Jeżeli ostatnio śledziłeś Microsoft, nie będzie zaskoczeniem, że dostawca konkurencyjnego produktu bazodanowego, a mianowicie SQL Server, również wskoczył na modę PostgreSQL. Od wydania 60 000 patentów dla OIN po bycie platynowym sponsorem na PGCon, Microsoft jako jedna z korporacyjnych organizacji wspierających PostgreSQL. Wykorzystałem każdą okazję, by pokazać, że nie tylko możesz uruchomić PostgreSQL w Microsoft, ale jest też odwrotnie:Microsoft, dzięki swojej ofercie chmury, może uruchomić PostgreSQL dla Ciebie. Stwierdzenie stało się jeszcze jaśniejsze wraz z przejęciem Citus Data i wypuszczeniem ich flagowego produktu w chmurze Azure pod nazwą Hyperscale. Można śmiało powiedzieć, że popularność PostgreSQL rośnie, a teraz jest jeszcze więcej dobrych powodów, aby go wybrać.
Moja podróż przez chmurę Azure zaczęła się od strony docelowej, na której spotykam rywali:Pojedynczy serwer i wersję zapoznawczą (innymi słowy bez umowy SLA) wersji Hyperscale (Citus). Ten blog skupi się na tym pierwszym. Podczas tej podróży miałem okazję przećwiczyć, na czym polega open source — oddając społeczności — w tym przypadku, przekazując informacje zwrotne do dokumentacji, która, ku chciwości Microsoftu, bardzo to ułatwia, przesyłając je bezpośrednio na Github:
Kompatybilność PostgreSQL z platformą Azure
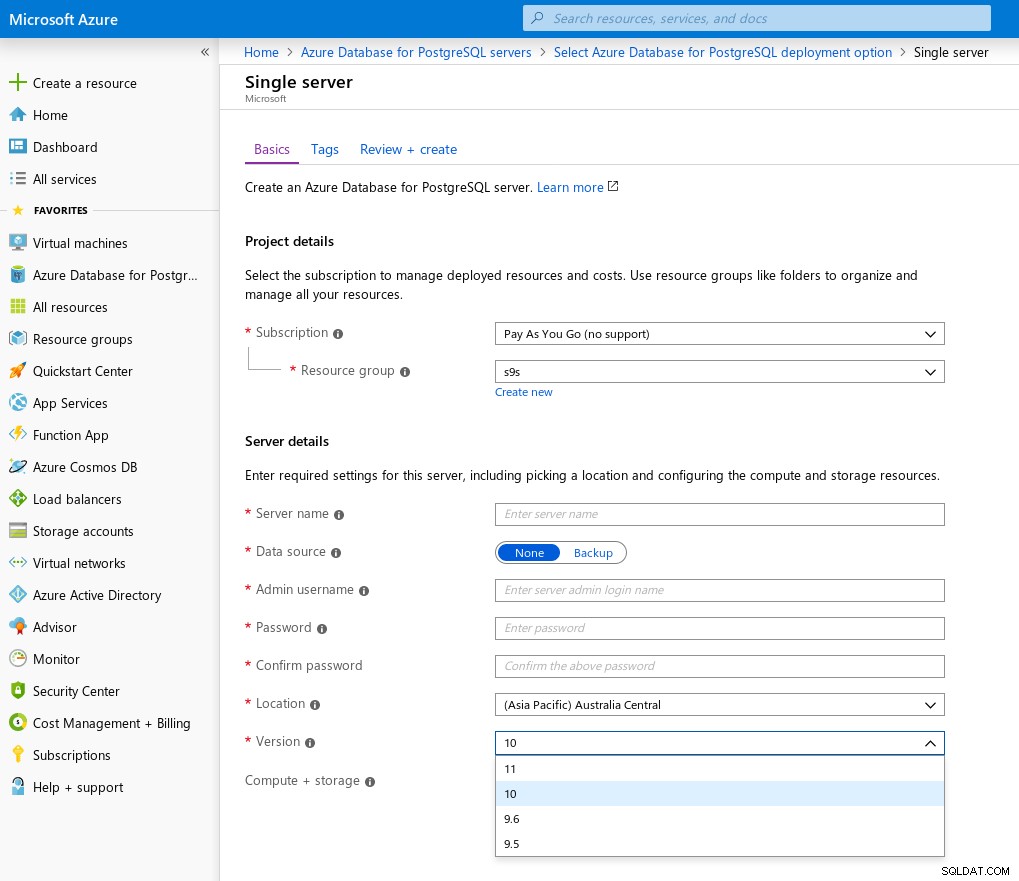
Wersje
Zgodnie z dokumentacją produktu Single Server jest przeznaczony dla wersji PostgreSQL w głównym zakresie n-2:
Jako rozwiązanie stworzone z myślą o wydajności Pojedynczy serwer jest zalecany dla zestawów danych 100 GB i większe. Serwery zapewniały przewidywalną wydajność — instancje bazy danych mają predefiniowaną liczbę rdzeni wirtualnych i IOPS (na podstawie rozmiaru udostępnionej pamięci masowej).
Rozszerzenia
Istnieje sporo obsługiwanych rozszerzeń, a niektóre z nich są instalowane po wyjęciu z pudełka:
example@sqldat.com:5432 postgres> select name, default_version, installed_version from pg_available_extensions where name !~ '^postgis' order by name;
name | default_version | installed_version
------------------------------+-----------------+-------------------
address_standardizer | 2.4.3 |
address_standardizer_data_us | 2.4.3 |
btree_gin | 1.2 |
btree_gist | 1.5 |
