Kilka dni temu została wydana nowa wersja ClusterControl, 1.7.1, w której możemy zobaczyć kilka nowych funkcji, z których jedną z głównych jest obsługa PostgreSQL 11.
Aby ręcznie zainstalować PostgreSQL 11, musimy najpierw dodać repozytoria lub pobrać niezbędne pakiety do instalacji, zainstalować je i poprawnie skonfigurować, w zależności od naszej infrastruktury. Wszystkie te kroki wymagają czasu, więc zobaczmy, jak możemy tego uniknąć.
W tym blogu zobaczymy, jak za pomocą kilku kliknięć za pomocą ClusterControl wdrożyć tę nową wersję PostgreSQL i jak nią zarządzać. Jako warunek wstępny zainstaluj wersję 1.7.1 ClusterControl na dedykowanym hoście lub maszynie wirtualnej.
Wdróż PostgreSQL 11
Aby wykonać nową instalację z ClusterControl, po prostu wybierz opcję „Wdróż” i postępuj zgodnie z wyświetlanymi instrukcjami. Pamiętaj, że jeśli masz już uruchomioną instancję PostgreSQL 11, musisz zamiast tego wybrać opcję „Importuj istniejący serwer/bazę danych”.
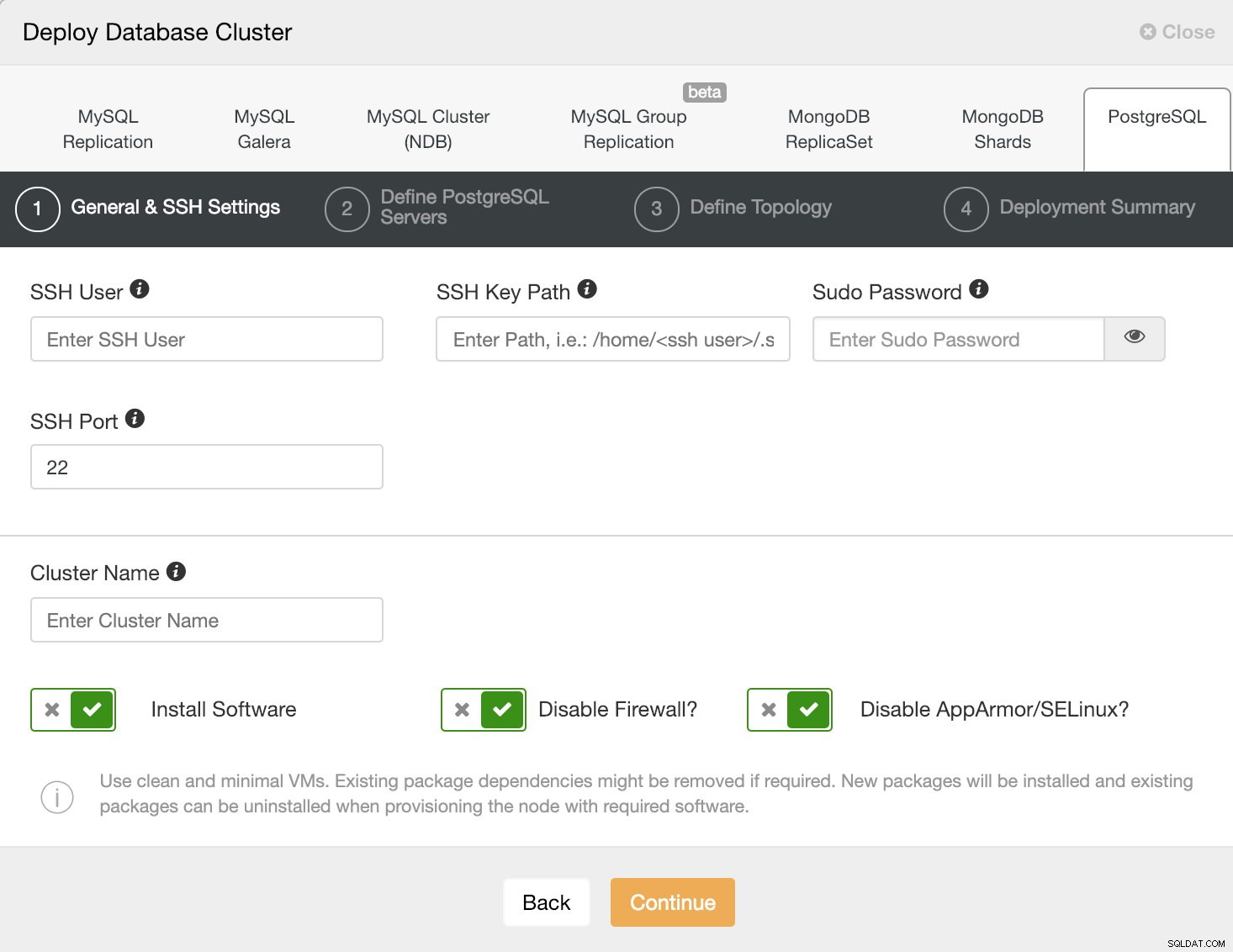
 Opcja wdrożenia ClusterControl
Opcja wdrożenia ClusterControl Wybierając PostgreSQL, musimy określić Użytkownika, Klucz lub Hasło i port, aby połączyć się przez SSH z naszymi hostami PostgreSQL. Potrzebujemy również nazwy dla naszego nowego klastra i jeśli chcemy, aby ClusterControl zainstalował dla nas odpowiednie oprogramowanie i konfiguracje.
 Informacje o wdrożeniu ClusterControl 1
Informacje o wdrożeniu ClusterControl 1 Sprawdź wymagania użytkownika ClusterControl dla tego zadania tutaj.
