Nie ma idealnego systemu, sprzętu lub topologii, aby uniknąć wszystkich możliwych problemów, które mogą wystąpić w środowisku produkcyjnym. Pokonanie tych wyzwań wymaga skutecznego planu DRP (Disaster Recovery Plan), skonfigurowanego zgodnie z wymaganiami aplikacji, infrastruktury i firmy. Kluczem do sukcesu w tego typu sytuacjach jest zawsze to, jak szybko możemy naprawić lub usunąć problem.
W tym blogu przyjrzymy się najczęstszym scenariuszom niepowodzeń PostgreSQL i pokażemy, jak można je rozwiązać lub poradzić sobie z nimi. Przyjrzymy się również, w jaki sposób ClusterControl może pomóc nam wrócić do trybu online
Wspólna topologia PostgreSQL
Aby zrozumieć typowe scenariusze awarii, musisz najpierw zacząć od wspólnej topologii PostgreSQL. Może to być dowolna aplikacja podłączona do głównego węzła PostgreSQL, do którego podłączona jest replika.
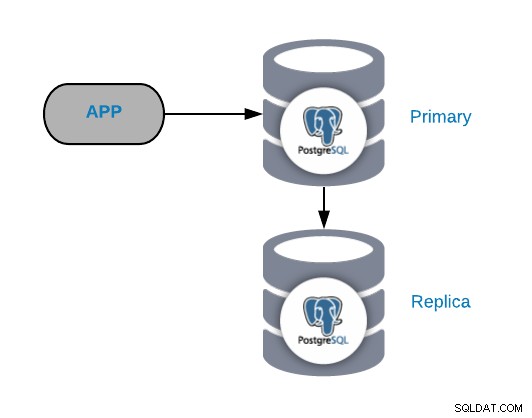
Zawsze możesz ulepszyć lub rozszerzyć tę topologię, dodając więcej węzłów lub systemów równoważenia obciążenia , ale jest to podstawowa topologia, z którą zaczniemy pracować.
Awaria głównego węzła PostgreSQL
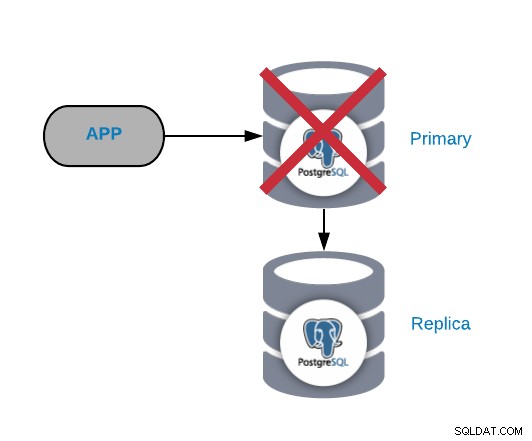
Jest to jeden z najbardziej krytycznych błędów, ponieważ powinniśmy go naprawić jak najszybciej, jeśli chcemy, aby nasze systemy były online. W przypadku tego typu awarii ważne jest, aby mieć jakiś mechanizm automatycznego przełączania awaryjnego. Po awarii możesz przyjrzeć się przyczynie problemów. Po procesie przełączania awaryjnego upewniamy się, że uszkodzony węzeł główny nie myśli, że jest węzłem podstawowym. Ma to na celu uniknięcie niespójności danych podczas zapisywania do nich.
Najczęstsze przyczyny tego rodzaju problemów to awaria systemu operacyjnego, awaria sprzętu lub awaria dysku. W każdym razie powinniśmy sprawdzić bazę danych i logi systemu operacyjnego, aby znaleźć przyczynę.
Najszybszym rozwiązaniem tego problemu jest wykonanie zadania przełączania awaryjnego w celu skrócenia czasu przestoju. Aby promować replikę, możemy użyć polecenia pg_ctl promotion na podrzędnym węźle bazy danych, a następnie musimy wysłać ruch z węzła aplikacji do nowego węzła podstawowego. Do tego ostatniego zadania możemy zaimplementować load balancer pomiędzy naszą aplikacją a węzłami bazy danych, aby uniknąć jakichkolwiek zmian ze strony aplikacji w przypadku awarii. Możemy również skonfigurować system równoważenia obciążenia, aby wykrywał awarię węzła i zamiast wysyłać do niego ruch, wyślij go do nowego węzła podstawowego.