chkpass | 1.0 |
citext | 1.4 |
cube | 1.2 |
dblink | 1.2 |
dict_int | 1.0 |
earthdistance | 1.1 |
fuzzystrmatch | 1.1 |
hstore | 1.4 |
hypopg | 1.1.1 |
intarray | 1.2 |
isn | 1.1 |
ltree | 1.1 |
orafce | 3.7 |
pg_buffercache | 1.3 | 1.3
pg_partman | 2.6.3 |
pg_prewarm | 1.1 |
pg_qs | 1.1 |
pg_stat_statements | 1.6 | 1.6
pg_trgm | 1.3 |
pg_wait_sampling | 1.1 |
pgcrypto | 1.3 |
pgrouting | 2.5.2 |
pgrowlocks | 1.2 |
pgstattuple | 1.5 |
plpgsql | 1.0 | 1.0
plv8 | 2.1.0 |
postgres_fdw | 1.0 |
tablefunc | 1.0 |
timescaledb | 1.1.1 |
unaccent | 1.1 |
uuid-ossp | 1.1 |
(35 rows)Monitorowanie PostgreSQL na platformie Azure
Monitorowanie serwerów opiera się na zestawie wskaźników, które można porządnie pogrupować w celu utworzenia niestandardowego pulpitu nawigacyjnego:
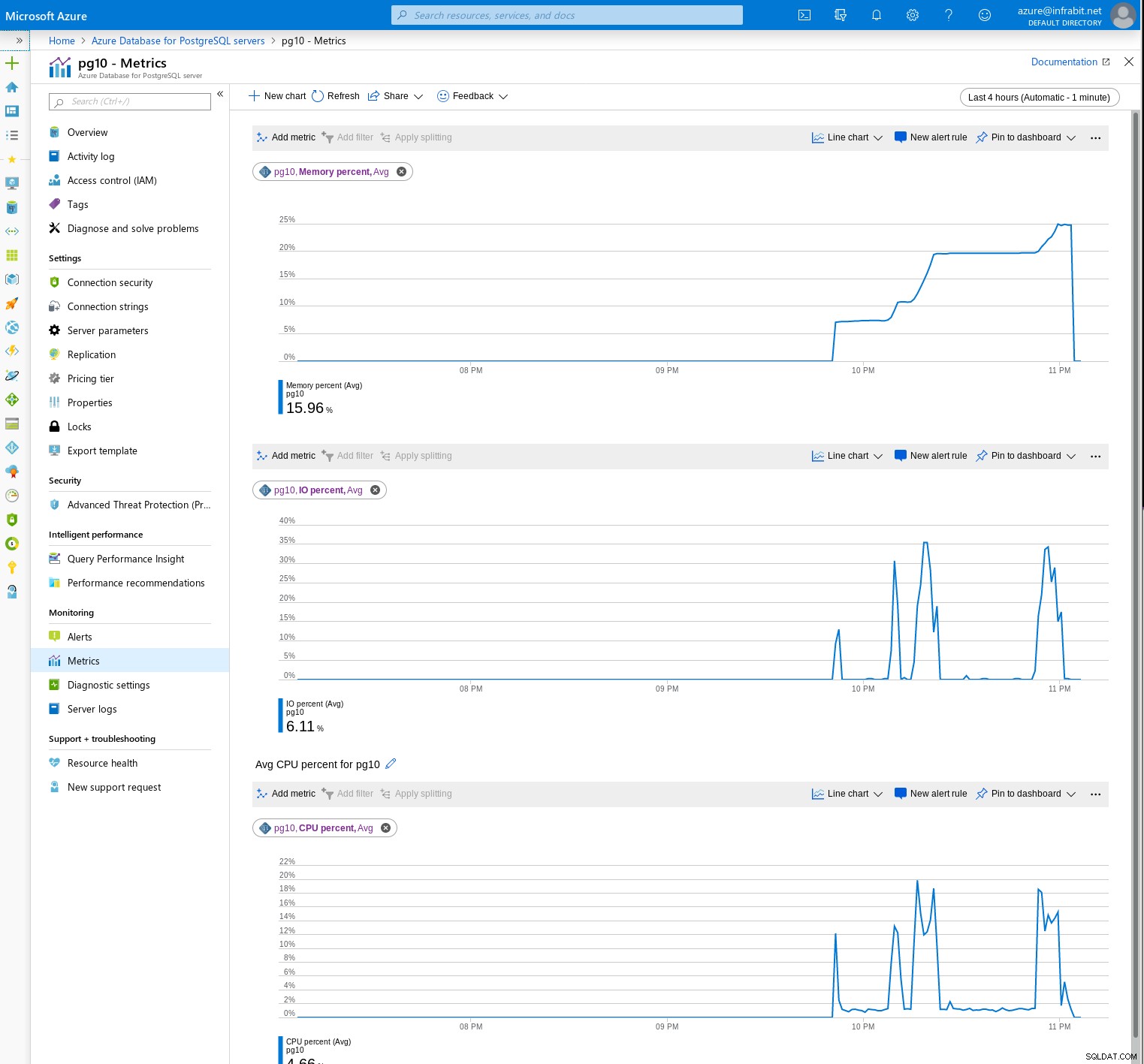
Osoby zaznajomione z Graphviz lub Blockdiag prawdopodobnie docenią opcję eksportu cały pulpit nawigacyjny do pliku JSON:
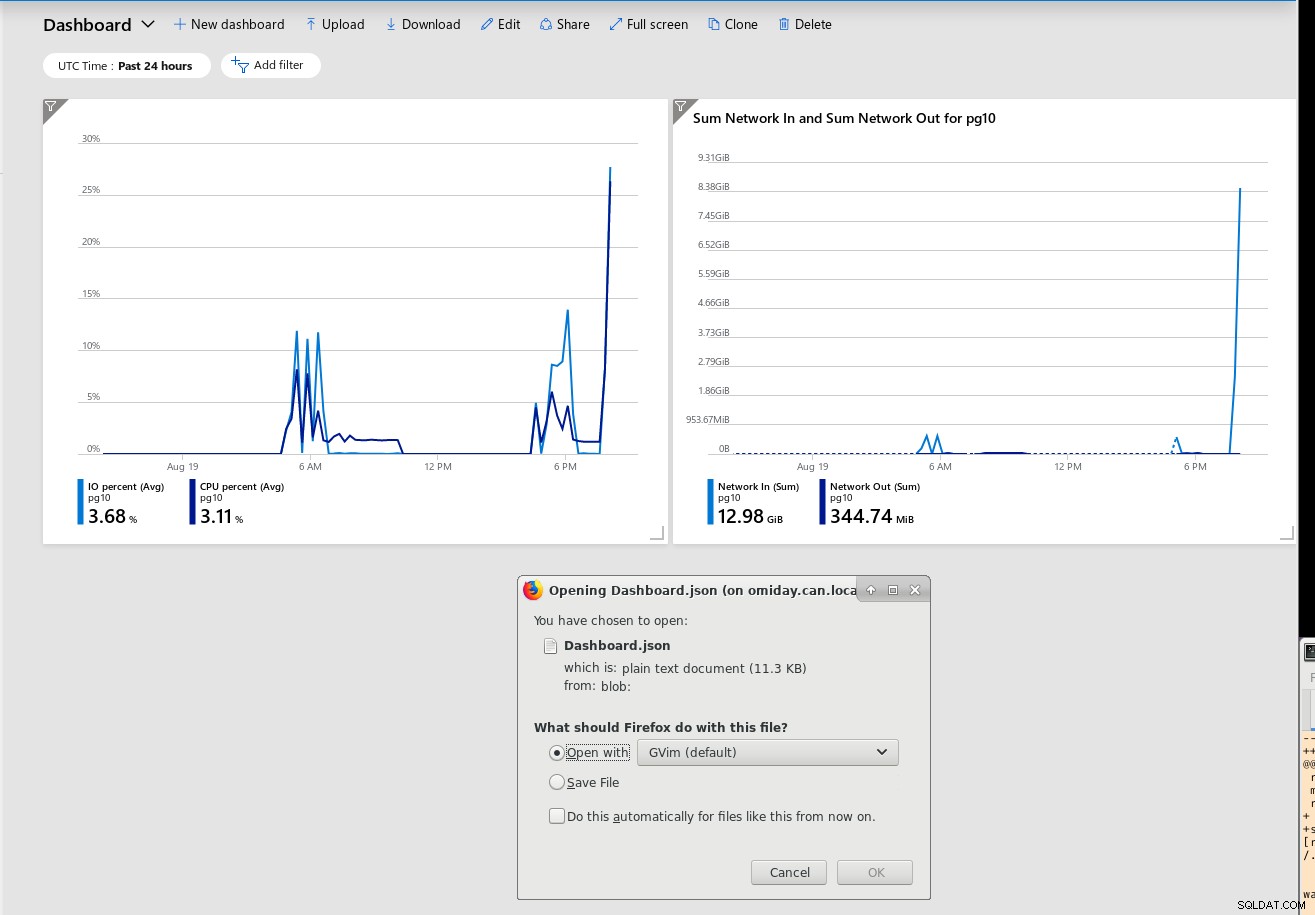
Ponadto dane mogą — i powinny — być powiązane z alertami:
Statystyki zapytań można śledzić za pomocą Query Store i wizualizować za pomocą Query Performance Wgląd. W tym celu należy włączyć kilka parametrów specyficznych dla platformy Azure:
example@sqldat.com:5432 postgres> select * from pg_settings where name ~ 'pgms_wait_sampling.query_capture_mode|pg_qs.query_capture_mode';
-[ RECORD 1 ]---+------------------------------------------------------------------------------------------------------------------
name | pg_qs.query_capture_mode
setting | top
unit |
category | Customized Options
short_desc | Selects which statements are tracked by pg_qs. Need to reload the config to make change take effect.
extra_desc |
context | superuser
vartype | enum
source | configuration file
min_val |
max_val |
enumvals | {none,top,all}
boot_val | none
reset_val | top
sourcefile |
sourceline |
pending_restart | f
-[ RECORD 2 ]---+------------------------------------------------------------------------------------------------------------------
name | pgms_wait_sampling.query_capture_mode
setting | all
unit |
category | Customized Options
short_desc | Selects types of wait events are tracked by this extension. Need to reload the config to make change take effect.
