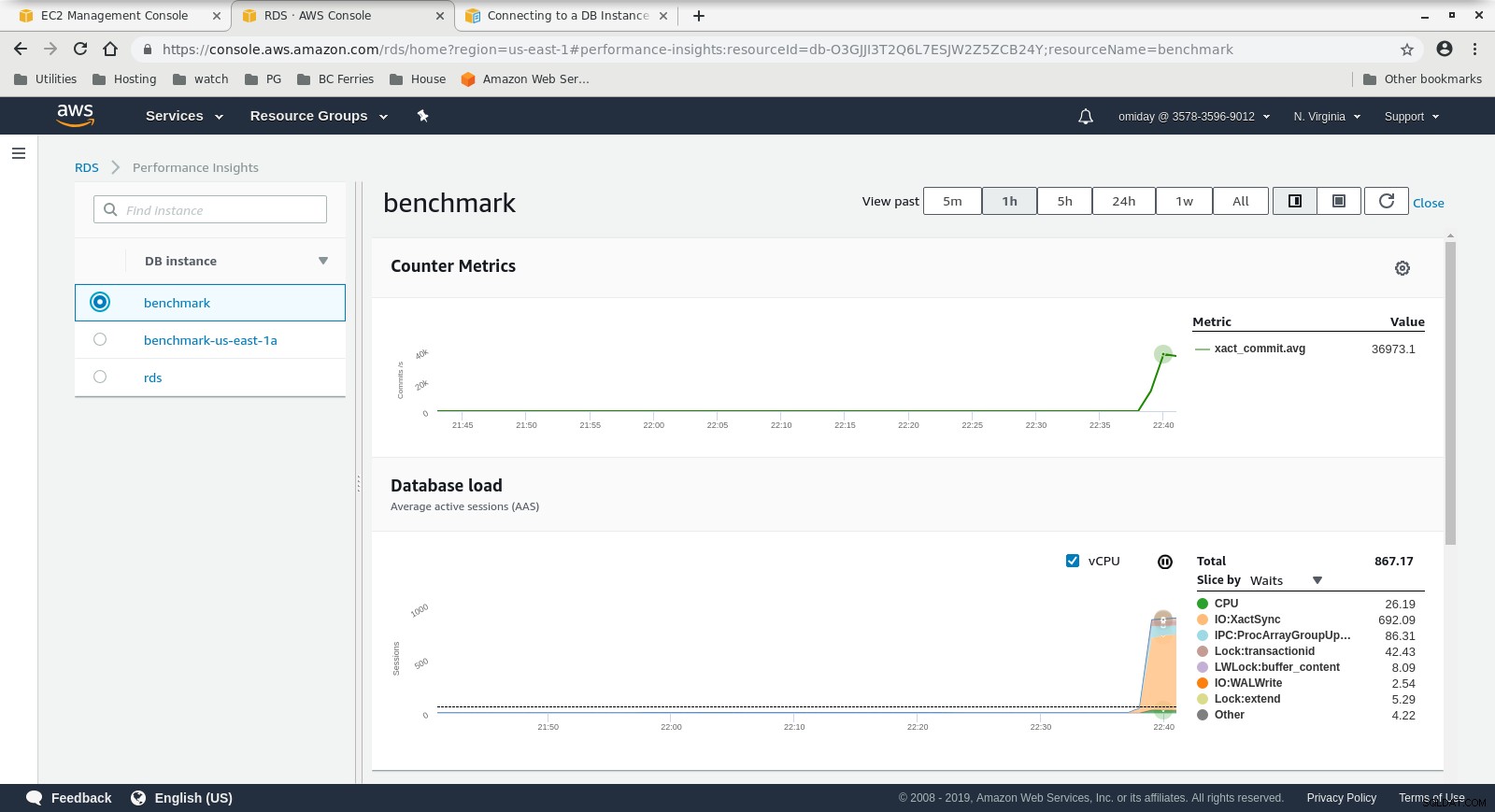 Performance Insights MetricsPobierz oficjalny dokument na dziś zarządzaj i skaluj PostgreSQLPobierz raport
Performance Insights MetricsPobierz oficjalny dokument na dziś zarządzaj i skaluj PostgreSQLPobierz raport Bieg nr 2
Szczegóły
- Ten test używa specyfikacji AWS dla klienta i mniejszego rozmiaru instancji dla bazy danych:
- Maszyna kliencka:instancja EC2 zoptymalizowana pod kątem pamięci na żądanie:
- procesor wirtualny:32 (16 rdzeni x 2 wątki/rdzeń)
- RAM:244 GiB
- Pamięć:zoptymalizowana przez EBS
- Sieć:10 Gigabit
- Klaster DB:db.r4.2xlarge:
- procesor wirtualny:8
- RAM:61GiB
- Pamięć:zoptymalizowana przez EBS
- Sieć:maksymalna przepustowość 1750 Mb/s przy połączeniu do 10 Gb/s
- Maszyna kliencka:instancja EC2 zoptymalizowana pod kątem pamięci na żądanie:
- Baza danych nie zawierała repliki.