Po procesie przełączania awaryjnego i upewnieniu się, że system działa ponownie, możemy przyjrzeć się problemowi i zalecamy, aby zawsze działał co najmniej jeden węzeł podrzędny, więc w przypadku nowej awarii podstawowej, możemy ponownie wykonać zadanie przełączania awaryjnego.
Awaria węzła repliki PostgreSQL
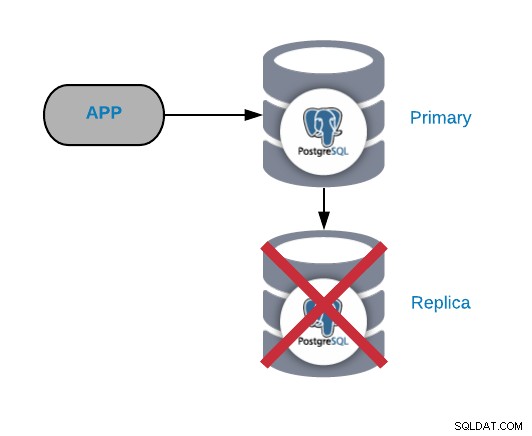
To zwykle nie jest krytyczny problem (o ile masz więcej niż jedną replikę i nie używają jej do wysyłania ruchu odczytu produkcyjnego). Jeśli masz problemy z węzłem podstawowym i nie masz zaktualizowanej repliki, będziesz mieć naprawdę krytyczny problem. Jeśli używasz naszej repliki do celów raportowania lub dużych zbiorów danych, prawdopodobnie i tak zechcesz to szybko naprawić.
Najczęstsze przyczyny tego rodzaju problemów są takie same, jak w przypadku węzła podstawowego, awarii systemu operacyjnego, awarii sprzętu lub awarii dysku. Należy sprawdzić bazę danych i dzienniki systemu operacyjnego znaleźć przyczynę.
Nie zaleca się utrzymywania systemu działającego bez żadnej repliki, ponieważ w przypadku awarii nie masz szybkiego sposobu na powrót do sieci. Jeśli masz tylko jednego niewolnika, powinieneś rozwiązać problem JAK NAJSZYBCIEJ; najszybszym sposobem jest stworzenie nowej repliki od podstaw. W tym celu musisz wykonać spójną kopię zapasową i przywrócić ją do węzła podrzędnego, a następnie skonfigurować replikację między tym węzłem podrzędnym a węzłem podstawowym.
Jeśli chcesz poznać przyczynę niepowodzenia, powinieneś użyć innego serwera do utworzenia nowej repliki, a następnie zajrzeć do starej, aby ją odkryć. Po zakończeniu tego zadania możesz również ponownie skonfigurować starą replikę i kontynuować pracę jako przyszłą opcję przełączania awaryjnego.
Jeśli używasz repliki do raportowania lub do celów big data, musisz zmienić adres IP, aby połączyć się z nowym. Podobnie jak w poprzednim przypadku, jednym ze sposobów uniknięcia tej zmiany jest użycie systemu równoważenia obciążenia, który będzie znał stan każdego serwera, umożliwiając dodawanie/usuwanie replik według własnego uznania.
Niepowodzenie replikacji PostgreSQL
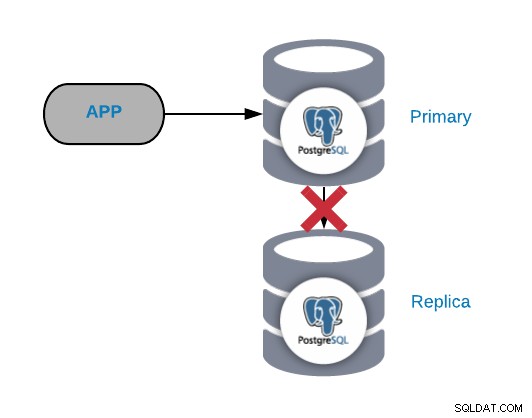
Na ogół ten rodzaj problemu jest generowany z powodu sieci lub konfiguracji wydanie. Jest to związane z utratą WAL (rejestrowanie z wyprzedzeniem) w węźle podstawowym i sposobem, w jaki PostgreSQL zarządza replikacją.