extra_desc |
context | superuser
vartype | enum
source | configuration file
min_val |
max_val |
enumvals | {none,all}
boot_val | none
reset_val | all
sourcefile |
sourceline |
pending_restart | fW celu wizualizacji powolnych zapytań i oczekiwania przechodzimy do widżetu Wydajność zapytań:
Długotrwałe zapytania
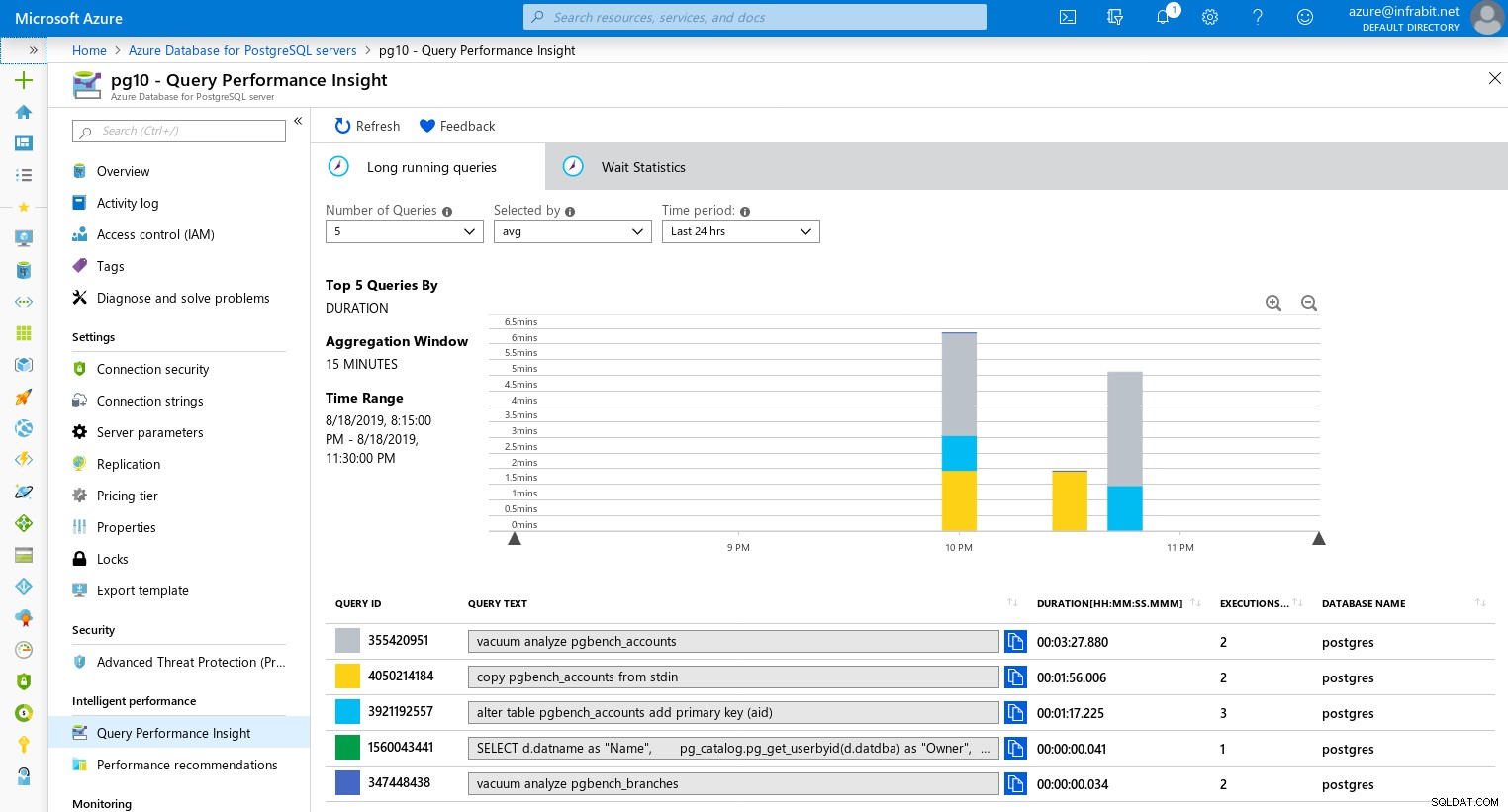
Statystyki oczekiwania
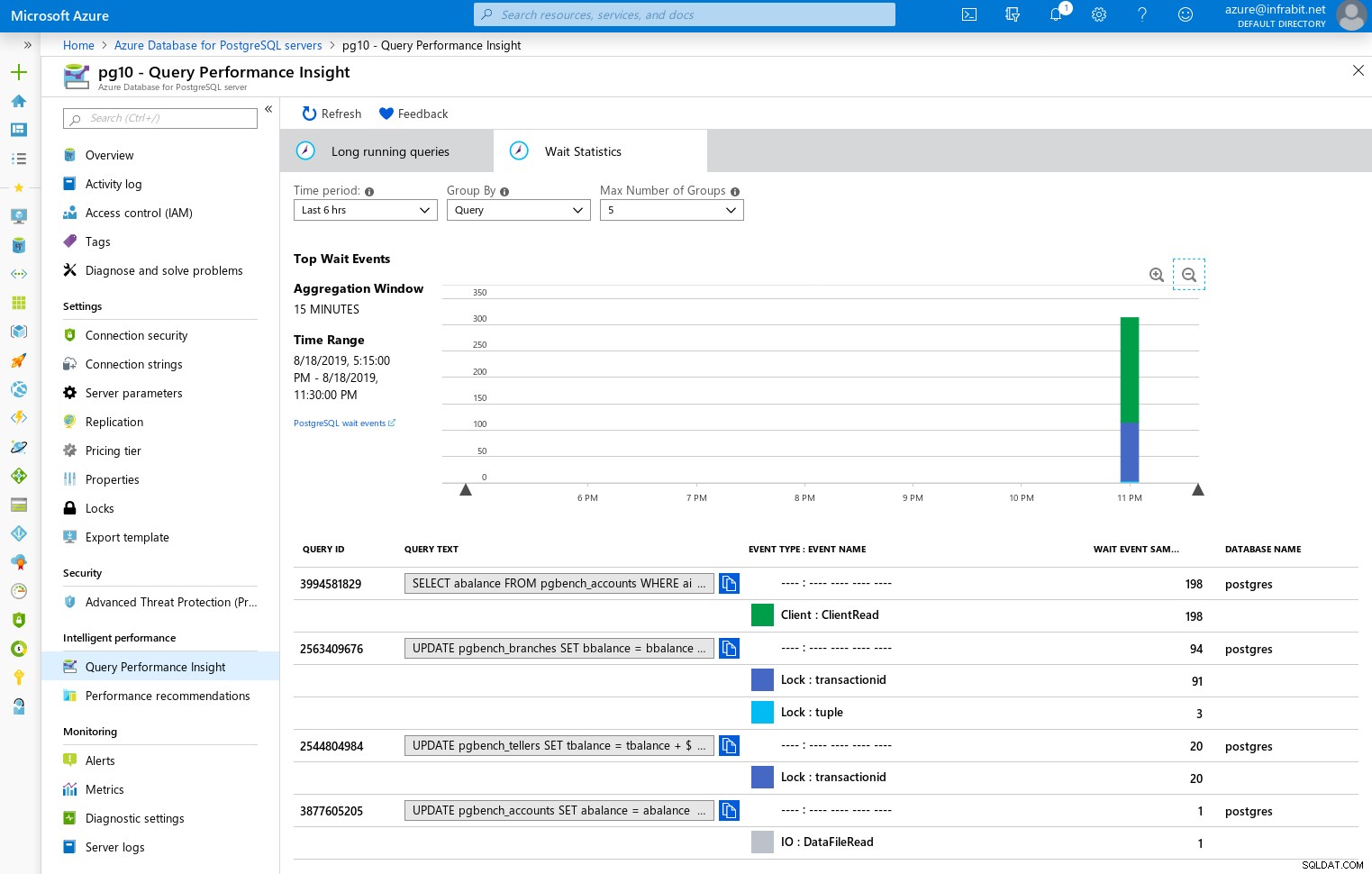
Logowanie PostgreSQL na platformie Azure