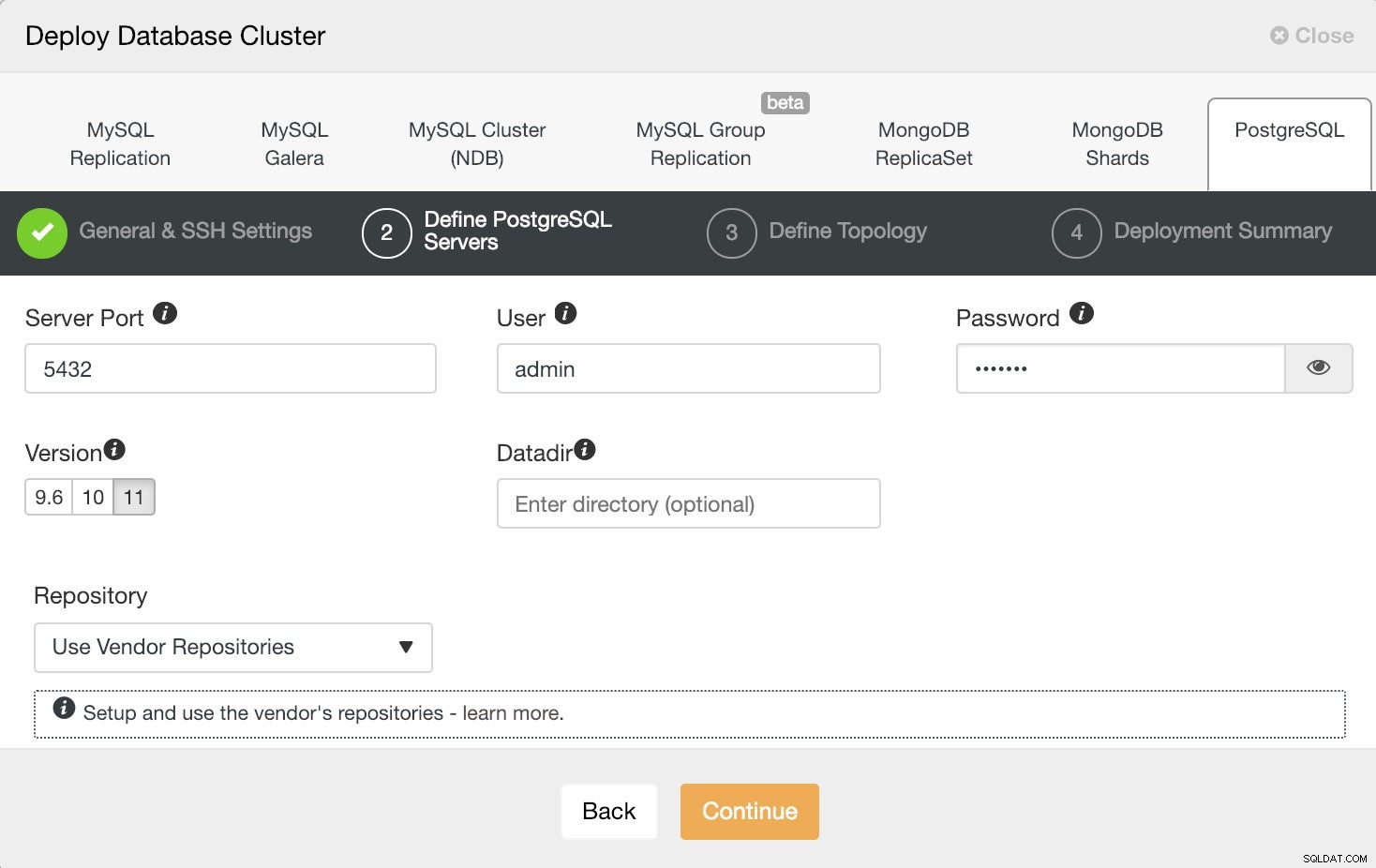 Informacje o wdrożeniu ClusterControl 2
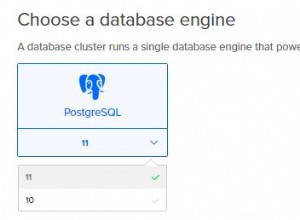
Informacje o wdrożeniu ClusterControl 2 Po skonfigurowaniu informacji dostępowych SSH musimy zdefiniować użytkownika bazy danych, wersję i datadir (opcjonalnie). Możemy również określić, którego repozytorium użyć. W tym przypadku chcemy wdrożyć PostgreSQL 11, więc po prostu wybierz go i kontynuuj.
W następnym kroku musimy dodać nasze serwery do klastra, który zamierzamy utworzyć.