Jeśli masz duży ruch, robisz punkty kontrolne zbyt często lub przechowujesz WLS tylko przez kilka minut; jeśli masz problem z siecią, będziesz miał mało czasu na jego rozwiązanie. Twoje pliki WAL zostaną usunięte, zanim będziesz mógł je wysłać i zastosować do repliki.
Jeżeli plik WAL, którego replika potrzebuje do kontynuowania pracy, został usunięty, musisz go odbudować, więc aby uniknąć tego zadania, powinniśmy sprawdzić konfigurację naszej bazy danych, aby zwiększyć segmenty wal_keep_segments (ilości WAL do przechowywania w pg_xlog) lub parametrami max_wal_senders (maksymalna liczba jednocześnie działających procesów WAL sender).
Inną zalecaną opcją jest włączenie trybu archive_mode i wysłanie plików WAL na inną ścieżkę z parametrem archive_command. W ten sposób, jeśli PostgreSQL osiągnie limit i usunie plik WAL, i tak będziemy mieli go w innej ścieżce.
Uszkodzenie danych PostgreSQL / Niespójność danych / Przypadkowe usunięcie

To koszmar dla każdego administratora i prawdopodobnie najbardziej złożony problem naprawiono, w zależności od zasięgu problemu.
Gdy niektóre z tych problemów dotyczą Twoich danych, najczęstszym sposobem rozwiązania tego problemu (i prawdopodobnie jedynym) jest przywrócenie kopii zapasowej. Dlatego kopie zapasowe są podstawową formą każdego planu odzyskiwania po awarii i zaleca się przechowywanie co najmniej trzech kopii zapasowych w różnych miejscach fizycznych. Zgodnie z najlepszymi praktykami, pliki kopii zapasowych powinny być przechowywane lokalnie na serwerze bazy danych (dla szybszego odzyskiwania), drugie na scentralizowanym serwerze kopii zapasowych, a ostatnie w chmurze.
Możemy również utworzyć kombinację pełnych/przyrostowych/różnicowych kopii zapasowych zgodnych z PITR, aby zmniejszyć nasz cel dotyczący punktu odzyskiwania.
Zarządzanie awarią PostgreSQL za pomocą ClusterControl
Teraz, gdy przyjrzeliśmy się tym typowym scenariuszom awarii PostgreSQL, przyjrzyjmy się, co by się stało, gdybyśmy zarządzali bazami danych PostgreSQL ze scentralizowanego systemu zarządzania bazami danych. Taki, który jest świetny pod względem szybkiego i łatwego rozwiązania problemu, JAK NAJSZYBCIEJ, w przypadku awarii.
ClusterControl zapewnia automatyzację większości opisanych powyżej zadań PostgreSQL; wszystko w sposób scentralizowany i przyjazny dla użytkownika. Dzięki temu systemowi będziesz mógł łatwo konfigurować rzeczy, które ręcznie wymagałyby czasu i wysiłku. Omówimy teraz niektóre z jego głównych funkcji związanych ze scenariuszami awarii PostgreSQL.
Wdrażanie/importowanie klastra PostgreSQL
Gdy wejdziemy do interfejsu ClusterControl, pierwszą rzeczą do zrobienia jest wdrożenie nowego klastra lub zaimportowanie istniejącego. Aby przeprowadzić wdrożenie, po prostu wybierz opcję Wdróż klaster bazy danych i postępuj zgodnie z wyświetlanymi instrukcjami.
Skalowanie klastra PostgreSQL
Jeśli przejdziesz do Akcje klastra i wybierzesz opcję Dodaj podrzędną replikację, możesz albo utworzyć nową replikę od podstaw, albo dodać istniejącą bazę danych PostgreSQL jako replikę. W ten sposób możesz uruchomić swoją nową replikę w ciągu kilku minut, a my możemy dodać tyle replik, ile chcemy; rozdzielanie ruchu odczytu między nimi za pomocą load balancera (który możemy również zaimplementować za pomocą ClusterControl).