Standardowe dzienniki PostgreSQL można pobrać lub wyeksportować do Log Analytics w celu bardziej zaawansowanego analizowania:
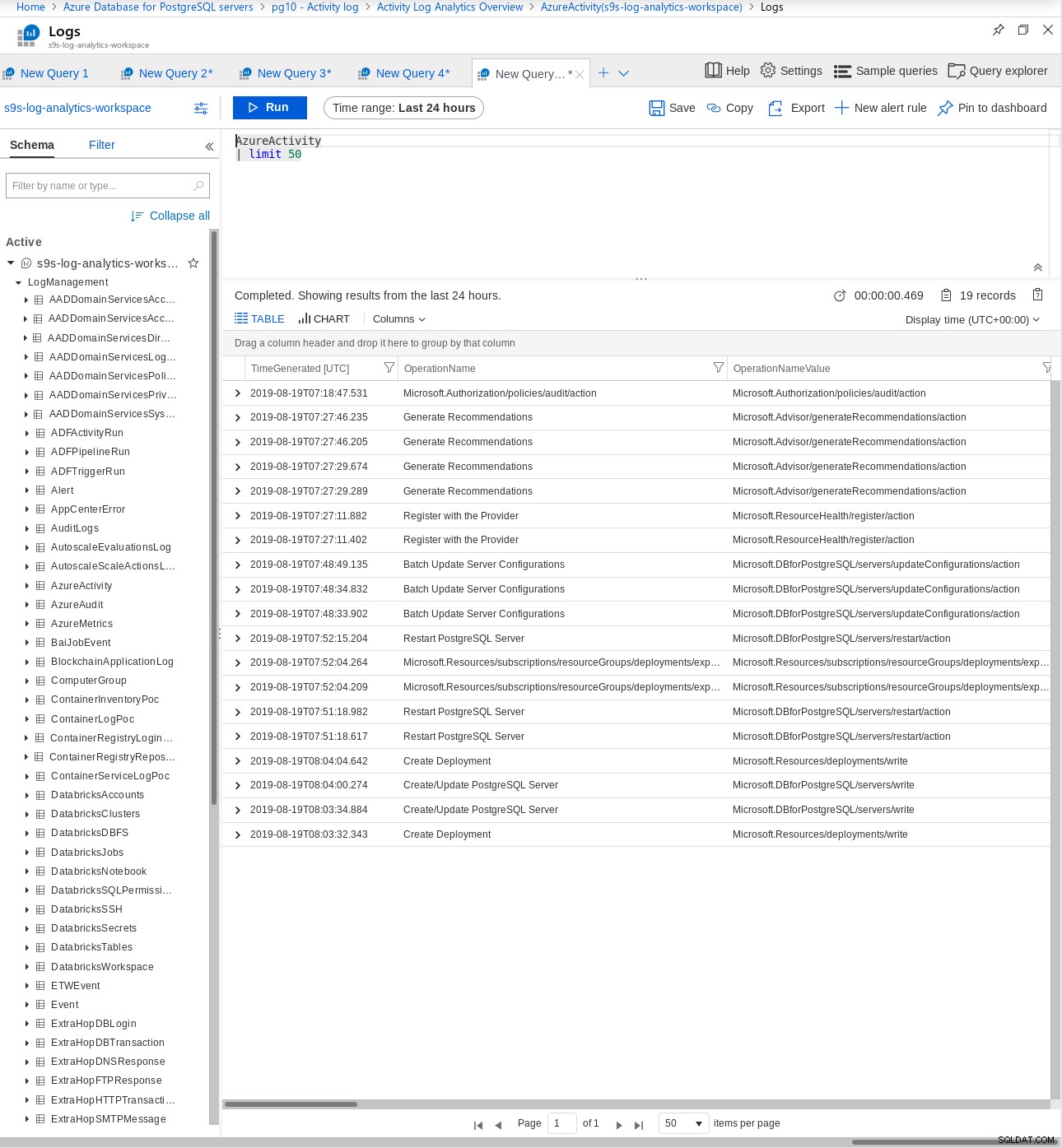
Wydajność i skalowanie PostgreSQL na platformie Azure
Chociaż liczbę rdzeni wirtualnych można łatwo zwiększyć lub zmniejszyć, ta akcja spowoduje ponowne uruchomienie serwera:
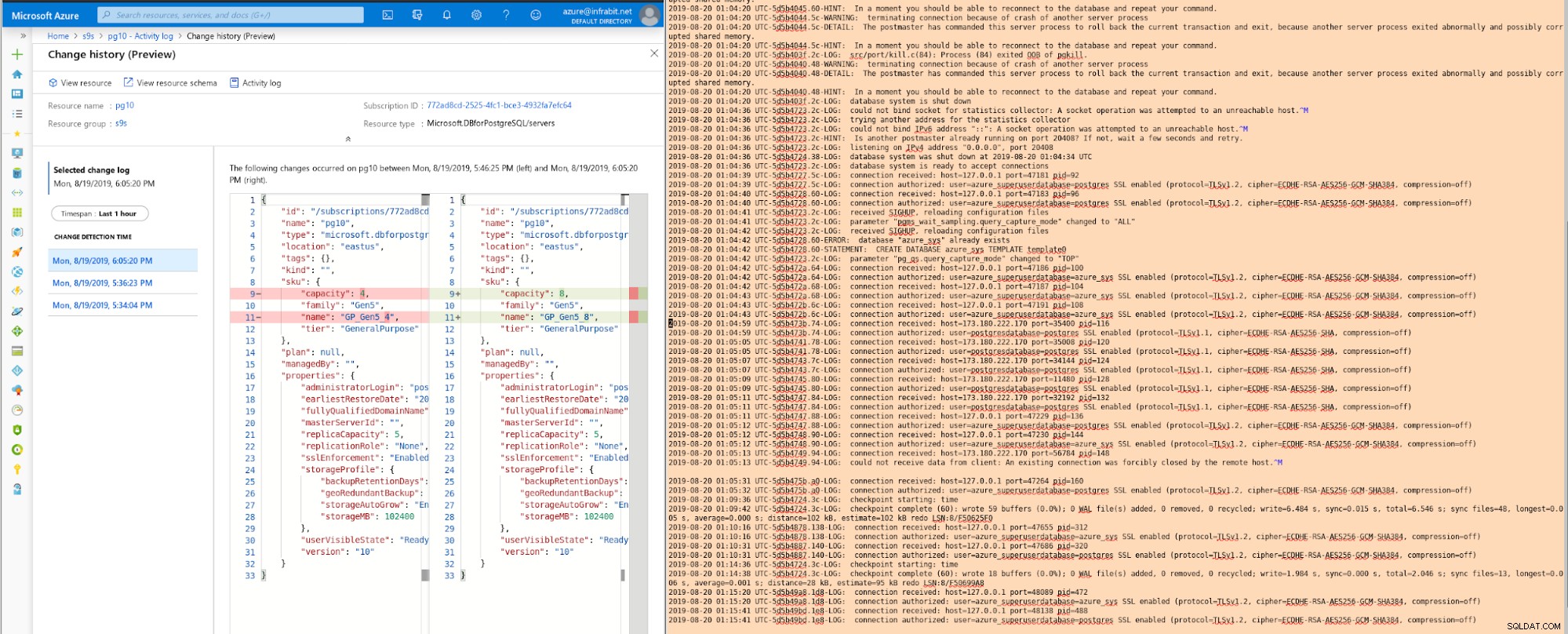
Aby osiągnąć zero przestojów, aplikacje muszą być w stanie bez problemu radzić sobie z przejściowymi błędami .