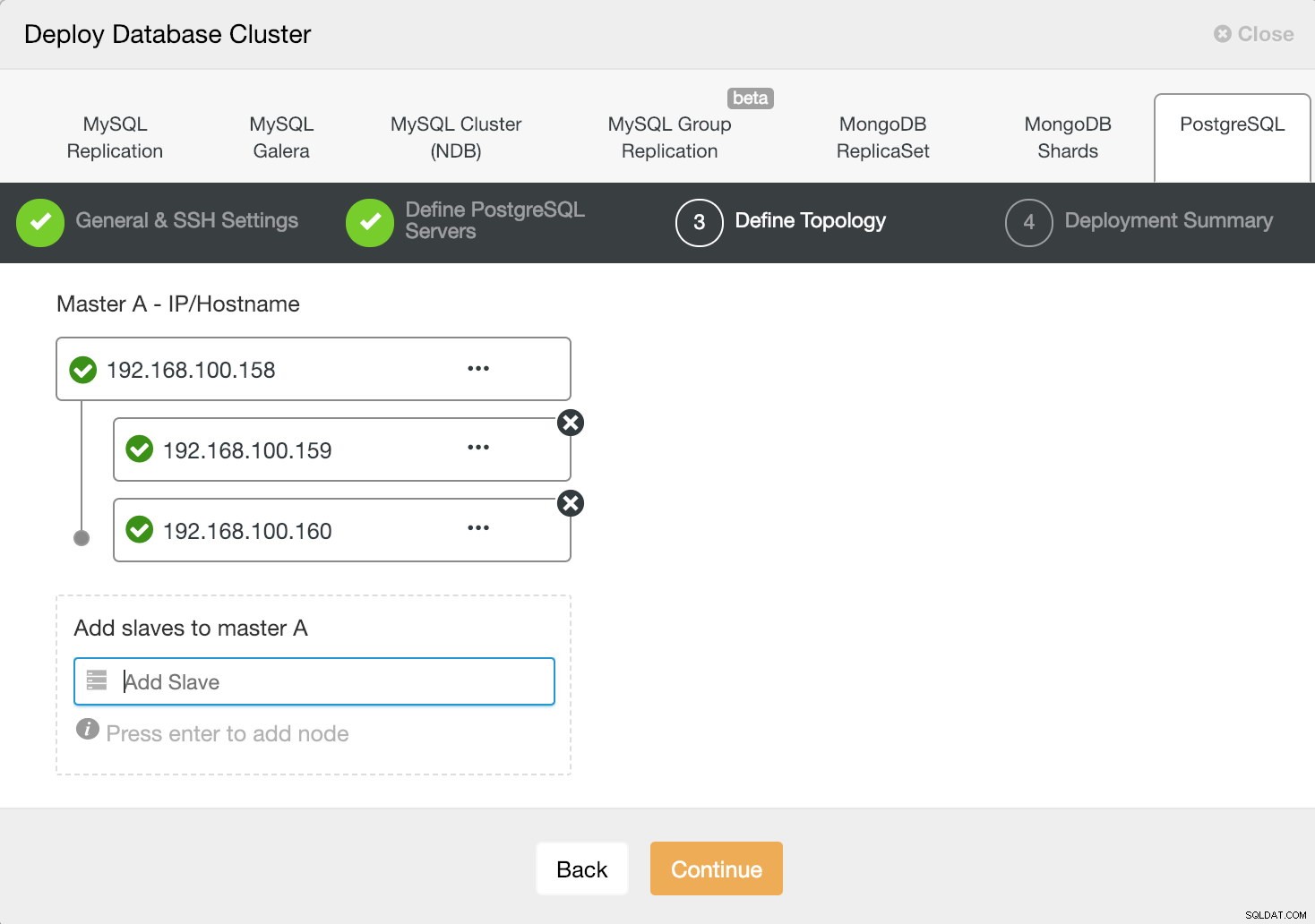 Informacje o wdrożeniu ClusterControl 3
Informacje o wdrożeniu ClusterControl 3 Podczas dodawania naszych serwerów możemy wprowadzić adres IP lub nazwę hosta.
W ostatnim kroku możemy wybrać, czy nasza replikacja będzie synchroniczna czy asynchroniczna.
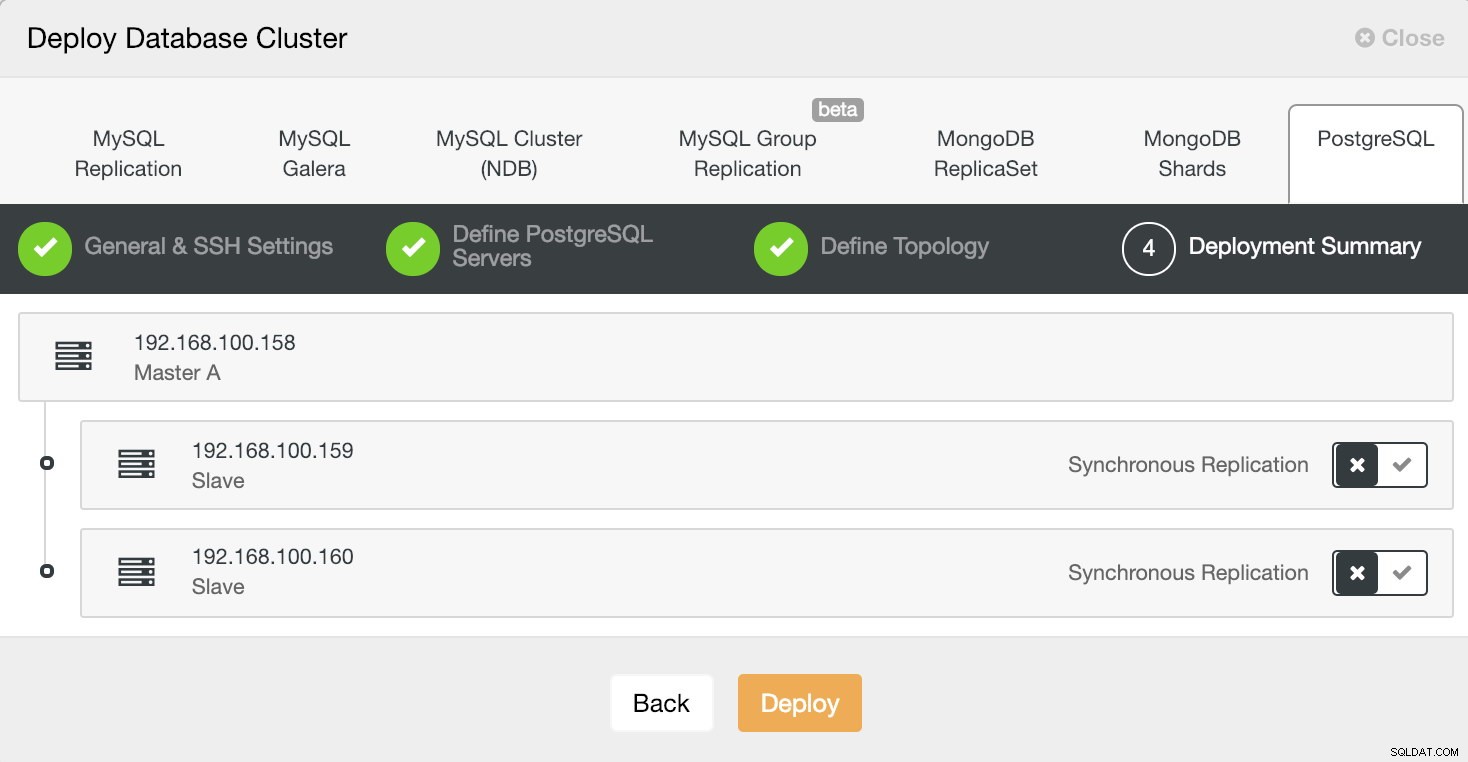 Informacje o wdrożeniu ClusterControl 4
Informacje o wdrożeniu ClusterControl 4 Możemy monitorować stan tworzenia naszego nowego klastra z monitora aktywności ClusterControl.