- Przechowywanie bazy danych nie było zaszyfrowane.
Wykonywanie testów i wyników
Kroki są identyczne z przebiegiem nr 1, więc pokazuję tylko wynik:
-
Obciążenie odczytu/zapisu pgbench:
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
test sysbenchowy:
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Zebrane dane
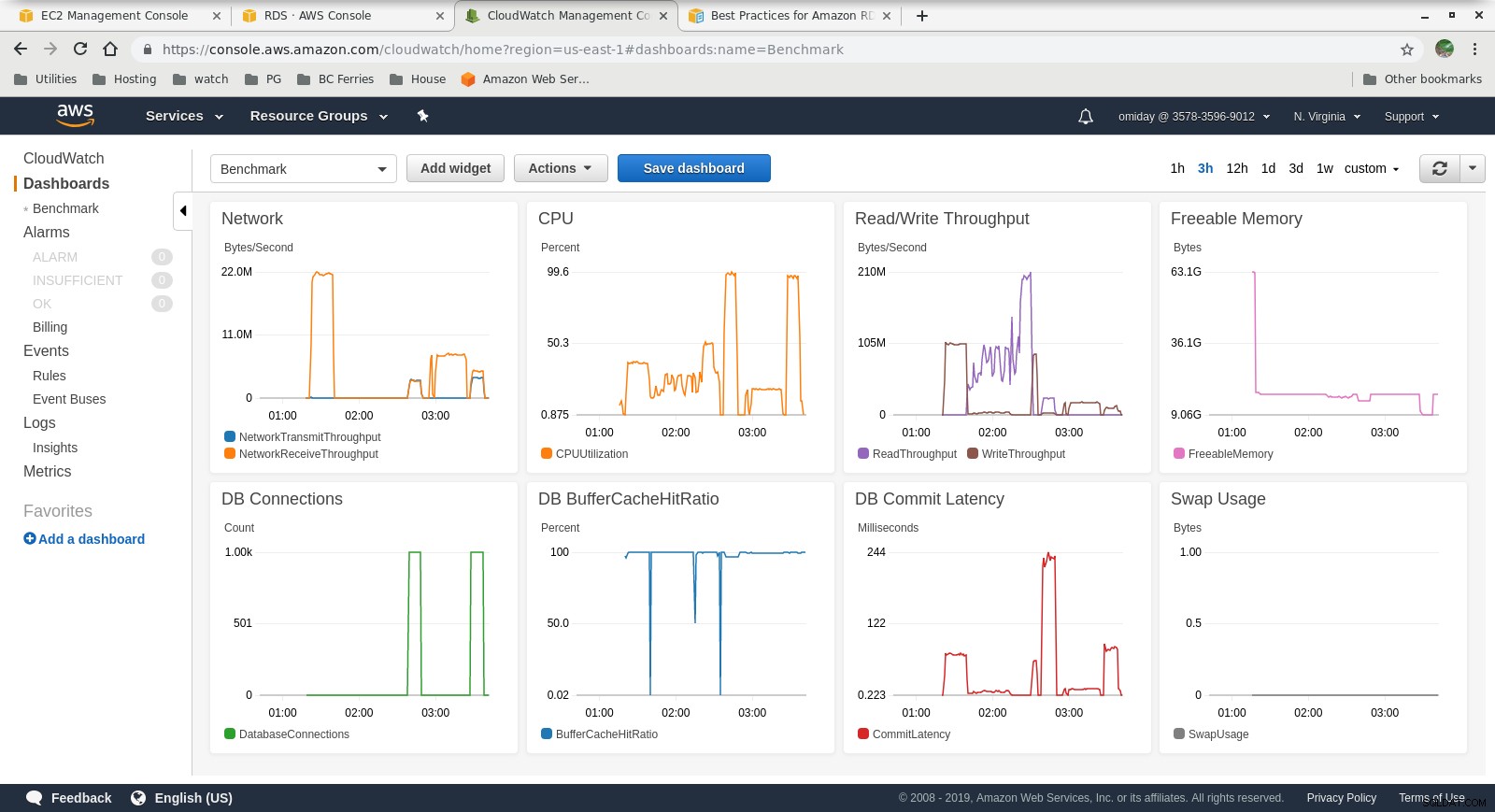 Wskaźniki Cloudwatch
Wskaźniki Cloudwatch 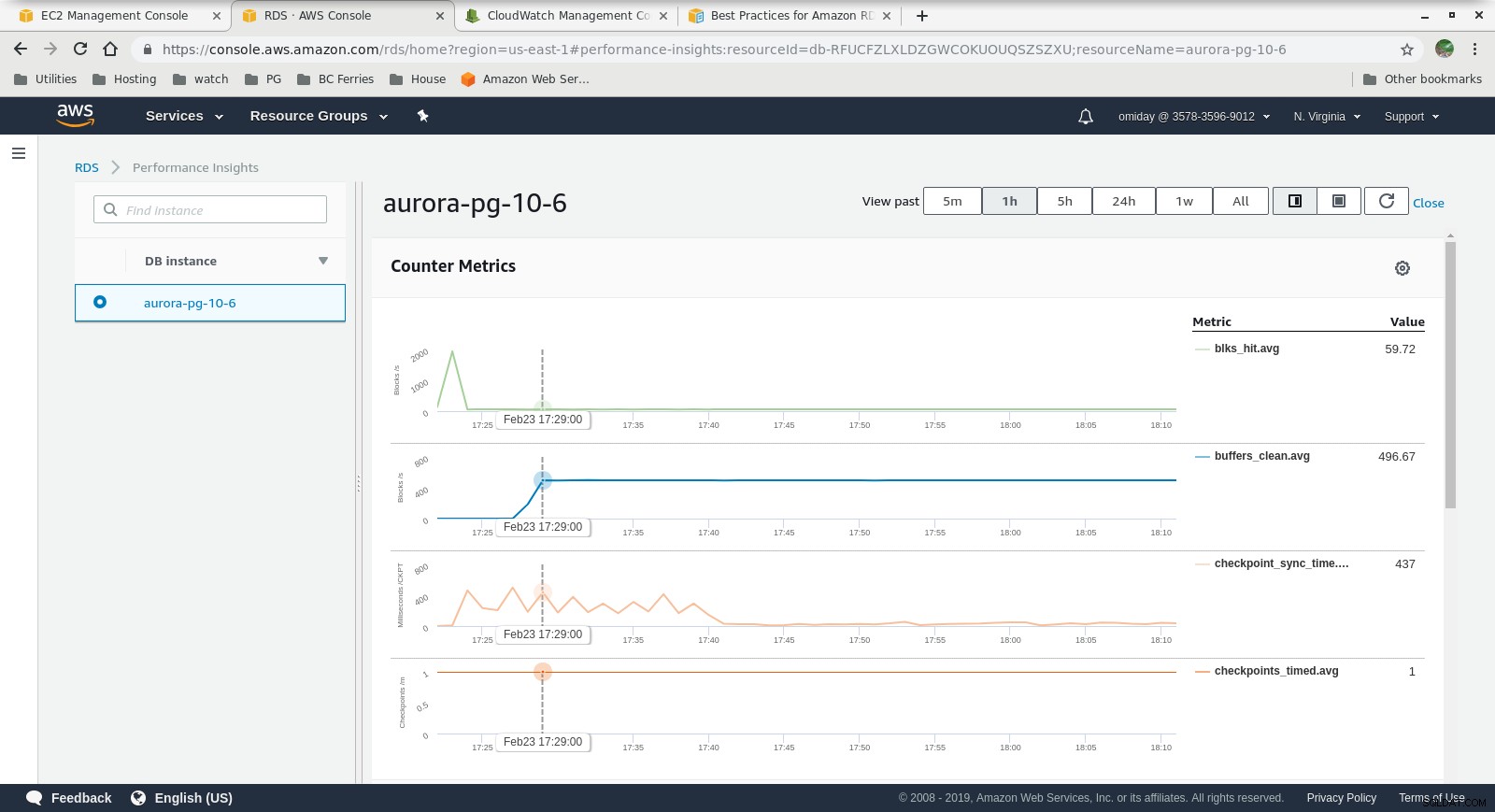 Informacje o wydajności — wskaźniki liczników