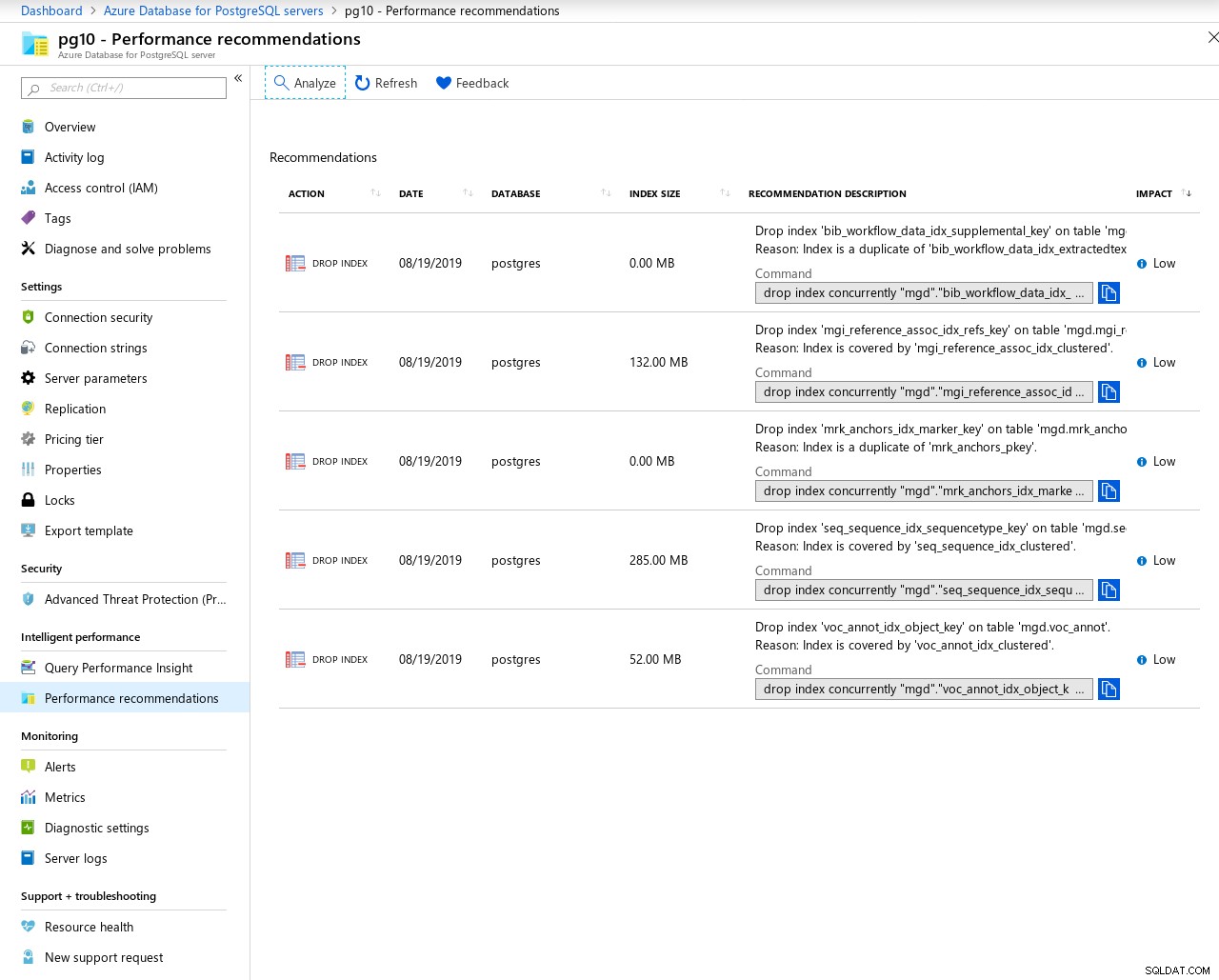
W celu dostrajania zapytań platforma Azure udostępnia administratorowi DBA zalecenia dotyczące wydajności, oprócz wstępnie załadowanych rozszerzeń pg_statements i pg_buffercache:
Wysoka dostępność i replikacja na platformie Azure
Wysoka dostępność serwera bazy danych jest osiągana za pomocą replikacji sprzętowej opartej na węźle. Gwarantuje to, że w przypadku awarii sprzętu nowy węzeł może zostać uruchomiony w ciągu kilkudziesięciu sekund.
Azure zapewnia nadmiarową bramę jako punkt końcowy połączenia sieciowego dla wszystkich serwerów baz danych w regionie.
Zabezpieczenia PostgreSQL na platformie Azure
Domyślnie reguły zapory odmawiają dostępu do instancji PostgreSQL. Ponieważ serwer bazy danych Azure jest odpowiednikiem klastra bazy danych, reguły dostępu będą miały zastosowanie do wszystkich baz danych hostowanych na serwerze.
Oprócz adresów IP reguły zapory mogą odwoływać się do sieci wirtualnej, co jest funkcją dostępną tylko w warstwach ogólnego przeznaczenia i zoptymalizowanych pod kątem pamięci.
Jedna rzecz, którą zauważyłem w interfejsie sieciowym zapory sieciowej — nie mogłem nawigować z dala od strony podczas zapisywania zmian:
Dane w spoczynku są szyfrowane przy użyciu klucza zarządzanego przez serwer, a użytkownicy chmury nie mogą wyłącz szyfrowanie. Przesyłane dane są również szyfrowane — wymagany protokół SSL można zmienić dopiero po utworzeniu serwera bazy danych. Podobnie jak dane w spoczynku, kopie zapasowe są szyfrowane i szyfrowania nie można wyłączyć.
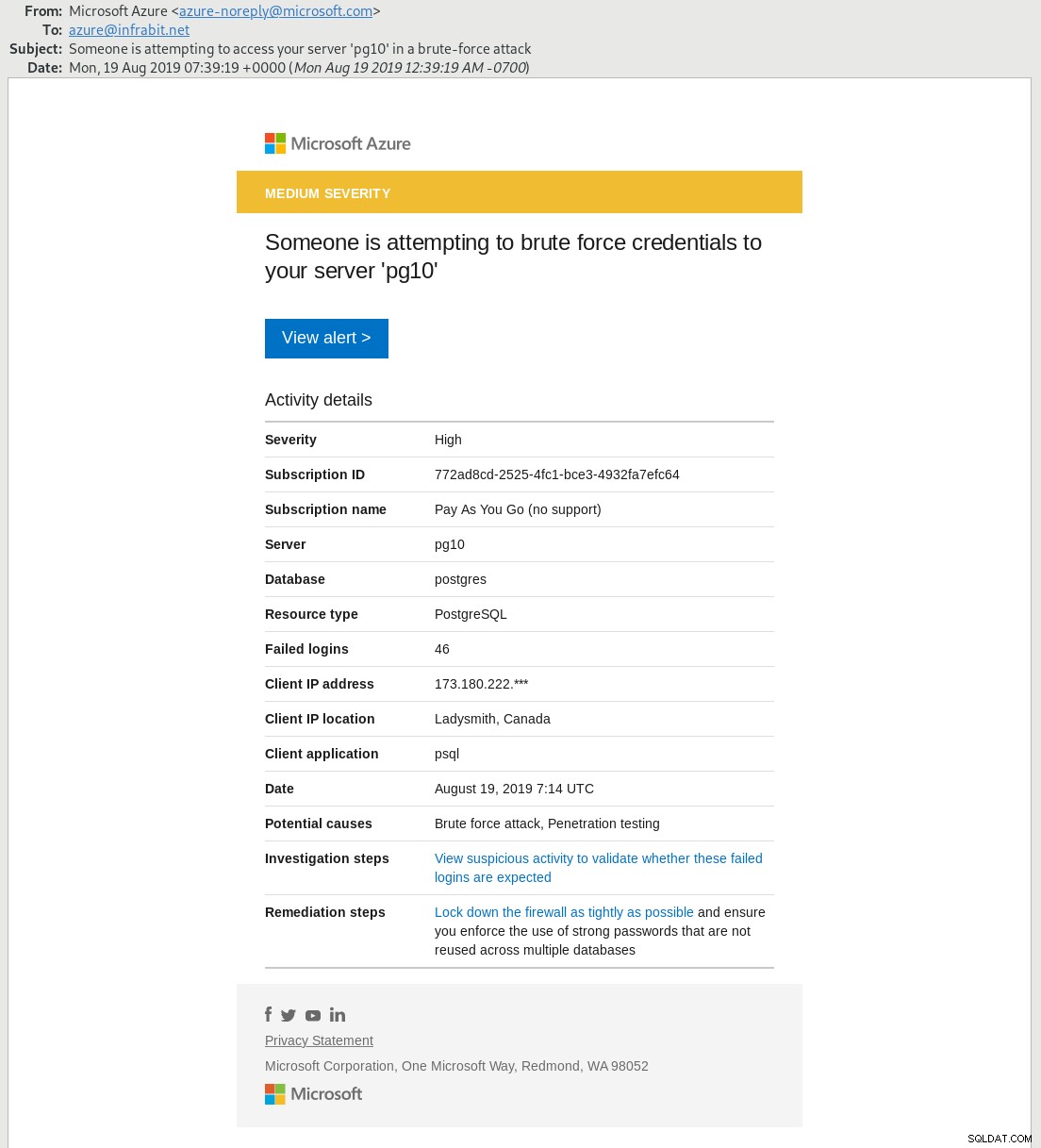
Zaawansowana ochrona przed zagrożeniami zapewnia alerty i zalecenia dotyczące szeregu żądań dostępu do bazy danych, które są uważane za zagrożenie bezpieczeństwa. Funkcja jest obecnie w wersji zapoznawczej. Aby to zademonstrować, zasymulowałem atak brute force na hasło:
~ $ while : ; do psql -U $(pwgen -s 20 1)@pg10 ; sleep 0.1 ; done
psql: FATAL: password authentication failed for user "AApT6z4xUzpynJwiNAYf"
psql: FATAL: password authentication failed for user "gaNeW8VSIflkdnNZSpNV"
psql: FATAL: password authentication failed for user "SWZnY7wGTxdLTLcbqnUW"
psql: FATAL: password authentication failed for user "BVH2SC12m9js9vZHcuBd"
psql: FATAL: password authentication failed for user "um9kqUxPIxeQrzWQXr2v"
psql: FATAL: password authentication failed for user "8BGXyg3KHF3Eq3yHpik1"
psql: FATAL: password authentication failed for user "5LsVrtBjcewd77Q4kaj1"
....Sprawdź logi PostgreSQL:
2019-08-19 07:13:50 UTC-5d5a4c2e.138-FATAL: password authentication failed
for user "AApT6z4xUzpynJwiNAYf"
2019-08-19 07:13:50 UTC-5d5a4c2e.138-DETAIL: Role "AApT6z4xUzpynJwiNAYf" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:51 UTC-5d5a4c2f.13c-LOG: connection received: host=173.180.222.170 port=27248 pid=316
2019-08-19 07:13:51 UTC-5d5a4c2f.13c-FATAL: password authentication failed for user "gaNeW8VSIflkdnNZSpNV"
2019-08-19 07:13:51 UTC-5d5a4c2f.13c-DETAIL: Role "gaNeW8VSIflkdnNZSpNV" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:52 UTC-5d5a4c30.140-LOG: connection received: host=173.180.222.170 port=58256 pid=320