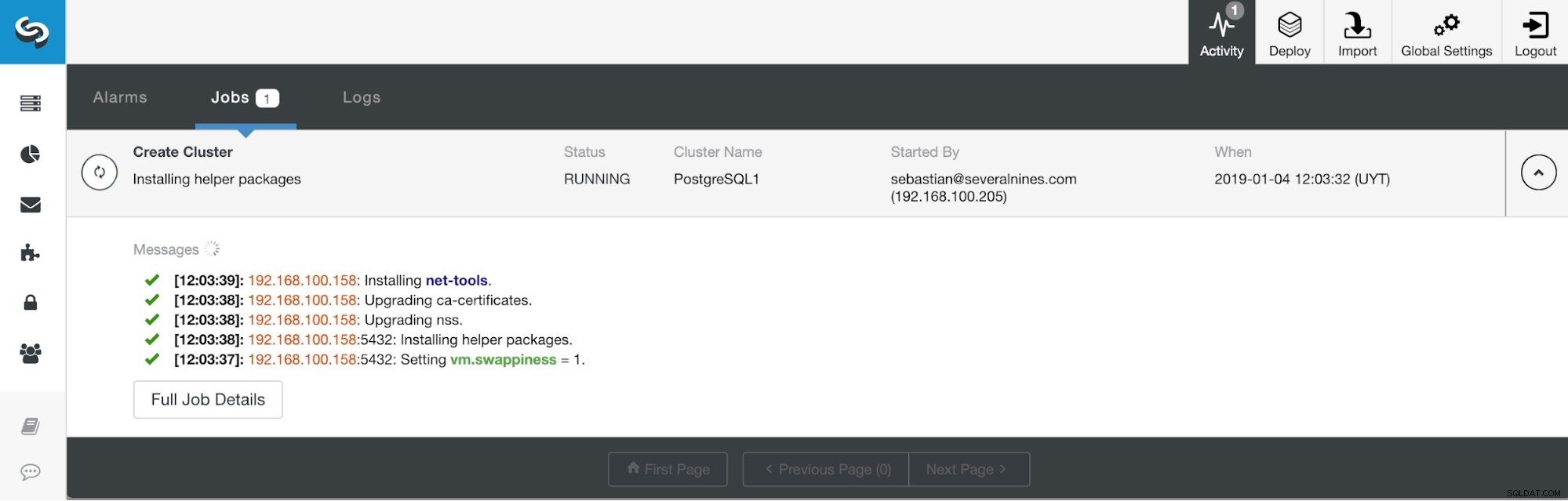 Sekcja aktywności ClusterControl
Sekcja aktywności ClusterControl Po zakończeniu zadania możemy zobaczyć nasz nowy klaster PostgreSQL 11 na głównym ekranie ClusterControl.