Automatyczne przełączanie awaryjne PostgreSQL
ClusterControl zarządza przełączaniem awaryjnym w konfiguracji replikacji. Wykrywa awarie urządzenia nadrzędnego i promuje urządzenie podrzędne za pomocą najbardziej aktualnych danych jako nowego urządzenia nadrzędnego. Automatycznie przełącza również pozostałe urządzenia podrzędne w celu replikacji z nowego urządzenia nadrzędnego. Jeśli chodzi o połączenia klientów, wykorzystuje do tego dwa narzędzia:HAProxy i Keepalived.
HAProxy to moduł równoważenia obciążenia, który rozdziela ruch z jednego źródła do jednego lub więcej miejsc docelowych i może zdefiniować określone reguły i/lub protokoły dla zadania. Jeśli którykolwiek z miejsc docelowych przestanie odpowiadać, zostaje oznaczony jako offline, a ruch jest kierowany do jednego z dostępnych miejsc docelowych. Zapobiega to wysyłaniu ruchu do niedostępnego miejsca docelowego i utracie tych informacji poprzez kierowanie go do prawidłowego miejsca docelowego.
Keepalived umożliwia skonfigurowanie wirtualnego adresu IP w ramach aktywnej/pasywnej grupy serwerów. Ten wirtualny adres IP jest przypisany do aktywnego „Głównego” serwera. Jeśli ten serwer ulegnie awarii, adres IP zostanie automatycznie przeniesiony na serwer „dodatkowy”, który okazał się pasywny, co pozwala mu kontynuować pracę z tym samym adresem IP w przejrzysty sposób dla naszych systemów.
Dodawanie systemu równoważenia obciążenia PostgreSQL
Jeśli przejdziesz do Akcje klastra i wybierzesz Dodaj Load Balancer (lub z widoku klastra - przejdź do Zarządzaj -> Load Balancer), możesz dodać load balancer do naszej topologii bazy danych.
Konfiguracja potrzebna do utworzenia nowego systemu równoważenia obciążenia jest dość prosta. Wystarczy dodać adres IP/nazwę hosta, port, politykę i węzły, których będziemy używać. Możesz dodać dwa load balancery z Keepalived pomiędzy nimi, co pozwala nam na automatyczne przełączanie awaryjne naszego load balancera w przypadku awarii. Keepalived używa wirtualnego adresu IP i migruje go z jednego systemu równoważenia obciążenia do drugiego w przypadku awarii, dzięki czemu nasza konfiguracja może nadal działać normalnie.
Kopie zapasowe PostgreSQL
Omówiliśmy już znaczenie tworzenia kopii zapasowych. ClusterControl zapewnia funkcję generowania natychmiastowej kopii zapasowej lub jej zaplanowania.
Do wyboru są trzy różne metody tworzenia kopii zapasowych:pgdump, pg_basebackup lub pgBackRest. Możesz także określić, gdzie przechowywać kopie zapasowe (na serwerze bazy danych, na serwerze ClusterControl lub w chmurze), poziom kompresji, wymagane szyfrowanie i okres przechowywania.
Monitorowanie i alarmowanie PostgreSQL
Zanim będziesz mógł podjąć działanie, musisz wiedzieć, co się dzieje, więc musisz monitorować klaster bazy danych. ClusterControl umożliwia monitorowanie naszych serwerów w czasie rzeczywistym. Dostępne są wykresy z podstawowymi danymi, takimi jak CPU, Sieć, Dysk, RAM, IOPS, a także metrykami specyficznymi dla bazy danych zebranymi z instancji PostgreSQL. Zapytania do bazy danych można również przeglądać w Monitorze zapytań.
W ten sam sposób, w jaki włączasz monitorowanie z ClusterControl, możesz również skonfigurować alerty, które informują o zdarzeniach w Twoim klastrze. Te alerty można konfigurować i spersonalizować w razie potrzeby.
Wnioski
Każdy w końcu będzie musiał poradzić sobie z problemami i awariami PostgreSQL. A ponieważ nie możesz uniknąć problemu, musisz być w stanie naprawić go JAK NAJSZYBCIEJ i utrzymać działanie systemu. Zobaczyliśmy również, jak użycie ClusterControl może pomóc w rozwiązaniu tych problemów; wszystko z jednej i przyjaznej dla użytkownika platformy.
Oto niektóre z najczęstszych scenariuszy niepowodzeń PostgreSQL. Chcielibyśmy usłyszeć o Twoich własnych doświadczeniach i sposobie ich naprawy.