2019-08-19 07:13:52 UTC-5d5a4c30.140-FATAL: password authentication failed for user "SWZnY7wGTxdLTLcbqnUW"
2019-08-19 07:13:52 UTC-5d5a4c30.140-DETAIL: Role "SWZnY7wGTxdLTLcbqnUW" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:53 UTC-5d5a4c31.148-LOG: connection received: host=173.180.222.170 port=32984 pid=328
2019-08-19 07:13:53 UTC-5d5a4c31.148-FATAL: password authentication failed for user "BVH2SC12m9js9vZHcuBd"
2019-08-19 07:13:53 UTC-5d5a4c31.148-DETAIL: Role "BVH2SC12m9js9vZHcuBd" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:53 UTC-5d5a4c31.14c-LOG: connection received: host=173.180.222.170 port=43384 pid=332
2019-08-19 07:13:54 UTC-5d5a4c31.14c-FATAL: password authentication failed for user "um9kqUxPIxeQrzWQXr2v"
2019-08-19 07:13:54 UTC-5d5a4c31.14c-DETAIL: Role "um9kqUxPIxeQrzWQXr2v" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:54 UTC-5d5a4c32.150-LOG: connection received: host=173.180.222.170 port=27672 pid=336
2019-08-19 07:13:54 UTC-5d5a4c32.150-FATAL: password authentication failed for user "8BGXyg3KHF3Eq3yHpik1"
2019-08-19 07:13:54 UTC-5d5a4c32.150-DETAIL: Role "8BGXyg3KHF3Eq3yHpik1" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:55 UTC-5d5a4c33.154-LOG: connection received: host=173.180.222.170 port=12712 pid=340
2019-08-19 07:13:55 UTC-5d5a4c33.154-FATAL: password authentication failed for user "5LsVrtBjcewd77Q4kaj1"
2019-08-19 07:13:55 UTC-5d5a4c33.154-DETAIL: Role "5LsVrtBjcewd77Q4kaj1" does not exist.Powiadomienie e-mail dotarło około 30 minut później:
Aby umożliwić szczegółowy dostęp do serwera bazy danych, platforma Azure zapewnia kontrolę RBAC, która jest natywną funkcją kontroli dostępu w chmurze, jeszcze jednym narzędziem w arsenale PostgreSQL Cloud DBA. To jest tak blisko, jak tylko możemy się zbliżyć do wszechobecnych reguł dostępu pg_hba.
Kopia zapasowa i odzyskiwanie PostgreSQL na platformie Azure
Niezależnie od poziomów cenowych kopie zapasowe są przechowywane od 7 do 35 dni. Poziom cenowy wpływa również na możliwość przywracania danych.
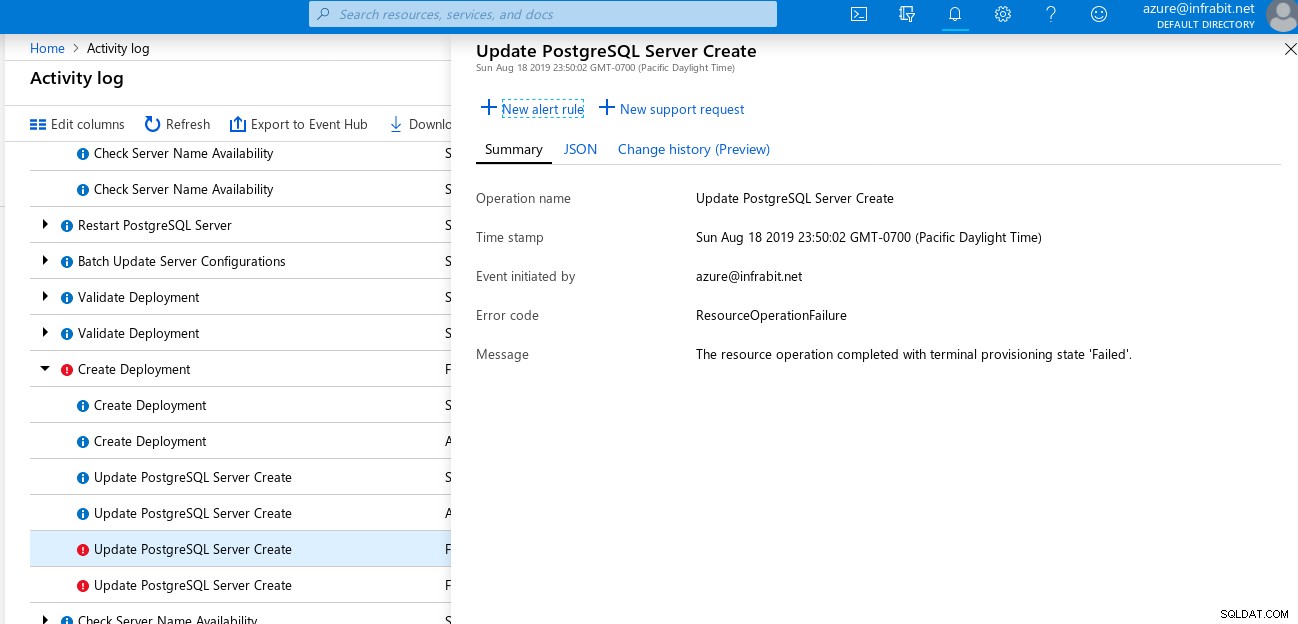
Odzyskiwanie do określonego punktu w czasie jest dostępne za pośrednictwem portalu Azure lub interfejsu wiersza polecenia, a zgodnie z dokumentacją nawet do pięciu minut. Funkcjonalność portalu jest raczej ograniczona — widżet wyboru daty ślepo pokazuje ostatnie 7 dni jako możliwe daty do wybrania, chociaż dzisiaj stworzyłem serwer. Ponadto nie przeprowadzono weryfikacji w docelowym czasie odzyskiwania — spodziewałem się, że wprowadzenie wartości poza interwałem odzyskiwania spowoduje błąd uniemożliwiający kontynuowanie kreatora:
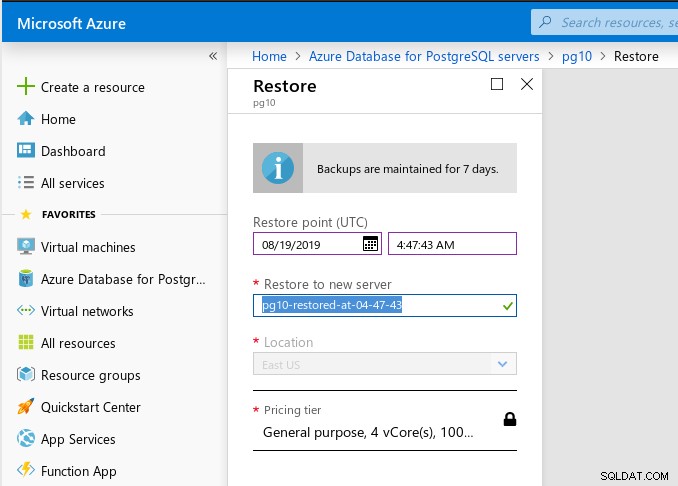
Po uruchomieniu procesu przywracania wystąpił błąd, prawdopodobnie spowodowany wartości zakresu, wyskoczy około minutę później:
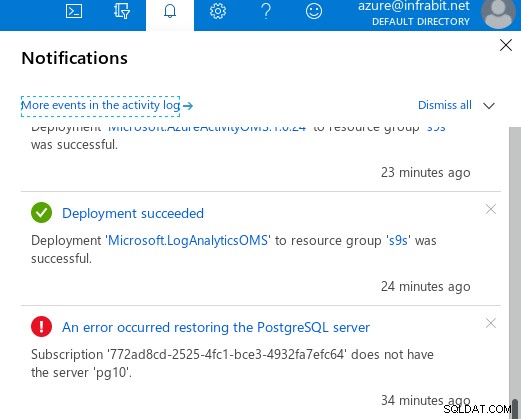
…ale niestety komunikat o błędzie nie był zbyt pomocny:
Przechowywanie kopii zapasowych jest bezpłatne przez okresy przechowywania do 7 dni. To może okazać się niezwykle przydatne w środowiskach programistycznych.