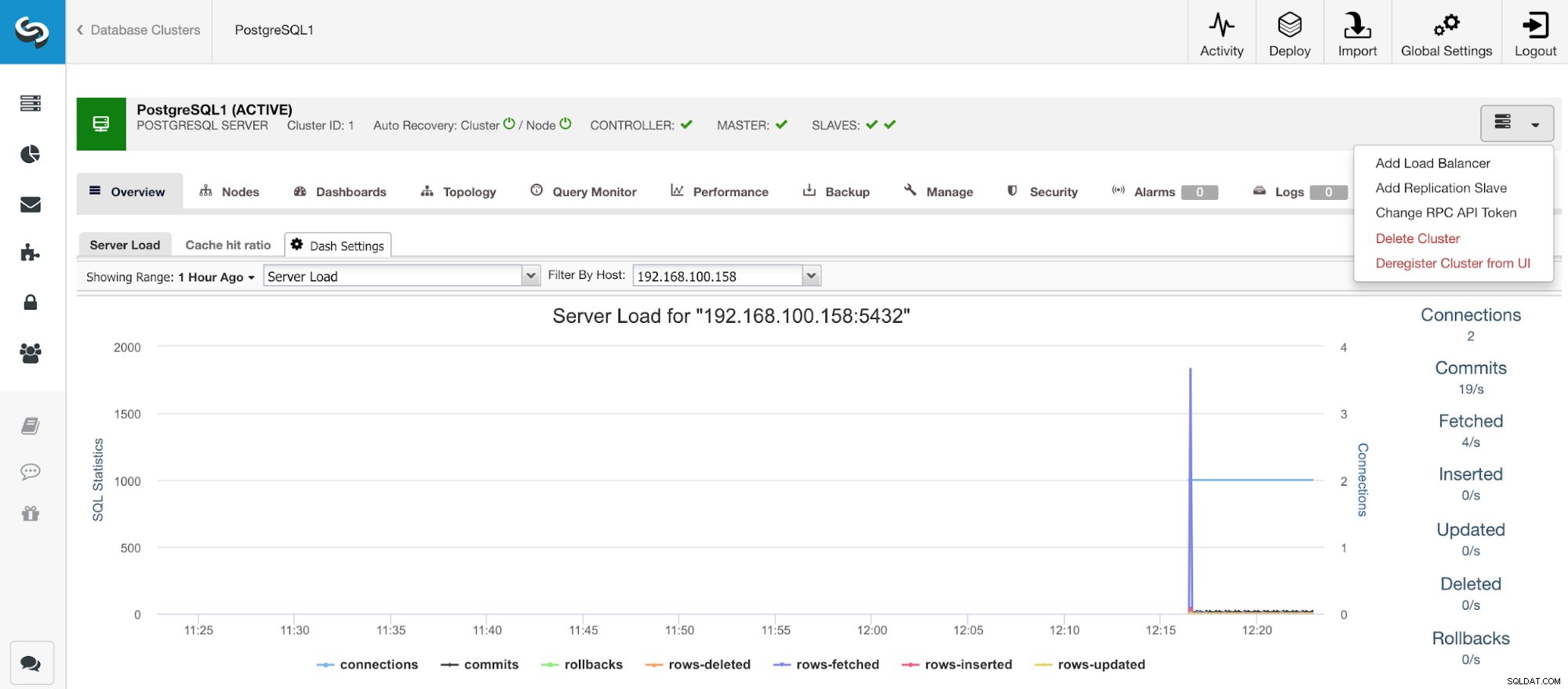
 Ekran główny ClusterControl
Ekran główny ClusterControl Po utworzeniu naszego klastra możemy wykonać na nim kilka zadań, takich jak dodanie modułu równoważenia obciążenia (HAProxy) lub nowej repliki.
 ClusterControl Cluster Section
ClusterControl Cluster Section Skalowanie PostgreSQL 11
Jeśli przejdziemy do działań klastrowych i wybierzemy „Dodaj niewolnik replikacji”, możemy albo utworzyć nową replikę od zera, albo dodać istniejącą bazę danych PostgreSQL jako replikę.
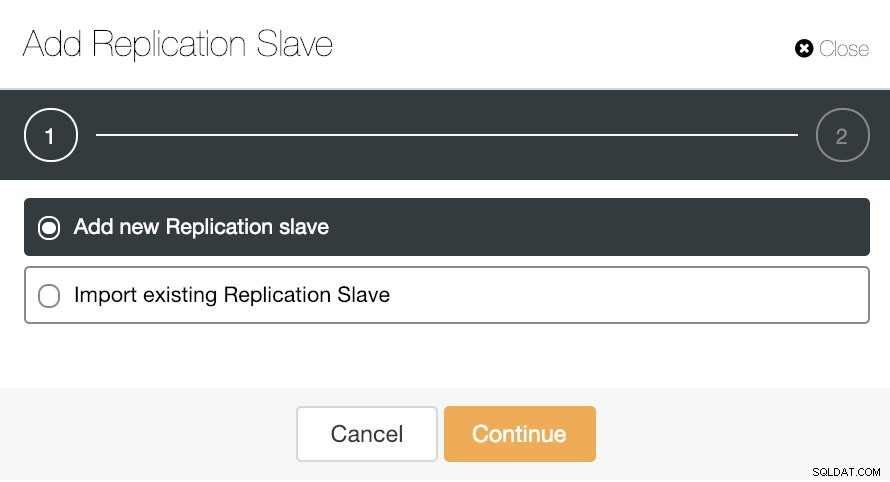 ClusterControl Dodaj opcję podrzędną replikacji
ClusterControl Dodaj opcję podrzędną replikacji Zobaczmy, jak dodanie nowego urządzenia podrzędnego replikacji może być naprawdę łatwym zadaniem.