Informacje o wydajności — wskaźniki liczników 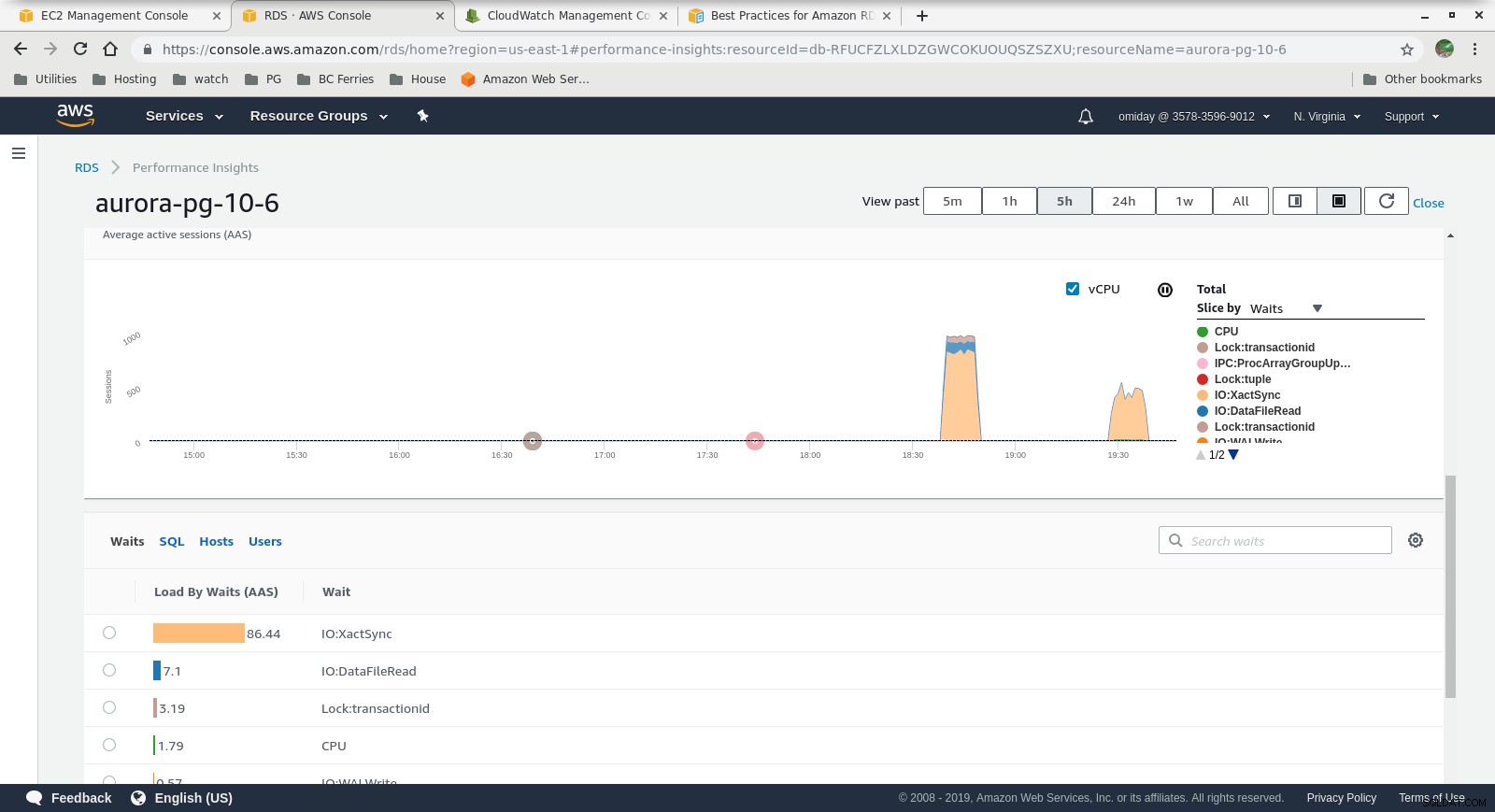 Informacje o wydajności — ładowanie bazy danych przez oczekiwania
Informacje o wydajności — ładowanie bazy danych przez oczekiwania Ostateczne myśli
- Użytkownicy mogą korzystać z predefiniowanych rozmiarów instancji. Minusem jest to, że jeśli benchmark pokazuje, że instancja może skorzystać z dodatkowej pamięci, nie można „po prostu dodać więcej pamięci RAM”. Dodanie większej ilości pamięci przekłada się na zwiększenie rozmiaru instancji, co wiąże się z wyższym kosztem (koszt podwaja się dla każdego rozmiaru instancji).
- Silnik pamięci masowej Amazon Aurora znacznie różni się od RDS i jest oparty na sprzęcie SAN. Metryki przepustowości we/wy na instancję pokazują, że test nie zbliżył się jeszcze do maksimum dla aprowizowanych woluminów IOPS SSD EBS wynoszących 1750 MiB/s.
- Dalsze dostrojenie można przeprowadzić, przeglądając zdarzenia AWS PostgreSQL zawarte na wykresach Performance Insights.
Następny w serii
Czekajcie na następną część:Amazon RDS dla PostgreSQL 10.6.