Wskazówki i porady
Limity
Przyzwyczaj się do limitów pojedynczego serwera.
Łączność
Zawsze używaj ciągu połączenia, aby połączenie było kierowane do właściwego serwera bazy danych.
Replikacja
W przypadku scenariuszy odzyskiwania po awarii zlokalizuj repliki do odczytu w jednym ze sparowanych regionów.
Role
Tak jak w przypadku AWS i GCloud, nie ma dostępu superużytkownika.
GUC
Parametry wymagające ponownego uruchomienia serwera lub dostępu superużytkownika nie mogą być konfigurowane.
Skalowanie
Podczas autoskalowania aplikacje powinny ponawiać próby, dopóki nie pojawi się nowy węzeł.
Nie można określić ilości pamięci i IOPS — pamięć jest przydzielana w jednostkach GB na rdzeń wirtualny, maksymalnie 320 GB (32 v rdzenie x 10 GB), a liczba operacji IOPS zależy od rozmiaru aprowizowanej pamięci do maksymalnie 6000 IOPS. Obecnie platforma Azure oferuje opcję podglądu dużej pamięci masowej z maksymalnie 20 000 IOPS.
Serwerów utworzonych w warstwie Podstawowa nie można uaktualnić do serwerów ogólnego przeznaczenia ani zoptymalizowanych pod kątem pamięci.
Pamięć
Upewnij się, że funkcja automatycznego powiększania jest włączona — jeśli ilość danych przekroczy zapewnioną przestrzeń dyskową, baza danych przejdzie w tryb tylko do odczytu.
Pamięć może być skalowana tylko w górę. Podobnie jak w przypadku wszystkich innych dostawców usług w chmurze, alokacji pamięci nie można zmniejszyć i nie mogłem znaleźć żadnego wyjaśnienia. Biorąc pod uwagę najnowocześniejszy sprzęt, dużych graczy w chmurze mogą sobie pozwolić, nie powinno być powodu, aby nie oferować funkcji podobnych do relokacji danych online LVM. Pamięć masowa jest obecnie naprawdę tania, naprawdę nie ma powodu, aby myśleć o zmniejszaniu skali do następnej dużej aktualizacji.
Zapora sieciowa
W niektórych przypadkach rozpowszechnienie aktualizacji reguł zapory może zająć do pięciu minut.
Serwer znajduje się w tej samej podsieci, co serwery aplikacji, nie będą dostępne, dopóki nie zostaną wprowadzone odpowiednie reguły zapory.
Reguły sieci wirtualnej nie zezwalają na dostęp między regionami, w wyniku czego dblink i postgres_fdw nie mogą być używane do łączenia się z bazami danych poza chmurą Azure.
Podejścia sieci wirtualnej/podsieci nie można zastosować do aplikacji sieci Web, ponieważ ich połączenia pochodzą z publicznych adresów IP.
Duże sieci wirtualne będą niedostępne, gdy punkty końcowe usługi są włączone.
Szyfrowanie
Dla aplikacji, które wymagają weryfikacji certyfikatu serwera, plik jest dostępny do pobrania z Digicert. Microsoft ułatwił to i nie musisz się martwić o odnowienie do 2025 r.:
~ $ openssl x509 -in BaltimoreCyberTrustRoot.crt.pem -noout -dates
notBefore=May 12 18:46:00 2000 GMT
notAfter=May 12 23:59:00 2025 GMTSystem wykrywania włamań
Wersja zapoznawcza Zaawansowanej ochrony przed zagrożeniami nie jest dostępna dla instancji w warstwie Podstawowa.
Kopia zapasowa i przywracanie
W przypadku aplikacji, które nie mogą sobie pozwolić na przestoje w regionie, rozważ skonfigurowanie serwera z geograficznie nadmiarowym magazynem kopii zapasowych. Ta opcja może być włączona tylko podczas tworzenia serwera bazy danych.
Wymaganie ponownej konfiguracji reguł zapory w chmurze po operacji PITR jest szczególnie ważne.
Usunięcie serwera bazy danych usuwa wszystkie kopie zapasowe.
Po przywróceniu należy wykonać pewne zadania po przywróceniu.
Tabele bez logowania są zalecane do wstawiania zbiorczego w celu zwiększenia wydajności, jednak nie są one replikowane.
Monitorowanie
Dane są rejestrowane co minutę i przechowywane przez 30 dni.
Logowanie
Zapis zapytań jest opcją globalną, co oznacza, że ma zastosowanie do wszystkich baz danych. Transakcje i zapytania tylko do odczytu dłuższe niż 6000 bajtów są problematyczne. Domyślnie przechwycone zapytania są przechowywane przez 7 dni.
Wydajność
Zalecenia dotyczące analizy wydajności zapytań są obecnie ograniczone do tworzenia i usuwania indeksu.
Wyłącz pg_stat_staements, gdy nie jest to potrzebne.
Zastąp uuid_generate_v4 funkcją gen_random_uuid(). Jest to zgodne z zaleceniem w oficjalnej dokumentacji PostgreSQL, zobacz Budowanie uuid-ossp.
Wysoka dostępność i replikacja
Istnieje limit pięciu replik do odczytu. Aplikacje intensywnie korzystające z zapisu powinny unikać używania replik do odczytu, ponieważ mechanizm replikacji jest asynchroniczny, co powoduje pewne opóźnienia, które aplikacje muszą tolerować. Repliki do odczytu mogą znajdować się w innym regionie.
Obsługę REPLICA można włączyć dopiero po utworzeniu serwera. Ta funkcja wymaga ponownego uruchomienia serwera:
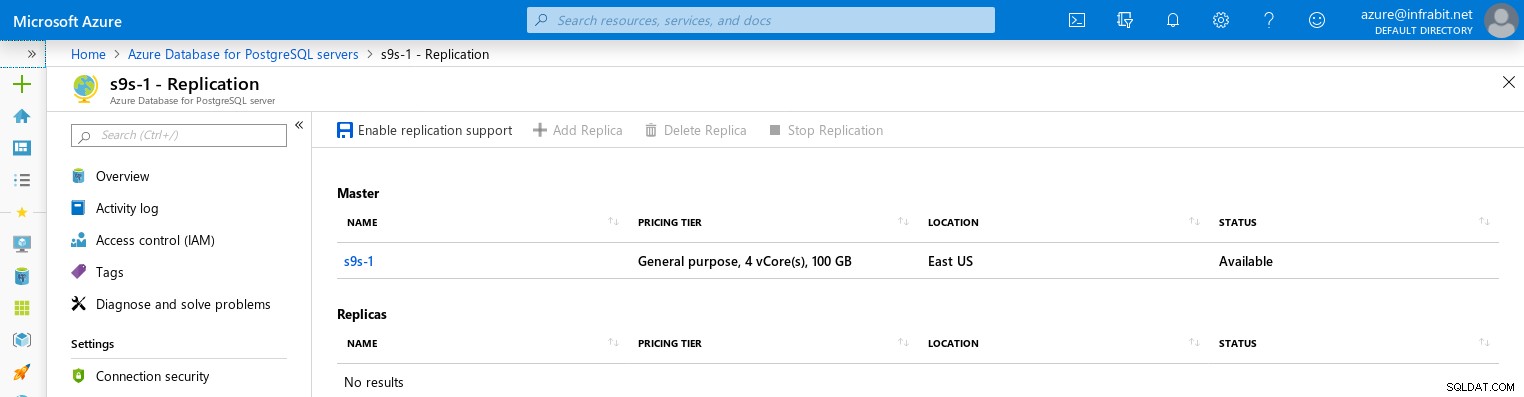
Repliki do odczytu nie dziedziczą reguł zapory z węzła głównego:
Przełączenie awaryjne w celu odczytania repliki nie jest automatyczne. Mechanizm przełączania awaryjnego jest oparty na węźle.