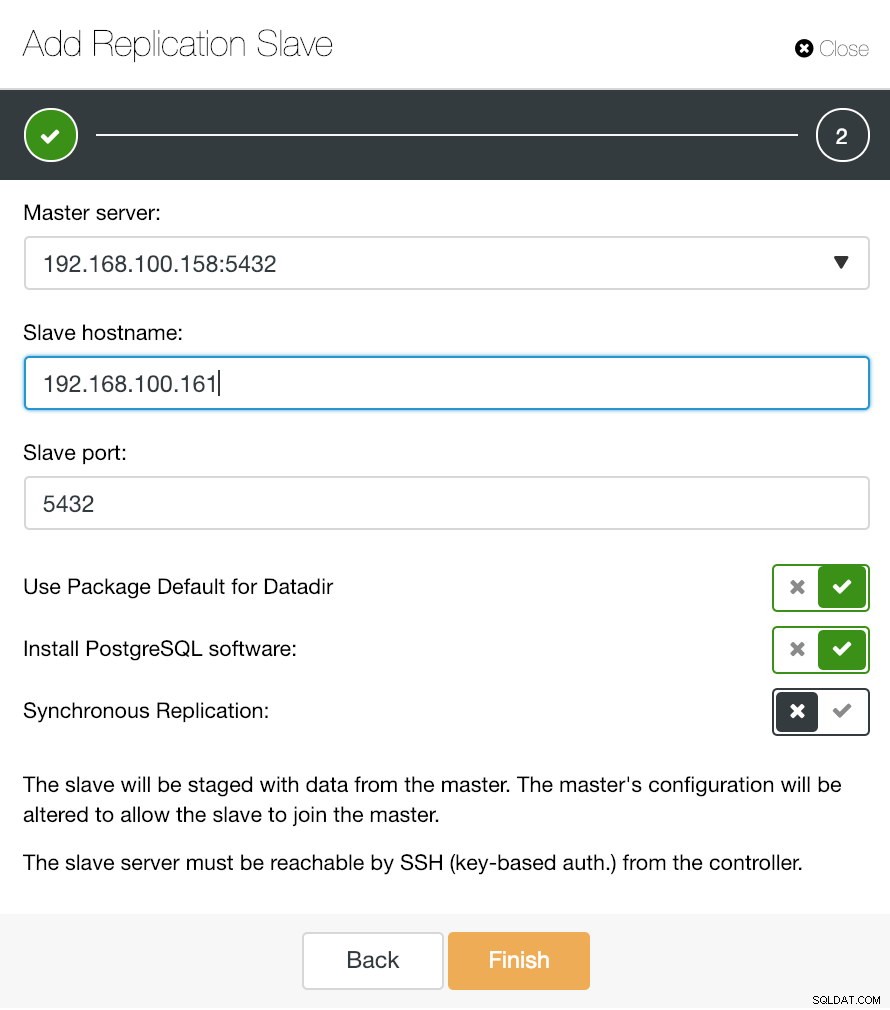 ClusterControl Dodaj informacje o jednostce podrzędnej replikacji
ClusterControl Dodaj informacje o jednostce podrzędnej replikacji Jak widać na obrazku, wystarczy wybrać nasz serwer główny, wprowadzić adres IP naszego nowego serwera podrzędnego i port bazy danych. Następnie możemy wybrać, czy chcemy, aby ClusterControl zainstalował oprogramowanie za nas i czy urządzenie podrzędne replikacji powinno być synchroniczne czy asynchroniczne.
W ten sposób możemy dodać dowolną liczbę replik i rozłożyć między nimi ruch odczytu za pomocą load balancera, który możemy również zaimplementować za pomocą ClusterControl.
Więcej informacji o HA dla PostgreSQL można znaleźć na powiązanym blogu.
Z ClusterControl możesz również jednym kliknięciem wykonywać różne zadania zarządzania, takie jak Reboot Host, Rebuild Replication Slave lub Prome Slave.
 Akcje węzła ClusterControl
Akcje węzła ClusterControl Kopie zapasowe
W poprzednich blogach przyjrzeliśmy się funkcjom tworzenia kopii zapasowych i PITR ClusterControl dla PostgreSQL. Teraz, w ostatniej wersji ClusterControl, mamy funkcje „weryfikuj/przywracaj kopię zapasową na samodzielnym hoście” i „utwórz klaster z istniejącej kopii zapasowej”.
W ClusterControl wybierz swój klaster i przejdź do sekcji „Kopia zapasowa”, aby wyświetlić bieżące kopie zapasowe.
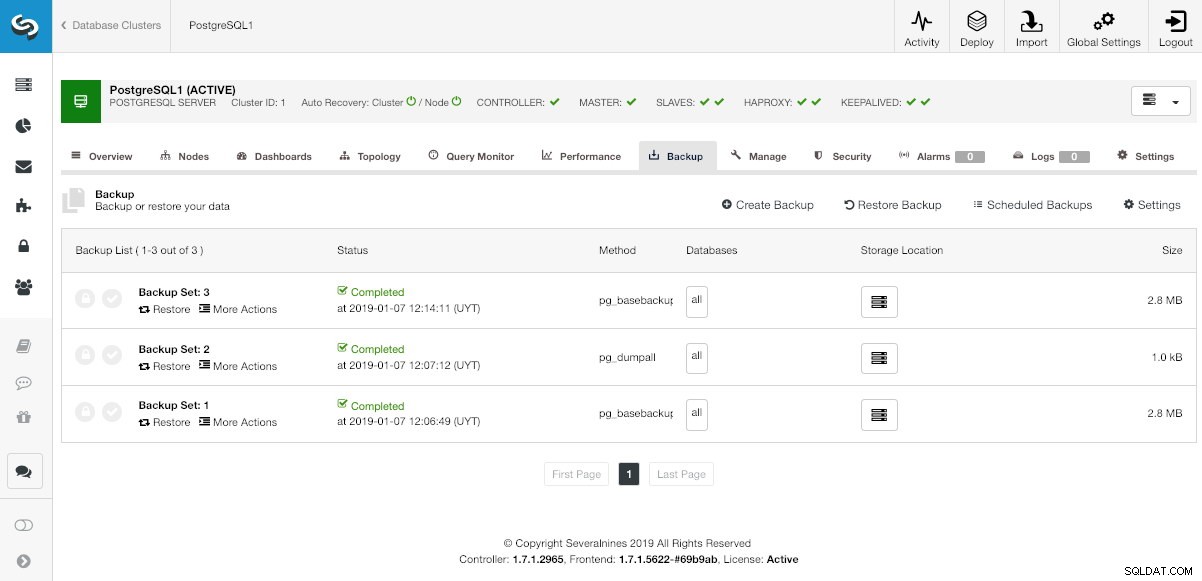 Sekcja kopii zapasowych ClusterControl
Sekcja kopii zapasowych ClusterControl W opcji „Przywróć” najpierw możesz wybrać, która kopia zapasowa zostanie przywrócona.