Istnieje długa lista kwestii, które należy przejrzeć przed skonfigurowaniem replik do odczytu.
Tworzenie replik zajmuje dużo czasu, nawet jeśli testowałem ze stosunkowo małym zestawem danych:
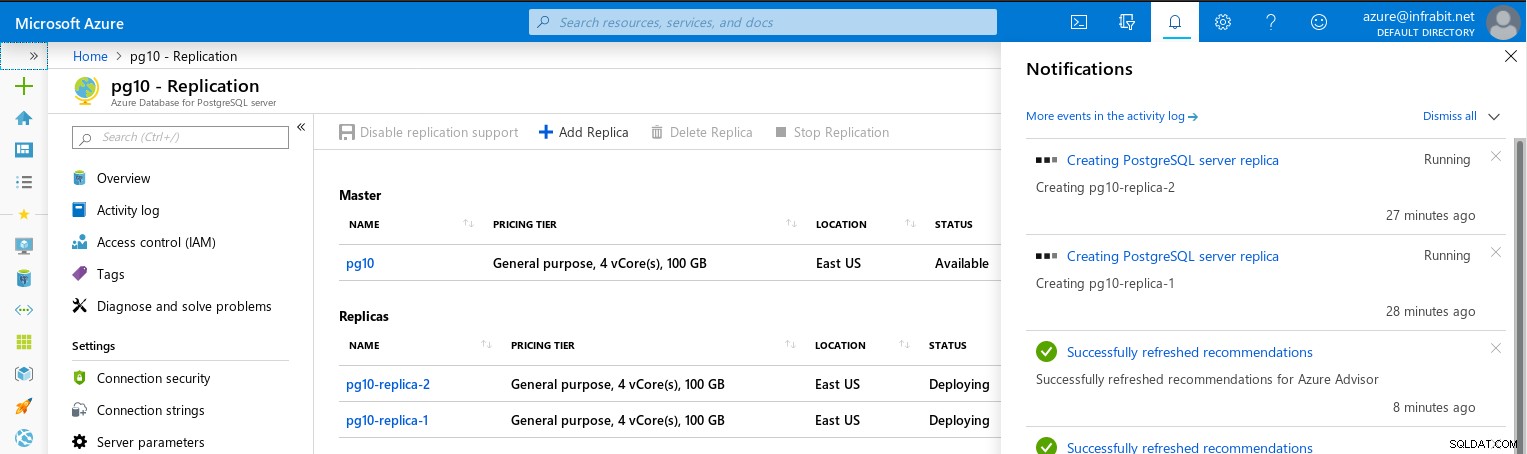 Próżnia
Próżnia Odkurzanie
Sprawdź kluczowe parametry, ponieważ usługa Azure Database for PostgreSQL jest dostarczana z domyślnymi wartościami próżni nadrzędnej:
example@sqldat.com:5432 postgres> select name,setting from pg_settings where name ~ '^autovacuum.*';
name | setting
-------------------------------------+-----------
autovacuum | on
autovacuum_analyze_scale_factor | 0.05
autovacuum_analyze_threshold | 50
autovacuum_freeze_max_age | 200000000
autovacuum_max_workers | 3
autovacuum_multixact_freeze_max_age | 400000000
autovacuum_naptime | 15
autovacuum_vacuum_cost_delay | 20
autovacuum_vacuum_cost_limit | -1
autovacuum_vacuum_scale_factor | 0.05
autovacuum_vacuum_threshold | 50
autovacuum_work_mem | -1
(12 rows)Aktualizacje
Automatyczne główne aktualizacje nie są obsługiwane. Jak wspomniano wcześniej, jest to okazja do oszczędności kosztów dzięki zmniejszeniu automatycznie powiększanej pamięci masowej.
Ulepszenia PostgreSQL Azure
Seria czasowa
TimescaleDB jest dostępny jako rozszerzenie (nie jest częścią modułów PostgreSQL), jednak to tylko kilka kliknięć myszą. Jedyną wadą jest starsza wersja 1.1.1, podczas gdy wersja upstream jest obecnie w 1.4.1 (2019-08-01).
example@sqldat.com:5432 postgres> CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
WARNING:
WELCOME TO
_____ _ _ ____________
|_ _(_) | | | _ \ ___ \
| | _ _ __ ___ ___ ___ ___ __ _| | ___| | | | |_/ /
| | | | _ ` _ \ / _ \/ __|/ __/ _` | |/ _ \ | | | ___ \
| | | | | | | | | __/\__ \ (_| (_| | | __/ |/ /| |_/ /
|_| |_|_| |_| |_|\___||___/\___\__,_|_|\___|___/ \____/
Running version 1.1.1
For more information on TimescaleDB, please visit the following links:
1. Getting started: https://docs.timescale.com/getting-started
2. API reference documentation: https://docs.timescale.com/api
3. How TimescaleDB is designed: https://docs.timescale.com/introduction/architecture
CREATE EXTENSION
example@sqldat.com:5432 postgres> \dx timescaledb
List of installed extensions
Name | Version | Schema | Description
-------------+---------+--------+-------------------------------------------------------------------
timescaledb | 1.1.1 | public | Enables scalable inserts and complex queries for time-series data
(1 row)Logowanie
Oprócz opcji rejestrowania PostgreSQL, Azure Database for PostgreSQL można skonfigurować do rejestrowania dodatkowych zdarzeń diagnostycznych.
Zapora sieciowa
Azure Portal zawiera przydatną funkcję umożliwiającą połączenia z adresów IP zalogowanych do portalu:
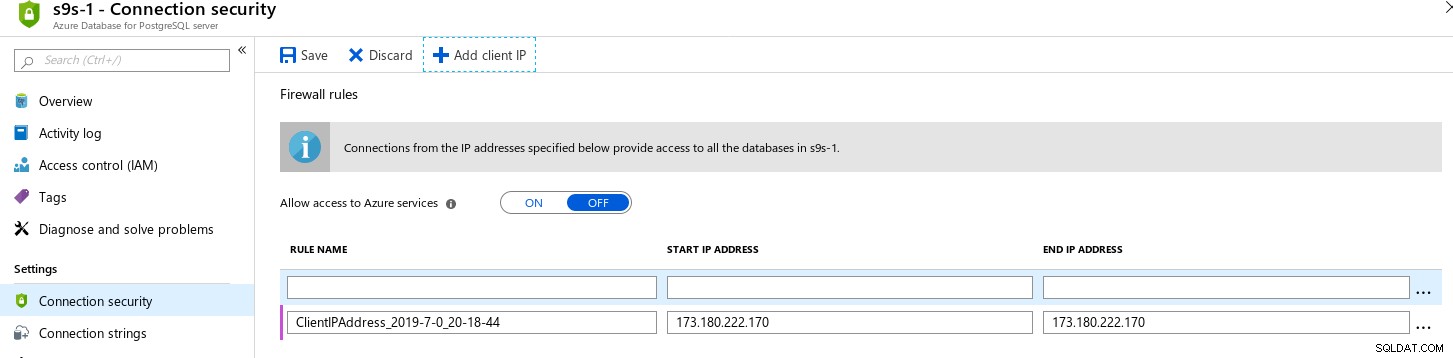
Zauważyłem tę funkcję, ponieważ ułatwia programistom i administratorom systemu pozwolić sobie na wejście i wyróżnia się jako funkcja, której nie oferuje ani AWS, ani GCloud.
Wnioski
Azure Database for PostgreSQL Single Server oferuje usługi na poziomie przedsiębiorstwa, jednak wiele z tych usług jest nadal w trybie podglądu:Magazyn zapytań, Wgląd w wydajność, Zalecenia dotyczące wydajności, Zaawansowana ochrona przed zagrożeniami, Duża pamięć masowa, Wiele regionów Przeczytaj repliki.
Podczas gdy znajomość systemu operacyjnego nie jest już wymagana do administrowania PostgreSQL w chmurze Azure, administrator baz danych powinien nabyć umiejętności, które nie ograniczają się do samej bazy danych — sieci Azure (VNet), bezpieczeństwo połączeń (zapora ), przeglądarka logów i analizy wraz z KQL, Azure CLI do wygodnego pisania skryptów, a lista jest długa.
Na koniec, dla tych, którzy planują migrację swoich obciążeń PostgreSQL na platformę Azure, dostępnych jest wiele zasobów wraz z wybraną listą partnerów platformy Azure, w tym Credativ, jednego z głównych sponsorów i współtwórców PostgreSQL.