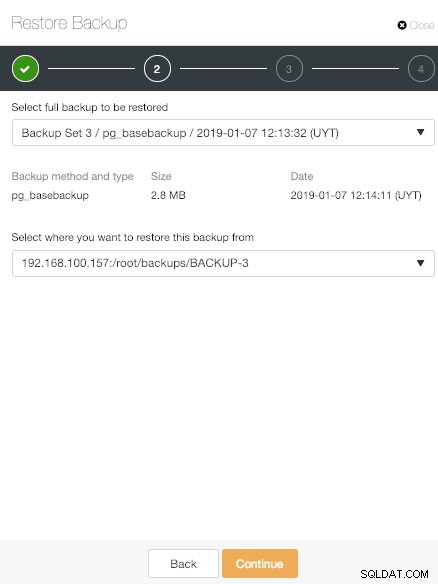 Opcja kopii zapasowej przywracania ClusterControl
Opcja kopii zapasowej przywracania ClusterControl Mamy trzy opcje.
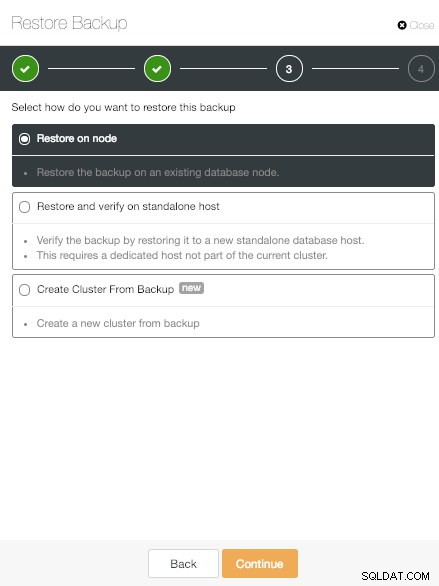 ClusterControl Przywracanie w węźle Opcja
ClusterControl Przywracanie w węźle Opcja Pierwsza z nich to klasyczna opcja „Przywróć na węźle”. To po prostu przywraca wybraną kopię zapasową w określonym węźle.
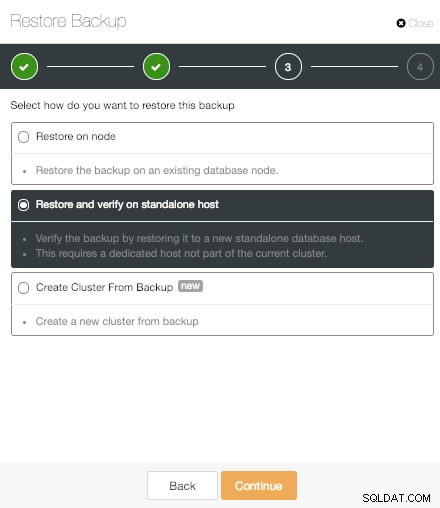 ClusterControl Opcja przywracania i weryfikacji na samodzielnym hoście
ClusterControl Opcja przywracania i weryfikacji na samodzielnym hoście Opcja „Przywróć i weryfikuj na samodzielnym hoście” to nowa funkcja ClusterControl PostgreSQL. Dzięki temu możemy przetestować wygenerowaną kopię zapasową, przywracając ją na samodzielnym hoście. Jest to naprawdę przydatne, aby uniknąć niespodzianek w scenariuszu odzyskiwania po awarii.
Aby korzystać z tej funkcji, potrzebujemy dedykowanego hosta (lub maszyny wirtualnej), który nie jest częścią klastra.
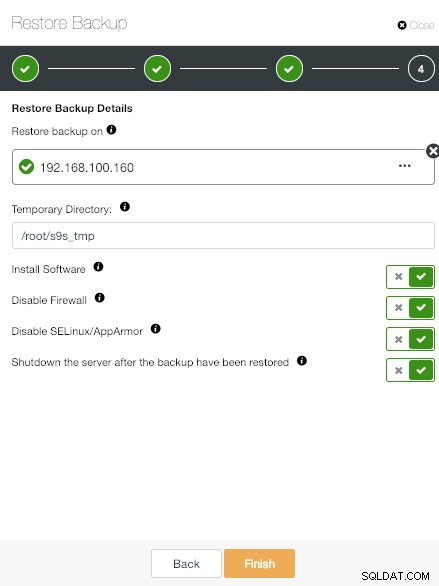 ClusterControl Przywracanie i weryfikacja informacji o autonomicznym hoście
ClusterControl Przywracanie i weryfikacja informacji o autonomicznym hoście Dodaj dedykowany adres IP hosta i wybierz żądane opcje.
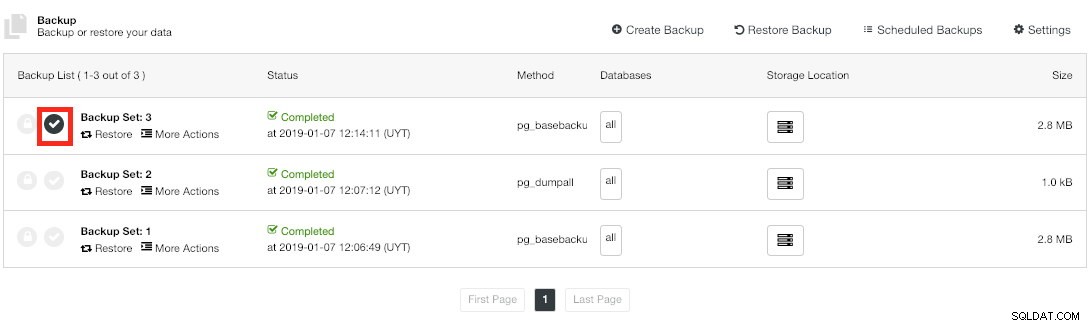 Zweryfikowana kopia zapasowa ClusterControl
Zweryfikowana kopia zapasowa ClusterControl Gdy kopia zapasowa zostanie zweryfikowana, na liście kopii zapasowych zobaczysz ikonę „Zweryfikowano”.
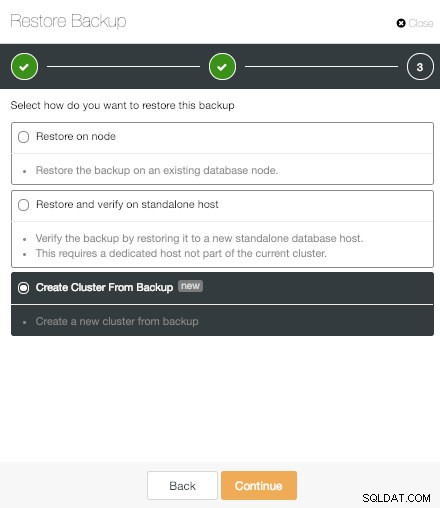 ClusterControl Utwórz klaster z kopii zapasowej
ClusterControl Utwórz klaster z kopii zapasowej „Utwórz klaster z kopii zapasowej” to kolejna ważna nowa funkcja ClusterControl PostgreSQL.
Jak sama nazwa wskazuje, ta funkcja pozwala nam stworzyć nowy klaster PostgreSQL z danymi z wygenerowanej kopii zapasowej.
Po wybraniu tej opcji musimy wykonać te same kroki, które widzieliśmy w sekcji wdrażania.
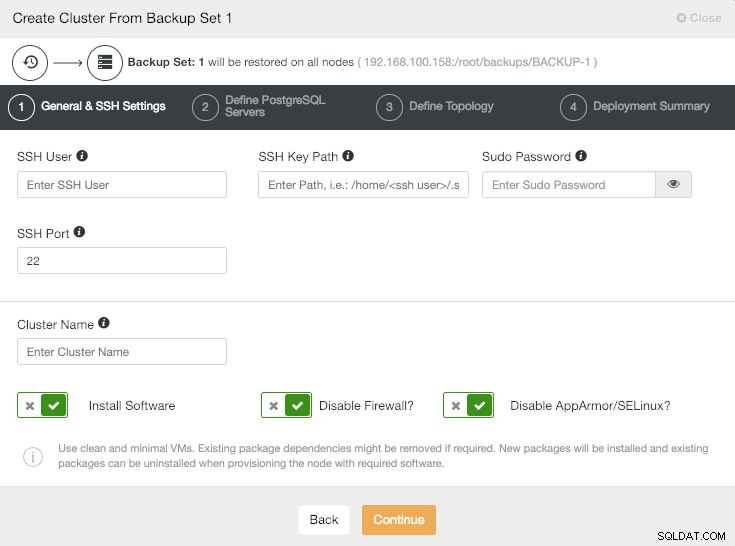 ClusterControl Utwórz klaster na podstawie informacji o kopii zapasowej
ClusterControl Utwórz klaster na podstawie informacji o kopii zapasowej
Cała konfiguracja, taka jak użytkownik, liczba węzłów lub typ replikacji, może być inna w tym nowym klastrze.
Po utworzeniu nowego klastra można zobaczyć zarówno stary, jak i nowy na głównym ekranie ClusterControl.
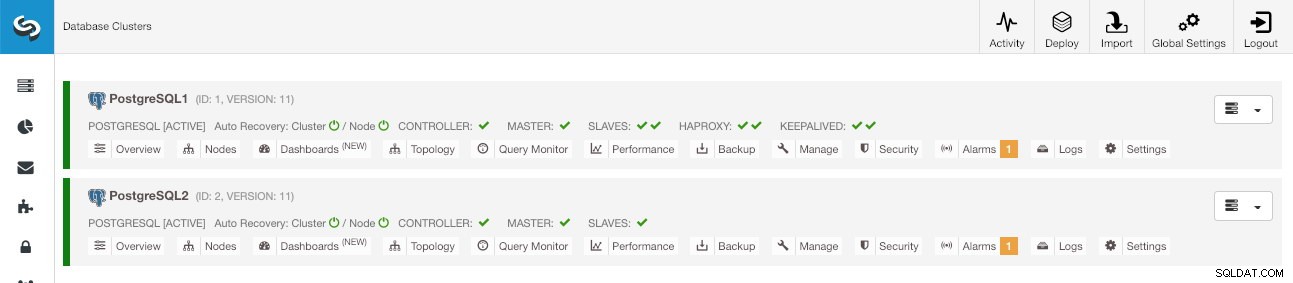 Ekran główny ClusterControl
Ekran główny ClusterControl Wniosek
Jak widzieliśmy powyżej, możesz teraz wdrożyć najnowszą wersję PostgreSQL, wersję 11, używając ClusterControl. Po wdrożeniu ClusterControl zapewnia całą gamę funkcji, od monitorowania, alarmowania, automatycznego przełączania awaryjnego, tworzenia kopii zapasowych, przywracania do określonego punktu w czasie, weryfikacji kopii zapasowych, po skalowanie replik do odczytu. Pomoże Ci to w przyjazny i intuicyjny sposób zarządzać Postgresem. Spróbuj!